
论文阅读笔记四十四:RetinaNet:Focal Loss for Dense Object Detection(ICCV2017)

论文原址:https://arxiv.org/abs/1708.02002
github代码:https://github.com/fizyr/keras-retinanet
摘要
目前,具有较高准确率的检测器基于双阶段的目标检测算法实现,单阶段通过对可能存在的位置进行密集的采样操作,一定程度上要比双阶段的方法要更简单快速,但是准确率会有所损失。在进行训练时,前景与背景二者之间较大的类别不平衡是产生上述问题的原因。针对上述问题,本文对常规的损失函数进行修改,降低易分类样本产生的损失的贡献度。本文设计了密集采样检测器-RetinaNet用于评估Focal损失的效果,实验发现速度可以超过当前的单阶段目标检测,同时准确率要高于双阶段的目标检测。
介绍
目前最好的目标检测算法基于双阶段的,由proposal驱动的方法,单阶段目标检测的方法对目标物的位置进行大小及尺寸的密集采样,单阶段检测速度更快但准确率相对为双阶段的10~40%左右。本文认为类比的不平衡是单阶段方法准确率较低的主要原因,并提出了一个新的损失函数。
类别不平衡问题在双阶段过程中得到解决,主要通过双阶段的级联及启发的方式进行。比如,在proposal阶段通过将背景的候选框剔除来控制候选框的数量(1k~2K),在第二阶段分类过程中,通过固定前景背景量的比例1:3,或者online hard example mining 方法进行前景/背景之间的平衡。
单阶段中产生的候选位置大约为(100k),相同的启发方式对其作用不大,容易分类的背景仍然对损失造成很大的影响。
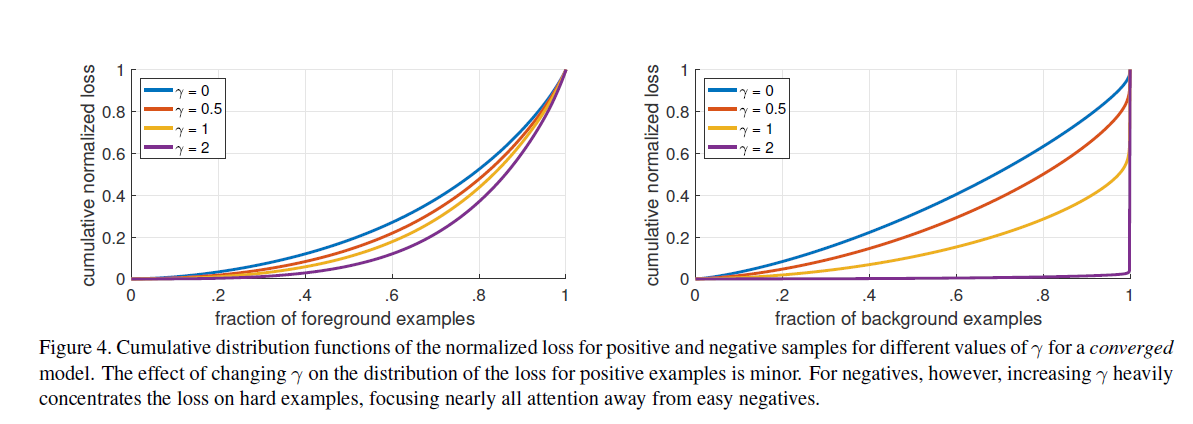
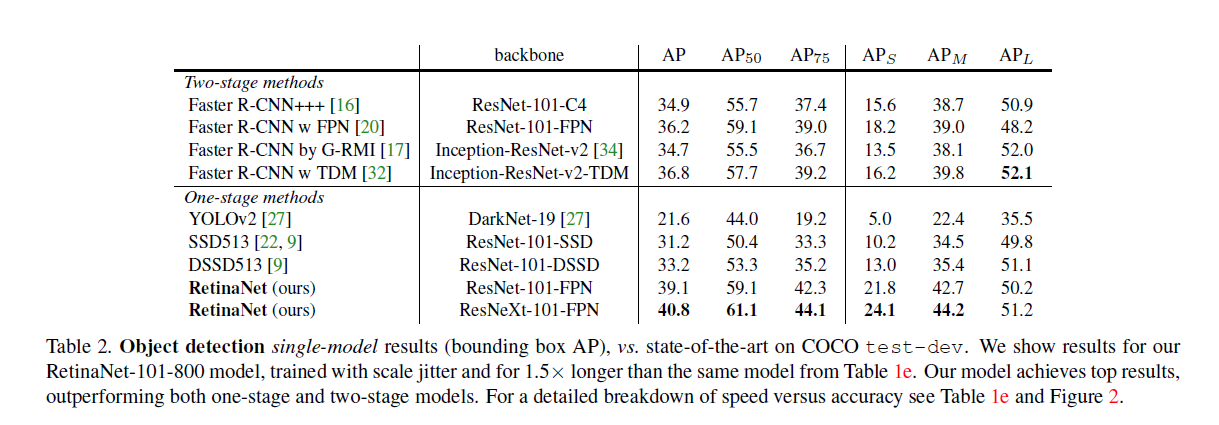
本文提出动态的比例交叉熵损失,比例系数大小随着正确分类样本置信度的增加逐渐趋向于0。如下图,直观上,比例系数可以降低简单样本贡献度的权重,让模型更注重于Hard examples的优化。本文最好发现,Focal loss对单阶段准确率的提升有很大效果,但损失函数不局限于固定的形式,使用了高效的特征金字塔及anchor boxes的方法。RetinaNet基于ResNet-101-FPN,在COCO test数据集上实现了39.1的AP,同时,速度为5fps,如下右图所示。
