论文阅读笔记三十四:DSSD: Deconvolutiona lSingle Shot Detector(CVPR2017)

论文源址:https://arxiv.org/abs/1701.06659
开源代码:https://github.com/MTCloudVision/mxnet-dssd
摘要
DSSD主要是向目标检测结构中增加语义信息。本文首先结合ResNet-101与SSD,然后,在此基础上添加反卷积层用于增大目标检测中的语义信息,从而提高目标物体尤其是小物体检测的准确率。本文主要研究在前向过程中添加附加单元至可学习模型中,本文主要指在前馈过程中反卷积与训练的模型输出之间的连接。
介绍
本文结构 SSD+ResNet-101+ 反卷积。近段时间,滑动窗口在目标检测任务中比较流行。与SS及R-CNN先生成候选框,然后分类器对一张图像中的候选框进行分类不同。其候选框逐渐增多,需要占用大量的资源。而滑动窗只需要有限的候选框,对于每个框除了预测类别的分数外,还有预测框的偏移量。YOLO结合全局feature map与全连接层对固定数量的区域进行预测,SSD结合网络每一层的特征,同时使用卷积核进行预测,得到更高的准确率。
效果更好的网络通过添加更多的语义信息,对小物体进行更好的检测。除了在预测时提高边界框的空间分辨率。以前版本的SSD基于VGG网络,但效果更好的网络基于ResNet-101,然而,使用更深的ResNet-101或者是添加反卷积层都无法立即生效,需要合理的将模型进行融合,进行高效的学习。
相关工作
SPPnet,Fast R-CNN,Faster R-CNN,R-FCN 及YOLO使用的都是网络前端的特征对不同尺寸的目标进行检测。而单层特征模型所有可能的目标尺寸及形状压力优点大。
有许多利用卷积网络中的多层特征来提高检测的准确率。ION使用L2正则化结合VGG中的多层特征用于目标框的生成。HyperNet也采用相似的方法 ,利用不同层的特征然后对特征进行pool操作,由于结合的特征包含输入图片中不同层次的信息。而池化后的特征更适合定位及分类。但是特征结合增加了内存,同时降低了模型的速度。
另一类包括利用卷积网络中的不同层来预测不同尺寸大小的目标。由于不同层中存在不同的感受野。因此,使用较大感受野的层预测大物体,使用较小的感受野对小物体进行预测。SSD将不同尺寸的默认框推广到卷积网络中的不同曾。并且强制每一层关注预测目标的特定尺寸。MS-CNN在多层卷积层中应用反卷积操作来增大feature map的分辨率。为了检测较小尺寸的物体,需要结合较低网络层的信息同时,feature map要较密集。但由于网络的低层缺少足够多的语义信息,因此对物体的分类存在不良影响。通过使用反卷积及跳跃结构,可以在密集的feature map中加入更多的语义信息,利于小目标物体的检测。
