
R2CNN项目部分代码学习
首先放出大佬的项目地址:https://github.com/yangxue0827/R2CNN_FPN_Tensorflow
那么从输入的数据开始吧,输入的数据要求为tfrecord格式的数据集,好在大佬在项目里已经给出了相应的代码,不过需要的原始数据为VOC格式,这里,我在以前的笔记里保存了普通图片+txt格式的原始数据生成VOC格式的数据集的代码(http://www.cnblogs.com/fourmi/p/8947342.html)。上述数据集生成后,就开始设置batch了,设置BatchSize为1,这里也被称为在线学习(https://blog.csdn.net/ycheng_sjtu/article/details/49804041),貌似收敛效果可能会有不好的影响,下面的是生成batch代码的解释。
def next_batch(dataset_name, batch_size, shortside_len, is_training):
if dataset_name not in ['tianchi', 'spacenet', 'pascal', 'coco']: raise ValueError('dataSet name must be in pascal or coco') if is_training: pattern = os.path.join('../data/tfrecords', dataset_name + '_train.tfrecord') else: pattern = os.path.join('../data/tfrecords', dataset_name + '_test.tfrecord') print('tfrecord path is -->', os.path.abspath(pattern)) filename_tensorlist = tf.train.match_filenames_once(pattern)#判断是否读取到文件 filename_queue = tf.train.string_input_producer(filename_tensorlist)#使用#tf.train.string_input_producer函数把我们需要的全部文件打包为一个tf#内部的queue类型,之后tf开文件就从这个queue中取目录了,要注意一#点的是这个函数的shuffle参数默认是True img_name, img, gtboxes_and_label, num_obs = read_and_prepocess_single_img(filename_queue, shortside_len, #这里对图像进行处理与变换从而进行数据增强 ,返回的是文件名,坐标及#标签,以及物体的个数。 is_training=is_training) img_name_batch, img_batch, gtboxes_and_label_batch, num_obs_batch = \ tf.train.batch( [img_name, img, gtboxes_and_label, num_obs], batch_size=batch_size, capacity=100, num_threads=16, dynamic_pad=True) return img_name_batch, img_batch, gtboxes_and_label_batch, num_obs_batch#这里产生batch,队列最大等待数为100,多线程处理
上述得到的坐标为(x0,y0,x1,y1,x2,y2,x3,y3),作者下面对其进行变换为(x_c,y_c,h,w),变换得到图像的中心及宽和高,使用的是opencv中的函数,
rect1 = cv2.minAreaRect(box) #得到最小矩形区域
这里有个有趣的函数,作用是将python用tensorflow进行封装
gtboxes_and_label = tf.py_func(back_forward_convert, inp=[tf.squeeze(gtboxes_and_label_batch, 0)], Tout=tf.float32) #tf.squeeze()这个是删除第0维的值
在此项目中R2CNN的网络部分主要包含三大结构与论文里的遥相呼应,分别为share-net,rpn,fast R-CNN。
首先聊一下share-net吧,放个代码感受一下。
_, share_net = get_network_byname(net_name=cfgs.NET_NAME, inputs=img_batch, num_classes=None, is_training=True, output_stride=None, global_pool=False, spatial_squeeze=False) #NET_NAME=resnet_v1_101
比较显然,这里使用的是resnet对数据进行特征提取,而论文里的是faster R-CNN,有关resnet_v1_101网络优化参数的调整都可以在config_res101.py这个文件中进行更改。而网络的结构的定义在resnet_v1.py文件中。这里显示的是其中resnet_v1_101网络的定义,还有其他的网络可以进行调用。
def resnet_v1_101(inputs, num_classes=None, is_training=True, global_pool=True, output_stride=None, spatial_squeeze=True, reuse=None, scope='resnet_v1_101'): """ResNet-101 model of [1]. See resnet_v1() for arg and return description.""" blocks = [ resnet_v1_block('block1', base_depth=64, num_units=3, stride=2), resnet_v1_block('block2', base_depth=128, num_units=4, stride=2), resnet_v1_block('block3', base_depth=256, num_units=23, stride=2), resnet_v1_block('block4', base_depth=512, num_units=3, stride=1), ] return resnet_v1(inputs, blocks, num_classes, is_training, global_pool=global_pool, output_stride=output_stride, include_root_block=True, spatial_squeeze=spatial_squeeze, reuse=reuse, scope=scope) resnet_v1_101.default_image_size = resnet_v1.default_image_size
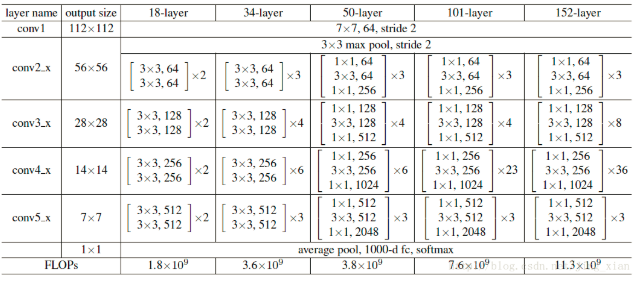
