论文阅读笔记二十七:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks(CVPR 2016)

论文源址:https://arxiv.org/abs/1506.01497
tensorflow代码:https://github.com/endernewton/tf-faster-rcnn
室友对Faster R-CNN的解读:https://www.cnblogs.com/pursuiting/
摘要
目标检测依赖于区域proposals算法对目标的位置进行预测。SPPnet和Fast R-CNN已经减少了检测网络的运行时间。然而proposals的计算仍是一个重要的瓶颈。本文提出了一个Region Proposal Network(RPN),在检测网路中共享卷积网络得到的整张图片的feature map。RPN是全卷积网络可以同时预测目标物的边界和每个位置出目标的分数。RPN是进行端到端的训练用于产生高质量的候选区域。后送入Fast R-CNN进行检测。该文通过共享卷积将RPN与Fast R-CNN进行融合为一个整体。基于注意力机制,RPN指明网络需要注意观察的地方。
介绍
目标检测的先进方法包含一系列的区域框,和基于区域的卷积网络。由于proposals之间共享卷积的操作,使基于区域的卷积方法减少大量的计算资源。Fast R-CNN在忽略region proposal上的时间消耗外,可以近似实时的速率进行检测。proposals的计算是测试时占用大部分时间的主要部分。
候选区域的生成主要依赖于较简单的特征和推理方法。Selective Search基于较低级的特征融合超像素的方式生成proposals。但SS的速度仍然很慢,在CPU上每张图需要2s时间,EdgeBoxes能够生成较高质量的proposal,同时,速度上也有一定的保证,处理每张图的时间为0.2s。然而,region proposal的生成仍消耗与检测网络相同的时间。