有部分工作主要在于结合上下文信息进行预测。Multi-Region CNN不仅从region proposals中池化特征。而且对预定义的区域(中心,边界等上下文区域)进行池化操作。借鉴现存的分割和姿态估计,使用编码-解码结构在预测前传递上下文信息。反卷积不仅解决了卷积网络中feature map分辨率的缩减,同时增加了预测的上下文信息。
Deconvolutional Single Shot Detection (DSSD) model
本文首先回顾SSD的结构,然后分析基于ResNet-101的SSD提高了训练效率。接下来,介绍如何增加反卷积层实现沙漏形状的网络,最后将反卷积与模型进行融合传递分割信息。
SSD
SSD在基础网络的顶部开始建立,以几层卷积层结束。如图1,SSD增加了一个小型卷积层。增加的层及先前的几层用于预测框的偏移及分数。预测通过3x3xchannels的卷积核进行预测,一个用于获得类别分数,另一个用于边界框的回归。使用NMS处理结果用于得到最终的检测结果。
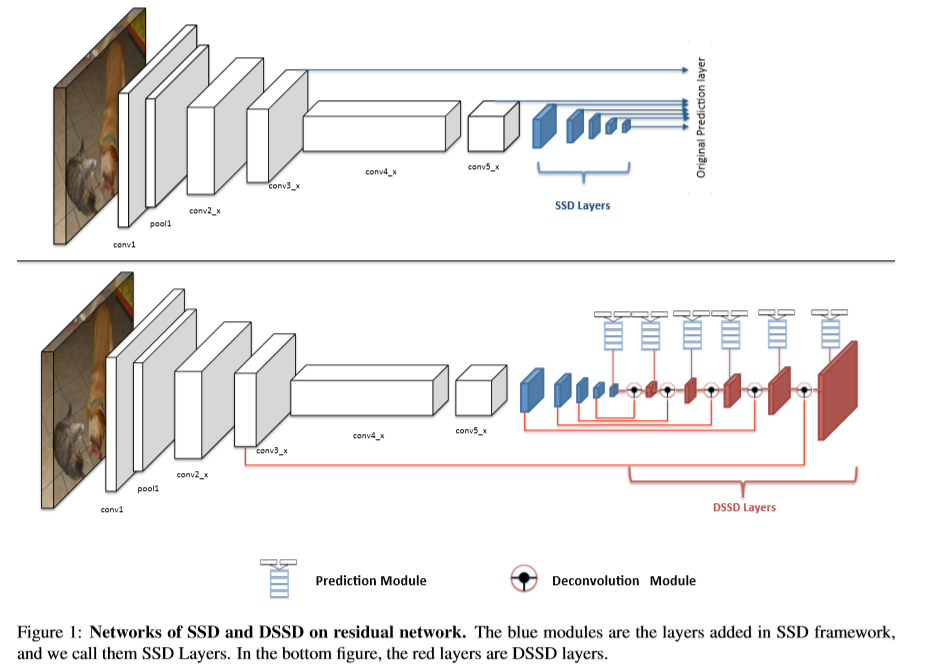
使用ResNet-101替换VGG:使用ResNet-101替换SSD中的VGG,从而提高检测的准确率。在resnet的conv5_x层后增加层,在conv3_x,conv5_x及增加的层进行预测分数及框的偏移。但实验发现,并没有对结果改善结果。
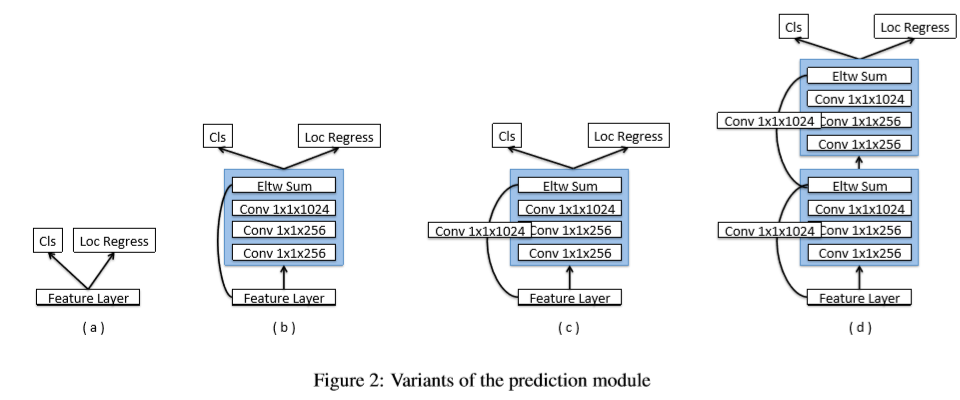
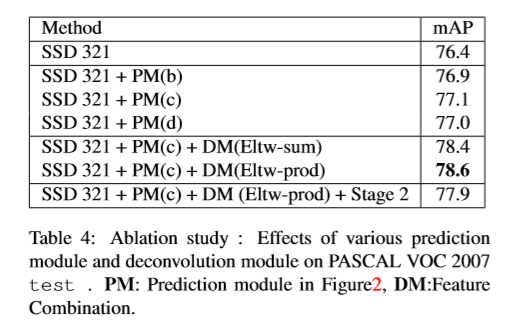
预测模块:在原始的SSD中,由于较大的梯度值,因此,将目标函数直接应用于挑选的feature map中,同时conv4_3层上应用L2正则化。MS-CNN指出提高每个子网络相关任务上的性能可以提高准确率。基于此,在每个预测层中增加了一个残差连接。如下图c,实验发现使用ResNet-101的检测效果要由于原始SSD中的VGG。
