
论文阅读笔记三十八:Deformable Convolutional Networks(ECCV2017)

论文源址:https://arxiv.org/abs/1703.06211
开源项目:https://github.com/msracver/Deformable-ConvNets
摘要
卷积神经网络由于其构建时固定的网络结构,因此只能处理模型的几何变换问题。本文主要介绍了两种增强CNN模型变换的模型,称为可变形卷积及可变形RoI pooling。二者都基于一种思路,通过额外增加模型的偏移及根据目标任务对此偏移量进行学习来增强空间采样位置。新模型可以取代CNN中的原有模型,可以通过反向传播算法进行端到端的训练学习。
介绍
视觉识别任务中的一个重要挑战是,如何适应物体的尺寸,视野,姿态及部分变形的几何变化及模型几何变换。一般具有两种方式(1)构建具有多样性变化的训练数据集,通常是在现有数据集上进行一些额外变换。进而可以从数据集中学习到一些鲁棒性表示。但需要大量的训练及模型参数。(2)使用非变换性质的特征及算法,比如SIFT及基于目标检测的滑动窗。
上述两种方式主要存在两个缺点。(1)模型的几何变换是假设固定,已知的。一些先验知识用于增强数据,特征及算法的设计。这种假设不利于具有位置几何变换新模型的生成。(2)手工设计的不变性特征及算法可能会很困难,对于复杂变换来说不太灵活。
卷积网络在视觉识别任务上取得了巨大的成功,比如图像分类,图像分割,目标检测。然而,仍然存在上述两个缺点。模型的几何变换能力主要通过扩展的数据增强,较大的模型能力,及一些简单的手工设计模块像最大池化。
CNN受限于模型的容量及未知变换。限制来源于CNN模型中固定的几何结构:一个卷积单元在固定位置采样输入feature map。pooling 层以一定的比例减少空间分辨率。RoI pooling层将一个RoI的信息划分为固定的空间bins。其中,缺少处理几何变换的中间机制。这会造成明显的问题。比如,相同的CNN层中激活单元的感受野大小相同。对于高级层次中的卷积层,对空间位置编码语义信息是不需要的。由于不同位置处与物体的不同尺寸,变形相关。自适应的确定尺寸及感受野的大小对视觉识别的定位意义重大。比如,语义分割使用全卷积网络。虽然,目标检测网络发展迅速,但所有方法仍依赖于基于特征提取的预选框中。对于非刚性物体,这种方式显然不是最好的。
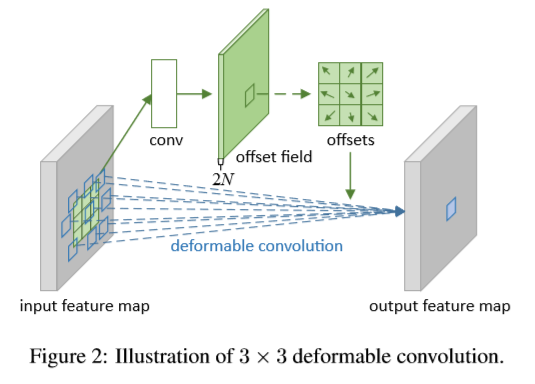
本文中,介绍了两个新模型用于增强CNN对几何变换性的能力。第一个为可变形卷积,在标准的卷积中对方格中的采样点增加了一个2D的偏移。可以实现采样格子的随机变换。如下图所示。

偏移通过额外的卷积层从预处理的feature maps中进行学习。因此,输入特征是局部,密集的及自适应的,可变形并以此作为条件。
另一个为可变形RoI Pooling。在每个bin位置处增加了一个偏移。相似的,偏移仍从预处理过的feature maps及Rois中进行学习,从而可以对不同形状的物体自适应的定位。
上面的模型都是轻量级的,增加少量的参数用于偏移的学习。可以替换CNN中的普通部分,同时,可以进行端到端的训练学习。最终的CNN被称为可变形卷积网络。
本文提出的方法与空间变换网络及可变形的部分模型在主旨上具有较高的相似性。都具有中间的变换参数并通过从数据中进行学习。本文不同的是,本文主要考虑在一个样本中以一种简便高效可端对端训练的方式进行密集的空间变换操作。
Deformable Convolutional Networks
CNN中的feature maps及卷积是3D的。而可变形卷积及RoI poolings都是在2D空间上进行操作。整个操作保持通道数不发生变化。本文以2D举例论述,3D的可以直接扩展。
Deformable Convolution
2D卷积包含两部分:(1)通过一个矩形格子R在feature map x上进行采样。(2)带权重的采样值的求和。R定义了感受野及空洞的大小。比如,下列定义了一个3x3的卷积核,空洞大小为1.