该文在生成候选区域方法上做了一些改进,用深度卷积网络来获得proposals。可以大幅度提升计算时间。RPN通过共享卷积使测试时,时间的占用十分少。基于区域的检测器可以被卷积特征及逆行利用,用于产生region proposals。在卷积网络的顶部通过增加一些额外的卷积层构建RPN用于同时回归区域的边界和在预测该区域类别的分数。因此RPN为全卷积网络,同时可以进行端到端的训练用于产生检测区域框。
RPN通过一个较大范围的尺寸与比例系数来高效的预测候选区域。以前的方法是使用图像金字塔,和不同大小的卷积核进行处理,本文提出了不同尺寸与比例系数组合得到的多个anchor 用于生成proposal作为参考,提高了测试的速度。如下图,
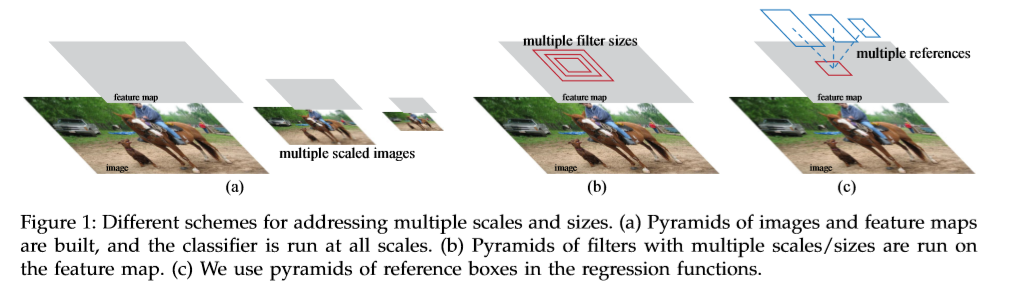
为了将RPN与Fast R-CNN融合在一起,本文,将proposals固定,交替的微调区域候选框生成任务和目标检测部分的网络。这样可以快速收敛,同时,卷积特征在两个任务之间共享可以实现网络的整合。
相关工作
目标候选区域生成的方法有:基于像素融合的SS,CPMC,MCG,基于滑动窗的EdgeBox等。目标区域框的被当作模型外的一部分,像基于SS的R-CNN和Fast R-CNN等。
基于深度网络的目标检测:R-CNN训练卷积网络用于对proposals进行前景/背景的分类。R-CNN主要作为一个分类器。并不进行目标框的预测,除了通过框的回归进行增强。其准确率主要依赖于proposal模型的表现。OverFeat基于全连接层对单个目标进行框坐标的预测。全连接层后接卷积层用于目标不同类别的确定。MultiBox方法从网络中生成区域候选框,该网络中的全连接层同时预测多个类别不确定的框。得到的类别不确定的框作为R-CNN的proposals。相比本文的全卷积机制,MultiBox网络应用在一个固定尺寸的输入图片上。同时,MultiBox在proposal和检测网络之间并未共享特征。
Faster R-CNN
该模型主要包含两个部分:(1)用于生成区域候选框的深度全卷积网络(2)Fast R-CNN用于作为检测器。 模型为一个单独一个整体用于目标检测。结构如下。
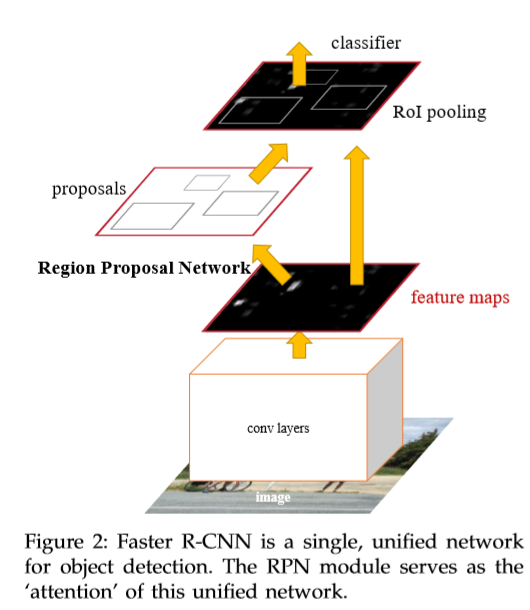
