论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn.pdf
三位大佬:Jonathan Long Evan Shelhamer Trevor Darrell
这个网址是网上一个大佬记录的FCN的博客,同时深深感受到了自己与大佬的差距,但还是硬着头皮把论文阅读完成,贴出网址,和大家一起学习:https://blog.csdn.net/happyer88/article/details/47205839
进入正题,作者在开始就说了,引以为傲的是他们提出了“完全卷积”网络,这种网络的特点是可以输入任意大小的数据,并通过有效的脱离和学习能产生相应大小尺寸的输出。用AlexNet,GoogleNet,VGG修改为全卷积网络,并进行迁移学习微调。接着,作者定义一个跳跃结构,结合来自深层的,粗略层的分割信息,其中,该层中含有来自浅层的,精细层的外观信息,通过前面的结构与信息,能够进行精确的和详细的分割。(插播:CNN的强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征:较浅的卷积层感知域较小,学习到一些局部区域的特征;较深的卷积层具有较大的感知域,能够学习到更加抽象一些的特征。这些抽象特征对物体的大小、位置和方向等敏感性更低,从而有助于识别性能的提高。)
作者认为卷积网络不仅改进了全图分类效果,而且在结构化输出的定位任务上也取得了较大的进步(边界框对象的检测,部分和关键点的预测,匹配定位等)。FCN进行了很多开创性的工作,是首个对像素点进行end-to-end训练,同时进行有监督的预训练,同时对现有的网络修改为全卷积网络,可以对任意大小的输入产生密集输出。作者指出学习和推理的过程都是通过前馈计算和反向传播在整幅图像上进行的。网络内不的上采样层可以实现像素的预测,同时,采用降采样的池化层在网络中进行学习。大佬表示,分批训练目前是很常见的方式,但是和全卷积训练相比,效率上还是稍逊一点。FCN并不需要产生proposals,或通过随机场,分类器进行事后的优化操作等,由此可以看出,FCN还是很轻便的。作者在论文中经常提到的密集预测,个人 感觉和针对像素点的预测的说法大同小异。语义分割在位置和语义之间有一个紧密的联系,全局信息可以解析局部信息。深层特征层次在非线性的 局部-全局金字塔上进行位置和语义的编码。作者由此定义了前面的跳跃结构,以更好的利用特征信息。
作者提出的方法是将图像分类作为有监督的预训练,同时进行微调全卷积,从而可以从整个输入图片和groundTruth上进行高效的学习。作者融合了各个层的特征定义一个非线性的端到端的局部-全局表示。感受野从CNN可视化的角度来讲,就是输出featuremap某个节点的响应对应的输入图像的区域。网络中卷积,池化,及激活函数等结构在局部的输入图像上运行,并依赖相对应的空间坐标。一般深层网络用于计算一般的非线性函数,但只有计算非线性函数的网络层被叫做深层滤波器或者全卷积网络。在loss函数这,有点不好理解,作者说一个由FCN组成的实值loss函数定义了一个任务,如果这个loss function是最后一层网络所有空间维度的和,这里它给出了一个式子, loss function的梯度是每个像素梯度的和,所以,整幅图像L的随机梯度下降等同于每个像素点随机梯度下降,这里将网络最后一层上所有感受野作为一个minibatch。当感受野显著重叠时,由层与层之间的 计算相比patch-by-patch,前馈计算和反向传播会更高效。
