论文阅读笔记六十六:Wide Activation for Efficient and Accurate Image Super-Resolution(CVPR2018)

论文原址:https://arxiv.org/abs/1808.08718
代码:https://github.com/JiahuiYu/wdsr_ntire2018
摘要
本文证明在SISR中在ReLU之前特征图越宽,在有效的计算资源及内存条件下,模型的性能越好。本文提出的残差网络具有平滑的identity mapping pathway,在激活层之前,每个block含有2x,4x多的通道数。为了进行6x,9x的增宽,本文将低等级的卷积引入到超分辨网络中。对比有BN层无BN层,本文发现对权重正则化会得到更好的结果。本文提出的超分辨网络在DIV2K数据集上取得较好的成绩。
介绍
以前的超分辨网络包括,SRCNN,FSRCNN,ESPCN利用相对较浅层的卷积网络(其网络层数一般为3至5),相比后来提出的深度SR网络(VDSR,SRResNet及EDSR等)以前的网络准确率上稍差一些。网络层数的增加使模型的表征能力更强。但是,同时,对底层的特征的利用效不是很充分。针对这种问题,SRDenseNet,RDN,MemNet等在低层及深层网络层之间引入了多种跳跃连接及拼接操作,对超分辨率的模型进行形式化处理。
本文从不同的方向解决上述问题。本文并未增加多种短连接,将网络低层次的ReLU编码的非线性的信息传递到更深的网络层中。基于残差SR网络,本文证实了通过简单的增加ReLU层前的特征可以有效的提高SISR模型的性能,甚至超过包含复杂的跳跃连接及拼接操作的网络模型。本文的创新点在于增宽ReLU前的特征,使更多的信息可以被传递到后面的网络层,从而进行密集的像素值预测。
这里存在一个问题,如何对ReLU前面的激活层有效的扩宽,在实际生活中,增加过多的参数会使超分辨变得十分的低效。本文首先引入了SR 残差网络WDSR-A,该结构在每个残差block的激活层之前都有一个更多通道数(x2,x4)的 identity mapping pathwey。但当通道数扩张率到达4之后,identity mapping pathway的通道数需要进一步的slimmed,这十分有损于准确率。因此,第二步,本文固定identity mapping pathway的通道数并寻找更有效的方式来扩张通道数。本文考虑了group conv及可分离卷积,但发现二者对于超分辨的性能表现的并不是很好。最终,提出线性low-rank卷积将一个较大的卷积分解为两个较低级的卷积。利用更宽的激活及low-rank卷积,本文构建了SR网络WDSR-B.其激活层更宽,但参数及计算量并不是增加很多。
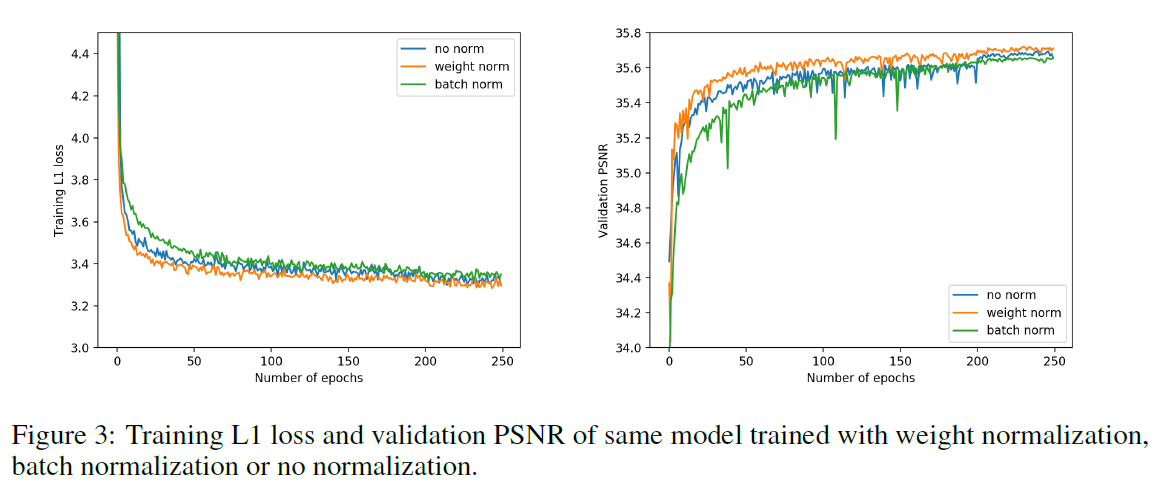
比较有BN及无BN,本文发现对于较深的超分辨网络,带有权重正则化的效果会好一些。EDSR,BTSRN,RDN认为BN层会对超分辨的准确率造成不利的影响,这里被我们实验所证实,本文提出了三个创新点,并进行了有关BN的实验(1)mini-batch 依赖性。(2)训练测试时不同的形式(3)训练时,正则化对SR网络并不合适。随着SR网络层数的增加,没有BN的模型训练起来比较困难。为此引入了权重正则化用于训练较深的SR网络。加了BN层可以使用较大的学习率,从而可以更快的收敛及得到更好的性能。
总结如下:I. 证实了在SISR模型中激活层前更宽的特征其性能更好。提出了宽度2x,4x的WDSR-A模型 II. 利用线性 low-rank卷积作为SR的基本构件在不增加额外计算量的前提下来提升效率及准确率。III. 证实BN不适用于训练深度SR网络,因此引入了权重正则化,使模型收敛的更快。