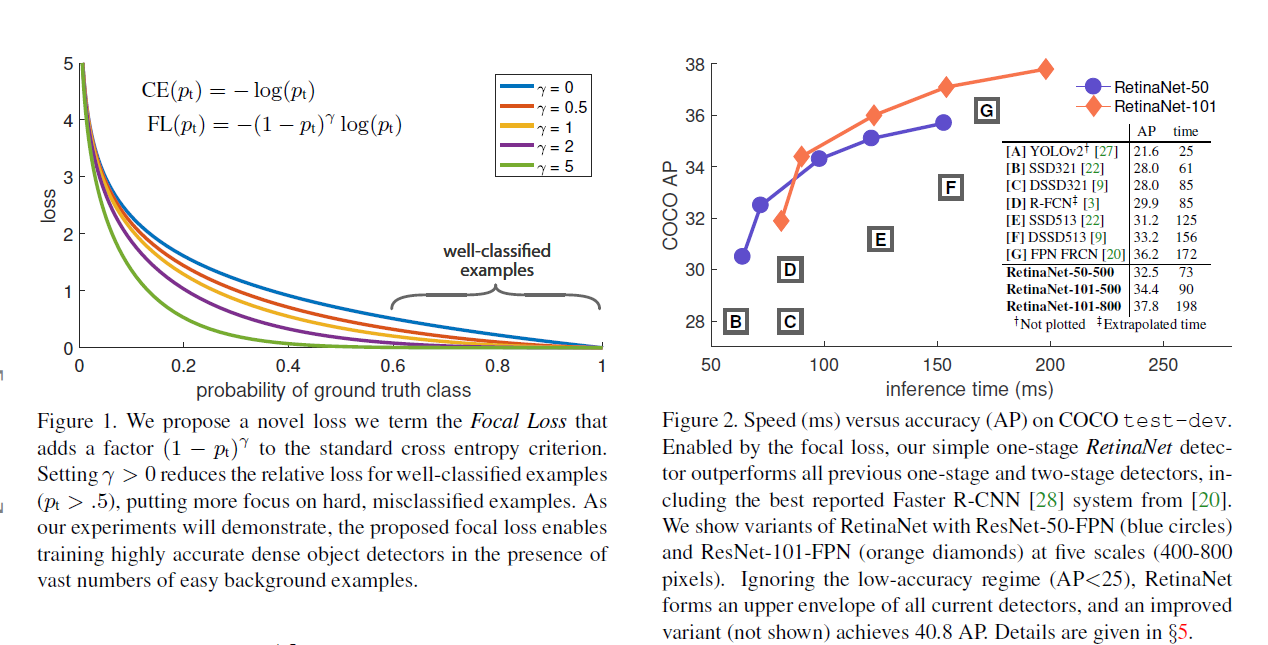
类别不平衡
单阶段检测方法中存在更多的类别不平衡问题,每张图片大约产生10e4-10e5个候选位置,但包含目标物的只有少数。产生不平衡的原因如下:(1)大多数负样本产生无用的学习信号对训练没有意义。(2)易于分类的负样本很容易就占据训练的主导地位,进而会使模型退化。一种常规的解决方法是类似于Hard example mining或者是更加复杂的采样或者重新分配权重的方法。而本文设计的Focal loss不需要借助采样手段也可以有效的解决类别不平衡的问题。
Robust Estimation
该方法主要针对损失函数进行设计,比如降低异常值产生的较大损失的权重进而控制Hard example对损失的贡献度。而Focal loss降低简单样本对损失的贡献,将关注点放在Hard example上。
Focal Loss
该损失用于单阶段检测场景,解决前景/背景(1:1000)的极端不平衡情况。常规的交叉熵损失如下。
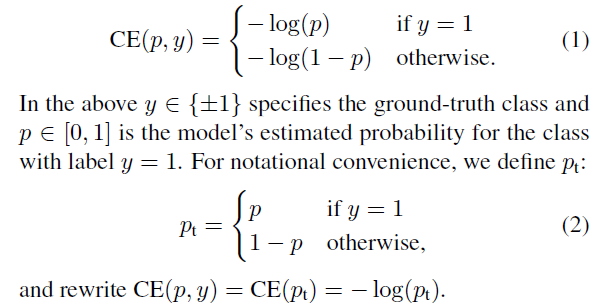
该损失有一个特点就是大量易于分类的负样本的产生的训练信号最终会主导模型的训练方向。
Balanced Cross Entropy
解决不平衡的一个方法是增加一个权重系数。本文定义带有权重的交叉损失函数如下。
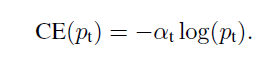
Focal Loss定义
上述的权重系数可以控制正负样本的比例,但对于easy/hard example样本作用不大,本文增加了一个调制系数。损失函数如下
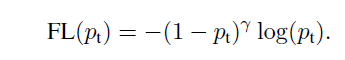
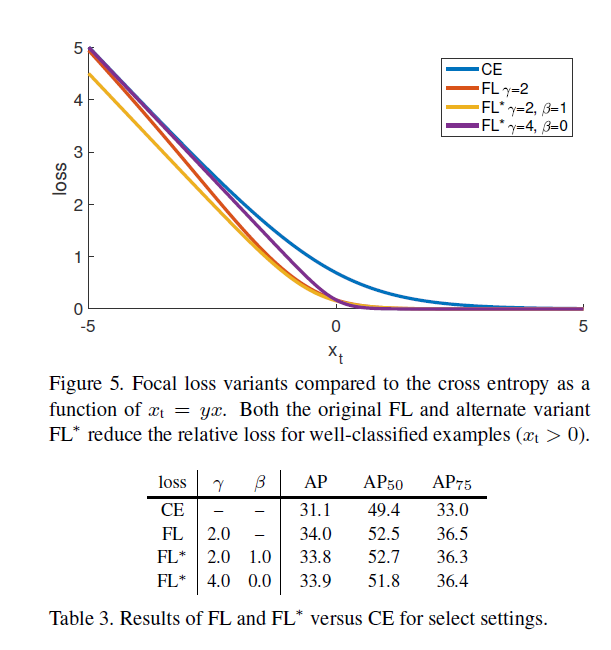
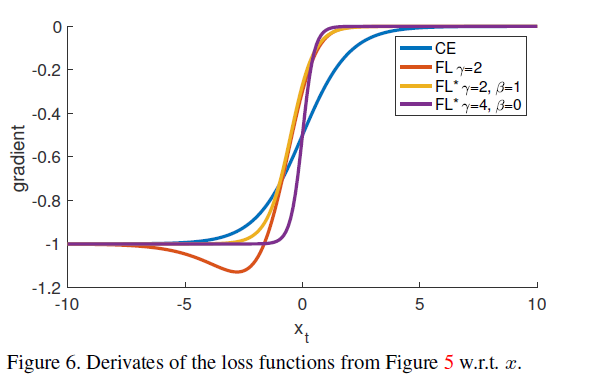
当一个样本被误分类同时其概率特别小时,其调制系数近似为1,该损失函数不受影响。而当易分类样本的Pt趋于1时,该调制系数降低,对损失函数影响较小。focusing 参数r平滑的调整easy样本的衰减权重。本文实验发现r为2时效果最好。本文实际使用的损失函数定义如下。

