论文阅读笔记五十六:(ExtremeNet)Bottom-up Object Detection by Grouping Extreme and Center Points(CVPR2019)

论文原址:https://arxiv.org/abs/1901.08043
github: https://github.com/xingyizhou/ExtremeNet
摘要
本文利用一个关键点检测网络来检测目标物的最左边,最右边,顶部,底部及目标物中心五个点。如果这几个点在几何空间上对齐,则生成一个边界框。目标检测进而演变为基于外形的关键点检测问题,不需要进行区域分类及复杂的特征学习。
介绍
Top-Down方法占据目标检测中的主要地位,一些流行的目标检测算法通过直接裁剪区域或者特征,或者设置一些固定尺寸的anchor得到一些方形区域,然后,基于这些方形区域进行分类。top-down的方式也是存在一定限制的,一个方形框并不能很好的表示目标物的外形。许多目标并不是轴对齐的,如果将目标放入框中,则会包含大量干扰的背景像素。如下图所示

Top-Down方法列举了大量可能存在位置的边框,而没有真正理解目标物的视觉成分,这个过程十分占用计算量。用边界框来定位目标不是一个好方法,因为他得到的目标的细节信息很少。比如目标物的形状及位置等。
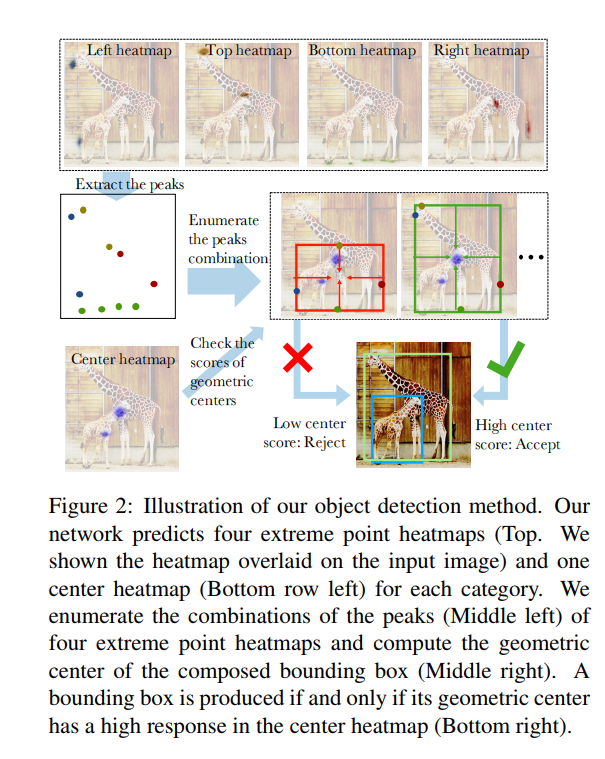
本文提出bottom-up的目标检测框架-ExtremeNet,用于检测目标物的四个极点。利用一个关键点检测网络,针对每个类别预测四个multi-peak heatmaps进而得到极点。对于每个类别又增加了一个heatmap用于预测目标的中心,其heatmap值为边框x,y方向的均值。然后基于纯几何的方法对extreme点进行组合。从每个map中得到一个点,得到四个extreme points,如果由这四个点决定产生的中心点对应的center map中的位置的值大于一个预定义的阈值,则将这四个点进行组合。本文详细罗列了O(n^4)个预测点的组合,并选择其中有效的组合方式。其中,n的设置十分小,对于COCO在GPU上的设置,一般取n<40就足够,下图为方法的大致流程。
CornerNet预测一组相对的点,然后基于嵌入式特征对这些点进行组合。本文与CornerNet存在两点不同:(1)关键点的定义(2)组合方式,角点是边界框的另一种表现形式,在top-down检测中会遇到很多问题,角点可能会经常落在没有较强特征目标物的外界。而另一方面,极点位于视觉可分,并具备连续性局部外形特征的目标物上。如最顶部的点极有可能落在人类的头部位置,车或者飞机的底部的点大概率会在轮子处。这使得极点的检测更加简单。另一点不同的是,CornerNet基于几何的方式进行组合,检测框架完全依赖于外形特征,并不进行复杂的特征学习,实验发现,基于外形特征的组合方式效果更好。
Extreme Points相比边界框,可以提供更丰富的信息,同时,extreme points也与目标物的mask有着紧密的联系。相比边界框,extreme points更好的预测目标物的mask。
Preliminaries
Extreme and center points:![]() 代表边界框的四条边,为了标记一个框,点击左上角的点
代表边界框的四条边,为了标记一个框,点击左上角的点![]() 及右下角的点
及右下角的点![]() ,通常这些点会位于目标物的外接,不太准确,进行调整也需要花费时间,平均下来需要花费34.5s。有人提出只标记四个极点,
,通常这些点会位于目标物的外接,不太准确,进行调整也需要花费时间,平均下来需要花费34.5s。有人提出只标记四个极点,![]() 构成的边界框为
构成的边界框为![]() ,极点(x(a),y(a))是指在a(top,left,right,bottom)方向上没有其他点位于目标物上,这种方式产生的annotation的时间平均为7.2s。本文额外利用目标物的中心点
,极点(x(a),y(a))是指在a(top,left,right,bottom)方向上没有其他点位于目标物上,这种方式产生的annotation的时间平均为7.2s。本文额外利用目标物的中心点![]() 。
。
关键点检测利用一组全卷积的编码-解码结构针对不同类型的关键点进行预测得到一个多通道的heatmap,基于L2 损失或者Gaussian map进行一个全监督的训练。state of the art 的关键点检测模型为Hourglass 网络。对于每个通道回归得到一个大小为H,W的heatmap,训练由一个多峰值的heatmap驱动,每个关键点定义高斯核的均值,其标准差设置为固定值或者根据目标大小进行调整。在L2损失情形下,高斯heatmap可以被看作为一个回归目标,在逻辑回归中,可以看作是在positive 位置附近减少惩罚的weight map。
CornerNet:基于Hourglass Network作为backbone用于目标检测。其预测两个heatmap用于获得边界框的对角点。为了平衡正负样本的比例,设置如下训练损失。

