论文阅读笔记二-ImageNet Classification with Deep Convolutional Neural Networks
分类的数据大小:1.2million 张,包括1000个类别。
网络结构:60million个参数,650,000个神经元。网络由5层卷积层,其中由最大值池化层和三个1000输出的(与图片的类别数相同)全链接层组成。
选用非饱和神经元和高性能的GPU来增强卷积操作。为防止在全链接层发生过拟合,我们进行规则化 'dropout'操作,效果明显。
1.说明:
通过改变卷积神经网络的深度和宽度可以控制网络自身的容量。卷积网络可以更准确的预测图片的本质(图像统计上的不变性和像素级的局部性)。
相比具有相似尺寸网络层数的标准前馈神经网路,卷积神经网络有更少的参数和链接。所以更容易进行训练。然而理论上卷积网络的最好性能可能表现的有些差。
尽管,卷积网络具有相对高效的局部结构。但针对大规模的高分辨率图像上的应用消耗仍然是巨大的。GPU和配合高度优化的2维卷积网络能够促进密集型卷积神经网络的训练。
神经网络的大小主要取决于目前GPU的存储能力和,训练的时间,此文中的网络还可以继续进行优化在由更好的GPU或者是获得更大的数据进行训练的情况下。
2.数据:
ImageNet 有超过15million张,2,2000个类别已标记的高分辨率的图片。ILSVRCL(1.2 million training images, 50,000 validation images, and 150,000 testing images.)
在ImageNet 通常报告两个错误率标准。top-1和top-5,其中,top-5是在测试图片中预测正确标签但不在由模型确定的最有可能的5个类别中的分数。
ImageNet中有可变分辨率的图像,然而本文中的网络要求固定维度的图像输入,因此,通过进行下采样得到固定分辨率(256*256)的图像。
我们只对像素进行减去平均值处理。
3.网络的结构:
总共包括8个层:5个卷积层和3个全链接层。
*****(重要度)3.1ReLU 非线性处理
模型化神经元输出的标准方式是通过以下等式:

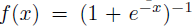
针对训练时间随着梯度下降,上述的饱和非线性化比非饱和的(![]() )训练时间要慢很多。使用传统的饱和神经元模型,无法对大型神经网络进行实验。
)训练时间要慢很多。使用传统的饱和神经元模型,无法对大型神经网络进行实验。
不同的数据类型对神经元的激活函数的选取也不同,同时考虑防止过拟合,更快的学习针对大规模的训练数据具有很好的效果。独立的选则神经网络的率使
训练尽可能的快。ReLU的神经元比饱和的神经元经过一系列的迭代后学习的更快。
*****3.2多GPU训练
1.2million个训练样本足够训练一个网络,但对一个GPU来说十分吃力。因此,将一个网络分布在两块GPU上,由于当前GPU可以直接的进行读和写操作,不需要通过主机内存。本文将一半的神经元放在每一块GPU上。GPU只在确定层上进行通讯。也就是说,第三层的神经元从第二层神经元的映射获得输入,而第四层神经元获得的输入只能从处于同一块GPU上的第三层的部分获得。选择GPU之间的沟通模式是一个问题,但是这可以让我们调整链接数量直至达到我们可接受的数量。在最后一个卷积层上单GPU的参数个数与双GPU的相同,因为网络的大部分参数都在全连接层,为了让两个网络有大致相同的参数,所以对最后一层卷积层没有进行减半处理。因此这个网络更实用于单GPU,因为他比双GPU的一半要大。
***3.3局部响应标准化
ReLU有一个很好的特性就是不需要标准化的输入来防止自身趋于饱和。如果一些训练样本为RELU神经元提供了正响应,则将会在此神经元处进行学习。然而一些局部标准化措施有助于普遍化。
局部响应标准化输出公式:

n为在相同位置遍历n个相邻的核的求和。N为这一层的所有神经元的个数。神经元映射的顺序是随意的,但在训练之前被确定,这种程度的响应归一化是被实际神经元执行抑制剂激发的灵感。用不同的神经元进行计算产生大的活动间的竞争。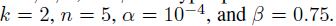 这几个隐含参数是事先确定的。
这几个隐含参数是事先确定的。
**3.4重叠的池化层
卷积神经网络中的池化层汇总具有相同内核映射的神经元组的输出。传统上,由相邻池化单元汇总的邻域是不重叠的。更确切的说,一个池化层可以被认为由一个单位间隔s个像素的池化网格组成,每个被汇总的大小为z*z的邻域以池化层结点为中心。如果令s=z我们会获得CNN中传统的局部池化层,若令s<z我们会获得重叠池化层。本文神经网络中使用的为重叠池化层。(令s=2,z=3),同时使用重叠池化层更不容易发生过拟合。
*3.5整体结构