类别失调及模型初始化
对于二分类的输出初始化相等的概率,这种情况下,类别失调及频率较高的类别会主导total loss进而在早期的训练过程会变的不稳定。因此,本文在训练开始时引入模型对于稀少类别概率预测值的“先验”概念。本文定义先验为pi,模型预测少数类的概率值是很低的比如,0.01.值得注意的是先验是在模型的初始化时变化的而不是损失函数上。
RetinaNet Detecor
该网络由一个backbone及两个任务明确的subnet组成,backbone由卷积网络组成用于提取整张图片的feature map,第一个subnet在backbone输出上进行卷积分类操作,第二个subnet在其进行卷积边界框回归操作。结构图如下
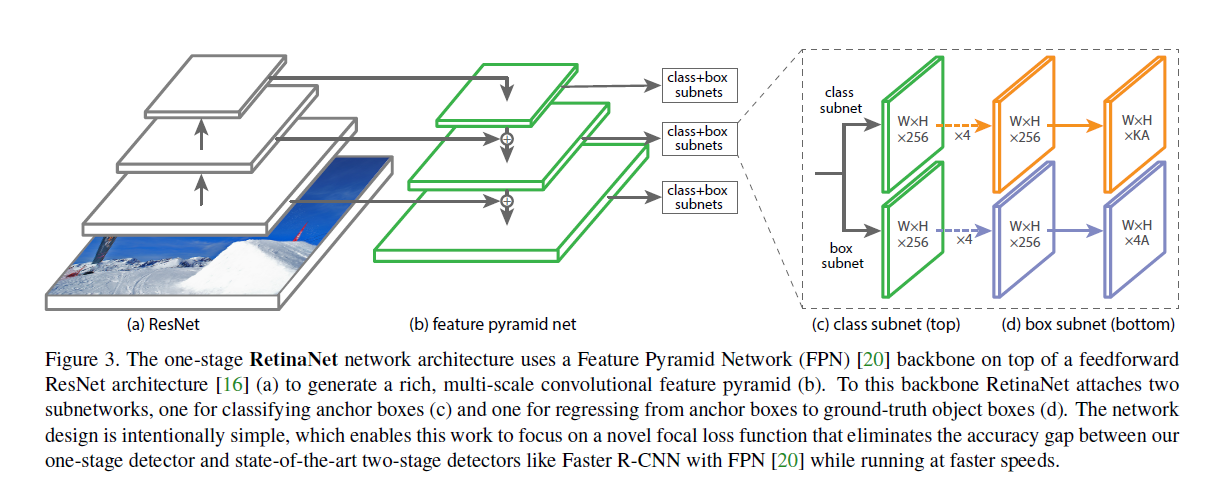
FPN backbone
本文使用FPN作为backbone,FPN通过自上而下的路径及lateral 连接来构建特征,其对于单分辨率的输入图片具有更丰富,多尺寸的特征信息。FPN中金字塔的每一层都可以用于不同尺寸大小的目标检测,并使用全卷积网络进(FCN)行增强。本文利用FPN构建了特征金字塔,p3~p7,数字越大,该层的分辨率尺寸越小,特征金字塔的每层通道数为256,
Anchors
随着层数p3~p7,anchor的大小由32x32变为512x512,在每一层anchor的比例大小为{1:2,1:1,2:1},在此基础上增加了三个缩放比例{20,21/3,22/3},在每层共有九个anchors,相对于网络的输入覆盖范围由32-813个像素。
每个anchor都标记一个宽度为k(类别数)的one-hot向量的分类标记及一个四个向量的边界框回归目标。将anchor与ground truth IOU超过0.5的标记为前景,0~0.4的标记为背景。将IOU在0.4~0.5之间的anchor进行忽略。框回归目标由每个anchor及assigned目标物框的偏移量计算得到,如果没有assigned框则忽略。
分类分支