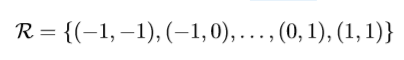
针对输出feature map y上的每个位置p0,有如下操作
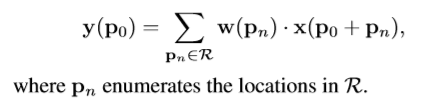
在可变形卷积中,标准的格子R增加了偏移量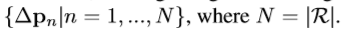 上式变为如下形式。
上式变为如下形式。
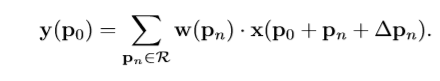
采样点在非矩形及偏移位置处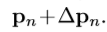 ,将
,将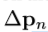 作为一部分,上式通过双线性插值操作得到x(p)如下,其中p代表,随机部分(p=p0+pn+deta pn),q映射feature map x中所有整体空间位置,G代表双线性插值核。G为两维的,可以被拆分为两个一维的
作为一部分,上式通过双线性插值操作得到x(p)如下,其中p代表,随机部分(p=p0+pn+deta pn),q映射feature map x中所有整体空间位置,G代表双线性插值核。G为两维的,可以被拆分为两个一维的

如下图所示,通过在相同的feature map上使用卷积层来得到偏移量。卷积核具有与当前卷积层相同的空间分辨率及扩张大小(3x3 with dilation 1)。输出的offset fields与输入feature map具有相同的空间分辨率。通通道数2N对应N个 2D的偏移。训练时,产生输出特征的卷积核与偏移同时进行学习。通过在上述等式中应用双线性插值及梯度下降算法学习偏移。
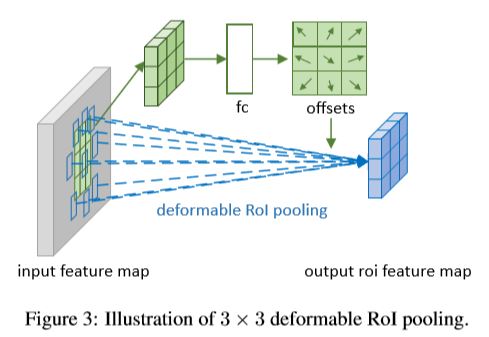
Deformable RoI pooling
RoI pooling基于目标检测方法中应用在所有region proposal。将任意输入大小的矩形框调整为固定尺寸大小的features。
RoI pooling: 输入feature map x及大小为wxh的RoI,左上角的点p0, RoI pooling将输入分为kxk个bins同时,输出一个kxk的feature map y。对于第(i,j)个bin,有如下表示,
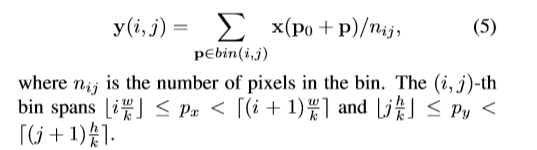
与Deformable 卷积中的式子相似,在空间bin位置处增加偏移量,结果如下
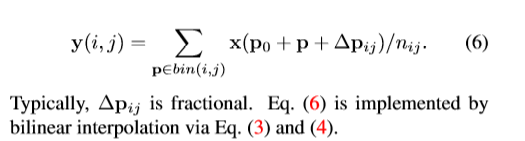
过程如下图,首先,RoI pooling会生成pooled feature maps。然后一个全连接层生成标准化后的offsets 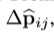 得到上式中的
得到上式中的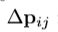 ,通过与RoI的宽和高进行点乘操作进行标准化处理。