整体过程为,首先是将网络调整为全卷积网络,用于产生粗略的输出,针对像素级的,需要将上述粗略的输出反映到像素。相比改造之前的AlexNet ,VGG,LeNet等网络,这些网络有固定的输入,同时产生非空间的输出,折磨受限的罪魁祸首是全连接层,其固定的尺寸就算了,还把空间位置给扔了,然而,作者就比较机智了,把全连接层看成卷积核覆盖整个输入图像的卷积。这种转变可以进行任意尺寸的输入。
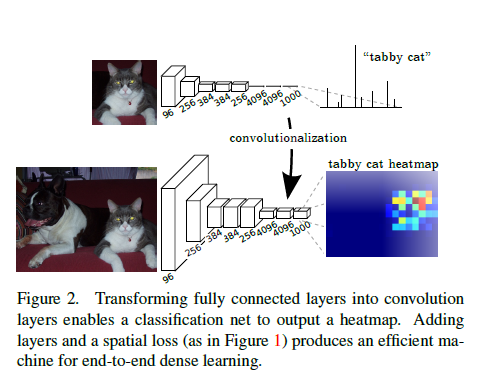
全卷积网络得到的结果图相当于调整前的网络对特定输入区域的评估,但是对那些patch中重叠区域的计算还是比较集中的。在FCN中,虽然输出map的大小由任意大小的输入图片控制,但是输出维度通常是由降采样减少的。分类网络进行降采样的原因是为了保持滤波器数量不大,同时计算要求可行,此版本的全卷积网络,通过乘上输出单元感受野的像素跨度因子使输出变得看起来“粗糙点”。
在看到shift and stitch is filter 这一块感觉没看懂,参考前面提供的大佬的网址,了解到Shift and stitch 是作者为了得到dense pretiction的方案之一,作者提到,Dense Prediction可以由在输入图片上进行移动得到的输出进行一起 拼接得到,如果输出图的下采样因子为f,则将输入像素向右移动x个,同时向下移动y个像素,(x,y) st 0<x,y<f。显而易见,经过一系列移动(这里前面的移动貌似是一步一步走的),相当于可以得到f*f个输入(这里注意,虽然计算量为f*f,增大了,但是获得了可以预测单个像素的效果),同时进行交错输出,使预测能够对应感受野中心的像素。接着,作者又提到了一个stride 为s的网络层(卷积或者池化层)和一系列带有权重fij的卷积层(忽略非相关特征的维度),设定低层网络的输入步长为1,对底层网络的输出进行因子为s的上采样。但是,将原始filter与上采样后的结果进行卷积却与
shift and stitch的不同,这里是因为这里进行卷积的filter只能看到输入减少的一部分,作者为此对filter 进行修改如下:
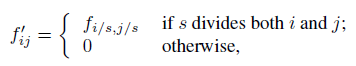
为了达到shift and stitch的效果,对滤波器进行逐层重复放大滤波器,直到所有的降采样消失。减少网络内的降采样是一个折中的措施,这样,filter可以获得更好的信息,但缺点就是有更小的感受野,并需要更多的时间进行计算。shift and stitch也是一种折中,在不见底滤波器感受野带线啊哦的情况下进行更密集的输出,但是缺点是禁止filters 以比当初设定的更精细的尺寸来访问信息。
卵而,上面两个技巧,作者并没有用到模型中,而是采用了上采样的技能。上采样中用到了插值的思想。作者解释道,一个因子为f的上采样就是一个步长大小为1/f的卷积。所以只要f为一个整数,上采样就进行一个输出stride为f的反卷积(实际上就是反转了卷积的前向和后向过程)。上采样是在网络内通过像素的损失反向传播进行end-to-end学习。反卷积滤波器的一个特点是尺寸不是固定,可以被学习的。
作者将ILSVRC分类器映射为FCN,并进行扩充,使其可以通过上采样和像素级的loss function进行dnese prediction。接下来,进行微调训练。在刚开始,提到过一个skip结构,这个个结构是进行end-to-end学习以细化输出的语义和空间精度(更精细的尺寸需要的网络层较少,将精细网络层和粗糙的网络层组合一起可以让model在考虑全局结构下进行局部预测)。
作者定义的网络结构如下:
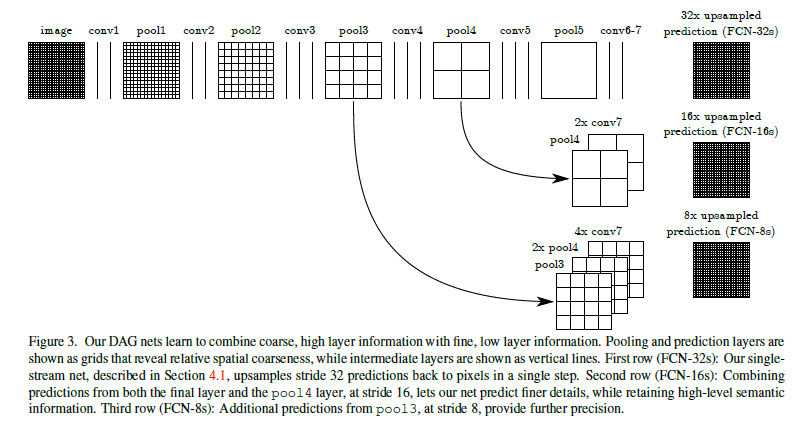
FCN的理论大体到此结束,有关网络结构的详细介绍会在代码中出现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号