论文阅读笔记三十五:R-FCN:Object Detection via Region-based Fully Convolutional Networks(CVPR2016)

论文源址:https://arxiv.org/abs/1605.06409
开源代码:https://github.com/PureDiors/pytorch_RFCN
摘要
提出了基于区域的全卷积网络,用于精确高效的目标检测,相比于基于区域的检测器(Fast/Faster R-CNN),这些检测器重复的在子区域进行数百次计算,而本文在整张图像上进行共享计算。因此,本文提出了基于位置敏感分数图用于解决图像分类中的平移不变性及目标检测中的平移可变性之间的矛盾。将图像分类网络处理为全卷积网络用于目标检测。
介绍
目标检测的网络可以被RoI pooling划分为两部分,(1)独立于RoIs的共享的全卷积子网络。(2)不共享计算的RoI子网络。这种形式的拆分在历史上是开创性分类结构的结果,像AlexNet,VGG等包含两个子网络。包含一个结尾为空间池化层的卷积子网络,另一部分为后接的全连接层。因此,图像分类网络中的最后一个空间池化层自然变为目标检测网络中的RoI pooling层。
效果较好的分类网络如,ResNet及GoogleNet等为全卷积层进行分类。相类似的,在目标检测网络中使用全卷积层构建共享的卷积子网络。使RoI子网络没有隐藏层。但实验发现,这种解决方案得到的检测精度十分低,与分类网络较高的准确度十分不匹配。为了解决此问题,Faster R-CNN中将RoI pooling非自然的插入在两个卷积层之间,提高了RoI子网络的深度,同时提高了精度,但由于每个Roi并非是共享计算的,因此,运行速度较慢。
本文认为上面的设计的不合理主要是由于图像分类中增加的平移不变性,而目标检测中的重视平移带来的变化二者之间的矛盾。一方面,图像级别的分类更偏向于平移不变性,图像中物体的移动并不影响分类结果的判定。因此,深度卷积网络结构最后尽可能的具有平移不变性。另一方面,目标检测的任务需要在一定程度上可以表示平移的变化。而分类网络中的深度卷积网络具有平移不变性。为了解决此问题,基于ResNet的检测网络在卷积层中插入RoI pooling层。区域确定操作打破了分类网络的平移不变性。当评估不同的区域时,后面的RoI层不再具有平移不变性。但这种设计引入大量的region-wise网络层,因此不利于训练及测试的效率。如下图。

本文提出了一个基于区域的全卷积网络(R-FCN)用于目标检测,网络包含共享的全卷积结构。为了将平移变化引入FCN,利用一组特殊的卷积层作为FCN的输出,构造了一系列对位置较为敏感的得分图。每个score map都针对相对空间位置信息进行编码。在FCN的顶部添加了一个对位置敏感的RoI池化层,用于处理从score map得到的信息。整个网络可学习的层为在整张图片上的共享卷积及编码用于目标检测的空间位置信息。网络结构如下
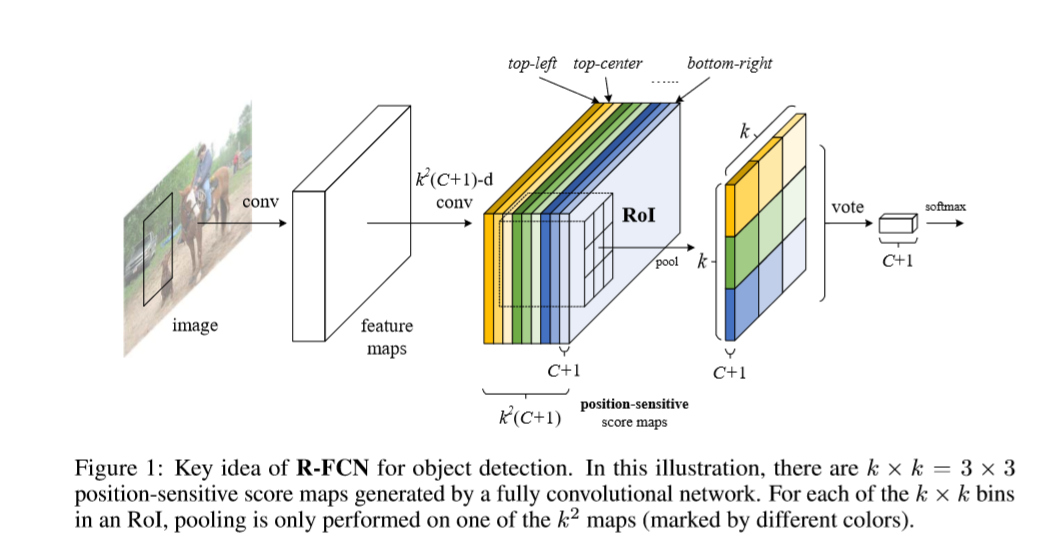
本文基于ResNet-101的backbone,R-FCN在PASCAL VOC2007上得到的结果为83.6%,在2012上得到的结果为82%.同时,速度要比基于ResNet-101的Faster R-CNN快2.5至20倍,实验证明本文方法可以很好的解决平移中的变化。基于全卷积的图像分类网络ResNet可以有效的被处理成全卷积网络用于目标检测。
本文方法
本文采用两阶段的目标检测策略:(i)region proposal(ii)region classification 虽然存在不依赖于region proposal的方法,但基于区域的方法仍然是效果最好的。本文通过全卷积网络RPN提取候选区域,本文在RPN及R-FCN网络之间共享特征。如下图所示。
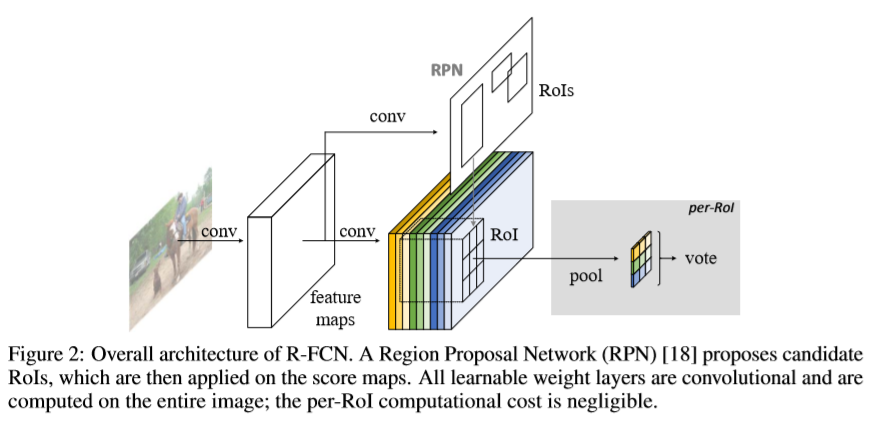
给定proposal regions,R-FCN的结构用于对RoI分类为目标类别及背景。R-FCN中,带有可学习权重的层只有在整张图片中的共享卷积。最后一层卷积输出一系列针对每个类别的大小为kxk 位置敏感的score maps,因此会有kxkx(c+1)维的输出。kxk的score map与一个描述相对位置的kxk的空间格子相对应。(大小为3x3,9个score maps编码一个目标的9种情况{top-left,top-center,top-right,....,botton-right})
R-FCN以位置敏感的RoI pooling 层结束。这一层聚合最后一层卷积层的输出,同时对每个RoI生成score.我们的位置敏感RoI层进行选择池化操作,每个大小为kxk的bin。每个大小为kxk的格子聚合来自一个score map中的响应。当进行端到端的训练时,RoI 层引导最后一层卷积来学习明确的位置敏感score maps。