region proposal networks
RPN将任意尺寸大小的图片作为输入,输出一系列的矩形目标框,每一个框都有一个类别的分数。该文使用一个全卷积网络实现上述操作。由于要想与fast rcnn实现共享计算,假定两个模型有一个公共的卷积层。
为了生成区域候选框,在卷积层最后一层feature map上滑动一个小的网络。该小型网络将输入的卷积特征映射到一个nxn的空间窗口作为输入。每一个滑动窗口都映射为一个更低维的特征。得到的特征送入两个分支中,一个用于框分类,另一个用于框回归。mi-ni 网络执行滑动窗口形式,所有空间位置都共享全连接层。该结构可以看作是一个nxn的卷积网络后接两个1x1的卷积层。
Anchors
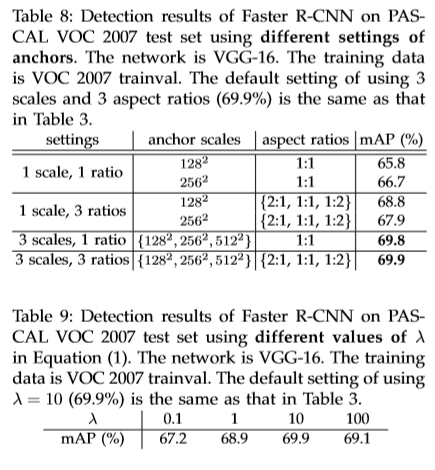
在滑动窗的每个位置,对多个候选区域同时进行预测,对于每个位置处,最大概率为目标proposal的个数记作k。因此,该部分模型输出为4xk用于编码k个框的坐标,和2xk个分数值用于表示k个框,前景/背景的概率。将kproposal叫做anchors。锚点处于滑动窗口的中心,并按照一定的尺寸及比例系数进行缩放。本文默认采用三种尺寸和比例系数,最终得到9个anchors在每个滑动位置处。对于一个大小为WxH的feature map,大约产生WHk个锚。
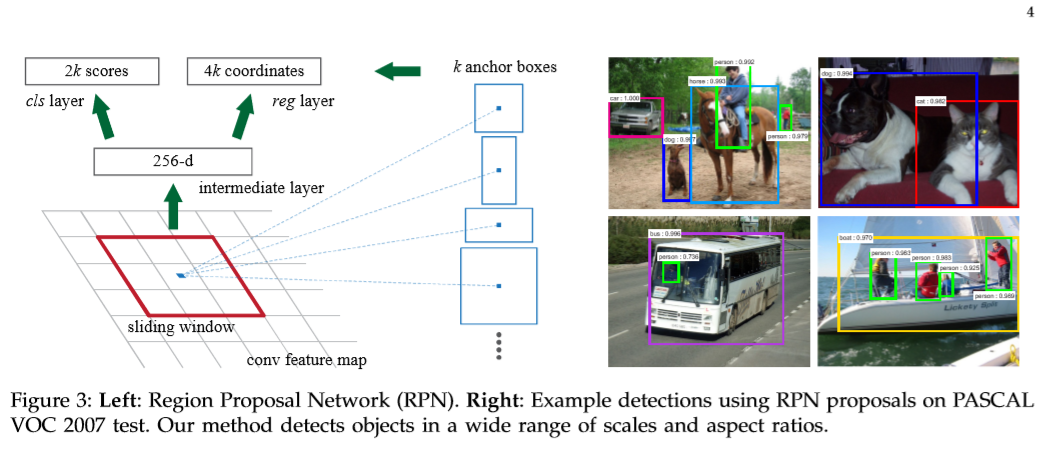
锚的平移不变性
锚的一个重要属性是平移不变性。如果图片中的物体发生了偏移,则proposal应该也进行平移,而相同的函数可以在预测出任意位置的proposal。
而Multibox是基于k-means来生成800个anchors,不具有平移不变性。同时,该方法可以减少大量的参数。并在小数据集上较少风险会产生过拟合。
多尺寸的锚作为回归准则
锚可以解决多尺寸问题(通过尺寸与比例系数)。本文基于不同尺寸的锚进行分类与回归操作。输入图片,与卷积核的尺寸都是固定的。
损失函数
针对RPN的训练,对每个anchor进行两类标记,前景/背景(二分类)。按两种方式对proposal进行正类标记:
