论文阅读笔记三:R2CNN:Rotational Region CNN for Orientation Robust Scene Text Detection(CVPR2017)
进行文本的检测的学习,开始使用的是ctpn网络,由于ctpn只能检测水平的文字,而对场景图片中倾斜的文本无法进行很好的检测,故将网络换为RRCNN(全称如题)。小白一枚,这里就将RRCNN的论文拿来拜读一下,也记录一下自己阅读过程中的收获。
原英文论文网址:https://arxiv.org/abs/1706.09579
在这篇论文中,作者提出了Rotational Region CNN(旋转区域CNN?),据作者说可以检测场景图片中任意角度的文本。这个网络是在Faster R-CNN的基础上搭建的。整个过程大体分为三部分,首先是作者使用RPN(Region Prposal Network)区域提议网络生成包围不同方向文本的轴对齐边界框。然后作者根据不同池化大小和连接特征提取出池化特征来同时预测文本/非文本的评分,轴对齐框和倾斜的最小区域框。最后,使用倾斜的非最大抑制(NMS)来获得结果。作者认为场景文本面临的挑战有:场景文本有不同的大小,宽高比,字体样式,光照,透视失真以及方向等。其中,方向信息对文本识别很重要,因此不同于普通的物体检测,除了预测出轴对齐框边界外还需要检测文本的方向。
传统的文本检测方法:基于滑窗或者是连接组件。目前是基于深度学习的方法,基于滑窗的方法是将多尺度窗口密集地移动通过图像,然后将候选框分为文本/非文本,连接组件基于生成字符候选。传统的文本检测方法是基于自下而上的策略(字符检测,文本行的构建以及文本行的分类)。
本文文本检测的流程:input images------>(RPN)产生包围文本的框(proposals)----------->分类proposals通过不同池化大小的池化特征以增强轴对齐框及倾斜最小区域框。------->用倾斜NMS后期处理检测候选框以获得最终的检测结果。
 (上图为过程图截取自论文)
(上图为过程图截取自论文)
前面作者提到过R2CNN是基于Faster-RCNN进行搭建的,那这里作者将Fast R-CNN修改为文本区域分类,强化和框位置坐标的预测,作者添加了一个小的anchor用于检测小场景文本。并用倾斜的NMS来检测候选框进行后处理。
作者认为方向任意的文本检测可以看作是一个多任务问题。解决方法的矛头要指向预测是否为文本的一个分数值,还有轴对齐框以及由RPN生成的proposals倾斜最小区域框的预测这三大魔头。。(⊙o⊙)?
为了覆盖更多的文本字符,作者对每一个proposal 用三种尺寸(7*7,11*3,3*11)的池化层进行ROIpoolings,提取的特征用于接下来的检测。
目标检测有依赖于RPN的(R-CNN,SPPnet,Fast R-CNN,Raster CNN R-FCN)也有直接估计候选对象的(SSD,YOLO)。
作者在Faster R-CNN中提出RPN,用于直接从卷积feature map 中生成高质量的proposals ,然后被改进用于Fast R-CNN进行分类。
作者在本文中提到了目前文本检测的深度学习的方法有:TextBoxes是一个具有单个深度神经网络的end to end 的快速场景文本检测器。DeepText通过Inception-RPN生成单词的proposals,然后文本检测网络对每个单词proposals 进行评分。FCRN(全卷机回归网络)利用合成图像训练场景文本检测模型,上述这些方法都是生成轴对齐框不能解决文本的方向问题。CTPN是检测固定宽度的垂直盒子,然后使用BLSTM捕获顺序信息,然后连接垂直盒子以获得最终检测框。CTPN擅长检测水平方向的文本,貌似相比RRCNN略有逊色啊,>o<..基于完全卷积网络用于文本检测的方法的过程为:一,文本块FCN的文本检测,二,基于MSER的多向文本行候选的生成,三,文本行候选的分类,RRPN(基于Faster R-CNN的旋转区域提议网络)与RPN遥相呼应,也被提出来检测任意方向的场景文本。RPN生成具有文本方向的倾斜proposals ,下面的分类和回归是基于这个倾斜proposals的。
另外,SegLink提出通过检测段落和连接来检测具有特定方向的文本,变态的是,SegLink貌似适用于任意长度的文本行。
EAST目标是在自然场景中产生快速准确的文本检测。DMPNet 设计用于检测四边形更紧密的文本。深度直接回归被用于多方向的场景文本检测。本文作者觉得RPN已经可以了,不需要生成倾斜的proposals(古语:杀鸡焉用宰牛刀?)