本文方法
宽激活层:WDSR-A
这部分主要讨论如何在不增加计算量的基础上拓宽ReLU层特征通道。一种简单的方法使增加特征通道数,但这种方法什么也说明不了,只能证明更多的参数有利于提高模型的性能。该部分作者自己设计SR网络研究在参数及计算量相同的情况下增加feature 的宽度对模型性能的影响。本文采用了较为简单的做法,如下图所示。
 在基准WDSR网络模型中研究,两层的残差blocks。假设identy mapping pathway的通道数为w1,而激活层前,内部残差块的通道数为w2,这里引入了扩张因子r,因此,w2 = r x w1,在常规残差块中w2 = w1,每个残差块的参数量为2xw1^2xk^2。当固定输入尺寸时,计算量是关于参数量的一个常熟,为了使其复杂度相同,
在基准WDSR网络模型中研究,两层的残差blocks。假设identy mapping pathway的通道数为w1,而激活层前,内部残差块的通道数为w2,这里引入了扩张因子r,因此,w2 = r x w1,在常规残差块中w2 = w1,每个残差块的参数量为2xw1^2xk^2。当固定输入尺寸时,计算量是关于参数量的一个常熟,为了使其复杂度相同,![]() ,参超identity mapping pathway 需要进行压缩,系数为
,参超identity mapping pathway 需要进行压缩,系数为![]() ,同时,激活层可以扩张至
,同时,激活层可以扩张至![]() 倍。本文在WDSR-A中实验发现,当r为2至4时,上述方案有效。当r超过这个范围时,性能会很快的下降。这是由于,identity mapping pathway变得过于细。比如,EDSR(包含16个残差blocks,通道数为64)当r超过6时,w1相对于最终的HR图像表示空间
倍。本文在WDSR-A中实验发现,当r为2至4时,上述方案有效。当r超过这个范围时,性能会很快的下降。这是由于,identity mapping pathway变得过于细。比如,EDSR(包含16个残差blocks,通道数为64)当r超过6时,w1相对于最终的HR图像表示空间![]() 小很多,其中S代表缩放尺寸,3代表RGB。因此,本文研究卷积核的参数有效性来进一步提升准确率及性能。
小很多,其中S代表缩放尺寸,3代表RGB。因此,本文研究卷积核的参数有效性来进一步提升准确率及性能。
更宽的激活层:WDSR-B
为了解决上述问题,本文固定identity mapping pathway的通道数,同时研究更多扩张特征的有效方法。首先考虑的是1x1的卷积,该卷积被广泛的应用于通道的扩张及压缩。在WDSR-B模型中,本文首先将通道数通过1x1的进行扩增,并在卷积层后增加一个ReLU进行非线性处理。后来又提出了一种高效的low-rank卷积将较大的卷积核分解为两个下级卷积,及一个1x1的卷积用于减少通道数外加一个3x3的卷积进行空间级别的特征提取。本文发现在线性low-rank后增加ReLU激活会减少准确性。
Weight Normalization vs Batch Normalization
Batch Normalization: BN 对中间的特征的均值及方差进行重新校准。从而解决internal covariate shift的问题即样本分布在训练过程中发生变化。BN在训练及测试时的表达式时不同的,这里忽略了BN中re-scaling 及re-centering可学习参数。在训练时,每层特征根据当前训练的Mini-batch的均值及方差进行归一化处理。