backbone architecture:R-FCN基于ResNet-101,ResNet-101具有100层卷积层+全局平均池化层+1000个类别的全连接层。本文只用到了ResNet-101中的卷积层。在卷积层中应用空洞卷积,及在ImageNet上进行预训练。ResNet的最后一个卷积block为2048维。本文增加了一个1024x1x1的卷积层用于将为。然后使用kxkx(c+1)通道的卷积层生成score maps。
位置敏感 score maps及位置敏感RoI Pooling:为了编码每个RoI的位置信息。将每个ROI矩形框分为kxk个bins。对于一个大小为wxh的矩形框。一个格子的大小为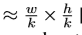 ,本文最后一层卷积层针对每个类别生成kxk个score maps。在第(i,j)个格子,定义一个roi pooling 操作用于池化第(i,j)个score map。kxk的位置敏感score 在RoI上进行投票。通过平均的scores进行投票。对于每个RoI产生一个(C+1)维的向量, 然后计算每个类别的softmax响应
,本文最后一层卷积层针对每个类别生成kxk个score maps。在第(i,j)个格子,定义一个roi pooling 操作用于池化第(i,j)个score map。kxk的位置敏感score 在RoI上进行投票。通过平均的scores进行投票。对于每个RoI产生一个(C+1)维的向量, 然后计算每个类别的softmax响应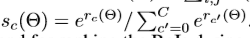 ,基于交叉熵损失进行评估。
,基于交叉熵损失进行评估。

本文以一种相似的方式进行框回归。 基于kxkx(C+1)维的卷积层,增加了一个4xkxk维的卷积层用于进行框回归。对于每个RoI生成一个4xkxk维的向量。通过平均通票最终得到一个4维的参数向量,代表边界框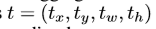 。
。
训练:损失函数定义为每个RoI框回归的交叉熵损失 ,c*代表RoI的ground -truth 标记,
,c*代表RoI的ground -truth 标记, 为类别交叉熵损失。将正样本定义为IOU大于0.5,其余的定义为负样本。假设一张图中 存在N个proposal。计算propsoal的损失,将其排序,选取排序最高的B个RoIs。对挑选的样本进行反向传播。
为类别交叉熵损失。将正样本定义为IOU大于0.5,其余的定义为负样本。假设一张图中 存在N个proposal。计算propsoal的损失,将其排序,选取排序最高的B个RoIs。对挑选的样本进行反向传播。
测试:推理后的结果基于NMS进行处理,阈值设置为0.3.
空洞卷积及stride:将ResNet-101的stride从32变为16像素,增大score map的分辨率。在conv5 block中执行stride=2变为stride=1。所有conv5的卷积核用空洞算法进行替换。结果如下。

实验




Reference
[1] S. Bell, C. L. Zitnick, K. Bala, and R. Girshick. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In CVPR, 2016.
[2] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Semantic image segmentation with deep convolutional nets and fully connected crfs. In ICLR, 2015.
[3] J.Dai,K.He,Y.Li,S.Ren,andJ.Sun. Instance-sensitivefullyconvolutionalnetworks. arXiv:1603.08678, 2016.
[4] D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov. Scalable object detection using deep neural networks. In CVPR, 2014.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号