
SGI STL迭代器 iterators
迭代器的设计思想
GoF提到iterator设计模式:
提供一种方法,使之能依序巡访某个聚合物(容器)所含的各个元素,而又无须暴露该聚合物的内部表述方式。
STL中的iterator(迭代器)正是践行了这些设计模式,其中心思想:将数据容器(containers)和算法(algorithm)分离开,彼此独立设计,最后用胶着剂将它们粘合到一起。如何将容器和算法良好地胶合到一起,是重难点所在。
如何才算是将容器和算法良好粘合到一起呢?
以std::find()算法为例,其源码:
// from SGI <stl_algo.h>
template<class InputIterator, class T>
InputIterator find(InputIterator first, InputIterator last, const T& value)
{
while (first != last && *first != value)
++first;
return first;
}
可见,find算法并不知道具体的迭代器类型,也不知道其内部细节,只是对迭代器调用了operator!=、operator++、解引用(dereference)操作,对迭代器所指元素调用operator!=。
也就是说,如果我们传入find()的迭代器实参,实现了这几个接口即可。
这样,对于不同迭代器类型,find()也能很好地工作:
#include <vector>
#include <list>
#include <deque>
#include <algorithm>
#include <iostream>
using namespace std;
int main()
{
const int arraySize = 7;
int ia[arraySize] = {0,1,2,3,4,5,6};
vector<int> ivect(ia, ia + arraySize);
list<int> ilist(ia, ia + arraySize);
deque<int> ideque(ia, ia + arraySize);
vector<int>::iterator it1 = find(ivect.begin(), ivect.end(), 4); /* ivect中查找元素4 */
if (it1 == ivect.end())
cout << "4 not found." << endl;
else
cout << "4 found. " << *it1 << endl;
// 执行结果: 4 found. 4
list<int>::iterator it2 = find(ilist.begin(), ilist.end(), 6);
if (it2 == ilist.end())
cout << "6 not found." << endl;
else
cout << "6 found. " << *it2 << endl;
// 执行结果: 6 found. 6
deque<int>::iterator it3 = find(ideque.begin(), ideque.end(), 8);
if (it3 == ideque.end())
cout << "8 not found." << endl;
else
cout << "8 found. " << *it3 << endl;
// 执行结果: 8 not found.
return 0;
}
整个过程,find算法不知道迭代器内部细节,也不知道容器的细节,容器也不知道算法的细节。迭代器就是粘合容器和find算法的胶合剂。
迭代器的本质:smart pointer
迭代器行为类似于指针,但并不等于指针,而是类似于指针的对象,因为迭代器在指针的基础上,还包裹了其他功能,比如重载运算符operator,operator->。
指针的核心行为是解引用(dereference)、成员访问(member access),对应地,迭代器重要编程工作就是重载(overloading) 运算符operator、operator->。
假设我们现在有一个list(STL中list是双向链表,这里为了方便只设计成单向链表),要为其设计一个迭代器。
list容器:
template<typename T>
class List
{
void insert_front(T value);
void insert_end(T value);
void display(std::ostream& os = std::cout) const;
// ...
private:
ListItem<T>* _end;
ListItem<T>* _front;
long _size;
};
template<typename T>
class ListItem
{
public:
T value() const { return _value; }
ListItem* next() const { return _next; }
...
private:
T _value;
ListItem* _next; /* 单向链表 */
};
如何让这个List能使用前面的std::find()算法?