share-net代码对比resnet网络结构就比较清晰了,就这样,有种暴殄天物的赶脚。。。。
下面就说说rpn部分的代码了,rpn可以说是比较经典了,但个人学习深度学习比较短,还不能很好的理解,这里引入网上大佬们的博客,大家一起学习学习:https://blog.csdn.net/jiongnima/article/details/79781792,https://blog.csdn.net/happyflyy/article/details/54917514
# *********************************************************************************************** # * rpn * # *********************************************************************************************** rpn = build_rpn.RPN(net_name=cfgs.NET_NAME, inputs=img_batch, gtboxes_and_label=gtboxes_and_label_minAreaRectangle, is_training=True, share_head=cfgs.SHARE_HEAD,#是否将起初的share-net 传入,这里设置为false share_net=share_net,#传入的是resnet_v1_101 stride=cfgs.STRIDE,#STRIDE = [4, 8, 16, 32, 64] anchor_ratios=cfgs.ANCHOR_RATIOS,#ANCHOR_RATIOS = [1 / 3., 1., 3.0]
anchor_scales=cfgs.ANCHOR_SCALES,#ANCHOR_SCALES = [1.]
scale_factors=cfgs.SCALE_FACTORS,#SCALE_FACTORS = [10., 10., 5., 5., 5.]
base_anchor_size_list=cfgs.BASE_ANCHOR_SIZE_LIST, # P2, P3, P4, P5, P6 level=cfgs.LEVEL, top_k_nms=cfgs.RPN_TOP_K_NMS, rpn_nms_iou_threshold=cfgs.RPN_NMS_IOU_THRESHOLD,#0.7 max_proposals_num=cfgs.MAX_PROPOSAL_NUM, rpn_iou_positive_threshold=cfgs.RPN_IOU_POSITIVE_THRESHOLD, rpn_iou_negative_threshold=cfgs.RPN_IOU_NEGATIVE_THRESHOLD, # iou>=0.7 is positive box, iou< 0.3 is negative rpn_mini_batch_size=cfgs.RPN_MINIBATCH_SIZE, rpn_positives_ratio=cfgs.RPN_POSITIVE_RATE, remove_outside_anchors=False, # whether remove anchors outside rpn_weight_decay=cfgs.WEIGHT_DECAY[cfgs.NET_NAME]) rpn_proposals_boxes, rpn_proposals_scores = rpn.rpn_proposals() # rpn_score shape: [300, ] rpn_location_loss, rpn_classification_loss = rpn.rpn_losses() rpn_total_loss = rpn_classification_loss + rpn_location_loss
从rpn的代码直观上可以感觉到的是,主要包含三部分,一是RPN网络的搭建及初始化,二是proposals 的生成,及对应的文本/非文本分数值的计算,最后一个就是对应的loss函数的定义,这里loss函数包含两个一个是回归loss,另一个是分类loss。重点是proposals的生成,首先要产生anchors,本代码中有五个级别的anchors(32,64,128,256,512),首先建立特征金字塔,滑动窗口的位置选在从resnet_v1_101/block4,作为p5,然后进行一次池化操作,作为P6,然后,依次对resnet_v1_101,的block4,block3,block2,分别进行上采样-卷积-求加-卷积,依次形成相应的特征金字塔层,返回的是多个尺寸的feature_map(p2,p3,p4,p5,p6,其中p6是由p5最大池化后处理得到的)。针对金字塔的每一层即相对应的feature-map生成anchors,每层金字塔特定的feature-map上用到的anchor都有对应的大小((P2, 32), (P3, 64), (P4, 128), (P5, 256), (P6, 512)),生成anchors中有一个base_anchor ,还有一个anchor_scales,首先base_anchor根据anchor_scales进行大小的缩放,
然后,根据anchor_ratios的值进行长宽比的缩放,从而有多个anchor尺寸的选择。然后,将feature_map*步长会得到相应的中心点,由下列代码最终得到final_anchor
:return: anchors of shape [w * h * len(anchor_scales) * len(anchor_ratios), 4]
最终返回的生成的anchor的数量及格式可以看的很清楚。
nchors of shape [w * h * len(anchor_scales) * len(anchor_ratios), 4] # [y_center, x_center, h, w]
有了anchors后,接下来就是rpn网络的定义了,上代码如下:
def rpn_net(self): rpn_encode_boxes_list = [] rpn_scores_list = [] with tf.variable_scope('rpn_net'): with slim.arg_scope([slim.conv2d], weights_regularizer=slim.l2_regularizer(self.rpn_weight_decay)): for level in self.level: if self.share_head: reuse_flag = None if level == 'P2' else True scope_list = ['conv2d_3x3', 'rpn_classifier', 'rpn_regressor'] else: reuse_flag = None scope_list = ['conv2d_3x3_'+level, 'rpn_classifier_'+level, 'rpn_regressor_'+level] rpn_conv2d_3x3 = slim.conv2d(inputs=self.feature_pyramid[level], num_outputs=256, kernel_size=[3, 3], stride=1, scope=scope_list[0], reuse=reuse_flag) rpn_box_scores = slim.conv2d(rpn_conv2d_3x3, num_outputs=2 * self.num_of_anchors_per_location, kernel_size=[1, 1], stride=1, scope=scope_list[1], activation_fn=None, reuse=reuse_flag) rpn_encode_boxes = slim.conv2d(rpn_conv2d_3x3, num_outputs=4 * self.num_of_anchors_per_location, kernel_size=[1, 1], stride=1, scope=scope_list[2], activation_fn=None, reuse=reuse_flag) rpn_box_scores = tf.reshape(rpn_box_scores, [-1, 2]) rpn_encode_boxes = tf.reshape(rpn_encode_boxes, [-1, 4]) rpn_scores_list.append(rpn_box_scores) rpn_encode_boxes_list.append(rpn_encode_boxes) rpn_all_encode_boxes = tf.concat(rpn_encode_boxes_list, axis=0) rpn_all_boxes_scores = tf.concat(rpn_scores_list, axis=0) return rpn_all_encode_boxes, rpn_all_boxes_scores
”with tf.variable_scope('rpn_net'):“代表初始化,采用前面特征金子塔对应层级的基础上进行依次核大小为3*3的卷积操作得到rpn_conv2d_3x3,然后下面就开始出现分歧,一部分在此基础上进行分类操作(文本/非文本分数值),另一个进行回归操作(框四个坐标位置的预测),然后将分类和回归所有对应合并得到两个标准(分类,和回归)。这就是rpn网络的功能???!!然后更具scores返回最高的几个框,然后对这几个框根据IOU(大于0.7的视为不错)进行NMS处理,返回index,然后根据Index挑选框(优秀选手),返回proposals(优秀选手)及他们的scores(成绩)。PROPOSALS白活到这里,下面就是rpn的loss函数了。。。
rpn_loss代码定义。。。来吧。
def rpn_losses(self): with tf.variable_scope('rpn_losses'): minibatch_indices, minibatch_anchor_matched_gtboxes, object_mask, minibatch_labels_one_hot = \ self.make_minibatch(self.anchors) minibatch_anchors = tf.gather(self.anchors, minibatch_indices) minibatch_encode_boxes = tf.gather(self.rpn_encode_boxes, minibatch_indices) minibatch_boxes_scores = tf.gather(self.rpn_scores, minibatch_indices) # encode gtboxes minibatch_encode_gtboxes = encode_and_decode.encode_boxes(unencode_boxes=minibatch_anchor_matched_gtboxes, reference_boxes=minibatch_anchors, scale_factors=self.scale_factors) positive_anchors_in_img = draw_box_with_color(self.img_batch, minibatch_anchors * tf.expand_dims(object_mask, 1), text=tf.shape(tf.where(tf.equal(object_mask, 1.0)))[0]) negative_mask = tf.cast(tf.logical_not(tf.cast(object_mask, tf.bool)), tf.float32) negative_anchors_in_img = draw_box_with_color(self.img_batch, minibatch_anchors * tf.expand_dims(negative_mask, 1), text=tf.shape(tf.where(tf.equal(object_mask, 0.0)))[0]) minibatch_decode_boxes = encode_and_decode.decode_boxes(encode_boxes=minibatch_encode_boxes, reference_boxes=minibatch_anchors, scale_factors=self.scale_factors) tf.summary.image('/positive_anchors', positive_anchors_in_img) tf.summary.image('/negative_anchors', negative_anchors_in_img) top_k_scores, top_k_indices = tf.nn.top_k(minibatch_boxes_scores[:, 1], k=5) top_detections_in_img = draw_box_with_color(self.img_batch, tf.gather(minibatch_decode_boxes, top_k_indices), text=tf.shape(top_k_scores)[0]) tf.summary.image('/top_5', top_detections_in_img) # losses with tf.variable_scope('rpn_location_loss'): location_loss = losses.l1_smooth_losses(predict_boxes=minibatch_encode_boxes, gtboxes=minibatch_encode_gtboxes, object_weights=object_mask) slim.losses.add_loss(location_loss) # add smooth l1 loss to losses collection with tf.variable_scope('rpn_classification_loss'): classification_loss = slim.losses.softmax_cross_entropy(logits=minibatch_boxes_scores, onehot_labels=minibatch_labels_one_hot) return location_loss, classification_loss