,通过与RoI的宽和高进行点乘操作进行标准化处理。
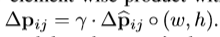 ,r代表预先定义尺寸,用于调整偏移带西奥,一般设置为0.1。偏移的标准化处理十分重要,可以使偏移的学习对不同的RoI大小具有不变性。全连接层通过反向传播进行学习。
,r代表预先定义尺寸,用于调整偏移带西奥,一般设置为0.1。偏移的标准化处理十分重要,可以使偏移的学习对不同的RoI大小具有不变性。全连接层通过反向传播进行学习。
位置敏感性RoI pooling:其为全卷积层,同时不同于RoI pooling。通过一个卷积层所有输入feature maps首先针对每个目标类别被变为kxk的score maps,如下图
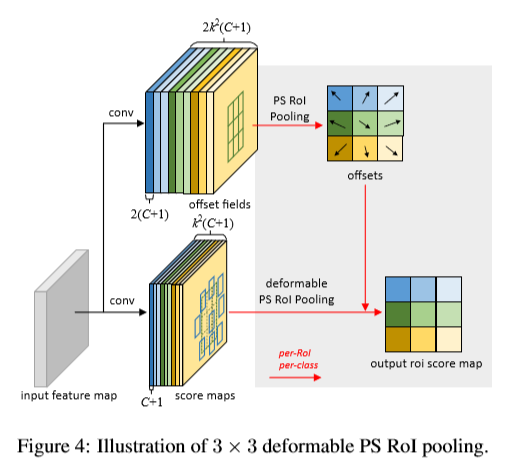
在得到的score maps上执行pooling操作。第(i,j)处的bin的输出值通过计算bIn对应的score maps值的相加得到。简言之,与前面的可变形RoI pooling的不同点在于使用位置铭感的score map xi,j替换其中的feature map。
在可变形PS RoI pooling中,等式唯一的变化是将x变为xi,j,但offset 得学习是不同得。遵循全卷积的思想。在上图的上面分支,一个卷积层生成一个对应空间分辨率的offset fields,PS ROI pooling 应用于每个ROI,来得到标准化后的offsets 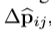 ,然后,以相同的方式得到实际偏移
,然后,以相同的方式得到实际偏移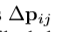
Deformable ConvNets: 可变形卷积与RoI pooling模型与正常的卷积与Roi pooling有相同的输入输出。因此,可以对卷积网络中的对应部分进行替换。训练时,增加卷积层及全连接层用于偏移量的学习,使用0对权重进行初始化。学习率设置为当前层数的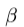 倍,默认为1,Faster R-CNN中默认为0.01倍。在上面等式中使用双线性插值进行反向传播算法,最终的CNN被称为可变形卷积网络。
倍,默认为1,Faster R-CNN中默认为0.01倍。在上面等式中使用双线性插值进行反向传播算法,最终的CNN被称为可变形卷积网络。
为了将可变形卷积网络与当前优秀的卷积结构进行结合,注意到这些网络包含两个阶段:(1)一个深层的全卷积网络对输入图片生成feature maps。(2)一个附属的任务网络用于根据feature map产生结果。