一种简单做法,就是按std::find()用到的迭代器的运算符,为我们要设计的迭代器ListIter重载operator*, operator->等运算符。
// List的迭代器类模板
template<class Item> /* Item可以是单向链表节点或双向链表节点, 该迭代器只为链表服务 */
struct ListIter
{
Item* ptr; // 保持与容器之间的一个联系
ListIter(Item* p = 0) // default ctor
: ptr(p) {}
// 不必实现copy ctor, default版本即可
// 不必实现operator=, default版本即可
Item& operator*() const { return *ptr; }
Item* operator->() const { return ptr; }
// 以下2个operator++遵循标准做法
// 1. pre-increment operator 前置式递增
ListIter& operator++()
{ ptr = ptr->next(); return *this; }
// 2. post-increment operator 后置式递增
ListIter operator++(int)
{ ListIter tmp = *this; ++*this; return tmp; }
bool operator==(const ListIter& other) const
{ return ptr == other.ptr; }
bool operator!=(const ListIter& other) const
{ return ptr != other.ptr; }
};
现在,可以将List和find()通过ListIter粘合起来了:
void main()
{
List<int> mlist;
for (int i = 0; i < 5; ++i) {
mlist.insert_front(i);
mlist.insert_end(i+2);
}
mlist.display(); // 10 {4 3 2 1 0 2 3 4 5 6}
ListIter<ListItem<int>> begin(mlist.front());
ListIter<ListIterm<int>> end; // default 0, null
ListIter<ListIterm<int>> iter; // default 0, null
iter = std::find(begin, end, 3);
if (iter == end)
cout << "not found" <<endl;
else
cout << "found. " << iter->value() << endl;
// 执行结果 found. 3
iter = std::find(begin, end, 7);
if (iter == end)
cout << "not found" << endl;
else
cout << "found. " << iter->value() << endl;
//执行结果 not found
}
由于find()内部调用了*iter != value 来检查迭代器所指元素跟目标元素是否相等,而iter所指元素是ListItem
template<typename T>
bool operator!=(const ListItem<T>& item, T n)
{
return item.value() != n;
}
可看到这种设计并不好,因为暴露了太多List实现细节,客户端main()为了得到begin、end迭代器,不得不知道ListItem存在;ListIter class template中,为了实现operator++,还暴露了ListItem的next()函数;而且还不得不实现一个全局的operator!=。
下面,我们看如何用traits编程技法来解决这个问题。
迭代器关联类型 associated types
在算法中使用迭代器时,可能会用到关联类型(associated type),即迭代器所指之物的类型。
如果算法有必要声明一个变量,以“迭代器所指对象的类型”为类型,如何是好?
因为C++只支持sizeof(),不支持typeof()(GCC编译器操作符),而且RTTI性质(运行时类型识别)中的typeid(),获得的也只是类型名称(字符串),不能拿来做变量声明、定义。
一个比较好的解决办法是,利用function template的参数推导(argument deducation)机制。例如,
template<class I, class T>
void func_impl(I iter, T t)
{
T tmp; // 这里解决了问题, T就是迭代器所指之物的类型, 本例中为int
// ... 做原本func()应该做的全部工作
}
template<class I>
inline void func(I iter) // 这里只给func传入一个实参iter, 由function template机制推导出iter类型I
{
func_impl(iter, *iter); // func的工作全部移往func_impl
}
int main()
{
int i;
func(&i); // 例:如何在算法中定义一个由&i推导出的变量类型?
}
例子中,func()作为对外接口,把实际操作全部置于func_impl()中。func()利用function template机制,根据传入实参推导出iter类型I。然后在func_impl定义iter关联类型的变量tmp。
traits编程技法
迭代器所指对象的类型,称为该迭代器的value type。
注意与关联类型区别:关联类型是一种概念,value type是具体的类型(是一种特性),value type可以用来表述关联类型的具体类型。
template的参数推导机制虽好,可用于推导出value type,但仅适用于函数参数类型,而不适用于函数返回值类型。
因此,可以把template的参数类型推导,声明为内嵌型:
// 为迭代器MyIter内嵌类型value_type
template<class T>
struct MyIter // 陷阱:如果迭代器是原生指针,根本就没这样一个class type
{
typedef T value_type; // 内嵌类型声明(nested type)
T* ptr;
MyIter(T* p = 0) : ptr(p) { }
T& operator*() const { return *ptr; }
// ...
};
// 将“template的参数类型推导”机制,针对value type,专门写成一个function template
template<class I>
typename I::value_type func(I ite) // typename I::value_type是func的返回值类型
{ return *ite; }
// 客户端
// ...
MyIter<int> ite(new int(8)); // 定义迭代器ite, 指向int 8
cout << func(ite); // 输出:8
// 如果传给func的参数(迭代器),是一个原生指针,这种方式就失效了
注意:func()返回值类型必须加上关键字typename,因为T是一个template参数,在编译器具现化前,编译器不知道T是什么。也就是说,编译器不知道typename I::value_type 是一个类型,member function,还是data member。用关键字typename显式告诉编译器,这是一个类型,从而通过编译。(见Effective C++ 条款42)
声明内嵌类型有一个陷阱:不是所有迭代器都是class type,比如原生指针(native pointer)就不是。如果不是class type,就无法为它定义内嵌类型,但STL又必须接受原生指针作为迭代器,那要怎么办?
