
论文阅读笔记四十五:Region Proposal by Guided Anchoring(CVPR2019)

论文原址:https://arxiv.org/abs/1901.03278
github:code will be available
摘要
区域anchor是现阶段目标检测方法的重要基石。大多数好的目标检测算法都依赖于anchors机制,通过预定义好的尺寸及大小在空间位置上进行均匀的采样。本文提出了一个可替换的解决方案-Guided Anchoring,该方法利用语义特征对anchor进行引导。该方法预测感兴趣目标物的中心的同时预测不同位置处的长宽尺寸及比例大小。在得到anchor的形状之后,通过一个特征调整模型来降低特征的不连续性。本文同时研究高质量的proposal对提升检测效果的作用。
介绍
anchor是回归的参考标准,用于预测proposals的分类候选或者是最终的边界框。进行anchor设计时存在两条标准:alignment consistency。
首先使用卷积特征作为anchor的表示特征。anchor的中心要与Feature map的中心很好的对齐。其次,感受野的大小及语义范围在一个feature map上的不同区域要一致。因此,不同区域的anchor的大小及尺寸要保持一致。滑动窗机制则遵循上述规则是一种简单而且广泛应用的anchor机制。对于大多数检测模型,通过预先设定好的尺寸及大小的k个anchors在feature map上的每个位置进行滑动。
基于anchor的检测流取得不错的效果。然而上述生成anchor的方法并不是最优的方法。这种机制会产生两个难点:(1)针对不同的问题需要制定不同尺寸及比例的anchors。而错误的设计将会阻碍检测的精度及速度。(2)对于proposals保持一个较高的召回率,需要生成大量的anchors。然而,其中大量的anchor为假样本,与感兴趣的目标物无关,同时大量的anchors也会占用大量的计算资源。
本文提出新的设计anchor的方法用于解决过程中存在的人为先验的因素。本文方法受启发于图像上的目标物不是均匀的分布。目标物的比例大小也与图像的内容,场景的位置及几何形状密切相关。本文通过两步来产生稀疏的anchors。首先确定可能包含目标物的子区域,然后确定每个位置处不同的尺寸及大小。
anchor的形状是可学习的,但违背了前面提到过的一致性的准则。因此,提出了anchor 表示学习的新挑战,从而进行准确的分类及回归。anchor的尺寸及比例不再是固定不变的,而是可以改变的,因此,不同的特征像素需要根据相关的anchor学习调整特征表示。因此,本文引入了基于anchor几何变化的有效模型来调整特征。
本文根据前面的guided anchor及特征调整模型构建了GA-RPN网络。借助动态的anchor,相比RPN,anchor的数量减少了90%,但召回率要高9.1%。