为了提高极点子像素的精度,CornerNet对于每个角点增加了一个类别无关的偏移回归![]() ,用于恢复在hourglass下采样过程中损失的信息。此offset map基于smooth L1损失进行训练,然后基于embeding对角点进行组合。ExtremeNet采用了CornerNet的损失及结构的思想。
,用于恢复在hourglass下采样过程中损失的信息。此offset map基于smooth L1损失进行训练,然后基于embeding对角点进行组合。ExtremeNet采用了CornerNet的损失及结构的思想。

ExtremeNet for Object detection:ExtremeNet基于HourglassNetwork针对每个类别预测五个heatmaps。本文参考CornerNet的训练初始化,损失及偏移预测,offset的预测是于与类别无关的,而四个极点的heatmap是类别明确的。center heatmap中不存在offset prediction.本文输出5XC的heatmaps及4x2的heatmaps用于预测offset。整体流程如下图所示,在得到四个极点后,完全基于几何原理对其进行组合。

Center Grouping:极点位于目标物的不同边上,这增加了组合的复杂度,associative embeding无法基于全局对关键点进行组合。
组合算法的输入为每个类别的5个heatmaps。一个center map及4个heatmaps。对于每个heatmap通过检测每个峰点得到其相应的关键点。峰点是像素点位置大于tp,同时是3x3像素中的局部最大点的像素,这个过程称为extractPeak。
分别从四个heatmaps中得到对应的极点,t,b,r,l,计算其中心点的位置为![]() ,若该点所对应centermap中具有一个较高的相应(大于一定阈值tc),则将此四个极点定义为一个有效检测。本文以粗鲁的方式将所有关键点组合进行罗列(复杂读为O(n^4,n为每个坐标方向上提取的极点个数))。算法流程如下,
,若该点所对应centermap中具有一个较高的相应(大于一定阈值tc),则将此四个极点定义为一个有效检测。本文以粗鲁的方式将所有关键点组合进行罗列(复杂读为O(n^4,n为每个坐标方向上提取的极点个数))。算法流程如下,

