一次mysql数据库性能调优
背景:使用Navicat执行show processlist(查看所有数据库进程),发现有大量state处在 “Opening tables”的进程,执行kill命令,再次执行show processlist发现command处于killed状态(此时线程已于客户端断开连接,但在服务器上并没有真正终止),执行SELECT * FROM information_schema.INNODB_TRX(查看是否有正在回滚的事务),发现处于killed状态的进程都在执行事务回滚,导致服务器性能达到阈值,使用ssh都无法登陆服务器,最终只能选择重启服务器,强制结束掉在执行回滚的进程(但是此操作可能会导致表损坏或是数据丢失,慎用,由于我这里是测试环境,无所谓了)
我很纳闷是什么原因导致存在大量的“Opening tables”进程,首先根据“Opening tables”进程中的info提示发现在执行一个多表关联sql,结合网上搜索结果,当同时打开表过多超过table_open_cache的阈值(默认64)时,新打开的表无法命中table cache(这里不太理解,还不太了解mysql内部原理),而不得不重新打开表,这样反应出来的现象就是有大量的线程处于opening tables状态,那么执行show GLOBAL STATUS like '%Open%_table%'看到如下图的结果,同时打开表(Open_tables)一直处于阈值,所以导致
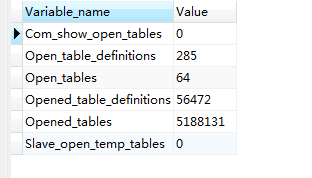 (图1)
(图1)
出现大量opening tables状态线程,那么如何优化那,可了解https://www.cnblogs.com/hzcya1995/p/13311797.html、https://www.cnblogs.com/CtripDBA/p/10304856.html,其中重要配置参考如下图,还了解到增大
 (图2)
(图2)
table_cache_instances可以加快remove_table对m_unused_tables的清理,也就会及时处理掉已打开且无用的表,原因是remove_table的触发条件是:table_open_cache/table_open_cache_instances&&m_unused_tables<m_table_count,其中m_table_count代表Open_tables,并且当table_open_cache_instances增大时,1个LOCK_open锁分散到多个m_lock的mutex上,大大降低了锁的争用,但是我未找到table_open_cache_instances这个参数,mysql官网说5.7版本后该值的默认值由1调为16,所以也没再修改此值。
总结:
1、优化sql,尽量减少多表查询;
2、调整table_open_cache的默认值,默认值太小了,具体值参考图2
3、调大table_cache_instances参数的值(如果能找到该参数的话),查看参数语句(show variables like '%table_open_cache%')
4、为保证性能,你应当设置为如下值:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号