本文主要贡献如下:
(1)本文提出了新的anchor机制可以预测任意形状的anchor
(2)将anchor的联合分布分解为两个条件分布,并分别使用模型进行建模。
(3)本文研究了相关anchor与feature map特征一致的重要性,并设计了一个特征调整模型来针对anchor的形状来增强feature。
(4)本文研究了双阶段检测高质量的proposals,并提出了一种提高训练性能的机制。
相关工作的比较异同
(1)以前的检测方法仍依靠滑动窗口来产生均匀密集的anchors。本文丢弃了滑动窗口,并提出guided anchor来产生稀疏的anchors。
(2)Cascade检测器通过级联多个阶段来增强框的回归,但会引入大量的参数,同时会降低Inference时的速度。通过ROI pooling或者RoI align来提取bounding box一致的特征,但对于单阶段检测来说该方法效率较低。
(3)Anchor-free的方法结构简单,在最后一个阶段得到检测结果,但由于anchor的缺少,同时并未对anchor进行进一步的回归,因此,该方法不适用于场景复杂的情况。本文在于稀疏及非均匀的anchor机制并利用高质量的proposals来提升检测的效果。因此必须解决不一致及非连续的问题。
(4)一些single-shot检测器通过多次分类回归来进行增强。而本文不对anchor进行增强,只是预测anchor的分布,分解为位置及形状。以前的方法并未考虑anchor与feature之间的一致性,因此,需要进行多次回归同时打破了上述的规则。因此,本文固定anchor的中心,并预测anchor的形状,并根据anchor调整预测出的形状调整feature。以前的分类目标是通过anchor与ground truth之间的IOU是否超过一定的阈值。而本文比较一个点是否靠近一个目标物的中心。
Guided Anchoring
guided anchor 机制工作方式如下:目标物的位置及形状可以由(x,y,w,h)表示。(x,y)代表物体空间位置的坐标。假想在一个给定的输入图片上画目标物的框则可以得到如下分布方式:

由上式得到两条重要信息,(1)目标物在图像中的特定区域(2)目标物的尺寸及比例与其所在位置密切相关。本文结构如下
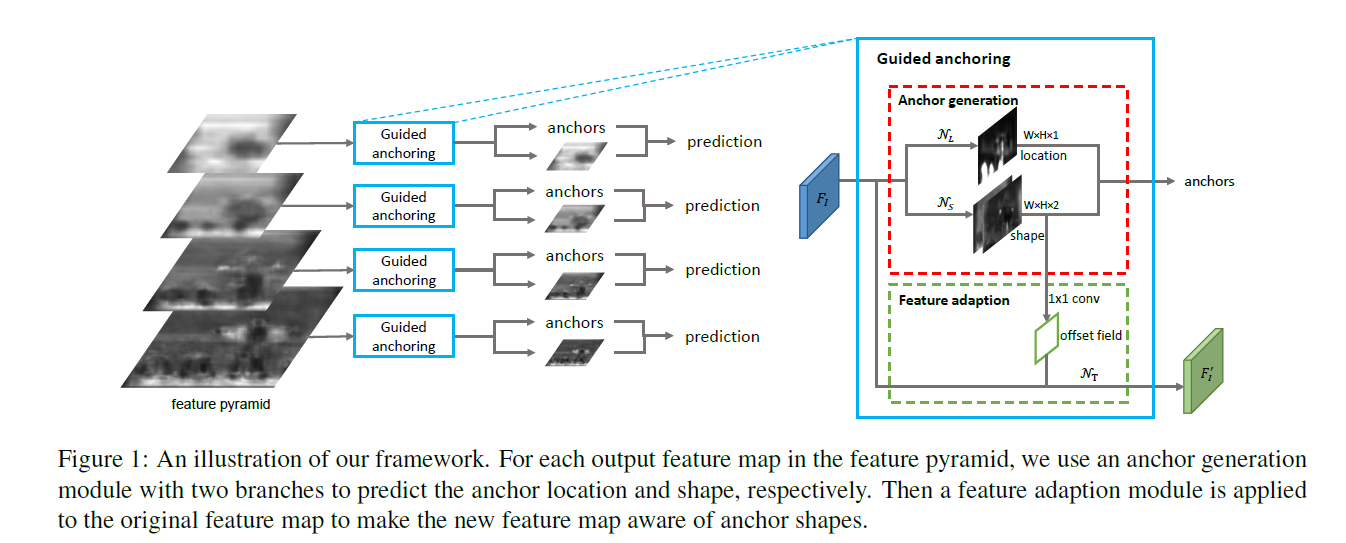
本文设计的anchor生成模型包含两个分支:一个用于定位,一个用于形状预测,对于一张输入图片I,首先得到feature map Fi,在Fi的头部,位置预测分支产生一个概率map代表目标物可能存在的位置,而形状预测分支则产生与位置无关的形状预测。然后,结合两个分支的输出结果,通过比较预测的值超过一定阈值的来得到一些可能的位置,并根据预测出的可能的位置预测最有可能的形状来生成一系列anchors。由于anchor的形状是可以变化的,因此,不同位置的特征应该可以捕捉不同范围的视觉内容。因此,本文引入了特征调整模型,进而根据特定的anchor形状来调整feature.同时,本文基于FPN,进行多层次的anchor生成。同时,anchor 生成的参数在所有层次的特征都是共享的,因此效率较高。