答案是可以针对这种特定情况,使用template partial specialization(模板偏特化)做特殊化处理。
Partial Specialization 偏特化
我们知道,一个class template参数包含模板参数类型、个数这2部分信息,偏特化是在这两方面做特殊化处理,但不是针对具体的特定类型作处理,而是作为通用模板的子集。针对具体类型做特殊处理,称为模板特例化(简称特化,template specialization),而不是偏特化(template partial specialization)。
关于模板特化、偏特化,可以参见C++ Primer学习笔记 - 模板特例化
假设有个class template:
// 通用版 class template
template<typename T>
class C{...} // 这个泛化版本允许(接受)T为任何类型
对T类型做出限制,让其仅适用于“T为原生指针”的情况,可以知道是一个partial specialization:
template<typename T>
class C<T*>{...} // 偏特化版class template,仅适用于“T为原生指针”的情况
// “T为原生指针”是“T为任何类型”的一个更进一步的条件限制
注:偏特化的class C<T*>仍然是一个模板,不过针对class C
有了这个技法,可以解决前面“内嵌类型”没能解决的问题。原来的问题是:原生指针并非class,无法定义内嵌类型(value_type)。现在,可以利用模板偏特化针对“迭代器的template参数为指针”的情况,设计特化版的迭代器。
如何针对迭代器参数为指针的情况,设计特化版迭代器,且看下面的 萃取内嵌类型。
萃取内嵌类型
参考前面用于提取迭代器的value_type特性的function template func(),写出一个更通用的class template,专门用来“萃取”迭代器的value type特性:
// 萃取内嵌类型value type
template<class I>
struct iterator_traits { // traits意为“特性”,用于萃取出模板参数I的关联的原生类型value type
typedef typename I::value_type value_type;
};
所谓traits,意义是,如果模板参数I定义有自己的value type,那么通过traits的作用,萃取出来的value_type就是I::value_type。
这样,如果I定义自己的value type,前面func具体可以改写:
template<class T>
tyename I::value_type func(I ite) // typename I::value_type是func返回值类型
{ return *ite; }
// 改写 ==>
template<class T>
typename iterator_traits<I>::value_type // 这一整行是函数返回值类型
func(I ite)
{ return *ite; }
多了一层间接性(利用iterator_traits<>来做萃取),好处是traits可以拥有特化版本。现在,可以让iterator_traits针对原生指针,拥有一个partial specialization:
// 原生指针不是class,没有内嵌类型,通过偏特化版本定义value type
template<class T>
struct iterator_traits<T*> // 针对原生指针设计的偏特化版iterator_traits
{
typedef T value_type;
};
这样,虽然原生指针int*不是一种class type,但也可以通过traits技法萃取出value type(iterator_traits偏特化版为其定义的,关联类型)。如此,就解决了先前的问题。
去掉常量性
针对“指向常数对象的指针(pointer-to-const)”,下面式子得到什么结果?
iterator_traits<const int*>::value_type
得到的是const int,而非int。然而,这并不是我们期望的,因为我们希望利用这种机制声明一个暂时变量,使其类型与迭代器的value type相同。而现在,声明一个无法赋值的临时变量(因为const属性),对我们没什么用。因此,如果迭代器是个pointer-to-const,我们应该设法令其value type为一个non-const类型。对此,设计一个特化版本:
// 通过针对pointer-to-const设计的偏特化版本,为萃取关联类型去掉const
template<class T>
struct iterator_traits<const T*>
{
typedef T value_type; // 注意这里value_type不再是const类型, 通过该偏特化版已经去掉了const属性
};
这样,不论面对自定义迭代器MyIter,原生指针int,还是pointer-to-const的const int,都可以通过iterator_traits萃取出正确的value type。
迭代器特性
traits扮演“特性萃取机”的角色,针对迭代器的traits称为iterator_traits,用于萃取各个迭代器特性。而迭代器特性,是指迭代器的关联类型(associated types)。为了让traits能正常工作,每个迭代器必须遵守约定,以内嵌类型定义(nested typedef)的方式,定义出关联的类型。这个约定,谁不遵守,后不能兼容STL。
当然,迭代器常用的关联类型不止value type,还有另外4种:difference type,pointer,reference,iterator category。如果希望开发的容器能与STL融合,就必须为你的容器的迭代器定义这5种类型。
如此,“特性萃取机”traits就能忠实地将各种特性萃取出来:
template<class I>
struct iterator_traits
{
typedef typename I::iterator_category iterator_category;
typedef typename I::value_type value_type;
typedef typename I::difference_type difference_type;
typedef typename I::pointer pointer;
typedef typename I::reference reference;
};
另外,iterator_traits必须针对传入类型为pointer、pointer-to-const者,设计偏特化版。
迭代器关联类型 value type
所谓value type,是指迭代器所指向的对象的类型,任何一个打算与STL算法完美搭配的class,都应该定义自己的value type内嵌类型。
迭代器关联类型 difference type
difference type 用来表示两个迭代器之间的距离,因此也可以用来表示容器的最大容量,因为对于连续空间的容器而言,头尾之间的距离就是最大容量。如果一个泛型算法提供计数功能,如STL count(),其返回值必须使用迭代器的difference type。
例如,std::count()算法对迭代器区间对值为value的元素进行计数:
template<class I, class T>
typename iteartor_traits<I>::difference_type // 这一整行是函数返回类型
count(I first, I last, const T& value)
{
typename iteartor_traits<I>::difference_type n = 0; // 迭代器之间的距离
for (; first != last; ++first)
++n;
return n;
}
原生指针的difference type
同value type,iterator_traits无法为原生指针内嵌difference type,需要设计特化版本。具体地,以C++内建ptrdiff_t(<stddef.h>)作为原生指针的difference type。
// 通用版,从类型I萃取出difference type
template<class I>
struct iterator_traits
{
...