由上面可以看出来,rpn_loss针对的是minibatch,那minibatch是个啥呢?在make_minibatch中调用了一句函数"rpn_find_positive_negative_samples",
#此函数的说明为: ''' assign anchors targets: object or background. :param anchors: [valid_num_of_anchors, 4]. use N to represent valid_num_of_anchors :return:labels. anchors_matched_gtboxes, object_mask labels shape is [N, ]. positive is 1, negative is 0, ignored is -1 anchor_matched_gtboxes. each anchor's gtbox(only positive box has gtbox)shape is [N, 4] object_mask. tf.float32. 1.0 represent box is object, 0.0 is others. shape is [N, ] '''
通过比较anchors和gtboxes比较计算出一个iou值,然后寻找每一行最大的iou值,将这个值与0.7比较,大于的为positivate,将每一列的最大值进行累加求和。
labels = tf.ones(shape=[tf.shape(anchors)[0], ], dtype=tf.float32) * (-1) # [N, ] # ignored is -1
positives2 = tf.reduce_sum(tf.cast(tf.equal(ious, max_iou_each_column), tf.float32), axis=1) positives = tf.logical_or(positives1, tf.cast(positives2, tf.bool)) labels += 2 * tf.cast(positives, tf.float32) # Now, positive is 1, ignored and background is -1
经过上述几句就可以将positivate 表示为1,其他情况表示为-1 ,这里看的不是很明白。。。labels=(-1,1)+2*(1,0)一一对应?
matchs = tf.cast(tf.argmax(ious, axis=1), tf.int32) anchors_matched_gtboxes = tf.gather(gtboxes, matchs) # [N, 4]
根据上述代码可以找到较好的matchs对应的groundtruth,寻找negative大同小异了,这里贴出代码,可以尝试比较一下。。
negatives = tf.less(max_iou_each_row, self.rpn_iou_negative_threshold) negatives = tf.logical_and(negatives, tf.greater_equal(max_iou_each_row, 0.1)) labels = labels + tf.cast(negatives, tf.float32) # [N, ] positive is >=1.0, negative is 0, ignored is -1.0 ''' Need to note: when opsitive, labels may >= 1.0. Because, when all the iou< 0.7, we set anchors having max iou each column as positive. these anchors may have iou < 0.3. In the begining, labels is [-1, -1, -1...-1] then anchors having iou<0.3 as well as are max iou each column will be +1.0. when decide negatives, because of iou<0.3, they add 1.0 again. So, the final result will be 2.0 So, when opsitive, labels may in [1.0, 2.0]. that is labels >=1.0 ''' positives = tf.cast(tf.greater_equal(labels, 1.0), tf.float32) ignored = tf.cast(tf.equal(labels, -1.0), tf.float32) * -1 labels = positives + ignored object_mask = tf.cast(positives, tf.float32) # 1.0 is object, 0.0 is others
# losses with tf.variable_scope('rpn_location_loss'): location_loss = losses.l1_smooth_losses(predict_boxes=minibatch_encode_boxes, gtboxes=minibatch_encode_gtboxes, object_weights=object_mask) slim.losses.add_loss(location_loss) # add smooth l1 loss to losses collection with tf.variable_scope('rpn_classification_loss'): classification_loss = slim.losses.softmax_cross_entropy(logits=minibatch_boxes_scores, onehot_labels=minibatch_labels_one_hot)
上述RPN部分代码介绍至此。。。。
接下来就是Fast R-CNN了,也就是最后一部分了。