Deconvolutional SSD:为了在检测时得到更多高层次的上下文信息,将预测放到一系列反卷积层中。形成一种对称的沙漏形状的网络。本文基于ResNet-101进行搭建DSSD,后续的反卷积层用于怎加feature map 的分辨率。同时,为了增强特征,增加了跳跃连接结构。DSSD中的解码层很浅,主要有两个原因:(1)检测是视觉中的基础任务,需要为后续任务提供更多的信息。因此,速度是一个重要的因素。建立对称的沙漏型网络意味着inference的时间会加倍。不利于快速检测的要求。(2)由于分类只给出一整张图像的标记,而不是针对目标检测的局部标签,没有在ILSVRC 数据集中预训练的解码部分的预训练模型。效果较好的网络依赖于迁移学习,可以获得更高的准确率,同时,拟合的会更快,而DSSD没有预训练模型,因此,无法利用迁移学习的优势,另一方面是反卷积十分吃计算资源,特别是将以前层的信息添加到反卷积的过程中。
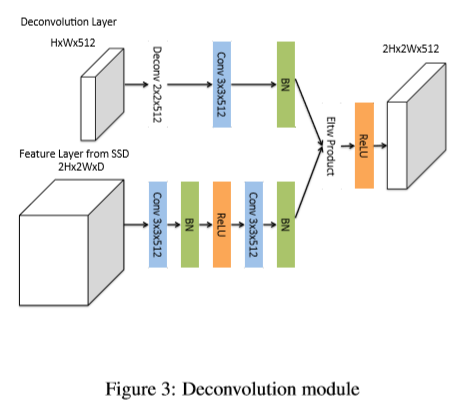
Deconvolution Module:为了将前层网络的信息与反卷积层进行融合,本文提出了反卷积模型,如下图,该模型嵌入在整个DSSD中。本文做了一下改进:(1)在每个卷积层后添加一层BN层。(2)用可学习的反卷积层替换双线性上采样(3)测试使用不同的结合方法,像素相加及像素点乘。
训练:参考SSD的训练策略。(1)将一系列默认框与ground truth进行匹配。方法是对每个ground truth box,挑出其与之匹配度(IOU)最高的默认框(2)其次,ground truth box与任意IOU大于0.5的default box。对于不匹配的default box,基于confidence loss选择确定的box,作为负样本,将正负样本之间的比例控制在1:3。然后,最小化联合训练位置损失(L1正则化)及confidence损失(Softmax)。由于Fast R-CNN及Faster R-CNN阶段没有特征或者像素的重采样过程,只是单纯的依赖于普通数据增强操作得到的数据。本文对原始的box的尺寸做了微小的设置。实验发现长宽比为2及3的尺寸比效果很好。本文基于box的面积的平方根为特征对训练box进行k-means聚类。
首先使用两个簇。如果误差改进超过20%,则增加簇的数量。本文聚集了7个簇,效果如下图。SSD网络将输入图片调整为方型,同时,由于大部分图片都比较宽。因此,大部分bounding box都比较高。实验观察,大部分box的比例在1-3范围内,因此,本文在网络的每一层增加(1.6,2.0,3.0)的尺寸比率。

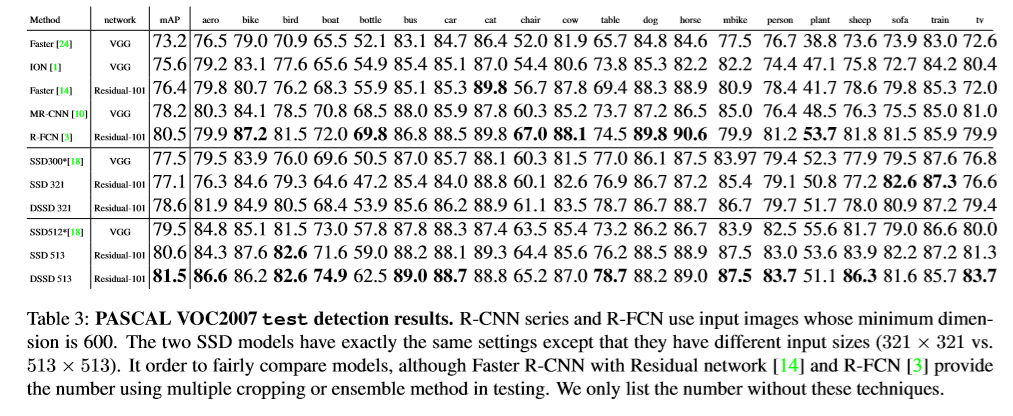
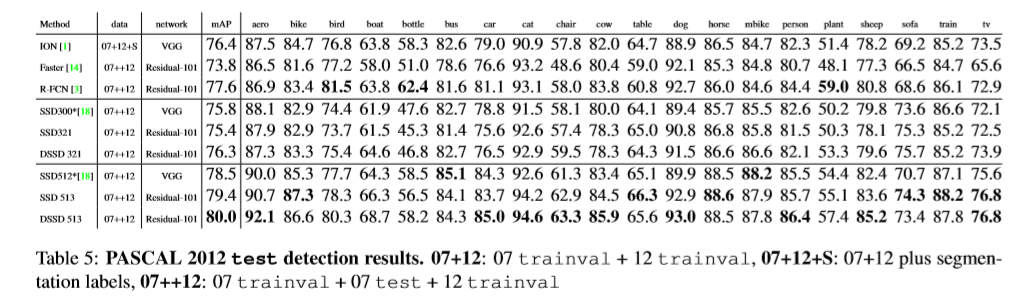
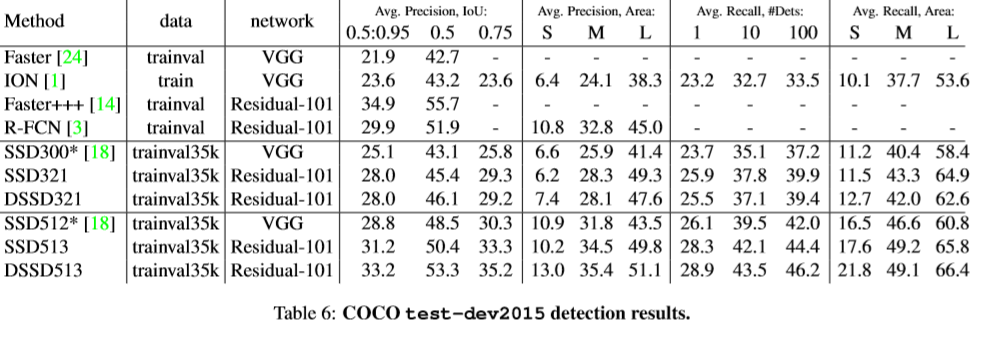
实验