其一二阶统计信息以移动平均的方式更新到全局统计信息中,![]() 代表使用移动平均。
代表使用移动平均。

在进行inference时,利用全局信息来归一化特征。分析BN的表达式可以看出来其存在的问题: (1)对于图像超分辨,只有较小分辨率的image patch及小的mini-batch size用于加速训练,其均值及方差会比较大,使统计信息并不稳定。(2)BN可以被看作是正则化的一种,有时甚至可以替代Dropout,但在超分辨模型中很少出现过拟合现象。因此,权重衰减,Dropout等并未存在在SR模型中。(3)不同于分类任务。网络的最后一层是softmax(尺寸不变性)用于预测,而SR模型中不同的训练及测试形式会影响密集像素值预测的准确率。
Weight Normalization: 该方法对网络中的权重进行在参数化,在mini-batch的样本中,并未引入依赖性,其训练及测试的形式是一样的,假设输出y形式如下
![]()
其中,w为k维度的权重向量,b为偏差,x为k维输入特征,WN按如下形式进行对权重向量重新进行处理。

v为k维向量,g代表一个比例数。||v||代表v的欧几里得范数。因此可以使![]() ,使其独立于参数v。其参数长度及方向上的消除可以有效的加速网络模型的收敛。对于超分辨模型,并不会存在上述BN存在的问题,同时引入了权重正则化,可以设置更大的准确率,加速模型的收敛。
,使其独立于参数v。其参数长度及方向上的消除可以有效的加速网络模型的收敛。对于超分辨模型,并不会存在上述BN存在的问题,同时引入了权重正则化,可以设置更大的准确率,加速模型的收敛。
网络结构
结构如下,本文基于EDSR超分辨网络进行了两方面的改进。

I. Global residual pathway:首先发现这个东西是由一系列卷积层堆成的,十分吃计算。本文认为这个东西是冗余的,可以将其插入到残差分支上。因此,本文只使用了5x5的单层卷积网络层直接处理3xHxW的LR RGB 图像或者patch作为输入,同时输出3S^2XHXW的HR图像。S代表放大系数。这样大量减少了参数及计算量。
II.上采样层:不同于在上采样后插入一个或多个卷积层,本文提出的WDSR模型提取低分辨率阶段的所有特征,本文实验发现该做法不仅没有损害准确率,而且大幅度的提高了收敛速度。
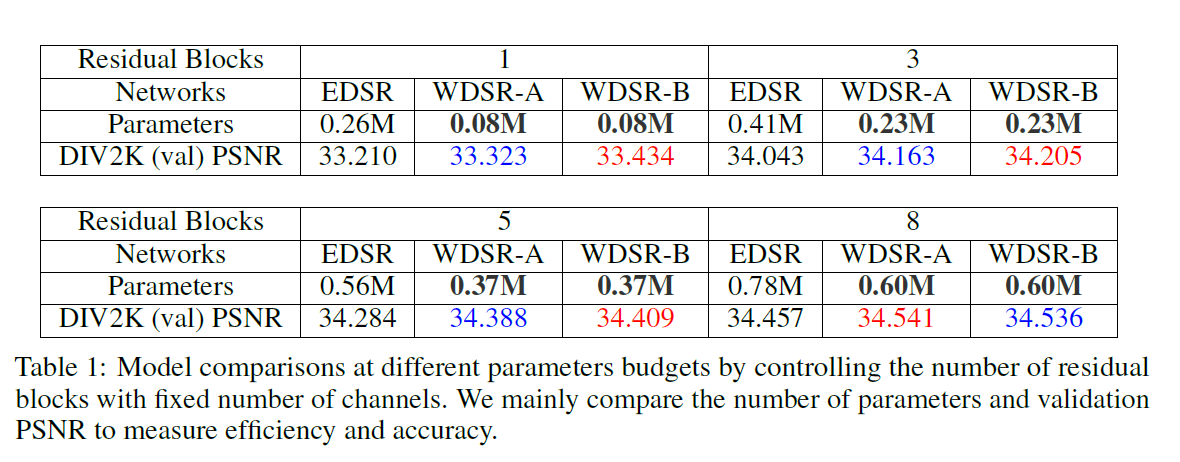
实验


 浙公网安备 33010602011771号
浙公网安备 33010602011771号