(1)将与一个ground Truth IOU值最大的proposal/proposals标记为正类。
(2)一个anchor与任意IOU值高于0.7的标记为正类。
值得注意的是,一个ground truth 可以对用多个anchors。上述第二种方式无法有效的确定正样本。采用第一种方式进行标记,在少数情况下,第二种方式无法得到正样本。将与任意ground truth IOU的值低于0.3的标记为负样本。其中,既不是正样本,也不是负样本的proposal不考虑在训练目标范围内。
对于单张图片的损失函数定义如下:i代表一个batch中一个anchor的序列,pi代表预测为目标的概率,t_i为预测框的坐标,而t*代表positivate anchor的ground truth 框的坐标。

分类采样log损失,对于回归损失,采用L1平滑处理,按如下定义,通过设置k个权重不共享的锚,虽然,特征图相同,但可以预测出不同尺寸的bounding box。

RPN网络的训练
RPN可以基于反向传播与SGD进行端到端的训练。每张图包含许多正负样本。因此会训练所有样本,但由于负样本的数量占大多数,因此,会导致结果偏向于负样本。对一张图片随机采样256个样本,如果,正样本个数小于128个,则会用少量的负样本进行填充。
RPN与Fast R-CNN之间的共享特征
该文讨论了共享特征训练的三种方式:(1)交替训练:首先训练RPN,然后,用得到的proposals训练fast R-CNN,通过fast R-CNN调试后的网络初始化RPN网络。整个过程重复进行,这是本文使用的训练方法。(2)近似联合训练:此方法中,RPN与Fast R-CNN合为一个网络。训练时,每次SGD迭代,前向过程生成proposal,在训练fast r-cnn时这些proposals可以被看作是固定的。反向传播过程正常执行,当经过共享卷积层时,对RPN 与Fast R-CNN的损失函数正常进行。但此方法的反向传播忽略了框坐标的优化。因此是近似的联合训练。(3)第三种方式是非近似的联合训练,将RPN预测框坐标的损失函数也要及进行考虑,但需要增加新的pooling 层和处理方法,超出本文的讨论范围。