该分支在FPN的每一层上做类似于全卷积操作,预测每个空间位置上每个anchor的K个类别的概率值,其参数在FPN的所有层都进行共享操作。具体操作为,输入某一层的特征,通道数为C,后街四个3x3xC的卷积层,每层都接ReLU,然后一个3x3xkXA的卷积,最后接sigmoid激活层,每个位置预测KA个binary predictions,实验中大部分C设置为256,A设置为9。注意的是分类分支与边界框分支的参数之间是独立的,不进行共享。
边界框回归分支
与分类分支平行,本文增加了另一个小型的FCN网络用于边界框回归。每个位置包含4A个线性输出。在每个空间位置的A个anchor上,四个输出用于预测每个anchor与ground truth box的相对偏移量。本文使用类别不确定的边界框回归,其参数量更少,但效果相同。分类分支与回归分支结构相同,但二者参数相互独立。
Inference and training
为了提速,本文将检测器的阈值设置为0.05后,只对FPN每层中分数高的前1000个预测值进行decode box 预测。最后将所有层得到的结果进一步使用阈值0.5进行NMS处理完成最终的检测。
Focal Loss
本文在分类分支中使用focal loss,将r(取值分为0.5~5)设置为2效果较好。训练RetinaNet时超过100k个anchors,toatal focal loss由所有anchor的损失的和normalized assigned a ground truth box anchor的数量,原因时anchor中包含大量的easy negative 样本。其权重a的值有一定的范围,随着r的增加其a的值不断减小。
初始化
本文实验了Resnet-50-FPN,ResNet-101-FPN两种backbones。basenet restnet-50及resnet-101在ImageNet1k上进行预训练。新添加的所有卷积层除了最后一层都按照bias为0,高斯分布(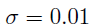 )的权重进行初始化。分类分支的最后一层卷积按照
)的权重进行初始化。分类分支的最后一层卷积按照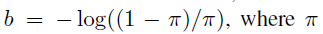
初始化,pi代表开始训练时每个anchor被标记为前景的概率先验,本文都设置为.01。该方法有效的防止在训练时的第一次迭代中大量背景anchors生成损失值。