Anchor Location Prediction
如上图所示,anchor location prediction分支产生一个与输入feature map Fi相同尺寸大小的概率图![]() ,feature map I在(i,j)上的概率
,feature map I在(i,j)上的概率![]()
的大小与原图 I上对应点的坐标位置![]() 相关,s代表feature map的stride,比如相邻anchor之间的距离,其值代表目标物的中心位于该位置的概率。
相关,s代表feature map的stride,比如相邻anchor之间的距离,其值代表目标物的中心位于该位置的概率。
![]() 由子网络
由子网络![]() 产生,该网络通过一个1x1的卷积在feature map I上来获得目标物的scores map,然后通过一个element-wise的sigmoid函数来得到概率值,这样做可以平衡效率及准确率。得到概率map后通过设置一个阈值
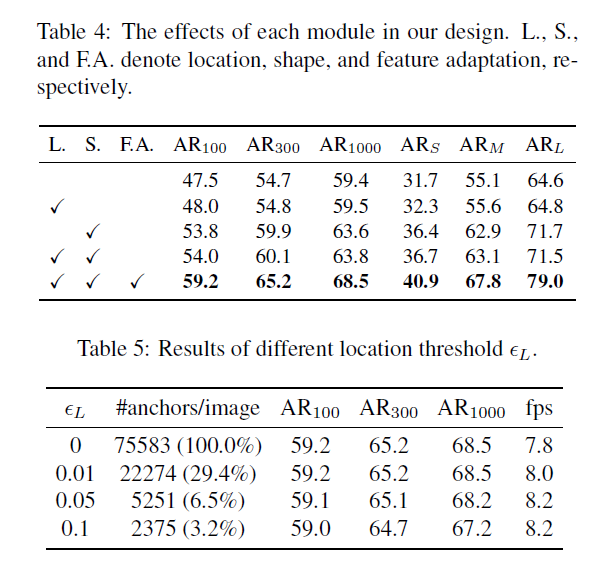
产生,该网络通过一个1x1的卷积在feature map I上来获得目标物的scores map,然后通过一个element-wise的sigmoid函数来得到概率值,这样做可以平衡效率及准确率。得到概率map后通过设置一个阈值![]() 来挑选目标物可能存在的位置,该方法可以在保持召回率的条件下筛选90%的区域。由于不考虑超过的区域,为了提高inference的效率,本文使用masked卷积。
来挑选目标物可能存在的位置,该方法可以在保持召回率的条件下筛选90%的区域。由于不考虑超过的区域,为了提高inference的效率,本文使用masked卷积。
Anchor Shape Prediction
在确定了目标物可能存在的位置后,接下来就判断相应位置anchor的形状,该分支与边界框的回归十分不同。由于没有改变anchor的位置,因此不存在anchor与其feature map不匹配的问题。给定Fi,该分支预测每个位置的(w,h),预测出的形状可能会与最近的Ground truth产生较高的IOU。但(w,h)的取值范围太大,直接进行预测存在难度。因此,做了如下变换。
![]()
该分支预测dw,dh,通过上式进行映射,s为stride,![]() 为经验系数,本文设置为8,该映射将[0,1000]映射至[-1,1]得到一个稳定的学习目标。该分支通过一个1x1x2的卷积网络
