
deeplearning 重要调参参数分析
reference: https://blog.csdn.net/jningwei/article/details/79243800
learning rate:学习率,控制模型的学习进度,决定权值更新的速度。也叫做步长,即反向传播算法的 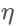
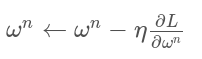
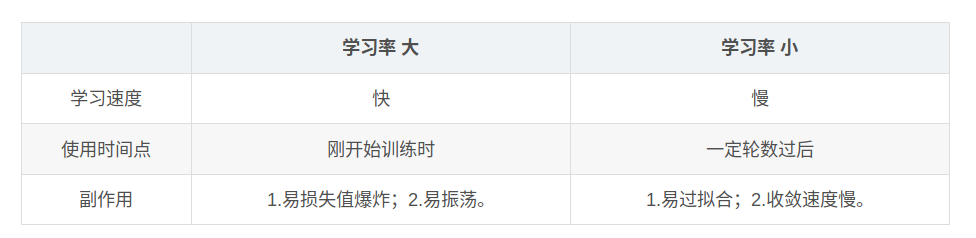
学习率的设置
在训练开始时,根据迭代次数动态设置学习率。
刚开始时,学习率以0.01~0.001 为宜,一定轮数后,开始下降,在快结束时学习率的衰减应该在100倍以上。由于迁移学习,模型已在原始数据上收敛,应设置较小的学习率(<= 0.00001),
在新数据上进行微调。
学习率缓解机制
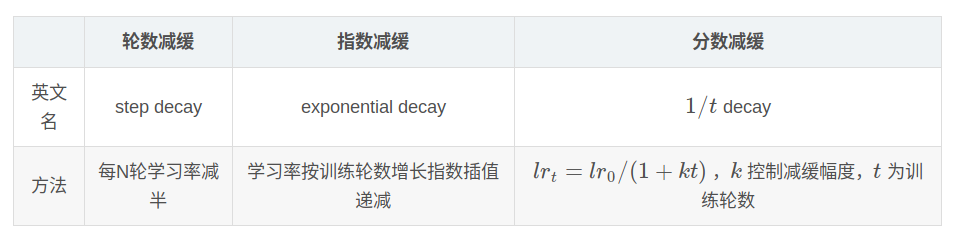
目标函数损失值看lr
理想情况下的损失曲线应该是滑梯式的,绿线所示:
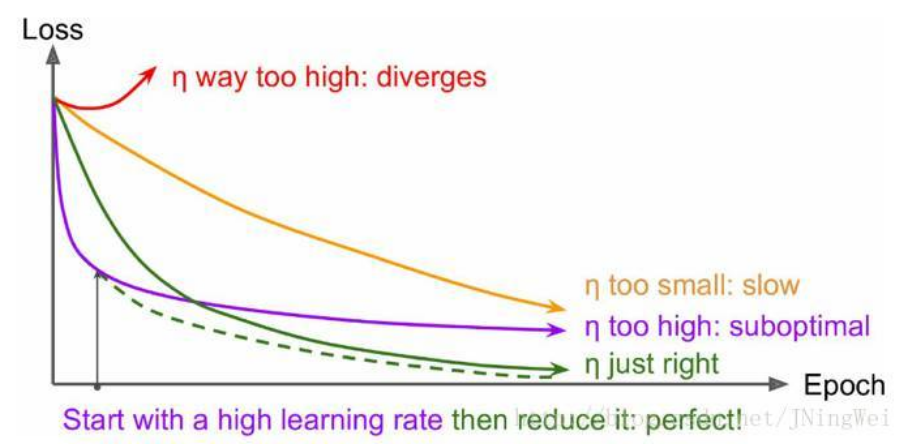
分析 :红线一开始就上扬,说明初始学习率过大,从而导致震荡,应该减小学习率。
黄线初始学习率较小,loss曲线收敛缓慢,易过拟合,应增大初始学习率。
紫线初始学习率过大,导致无法过拟合,应减小学习率。
权重衰减
为了避免网络的过拟合,对cost function引入正则项,作用是减小不重要参数对最后结果的影响,有用的权重不会受到weight decay的影响。过拟合时权重值逐渐变大,在loss function增加一个惩罚项。不是为了提高收敛速度或是收敛精度,正则项指示模型的复杂度,权重衰减调节模型复杂度对损失函数的影响。
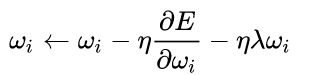
Momentum
基本思想是为了找到最优加入“惯性”的影响,当误差曲面中存在平坦区域时,SGD可以更快的学习。
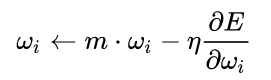
Learning Rate Decay
目的是为了提高SGD的寻优化能力,每次迭代的时候减小学习率的大小。
BN的好处:BN在NeuralNetwork 的激活函数之前,将wx+b按照特征进行标准化处理。
1.Normalization可以使特征缩放至【0,1】,在反向传播时梯度在1左右,避免梯度消失。
2.提高学习速率,标准化后更快达到收敛。
3.减少模型对初始化的依赖。
batch大小的作用
batch决定梯度下降的方向。如果batch size为全体数据集,则确定的方向可以更好的代表样本总体,更加准确的朝向极值的方向。缺点是内存的限制。
如果设置为1,即为在线学习,每次修正方向都以各自样本的梯度方向修正,难以收敛。
在合理的范围内增大batch_size可以提高内存利用率,减少跑完整个数据集的所需要的迭代次数,加快了相对于相同数据量的处理速度。一般设置为8的倍数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号