# *********************************************************************************************** # * Fast RCNN * # *********************************************************************************************** fast_rcnn = build_fast_rcnn1.FastRCNN(feature_pyramid=rpn.feature_pyramid, rpn_proposals_boxes=rpn_proposals_boxes, rpn_proposals_scores=rpn_proposals_scores, img_shape=tf.shape(img_batch), roi_size=cfgs.ROI_SIZE, roi_pool_kernel_size=cfgs.ROI_POOL_KERNEL_SIZE, scale_factors=cfgs.SCALE_FACTORS, gtboxes_and_label=gtboxes_and_label, gtboxes_and_label_minAreaRectangle=gtboxes_and_label_minAreaRectangle, fast_rcnn_nms_iou_threshold=cfgs.FAST_RCNN_NMS_IOU_THRESHOLD, fast_rcnn_maximum_boxes_per_img=100, fast_rcnn_nms_max_boxes_per_class=cfgs.FAST_RCNN_NMS_MAX_BOXES_PER_CLASS, show_detections_score_threshold=cfgs.FINAL_SCORE_THRESHOLD, # show detections which score >= 0.6 num_classes=cfgs.CLASS_NUM, fast_rcnn_minibatch_size=cfgs.FAST_RCNN_MINIBATCH_SIZE, fast_rcnn_positives_ratio=cfgs.FAST_RCNN_POSITIVE_RATE, fast_rcnn_positives_iou_threshold=cfgs.FAST_RCNN_IOU_POSITIVE_THRESHOLD, # iou>0.5 is positive, iou<0.5 is negative use_dropout=cfgs.USE_DROPOUT, weight_decay=cfgs.WEIGHT_DECAY[cfgs.NET_NAME], is_training=True, level=cfgs.LEVEL) fast_rcnn_decode_boxes, fast_rcnn_score, num_of_objects, detection_category, \ fast_rcnn_decode_boxes_rotate, fast_rcnn_score_rotate, num_of_objects_rotate, detection_category_rotate = \ fast_rcnn.fast_rcnn_predict() fast_rcnn_location_loss, fast_rcnn_classification_loss, \ fast_rcnn_location_rotate_loss, fast_rcnn_classification_rotate_loss = fast_rcnn.fast_rcnn_loss() fast_rcnn_total_loss = fast_rcnn_location_loss + fast_rcnn_classification_loss + \ fast_rcnn_location_rotate_loss + fast_rcnn_classification_rotate_loss
首先看一下下面的代码,这个是fast R-CNN的定义。
def fast_rcnn_net(self): with tf.variable_scope('fast_rcnn_net'): with slim.arg_scope([slim.fully_connected], weights_regularizer=slim.l2_regularizer(self.weight_decay)): flatten_rois_features = slim.flatten(self.fast_rcnn_all_level_rois) net = slim.fully_connected(flatten_rois_features, 1024, scope='fc_1') if self.use_dropout: net = slim.dropout(net, keep_prob=0.5, is_training=self.is_training, scope='dropout') net = slim.fully_connected(net, 1024, scope='fc_2') fast_rcnn_scores = slim.fully_connected(net, self.num_classes + 1, activation_fn=None, scope='classifier') fast_rcnn_encode_boxes = slim.fully_connected(net, self.num_classes * 4, activation_fn=None, scope='regressor') if DEBUG: print_tensors(fast_rcnn_encode_boxes, 'fast_rcnn_encode_bxes') with tf.variable_scope('fast_rcnn_net_rotate'): with slim.arg_scope([slim.fully_connected], weights_regularizer=slim.l2_regularizer(self.weight_decay)): flatten_rois_features_rotate = slim.flatten(self.fast_rcnn_all_level_rois) net_rotate = slim.fully_connected(flatten_rois_features_rotate, 1024, scope='fc_1') if self.use_dropout: net_rotate = slim.dropout(net_rotate, keep_prob=0.5, is_training=self.is_training, scope='dropout') net_rotate = slim.fully_connected(net_rotate, 1024, scope='fc_2') fast_rcnn_scores_rotate = slim.fully_connected(net_rotate, self.num_classes + 1, activation_fn=None, scope='classifier') fast_rcnn_encode_boxes_rotate = slim.fully_connected(net_rotate, self.num_classes * 5, activation_fn=None, scope='regressor') return fast_rcnn_encode_boxes, fast_rcnn_scores, fast_rcnn_encode_boxes_rotate, fast_rcnn_scores_rotate