优化
本文基于SGD使用8块GPU进行同步训练,每个batch设置为16.所有模型的初始学习率为0.01,迭代90k步。权重衰减为0.0001及动量大小设置为0.9,损失用的focal loss用于分类及smoth L1损失用于回归,模型训练用时10到35个小时。
实验
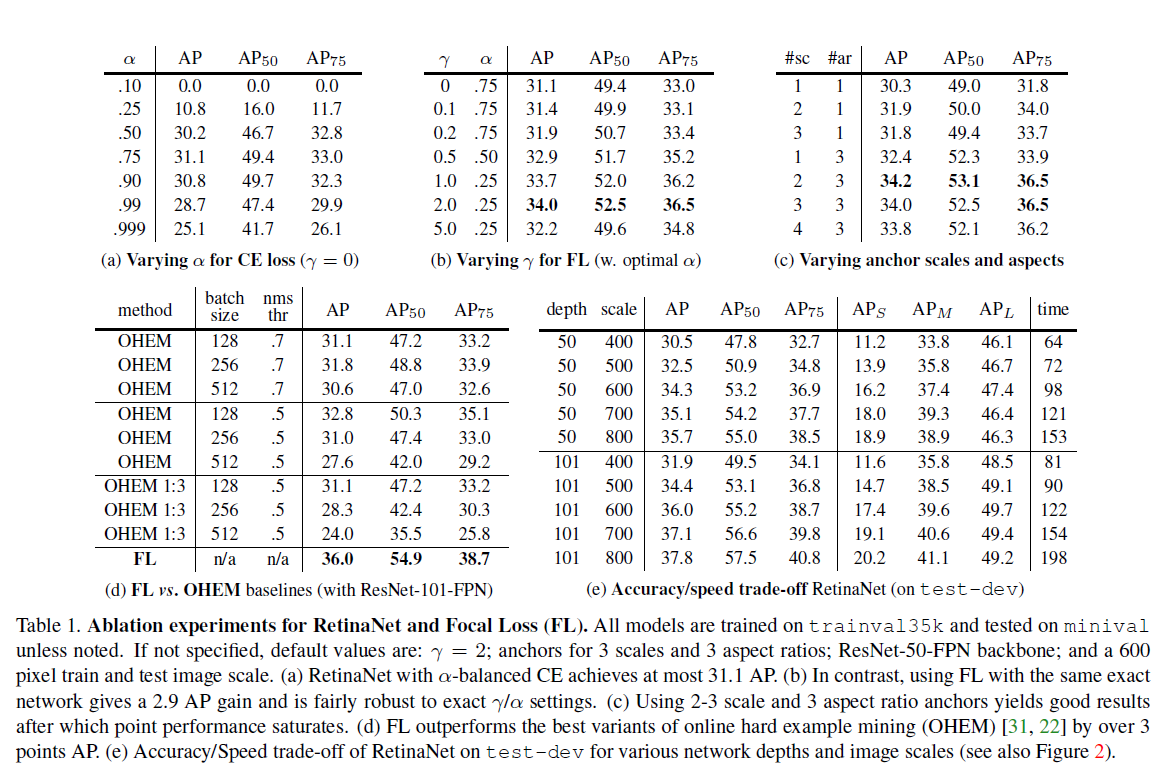
References
[1] S. Bell, C. L. Zitnick, K. Bala, and R. Girshick. Insideoutside net: Detecting objects in context with skip pooling and recurrent neural networks. In CVPR, 2016. 6
[2] S. R. Bulo, G. Neuhold, and P. Kontschieder. Loss maxpooling for semantic image segmentation. In CVPR, 2017.3
[3] J. Dai, Y. Li, K. He, and J. Sun. R-FCN: Object detection via region-based fully convolutional networks. In NIPS, 2016. 1
[4] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In CVPR, 2005. 2
[5] P. Doll´ar, Z. Tu, P. Perona, and S. Belongie. Integral channel features. In BMVC, 2009. 2, 3
[6] D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov. Scalable object detection using deep neural networks. In CVPR, 2014.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号