typedef typename I::difference_type difference_type;
};
// 针对原生指针而设计的偏特化版
template<class I>
struct iterator_traits<T*>
{
...
typedef ptrdiff_t difference_type;
};
// 针对原生pointer-to-const而设计的偏特化版
template<class I>
struct iterator_traits<const T*>
{
...
typedef ptrdiff_t difference_type;
};
这样,任何时候,我们需要任何迭代器I的difference type的时候,可以这样写,而不论I是class type,还是pointer,或者const-to-pointer:
typename iterator_traits<I>::difference_type
迭代器关联类型 reference type
从“迭代器所指之物的内容是否允许改变”的角度看,迭代器分为两种:
1)不允许改变“所指对象的内容”,称为constant iterators(常量迭代器),例如const int* pic;
2)允许改变“所指对象的内容”,称为mutable iterators(摆动迭代器),例如int* pi;
当对一个mutable iterators进行解引用(dereference)时,获得不应该是一个右值(rvalue),而应当是一个左值(lvalue)。因为右值允许赋值操作(assignment),左值才允许。
而对一个constant iterator进行解引用操作时,获得的是一个右值。
int* pi = new int(5);
const int* pci = new int(9);
*pi = 7; // mutable iterator进行解引用操作时, 获得的是左值, 允许赋值
*pci = 1; // 不允许赋值, 因为pci是const iterator, 解引用pci获得的是右值
C++中,函数如果要传回左值,都是以by reference方式进行,所以当p是个mutable iterators时,如果是其value type是T,那么p的类型不应该是T,而应该是T&。
如果p是个constant iterators,其value type是T,那么p的类型不应该是const T,而应该是const T&。
这里讨论的*p的类型,也就是reference type。其实现细节,在下一节跟pointer type一起描述。
迭代器关联类型 pointer type
pointer与reference在C++关系非常密切。如果“传回一个左值,令它代p表所指之物”(reference)是可能的,那么“传回一个左值,令它代表p所指之物的地址”(pointer)也一定可以。pointer,就是指向迭代器所指之物。
reference type, pointer type类型,之前在ListIter class template中已经出现过:
Item& operator*() const { return *ptr; } // 返回值类型是reference type
Iterm* operator->() const { return ptr; } // 返回值类型是pointer type
现在,把reference type和pointer type这两个类型加入traits:
// 通用版traits
template<class I>
struct iterator_traits
{
...
typedef typename I::pointer pointer; // native pointer 无法内嵌pointer, 因此需要偏特化版
typedef typename I::reference reference; // native pointer 无法内嵌reference
};
// 针对原生指针的偏特化版traits
template<class I>
struct iterator_traits<T*>
{
...
typedef T* pointer;
typedef T& reference;
};
// 针对pointer-to-const的偏特化版traits,去掉了const常量性
template<class I>
struct iterator_traits<const T*>
{
...