基础网络:基于在ILSVRC CLS-LOC数据集上预训练的ResNet-101,遵从R-FCN,改变conv5的有效stride从32像素变为16像素,来增加feature map的分辨率。conv5的第一层卷积层的stride 由2变为1.应用空洞卷积算法,将dilation从1变为2。为了提高inference时间,按下式1,测试时将网络的BN层移除,按式子3及4重新定义权重及偏差。但仍无法和原始SSD一样快。原因:(1)ResNet-101比精简的VGG比较。(2)给模型附加的卷积层。(3)使用过多的default box。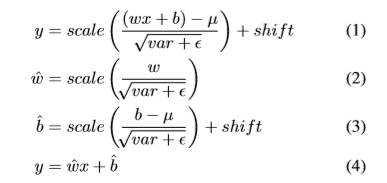




Reference
[1] S. Bell, C. L. Zitnick, K. Bala, and R. Girshick. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In CVPR, 2016. 2, 6, 7, 8
[2] Z. Cai, Q. Fan, R. S. Feris, and N. Vasconcelos. A unified multiscale deep convolutional neural network for fast object detection. In ECCV, 2016. 3, 4
[3] J. Dai, Y. Li, K. He, and J. Sun. R-fcn: Object detection via regionbased fully convolutional networks. In NIPS, 2016. 1, 2, 5, 6, 7, 8
[4] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In CVPR, 2005. 1
[5] D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov. Scalable object detection using deep neural networks. In CVPR, 2014. 1
[6] M.Everingham,L.VanGool,C.K.Williams,J.Winn,andA.Zisserman. The pascal visual object classes (voc) challenge. IJCV, 2010

 浙公网安备 33010602011771号
浙公网安备 33010602011771号