接下来前方高能,首先放图冷静一下, (恬不知耻的说明:图片从论文上抠的)
(恬不知耻的说明:图片从论文上抠的)
作者认为倾斜的框可以覆盖大部分文本区域,故将任意方向的场景文本检测任务近似为检测作者的方法中倾斜的最小区域矩形。
接下来的问题是倾斜的矩形该如何表示呢?常人首先能想到的就是角度了,但随后就被作者否定了,是因为角度目标在某些特殊点中是不稳定的。。。作者还举了个栗子--旋转90度的矩形和-90度的矩形是极其相似的。很显然的是他们的角度天壤之别,直接后果是使网络很难学习和检测 垂直文本。作者机智的提出了用顺时针方向的前两个点的坐标和边界框的高度来表示倾斜的矩形。大体是下面图(来源我就不说了。。)那个样子的。
 RPN大体如上,接下来就唠唠RRCNN吧,作者采用了两阶段的物体检测策略,包括proposals 及其分类。RRCNN基于faster R-CNN。
RPN大体如上,接下来就唠唠RRCNN吧,作者采用了两阶段的物体检测策略,包括proposals 及其分类。RRCNN基于faster R-CNN。
首先RPN生成文本proposals,包含面向任意文本的轴对齐边界框。然后对每个proposal,对卷积的feature map 执行不同尺寸大小(7*7,11*3,3*11)的池化操作,并将特征级联从能用于接下来的分类与回归。通过连接的特征和全连接层,可以预测文本/非文本的分数,轴对齐框和倾斜最小区域框,最后,对倾斜的框进行NMS处理从而得到检测结果。
前面也提到了作者是用RPN生成的轴对齐框,这个框可以包围任意方向文本,那它可行的原因是什么呢?作者从产生的轴对齐框中的文本方面进行了分析,框内的文本要么处于水平方向的,要么处于垂直方向的,要不然就是处于对角线方向。面对小场景文字,作者在RPN中利用较小的anchor比例来处理,采用两种策略一个是将anchor比例改为小尺寸,并增加anchor的规模和使用,采用小尺寸的anchor有助于场景文本检测。作者在RPN的 anchor纵横比,正负样本的定义等设置的和faster R-CNN相同。
faster R-CNN在每个RPN proposal 上通过大小为7*7的池化层在对应的feature map 上进行ROIpooling。接下来遇到一个很明显的问题那就是
一些文本的宽度比他们的高度是大得多的,作者尝试使用三种不同大小的ROIpooling来捕捉更多的文本特征。将这些feature 连接在一起以便进一步的检测。作者增加了11*3和3*11尺寸的pooling,其中,3* 11的可以捕捉更多水平方向的特征,而11*3的相对应的可以捕捉更多垂直方向的文本特征。
下面给出的是一些类似于评价标准的东西,文本/非文本分数的回归,轴对齐框及倾斜最小区域框的回归。在RPN之后,将其生成的proposal 分为文本/非文本,增强包含任意方向的轴对齐框并预测倾斜边界框。每个倾斜的框都有个相关的轴对齐的框,这里作者认为相对于倾斜框,轴对齐框相当于额外约束可以提高性能,事实如此。
下面说说NMS,NMS(非最大抑制)广泛用于通过当前目标检测的方法对检测候选框进行后处理。在估计轴对齐边界框和倾斜边界框是,可以在轴对齐框上执行常规NMS,也可以在倾斜边界框上执行倾斜NMS。在倾斜的计算下,IOU的计算被修改为两个倾斜边界的IOU。
Loss函数:
作者说了,RPN的training loss 和faster R-CNN的相同。只介绍RRCNN有RPN生成的轴对齐框的损失函数。定义为文本/非文本的分类loss和框回归loss.回归loss包含两个部分,包含任意方向的文本的轴对齐框,和倾斜最小区域框。形式如下,晕。。。。
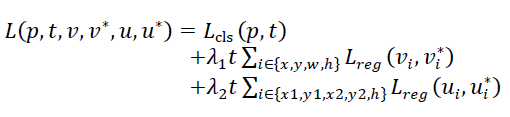 文本标记为1,背景标记为0,p={p0,p1}代表由softmax 计算出的文本和背景类别的概率。Lcls(p,t)=-logpt是真实类别的对数损失。v=(vx,vy,vw,vh),是包含中心点坐标及其宽度和高度的真正轴对齐边界框回归的目标元组,v*为对应的标签,u,u*依次对应倾斜的框。Lreg如下:
文本标记为1,背景标记为0,p={p0,p1}代表由softmax 计算出的文本和背景类别的概率。Lcls(p,t)=-logpt是真实类别的对数损失。v=(vx,vy,vw,vh),是包含中心点坐标及其宽度和高度的真正轴对齐边界框回归的目标元组,v*为对应的标签,u,u*依次对应倾斜的框。Lreg如下:
 RRCNN的理论介绍就到此结束,下面给出一位中科院大佬的github项目进行实践分析学习。
RRCNN的理论介绍就到此结束,下面给出一位中科院大佬的github项目进行实践分析学习。
GitHub网址:https://github.com/yangxue0827/R2CNN_FPN_Tensorflow
2018-04-2516:28:54

 浙公网安备 33010602011771号
浙公网安备 33010602011771号