描述:带有权重的8层神经网络。前5层为卷积层,后3层为全连接层。最后一层的全链接层的输出被送到softmax,被分配为1000个类别标签。
我们的网络最大化多项式逻辑回归目标,相当于最大化了训练样本中预测分布下的对书概率的正确标签的平均值。第二层,第四层,第五层卷积层的核只链接那些在同一个GPU的前一层。第三层卷积层是链接到第二层的所有核映射。响应标准化层在第一和第二卷积层。最大池化层在响应标准化层和第五个卷积层呢个之后。RELU应用在每个卷积层呢个和全链接层。
第一层卷积滤波是224*224*3的输入图像和96个大小为11*11*3,步间距为4个像素。第二层卷积将第一层的输出作为输入同时用256个大小为5*5*48的卷积核进行滤波,第三四五层卷积之间直接链接没有池化层和响应标准化层的干预。第三层含有384个大小为3*3*256的核与第二层卷积的输出。第四个卷积层呢个有384个3*3*192大小的卷积核。第五个卷积层有256个大小为3*3*192的卷积核,每个全链接层有4096个神经元。
4降低过拟合
4.1数据增强
最常用的数据增强是使用标签保留转换。我们采用两种不同的形式的数据增强,这两者都允许从原始图像生成变换后的图像,图像的计算量非常小,所以转换后的图像不需要存储在磁盘上。在我们的实现中,转换后的图像是在CPU上的Python代码中生成的,而GPU正在训练上一批图像。 所以这些数据增强方案实际上是计算方便的。
第一种形式的数据增强是包括生成图像翻译和水平映射。我们从大小256*256的图像上随即提取224*224的像素块,进行训练。这些样本具有高度的关联性,若没有这些,网络会产生较强的过拟合。在进行测试时我们的网络通过对提取的5个(四个角加一个中心)大小为224*224像素块及其水平映射(共10个像素块的特征),并对softmax在这10个像素块上做出的预测取平均。
数据增强的第二种形式包括改变RGB通道的强度训练图像。 具体来说,我们在整个RGB像素值集上(即ImageNet训练集)进行PCA降维。 对于每个训练图像,我们添加多个找到的其主成分,这就是图2中的输入图像为224×224×3维的原因。大小与相应的特征值成比例,乘以一个随机变量具有平均零和标准偏差0.1的高斯值。
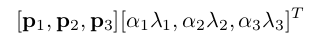
针对特定训练图像的所有像素每个αi只绘制一次,直到该图像再次用于训练,该点会重新绘制。 该方案大致捕捉了自然图像的重要属性,即对象身份对于照明的强度和颜色的变化是不变的。 这个措施将top-1的错误率降低1%以上。
4.2 Dropout
用不同的模型进行联合预测是一个很有效的措施但是花费巨大,但dropout是一个让花费减半的模型联合预测的有效版本,他让每个神经元有0.5的概率失活,被drop-out 的神经元对前馈和反馈过程都不起作用。所以每次提交输入时,神经网络都会采样不同的体系结构,但是所有这些架构都具有相同的权重 这种技术减少了神经元的复杂适应,
因为神经元不能依赖特定其他神经元的存在。 因此,它被迫学习更强大的功能,这些功能可以与许多不同的随机子集结合使用其他神经元。 在测试时间,我们使用所有的神经元,但它们的输出乘以0.5,这是一个合理地近似得到由多指数的dropout网产生的预测分布的几何平均数。
我们在图2的前两个完全连接层中使用了dropout。没有dropout,网络表现出较强的过拟合。 同时dropout要达到收敛需要双倍的迭代次数。
5 学习策略
我们采用一批为128个样本,动量为0.9的随机梯度下降方法进行学习,权重衰减为0.0005,权重衰减不仅是一个正则化值同时减少模型的训练错误。
权重的更新公式为:
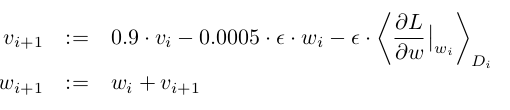

我们用标准偏差为0.01的零均值高斯分布初始化各层的权重。 我们初始化了第二,第四和第五卷积层以及在完全连接的隐藏层中中的神经元偏差为常数1.这种初始化会加速
通过向ReLU提供积极的投入来学习的早期阶段。 我们用0初始化剩余网络层的神经元。
我们对所有图层使用相同的学习率,我们在整个训练过程中手动进行了调整。我们遵循的启发式是在验证错误时将学习速率除以10
直到验证错误率停止改善。 学习率初始化为0.01,在终止前减少三次。 我们通过网络训练了大约90个周期的网络训练120万张图片,这两张图片在两台NVIDIA GTX 580 3GB GPU上花费了五到六天时间。
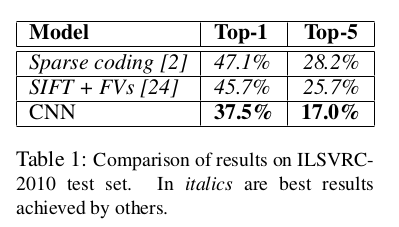
6结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号