为经验系数,本文设置为8,该映射将[0,1000]映射至[-1,1]得到一个稳定的学习目标。该分支通过一个1x1x2的卷积网络![]() 进行预测得到dw,dh,并通过element-wise的上式进行变换。该方法与以前的不同,一个位置只预测一个动态变化的anchor形状,而以前的为一系列anchor的形状,该方法具有更高的召回率,同时对于极端形状的物体能更好的捕捉其信息。
进行预测得到dw,dh,并通过element-wise的上式进行变换。该方法与以前的不同,一个位置只预测一个动态变化的anchor形状,而以前的为一系列anchor的形状,该方法具有更高的召回率,同时对于极端形状的物体能更好的捕捉其信息。
AnchorGuided Feature Adaptation
在基于滑动窗机制的单阶段或者RPN网络中,每个位置都均匀的共享相同尺寸的anchors,因此,feature map可以学到连续的表示。而本文的anchor在每个位置的形状是不同的,因此,不易按照以前使用一个全卷积分类器作用在ferature map上。较大的anchor的特征应该编码较大区域的特征,而小的anchor特征则应该编码较小的区域特征。因此,本文设计了基于每个独立位置anchor形状调整feature 形状的anchor guided feature adaptation组件,如下

其中,fi代表第I个位置的feature map,(wi,hi)为相应的anchor的形状。为了进行与位置无关的转换,本文应用了一个3x3的可变形卷积来增强分支![]() ,首先得到anchor 形状预测分支的偏移量,然后利用原始的feature map结合offset获得新的特征fi',在新得到的特征上可以进行接下来的分类及回归操作。
,首先得到anchor 形状预测分支的偏移量,然后利用原始的feature map结合offset获得新的特征fi',在新得到的特征上可以进行接下来的分类及回归操作。
Training
Join objective:该网络结构基于多损失任务的end-to-end的框架。除了常规的分类损失![]() 及回归损失
及回归损失![]() ,引入了用于anchor定位及形状的两个损失
,引入了用于anchor定位及形状的两个损失![]() 及
及![]() ,得到最终的损失函数如下:
,得到最终的损失函数如下:
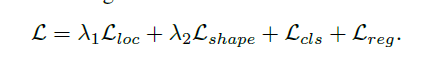
Anchor location targets
为了训练anchor定位分支,对于每张图片需要获得一张binary label map,1代表可以放置anchor的有效位置,否则为0,本文利用ground truth来生成binary label map。希望在一个目标物的中心附近尽可能多的安置anchors,其很少有距离中心很远的。首先,将ground truth bounding box的![]() 映射到相应的feature map大小