Ghost box suppression:对于共线的同样大小的目标物,Extremenet可能会得到一个confidence较高的假阳性检测结果。对于中间的目标存在两种情形:要么产生一个小的边界框,要么得到一个相对较大的边框将相邻目标的极点也包含在内。将这戏额fasle-positive检测框成为ghost box。这种框不多,但是在组合过程中固定存在。
本文增加了一个后处理的方法,提出了一个类似于soft NMS的方法进行处理。“ghost box”中包含许多其他的小的检测,如果包含的框的分的和超过其自身的3倍,则将概况的分数除以2。该方法只是对潜在的"Ghost"box进行的惩罚。
Edge aggregation: 极点的定义不是固定的,如果目标物边界边缘构成极点,则该边的任意一个点都可以看作是极点。因此,本文对目标物的对齐边界产生一个较弱的相应,而不是强峰值响应。但这种弱相应存在两个问题:第一:较弱的相应其值可能会低于峰值阈值,因此该极点可能会被忽略。第二:即使检测到了一个极点,其分数仍可能会比具有强响应的旋转对象的分数低。本文采用edge aggregation解决上述问题。
对于提取出局部最大点的极点,将其水平方向及垂直方向极点的分数进行聚合。将所有分数单调递减的极点进行聚合。当在聚合方向达到局部最小值的时候停止聚合。令m代表一个极点,![]() 代表该点水平或者垂直方向上的两个分段分数。i0<0,i1>0代表两个局部最小
代表该点水平或者垂直方向上的两个分段分数。i0<0,i1>0代表两个局部最小![]() ,
,![]() 的位置。边缘聚合根据下式对关键点分数进行更新。
的位置。边缘聚合根据下式对关键点分数进行更新。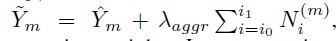 结果如下
结果如下

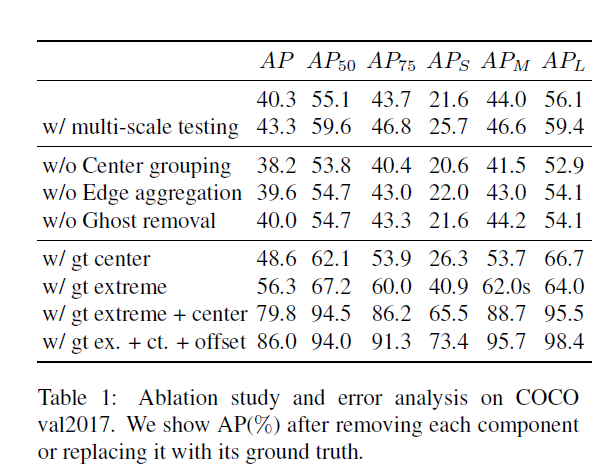
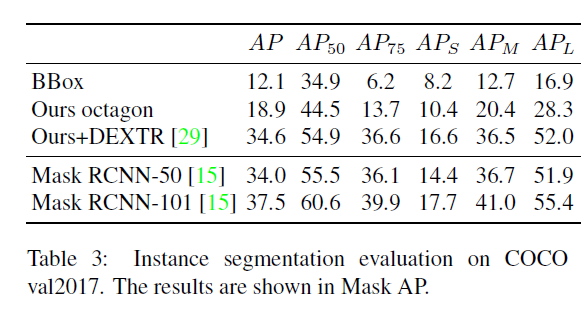
实验


Reference
[1] N. Bodla, B. Singh, R. Chellappa, and L. S. Davis. Softnmsimproving object detection with one line of code. In ICCV, 2017. 5, 6
[2] Z. Cai and N. Vasconcelos. Cascade r-cnn: Delving into high quality object detection. CVPR, 2018. 7
[3] Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh. Realtime multiperson 2d pose estimation using part affinity fields. In CVPR,2017. 1, 3
[4] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. PAMI, 2018. 4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号