Deformable ConvNets for Feature Extraction: 本文选用ResNet及改进的Inception ResNet进行特征提取。原始的Inception ResNet用于图像分类。针对密集预测任务其具有特征不匹配问题。对齐修改使其适用于匹配问题。两个模型都包含几个卷积blocks,一个平均池化层,及一千路全连接层。全连接层及平均池化层被移除。后接随机初始化的1x1卷积用于降维。为了增加feature map的分辨率,最后一个卷积block的有效stride由32个像素,变为16个。在最后一个block的开始处,stride由2变为1,.同时为了进行补偿,所有卷积核的dilation由1变为2.可变形卷积应用在最后几个卷积层中。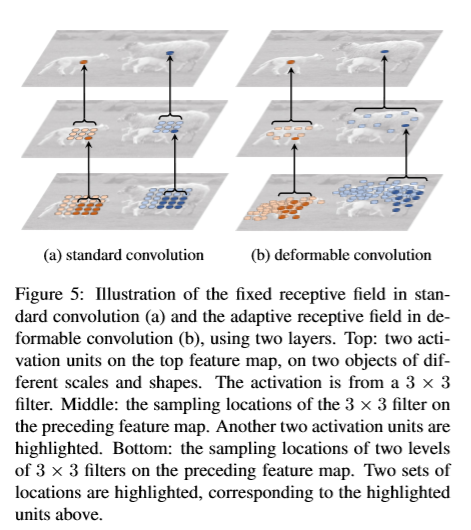

Deformable ConvNets的理解
本文工作主要是:增强卷积中的空间采样位置,带偏移的RoI pooling及目标任务中偏移量的学习。标准卷积中的感受野及采样位置是固定的。而在可变形卷积中这些会根据目标的尺寸及形状自适应的发生变化。在可变形RoiPooling中,标准的RoIpooling的grid不存在,部分与RoI bins发生偏离,并移至附近的前景区域中,对非刚性物体的定位能力进行增强。
实验
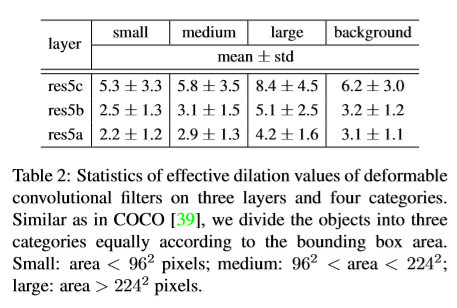
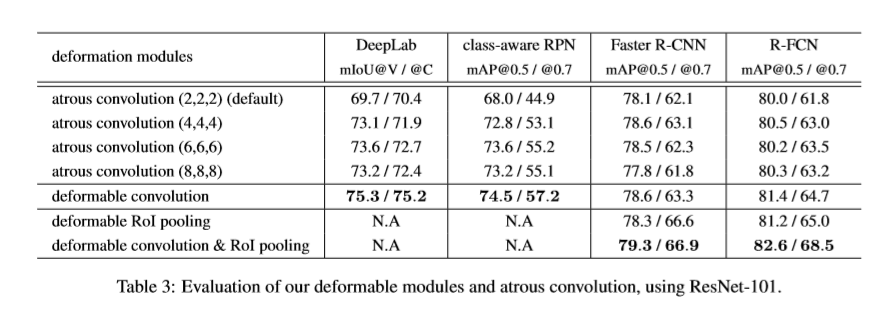
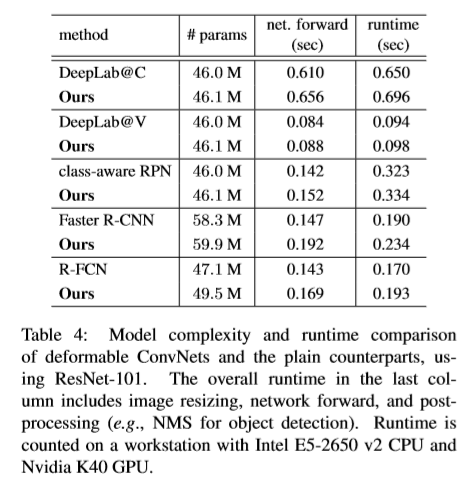
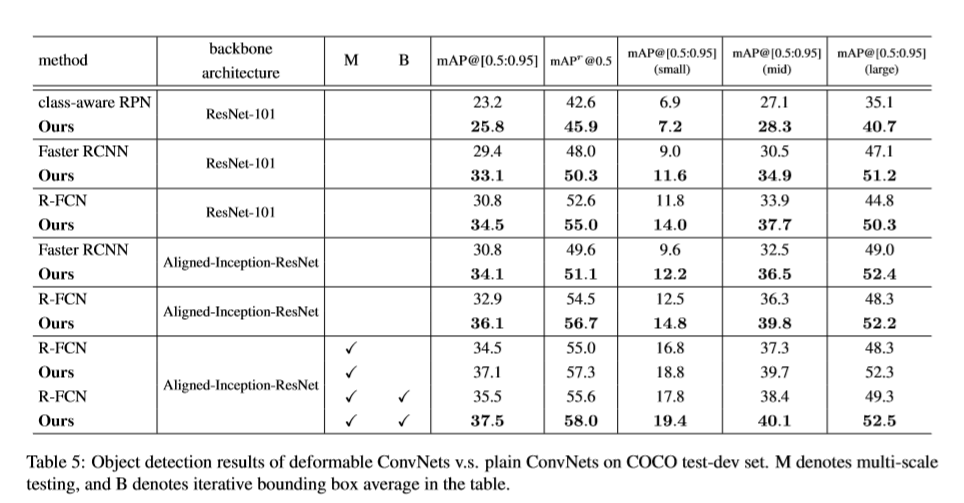
Reference
[1] Y.-L. Boureau, J. Ponce, and Y. LeCun. A theoretical analysis of feature pooling in visual recognition. In ICML, 2010. 1
[2] B. D. Brabandere, X. Jia, T. Tuytelaars, and L. V. Gool. Dynamic filter networks. In NIPS, 2016. 6
[3] J. Bruna and S. Mallat. Invariant scattering convolution networks. TPAMI, 2013. 6
[4] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Semantic image segmentation with deep convolutional nets and fully connected crfs. In ICLR, 2015. 4, 7
[5] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. arXiv preprint arXiv:1606.00915, 2016. 4, 6, 7
[6] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In CVPR, 2016. 7

 浙公网安备 33010602011771号
浙公网安备 33010602011771号