映射到相应的feature map大小![]() ,用
,用![]() 代表中心为(x,y)大小为wxh的矩形区域。anchor被期望放到距离ground truth object中心较近的位置来得到更高的初始IOU,因此,本文针对每个box定义三种类型的矩形区域。如下图
代表中心为(x,y)大小为wxh的矩形区域。anchor被期望放到距离ground truth object中心较近的位置来得到更高的初始IOU,因此,本文针对每个box定义三种类型的矩形区域。如下图

(1)中心区域:![]() 代表目标物的中心,该区域的像素都为正样本。
代表目标物的中心,该区域的像素都为正样本。
(2)忽略区域:![]() ,该区域除了CR,范围更大
,该区域除了CR,范围更大![]() ,该区域内的像素在训练时被标记为ignore。
,该区域内的像素在训练时被标记为ignore。
(3)外部区域:OR除了CR及IR的区域,该区域的像素标记为负样本。
gray zone曾用作平衡采样的方法,但只作用在单分辨率的feature map上,本文利用FPN得到多层次的feature map,因此,需要考虑相邻feature map的影响。因此,每个层次的Feature map只能对应特定尺寸的目标物。如果feature map与目标物的尺寸相互匹配,则分配CR。而相同区域的相邻层次被设置为IR区域如上图所示,由于CR只占很少的一部分,因此使用Focal Loss来训练定位分支。
Anchor shape targets
为了获得每个anchor最合适的目标形状,首先将anchor与一个ground truth box进行匹配,然后通过二者之间的IOU来计算得到最优的![]() ,由于本文anchor的w,h是变化的,因此直接计算IOU有点难度,因此,重新定义了变化的anchor
,由于本文anchor的w,h是变化的,因此直接计算IOU有点难度,因此,重新定义了变化的anchor![]() 与ground truth
与ground truth![]() 之间的IOU,记作vIOU
之间的IOU,记作vIOU
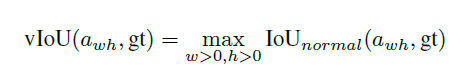
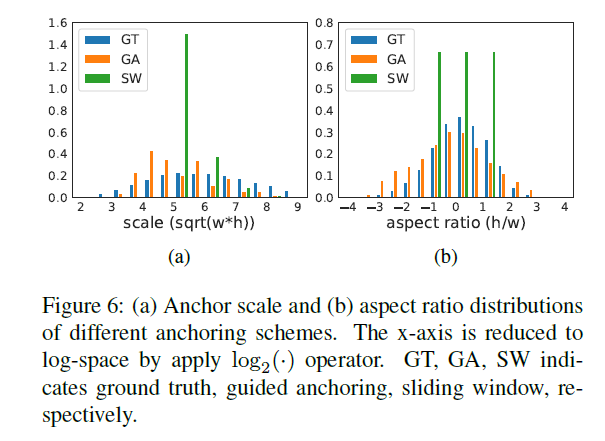
其中,IoUnormal为经典的IOU定义,w,h为变量,但对于任意位置的anchor与ground truth,对vIOU进行明确的表示是困难的,也不利于有效的潜入到end-to-end网络中,给定(x0,y0),本文采样了一些w,h常用值,用于列举w,h。计算采样的anchor与ground truth IOU,并选取最大的IOU作为vIOU的近似。本文采样了9对不同尺寸及比例的(w,h)。然后,本文并不直接回归anchor的宽及高,损失函数与原始的近似相同,但本文由于anchor的位置是固定的,因此只优化w,h,而不是(x,y,w,h)。