定义用到的是全连接层,注意这一句,
flatten_rois_features = slim.flatten(self.fast_rcnn_all_level_rois)
self.fast_rcnn_all_level_rois是为了从feature map 上 获得感兴趣区域。过程大体是首先是寻找对应层的rpn_proposals,然后提取出坐标,进行归一化处理后,根据处理后的坐标,从特征金字塔上提取相对应的区域feature map,然后经一个最大池化操作后得到。。。
self.fast_rcnn_encode_boxes, self.fast_rcnn_scores, \
self.fast_rcnn_encode_boxes_rotate, self.fast_rcnn_scores_rotate = self.fast_rcnn_net()
fast_rcnn_encode_boxes,fast_rcnn_scores都是由fast_rcnn_net得到的,是一个全连接的网络。根据上述得到的一些ROI区域的框及分数,可以得到fast R-CNN的proposals
def fast_rcnn_proposals_rotate(self, decode_boxes, scores): ''' mutilclass NMS :param decode_boxes: [N, num_classes*5] :param scores: [N, num_classes+1] :return: detection_boxes : [-1, 5] scores : [-1, ] ''' with tf.variable_scope('fast_rcnn_proposals'): category = tf.argmax(scores, axis=1) object_mask = tf.cast(tf.not_equal(category, 0), tf.float32) decode_boxes = decode_boxes * tf.expand_dims(object_mask, axis=1) # make background box is [0 0 0 0, 0] scores = scores * tf.expand_dims(object_mask, axis=1) decode_boxes = tf.reshape(decode_boxes, [-1, self.num_classes, 5]) # [N, num_classes, 5] decode_boxes_list = tf.unstack(decode_boxes, axis=1) score_list = tf.unstack(scores[:, 1:], axis=1) after_nms_boxes = [] after_nms_scores = [] category_list = [] for per_class_decode_boxes, per_class_scores in zip(decode_boxes_list, score_list): valid_indices = nms_rotate.nms_rotate(decode_boxes=per_class_decode_boxes, scores=per_class_scores, iou_threshold=self.fast_rcnn_nms_iou_threshold, max_output_size=self.fast_rcnn_nms_max_boxes_per_class, use_angle_condition=False, angle_threshold=15, use_gpu=cfgs.ROTATE_NMS_USE_GPU) after_nms_boxes.append(tf.gather(per_class_decode_boxes, valid_indices)) after_nms_scores.append(tf.gather(per_class_scores, valid_indices)) tmp_category = tf.gather(category, valid_indices) category_list.append(tmp_category) all_nms_boxes = tf.concat(after_nms_boxes, axis=0) all_nms_scores = tf.concat(after_nms_scores, axis=0) all_category = tf.concat(category_list, axis=0) all_nms_boxes = boxes_utils.clip_boxes_to_img_boundaries_five(all_nms_boxes, img_shape=self.img_shape) print('all_nms_boxes:',all_nms_boxes) scores_large_than_threshold_indices = \ tf.reshape(tf.where(tf.greater(all_nms_scores, self.show_detections_score_threshold)), [-1]) all_nms_boxes = tf.gather(all_nms_boxes, scores_large_than_threshold_indices) all_nms_scores = tf.gather(all_nms_scores, scores_large_than_threshold_indices) all_category = tf.gather(all_category, scores_large_than_threshold_indices) return all_nms_boxes, all_nms_scores, tf.shape(all_nms_boxes)[0], all_category
接下来就是定义loss函数,这里形式和rpn的大体相似。就不加赘述了。
fast_rcnn_total_loss = fast_rcnn_location_loss + fast_rcnn_classification_loss + \
fast_rcnn_location_rotate_loss + fast_rcnn_classification_rotate_loss
放出几张测试的结果图吧,不带数字的是标签,带数字的为预测的,分为不考虑角度的和考虑角度的两种。




至此,经过几天的折腾,算是完事了吧,通过阅读代码可以明白整个实现流程,对理清思路还是很有个帮助的,尤其是理解将论文具体应用的生活实践的过程是如何实现的很有用,但是自身水平极其有限,对这个大佬的代码好多细节不太明白,有点暴殄天物了,前方路途遥远,我们继续吧!!!
2018-04-29 09:44:21

 浙公网安备 33010602011771号
浙公网安备 33010602011771号