整体训练过程分为四步:
I.训练RPN网络,用ImageNet 预训练模型进行初始化,并用proposal进行迭代训练。
II.基于Fast R-CNN的检测网络的训练,使用第一步RPN得到的proposals进行训练。仍用ImageNet的预训练模型进行初始化。目前,二者并未进行共享卷积的计算。
III.用检测网络初始化RPN网络训练,将共享卷积层固定,只对RPN中的层进行微调。
IV固定共享卷积层,对只属于Fast R-CNN的层进行微调。
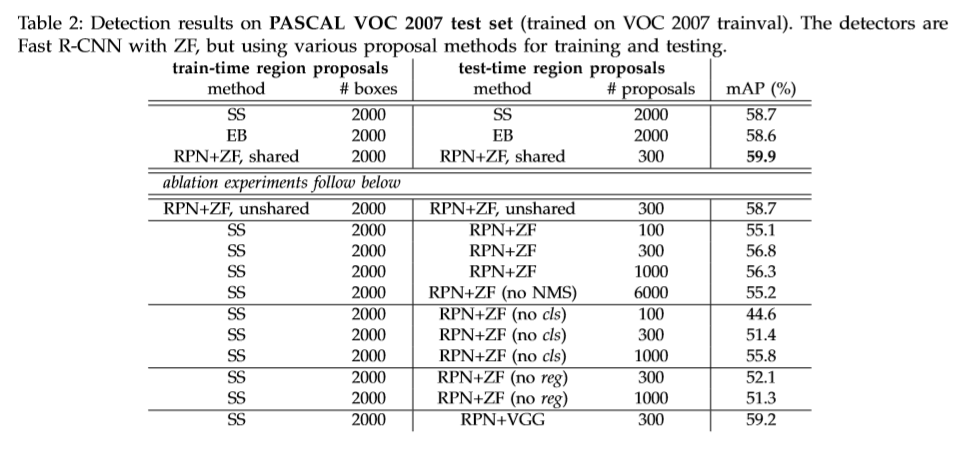
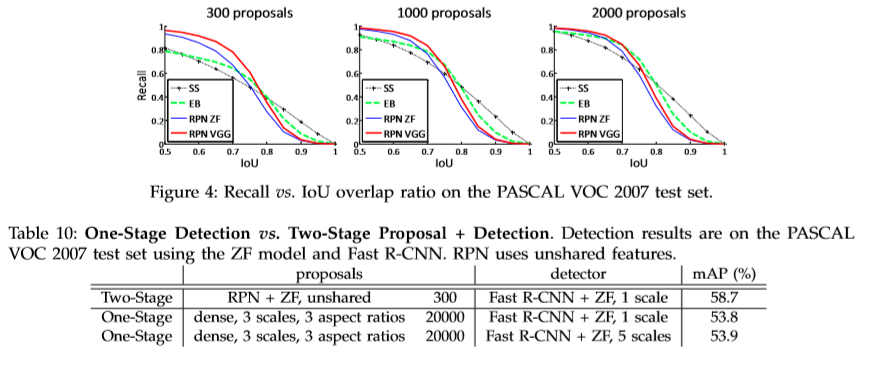
存在一些彼此高度重复的RPN框,基于类别分数采用NMS处理。将NMS的IOU设置为0.7,每张图得到2000多个proposals。使用NMS并未降低准确率,同时会减少proposal的数量。
实验
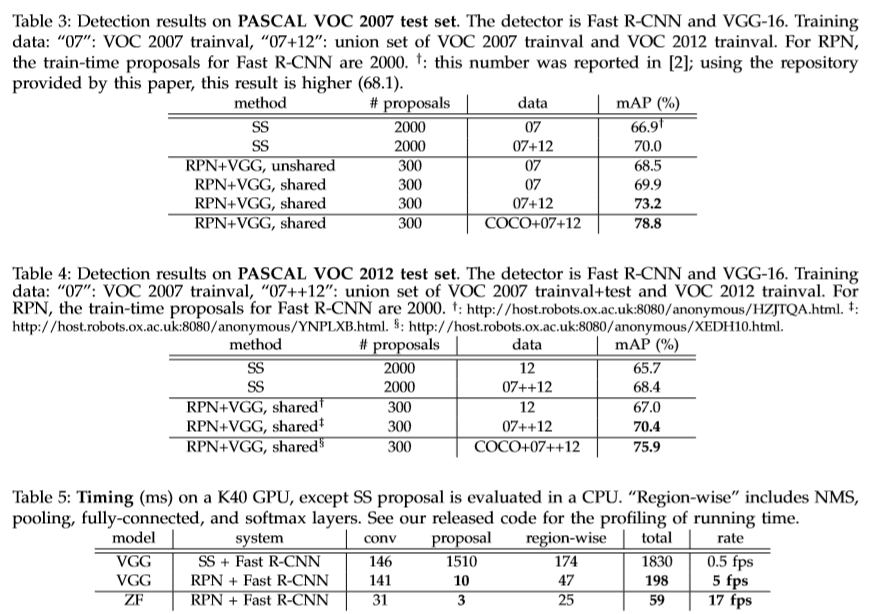
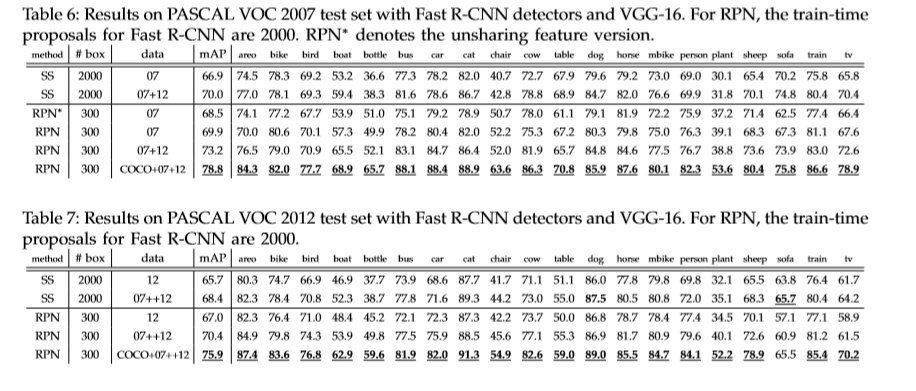
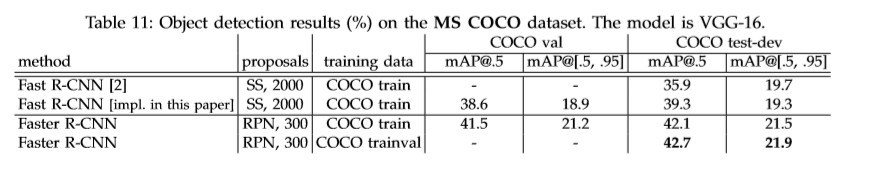
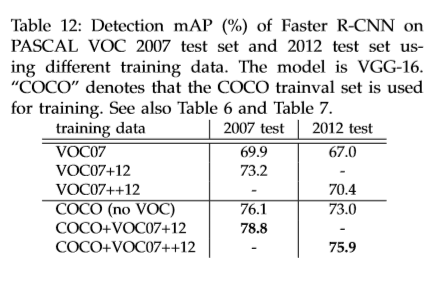

Reference
[1] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid pooling in deep convolutional networks for visual recognition,” in European Conference on Computer Vision (ECCV), 2014.
[2] R. Girshick, “Fast R-CNN,” in IEEE International Conference on Computer Vision (ICCV), 2015.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号