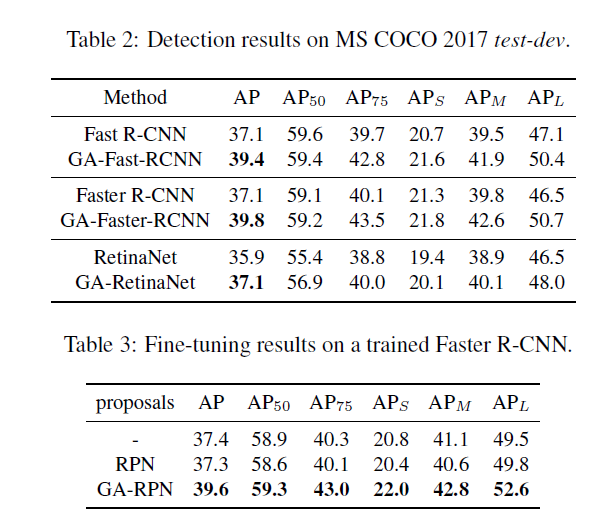
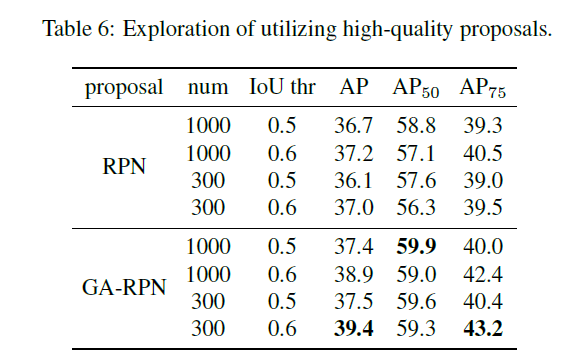
The Use of Highquality Proposals
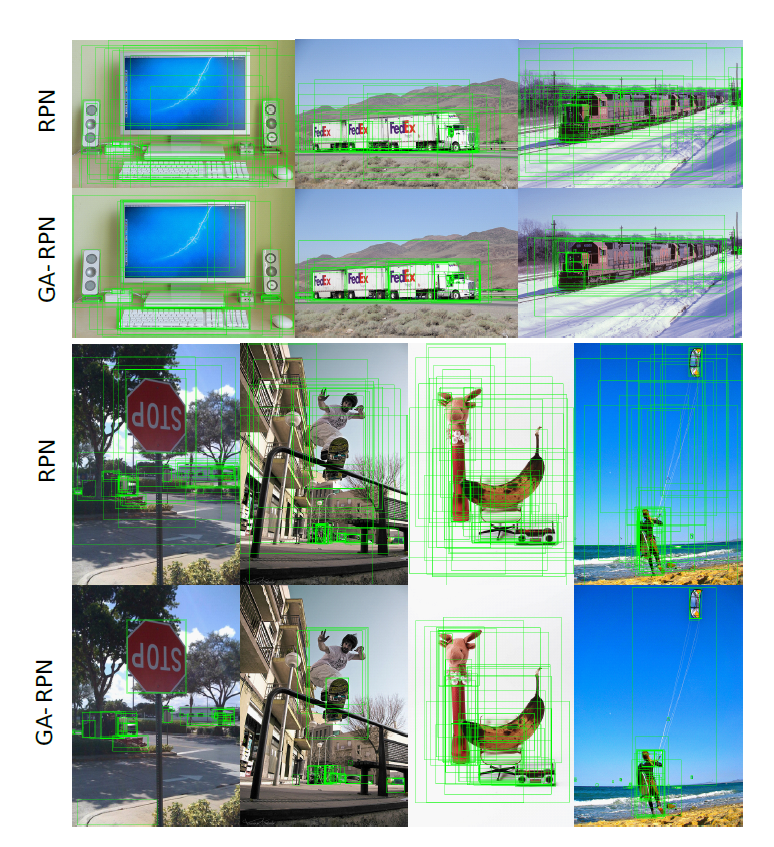
相比传统的RPN,GA-RPN可以产生更高质量的anchors。本文考虑了如何利用这些高质量的anchors来提升两阶段检测性能。首先研究了,RPN及GA-RPN产生的anchors IOU的分布规律,如下图。
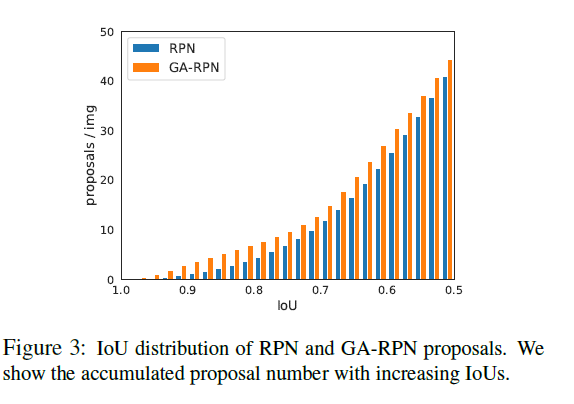
相比GA-RPN存在两个明显的优点:(1)正proposals的数量更多。(2)高IOU的proposals的比例更有用。但将RPN换作GA-RPN效果提升不大。据实验观察,使用高质量proposal的先决条件是根据proposals的分布来进一步调整训练样本的分布。因此,相比RPN,训练GA-RPN时使用更高的阈值来使用更少的样本来进行训练。
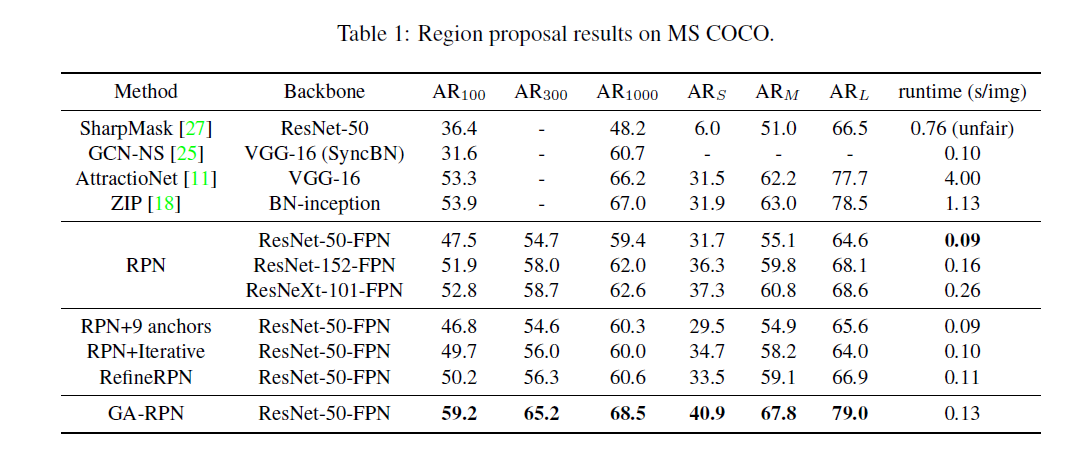
实验


Reference
[1] Z. Cai and N. Vasconcelos. Cascade r-cnn: Delving into high quality object detection. In IEEE Conference on Computer
Vision and Pattern Recognition, 2018. 2
[2] J. Dai, Y. Li, K. He, and J. Sun. R-fcn: Object detection via region-based fully convolutional networks. In Advances in
Neural Information Processing Systems, 2016. 2
[3] J. Dai, Y. Li, K. He, and J. Sun. R-FCN: Object detection via region-based fully convolutional networks. In Advances
in Neural Information Processing Systems, 2016. 4
[4] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In IEEE Conference on Computer Vision
and Pattern Recognition, 2005. 2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号