C++ 内存模型与顺序一致性
顺序一致性
如果只是简单的进行线程间同步数据,而不考虑效率,那么使用原有的原子类型(atomic
什么是内存模型?
通常,内存模型是一种硬件上的概念,表示的是机器指令以什么样的顺序被处理器执行。
什么是顺序一致性?
C++11中的原子类型的变量,在线程中总是保持着顺序执行的特性,不会由于编译器或处理器对指令重排,从而导致原子变量的实际修改顺序与源代码的声明顺序不同。我们称这样的特性为“顺序一致性”。
为什么非原子类型不存在顺序一致性概念?
因为非原子类型不需要线程间同步。
为了加强理解,我们举例说明:
#include <thread>
#include <atomic>
#include <iostream>
using namespace std;
atomic<int> a{0};
atomic<int> b{0};
int ValueSet(int) {
int t = 1;
a = 1;
b = 2;
}
int Observer(int) {
cout << "(" << a << ", " << b << ")" << endl; // 可能有多种输出
}
int main() {
thread t1(ValueSet, 0);
thread t2(Observer, 0);
t1.join();
t2.join();
cout << "Got (" << a << ", " << b << ")" << endl; // 输出 Got(1, 2)
return 0;
}
// build command: g++ -std=c++11 main.cpp -lpthread
我们依据代码,画出如下线程示意图:
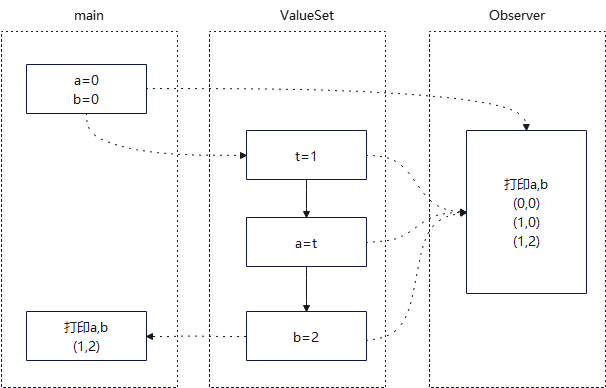
可以看出,Observer线程可能打印3种a、b的组合。是否能打印除(0, 2)这种组合?按代码顺序看,是不可能的,而实际上完全可能的。因为编译器或处理器,可能会对指令重排序(reorder),以提高性能。
上面程序代码,对于a、b赋值语句执行先后顺序,并没有严格要求;而下面的代码,如果对其执行优化,导致顺序颠倒,可能发生严重错误。
#include <thread>
#include <atomic>
#include <iostream>
using namespace std;
atomic<int> a{0};
atomic<int> b{0};
int Thread1(int) {
int t = 1;
a = t;
b = 2;
}
int Thread2(int) {
while (b != 2)
; // 自旋等待
cout << a << endl; // 总是期待a值为1
}
int main() {
thread t1(Thread1, 0);
thread t2(Thread2, 0);
t1.join();
t2.join();
return 0;
}
在Thread2中,我们期待b值为2时,a值已经为1(根据Thread1中,a、b赋值顺序)。然而,由于指令重排的影响,a、b赋值顺序可能颠倒,那么程序可能就会发生问题。
如何避免原子变量指令重排而导致的多线程问题?
