论文阅读笔记二十:LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation(CVPR2017)

源文网址:https://arxiv.org/abs/1707.03718
tensorflow代码:https://github.com/luofan18/linknet-tensorflow
基于Linknet的分割实验:https://github.com/fourmi1995/IronSegExperiment-LinkNet
摘要
像素级分割不仅准确率上有要求,同时需要应用的实际中实时的应用中。虽然精度上较高,但参数与操作上的数量都是十分巨大的。本文提出的网络结构参数并未增加。只使用了11.5million的参数量,与21.2GFLOPs用于处理3x360x480的图片。该网络在CAMVID上取得state-of-the-art的效果,同时,在Cityscapes上取得较好的结果。该文同时以不同图像分辨率在NVIDIA GPU上的处理时间进行比较。
介绍
由于像增强现实,自动驾驶等大量任务应用于像素级的分类分割任务上,因此像素级分割成为一个较热的研究点。受自编码器的启发,目前现存的分割网络以encoder-decoder作为主要网络结构。编码层将输入的信息编码到特征信息上,解码器将特征信息映射到空间分类中以进行分割。目标检测上中Fast RCNN,YOLO,SSD致力于实时的目标检测,但分割任务上实时性的相关工作仍未有所进展。
该文的贡献是在不影响处理时间的条件下得到较高分割准确率。一般,编码层由于卷积池化丢失的位置信息通过池化层最大值的索引或者全卷积操作进行恢复。
该文主要贡献是并未使用上述方法进行恢复,绕过空间信息,直接将编码器与解码器连接来提高准确率,一定程度上减少了处理时间。通过这种方式,保留编码部分中不同层丢失的信息,同时,在进行重新学习丢失的信息时并未增加额外的参数与操作。
相关工作
分割任务需要对每个像素进行标记,因此,空间信息的保留就比较重要,用于场景分析的分割网络一般可以分为编码-解码部分,分别用于分类与生成。state-of-the-art的分割网络大多使用ImageNet上的分类模型作为encoder部分。解码部分使用最大池化操作保留的索引或者学习反卷积的参数等。编码部分与解码部分可以是对称的,也可以是非对称的。大多数分割网络在嵌入式上都无法进行实时的分割。使用RNN来获得语义信息,但RNN的计算量较大。
网络结构
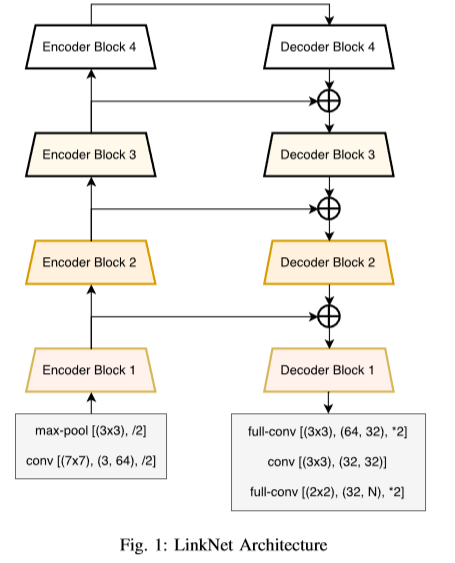
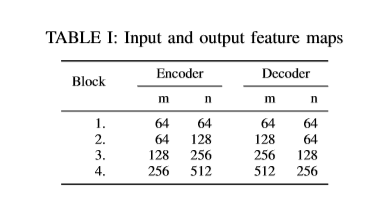
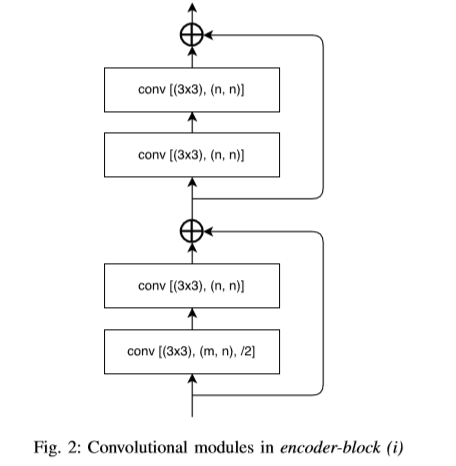
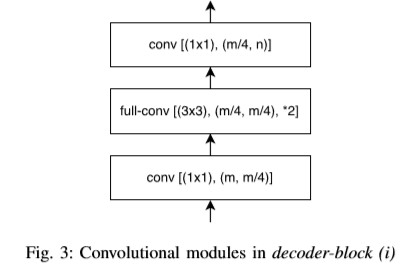
结果
比较方向:(1)网络执行前行过程的操作数。(2)Cityscapes与CamVid数据集上的准确率。
操作:类别不平衡处理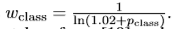 ,基于Pytorch框架,RMSProp优化方法。
,基于Pytorch框架,RMSProp优化方法。
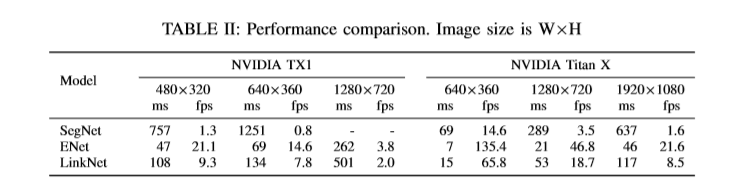


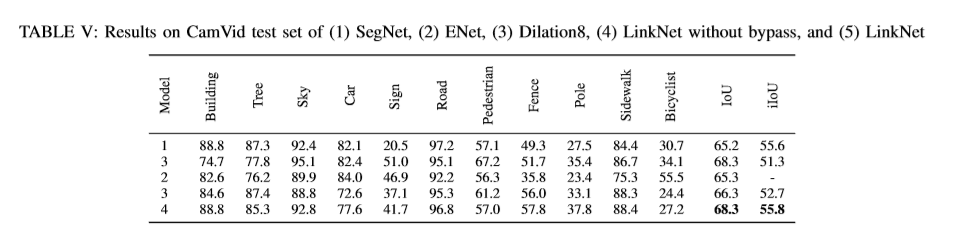
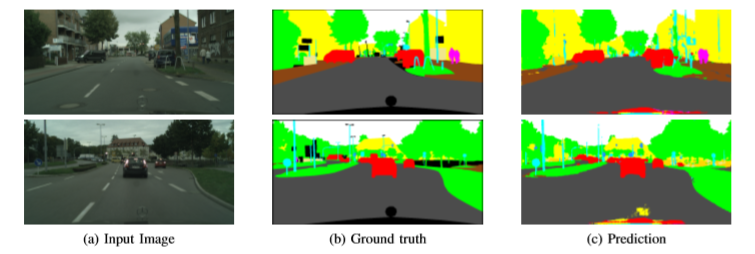

参考
[1] Y. LeCun and Y. Bengio, “Convolutional networks for images, speech, and time series,” The handbook of brain theory and neural networks, pp. 255–258, 1998.
[2] Y. LeCun, L. Bottou, G. B. Orr, and K. R. M¨uller, Neural Networks: Tricks of the Trade. Berlin, Heidelberg: Springer Berlin Heidelberg, 1998, ch. Efficient BackProp, pp. 9–50.
[3] M. A. Ranzato, F. J. Huang, Y.-L. Boureau, and Y. LeCun, “Unsupervised learning of invariant feature hierarchies with applications to object recognition,” in Computer Vision and Pattern Recognition, 2007. CVPR’07. IEEE Conference on, 2007, pp. 1–8.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号