默认情况下,C++11中的原子类型变量在线程中,总是保持着顺序执行的特性,即“顺序一致性”。这样,能最大限度保证程序的正确性。代码中,a赋值语句先于b赋值语句发生,这样的“先于发生”(happens-before)关系,在有些应用场景必须得到遵守,否则可能导致错误;而有些应用中,不需要遵守happens-before关系,而且可能进一步提升程序并行性能。
但,顺序一致也有代价,意味着低效的同步方式。
强顺序与弱顺序
假设我们的a、b的赋值语句编译出以下伪汇编代码:
t = 1
1: Loadi reg3, 1; # 将立即数1放入寄存器reg3
a = t
2: Move reg4, reg3; # 将reg3的数据放入reg4
3: Store reg4, a; # 将寄存器reg4的数据存入内存地址a
b = 2
4: Loadi reg5, 2; # 将立即数2放入寄存器reg5
5: Store reg5, b; # 将寄存器reg5的数据存入内存地址b
按通常的理解,指令按"1->2->3->4->5"的顺序执行。如果处理器的执行顺序与代码声明顺序相同,我们称这样的内存模型为强顺序的(strong ordered)。
而有些处理器可能会将指令执行顺序打乱,如按"1->4->2->5->3"的顺序执行(通常是超标量流水线)。如果指令按这个顺序被处理器执行,与代码声明顺序不同,我们称这样的内存模型为弱顺序的(weak ordered)。
强顺序、弱顺序都是硬件上的概念。
对于多线程程序而言,强顺序,意味着看到的指令执行顺序是一致的;弱顺序,意味着看到的指令执行顺序可能不一致。
不同体系结构,如x86、PowerPC、Alpha等平台,强弱顺序模型可能是不一样的。代码中要保证指令执行顺序,就要加入一条所谓的内存栅栏(memory barrier)指令。该指令迫使已经进入流水线中的指令都完成后,处理器才执行后面的指令。
比如,我们在上面汇编代3、4之间插入一条Sync指令(PowerPC上的内存栅栏指令),确保sync之前的指令总是先于sync知乎的指令完成。
t = 1
1: Loadi reg3, 1; # 将立即数1放入寄存器reg3
a = t
2: Move reg4, reg3; # 将reg3的数据放入reg4
3: Store reg4, a; # 将寄存器reg4的数据存入内存地址a
4: Sync # 内存栅栏指令
b = 2
5: Loadi reg5, 2; # 将立即数2放入寄存器reg5
6: Store reg5, b; # 将寄存器reg5的数据存入内存地址b
既然弱顺序可能导致程序一致性问题,那么其意义何在?
弱顺序的内存模型,可以使得处理器进一步提升并行性,从而提升程序性能。
顺序一致性与内存模型的强弱顺序
C++中定义的内存模型和顺序一致性,跟硬件的内存模型的强顺序、弱顺序,有什么关系呢?
在高级语言和机器指令之间,还有一层隔离,由编译器完成。编译器可能出于代码优化考虑,会将指令前移或后移,以获得最佳运行性能的指令执行序列。
对于C++的内存模型,想要保证代码的顺序一致性,就需要做到这几点:
1)编译器保证原子操作的指令间顺序不变,即读写原子类型的变量的机器指令与代码编写者看到的是一致 ;
2)处理器对于原子操作的汇编指令的执行顺序不变。对x86,没有问题;对PowerPC,编译器要在每次原子操作后加入内存栅栏;
C++内存顺序(memory_order)
C++中,原子操作默认是顺序一致性的,即遵守happens-before。但有些代码想要提升性能,并不关心是否遵守happens-before。如何让程序针对一些代码打破happens-before的规则,另一些代码则遵守?
C++11中,设计者给出的解决方案是让程序员为原子操作指定所谓的内存顺序(memory_order)。比如,使用松散的内存模型(relaxed memory model)放松对原子操作的执行顺序的要求。
#include <thread>
#include <atomic>
#include <iostream>
using namespace std;
atomic<int> a{0};
atomic<int> b{0};
// 对ValueSet进行了修改, a、b赋值时使用了relaxed memory model
int ValueSet(int) {
int t = 1;
a.store(t, memory_order_relaxed);
b.store(t, memory_order_relaxed);
}
int Observer(int) {
cout << "(" << a << ", " << b << ")" << endl; // 可能有多种输出
}
int main() {
thread t1(ValueSet, 0);
thread t2(Observer, 0);
t1.join();
t2.join();
cout << "Got (" << a << ", " << b << ")" << endl; // 输出 Got(1, 2)
return 0;
}
由于使用了relaxed memory model,a、b的赋值语句执行顺序并没有要求,编译器或处理器可以按需要重排。
memory_order有哪些?
C++11共定义6种memory_order枚举值:
| 枚举值 | 定义规则 |
|---|---|
| memory_order_relaxed | 不对执行顺序做任何保证 |
| memory_order_acquire | 本线程中,所有后续的读操作必须在本条原子操作完成后执行 |
| memory_order_release | 本线程中,所有之前的写操作完成后才能执行本条原子操作 |
| memory_order_acq_rel | 同时包含memory_order_acquire和memory_order_release标记 |
| memory_order_consume | 本线程中,所有后续的有关本原子类型的操作,必须在本条原子操作完成后执行 |
| memory_order_seq_cst | 全部存取都按顺序执行 |
memory_order_seq_cst 表示该原子操作必须是顺序一致的,这是C++11中所有atomic原子操作的默认值,即不带memory_oder参数的原子操作。
memory_order_relaxed 表示该原子操作是松散 ,可以被任意重排顺序。
哪些原子操作使用memory_order参数?
通常,atomic成员函数可使用的memory_order值可分为3组:
1)原子存储操作(store):可使用memory_order_relaxed、memory_order_release、memory_order_seq_cst;
2)原子读操作(load):可使用memory_order_relaxed、memory_order_consume、memory_order_acquire、memory_order_seq_cst;
3)RMW操作(read-modify-write):需要同时读写操作,如atomic_flag的test_and_set(),atomic的atomic_compare_exchange()。可使用memory_order_relaxed、memory_order_consume、memory_order_acquire、memory_order_release、memory_order_acq_rel、memory_order_seq_cst 。
其他操作,如operator=、operator+=等,都是memory_order_seq_cst作为默认参数的简单封装。
如果程序员需要顺序一致性的内存模型,之间调用atomic不带memory_order参数的函数版本即可,包括operator=这样的操作符;
如果要指定内存顺序的话,则应该采用如load、atomic_fetch_add这样的版本,支持传入memory_order参数。
如何使用memory_order?
还是基于前面的例子,假如我们想让thread1中,a赋值一定先于b赋值;thread2中,b读取一定先于a读取。可以这样前面的程序:
#include <thread>
#include <atomic>
#include <iostream>
using namespace std;
atomic<int> a{0};
atomic<int> b{0};
int Thread1(int) {
int t = 1;
a.store(t, memory_order_relaxed);
b.store(t, memory_order_release); // 本原子操作前所有写原子操作必须完成
}
int Thread2(int) {
while(b.load(memory_order_acquire) != 2); // 本原子操作必须完成, 才能执行后面所有读原子操作
cout << "(" << a.load(memory_order_relaxed) << endl; // 1
}
int main() {
thread t1(Thread1, 0);
thread t2(Thread2, 0);
t1.join();
t2.join();
return 0;
}
根据代码,2个线程对a、b执行读写指令顺序,如下图所示:
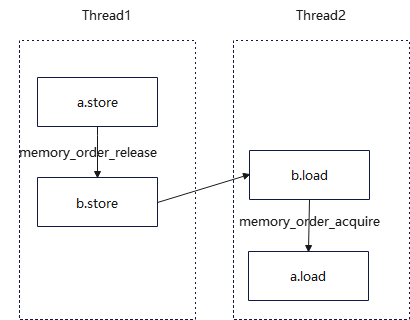
memory_order_release和memory_order_acquire常结合使用,成这种内存顺序为release-acquire内存顺序。不仅可以用了确保同一线程的指令顺序,还可以确保不同线程间指令顺序。
还有一种常用的内存顺序:release-consume,用于确保Produce、Consume线程间原子操作的顺序。memory_order_consume是比memory_order_acquire更宽松的内存顺序,在当前线程中,只确保所有后续对同一原子变量操作,必须在本原子操作之后。而memory_order_acquire是作用于后续的所有原子操作。
release-consume示例例:
#include <thread>
#include <atomic>
#include <string>
#include <cassert>
using namespace std;
atomic<string> ptr;
atomic<int> data;
void Producer() {
string* p = new string("hello");
data.store(43, memory_order_relaxed);
ptr.store(p, memory_order_release); // 本原子操作前所有写原子操作必须完成
}
void Consumer() {
string* p2;
while (!(p2 = ptr.load(memory_order_consume)))
;
assert(*p2 == "hello"); // 总是相等
assert(data.load(memory_order_relaxed) == 42); // 可能断言失败
}
int main() {
thread t1(Producer);
thread t2(Consumer);
t1.join();
t2.join();
return 0;
}
参考
[1]MichaelWon, IBM XL编译器中国开发团队. 深入理解C++11:C++11新特性解析与应用[M]. 机械工业出版社, 2013.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号