typedef T* pointer;
typedef T& reference;
};
迭代器关联类型 iterator_category
先讨论迭代器分类。
迭代器类型
根据移动特性和施行操作,迭代器被分为5类:
- Input Iterator:这种迭代器所指对象,不允许外界改变,只读(read only)。
- Output Iterator:只写(write only)。
- Forward Iterator:允许“写入型”算法(如replace()),在此种迭代器所形成的的区间上进行读写操作。
- Bindirectional Iterator:可双向移动。某些算法需要逆向走访某个迭代器区间(录入逆向拷贝某范围内的元素),可使用Bindirectional Iterator。
- Random Access Iterator:前4种迭代器都只供应一部分指针算术能力(前3支持operator++,第4中加上operator--),第5中则涵盖所有指针算术能力,包括p+n, p-n,p[n],p1-p2,p1 < p2。
这些迭代器分类与从属关系:
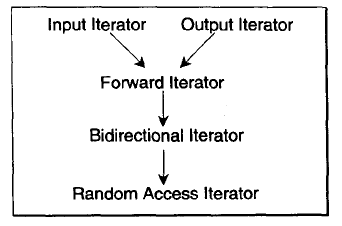
注:直线与箭头并发C++继承关系,而是所谓concept(概念)与refinement(强化)关系。
设计算法时,如果可能,应尽量针对某种迭代器提供一个明确定义,并针对更强化的某种迭代器提供另一种定义,重复利用迭代器特性。这样,才能在不同情况下,提供最大效率。
以advance()为例
advance()是一个许多算法内部常用的函数,功能是内部将p累进n次(前进距离n)。该函数2个参数:迭代器p,数值n。下面3分定义:分别针对Input Iterator,Bidirectional Iterator,Random Access Iterator。没有针对Forward Iterator设计的版本,因为和针对Input Iterator设计的版本完全一致。
// 针对InputIterator的advance()版本
// 要求 n > 0
template<class InputIterator, class Distance>
void advance_II(InputIterator& i, Distance n)
{
// 单向,逐一前进
while (n--) ++i; // or for(; n > 0; --n; ++i);
}
// 针对BidirectionalIterator的advance()版本
// n没有要求,可大于等于0,也可以小于0
template<class BidirectionalIterator, class Distance>
void advance_BI(BidirectionalIterator& i, Distance n)
{
// 双向,逐一前进
if (n >= 0)
while (n--) ++i; // or for (; n > 0; --n, ++i);
else
while (n++) --i; // or for (; n < 0; ++n, --i);
}
// 针对RandomAccessIterator的advance()版本
// n没有要求
template<class RandomAccessIterator, class Distance>
void advance_RAI(RandomAccessIterator& i, Distance n)
{
// 双向,跳跃前进
i += n;
}
现在,当程序调用advance()时,应选择哪个版本的函数呢?
如果选择advance_II(), 对Random Access Iterator效率极低,原本O(1)操作成了O(N);如果选择advance_RAI(),则无法接收Input Iterator(Input Iterator不支持跳跃前进)。
我们可以将三者合一,对外提供统一接口。其设计思想是根据迭代器i的类型,来选择最适当的advance()版本:
tempate<class InputIterator, class Distance>
void advance(InputIterator& i, Distance n)
{
if (is_random_access_iterator(i)) // 函数有待设计
advance_RAI(i, n);
else if (is_bidirectional_iterator(i)) // 函数有待设计
advance_BI(i, n);
else
advance_RAI(i, n);
}
这种方法的问题在于:在执行期才决定使用哪个版本,而且需要一个个判断,会影响程序效率。最好能在编译期就能选择正确的版本。函数的重载机制能达成这个目标。
上面的3个advance_xxx()都有2个函数参数(i,n),类型都未定(因为是template参数)。为了让这3个函数同名,形参重载函数,可以加上一个类型已经确定的函数参数,使得函数重载机制能有效运作起来。
设计考虑:如果traits有能力萃取出迭代器的类型,便可以利用这个“迭代器类型”的关联类型,作为advance()的第三个参数,让编译器根据函数重载机制自动选择对应版本advance()。这个关联类型一定是一种class type,不能是数值、号码类的东西,因为编译器需要依赖它进行函数重载决议(overloaded resolution),而函数重载是根据参数类型来决定的。
下面定义5个class,作为迭代器的类型,代表5种迭代器类型:
// 5个作为标记用的类型(tag types)
struct input_iterator_tag {};
struct output_iterator_tag {};
struct forward_iterator_tag : public input_iterator_tag {};
struct bidirectional_iterator_tag : public forward_iterator_tag {};
struct random_access_iterator_tag : public bidirectional_iterator_tag {};
这5个class只用作标记,不需要任何成员,因此不会有任何内存代价。现在重新设计__advance()(由于只在内部使用,因此所有函数名前加上特定前导符),并加上第三个参数,使之形成重载:
// 如果迭代器类型是input_iterator_tag,就会dispatch至此
template<class InputIterator, class Distance>
inline void __advance(InputIterator& i, Distance n, input_iterator_tag)
{
// 单向, 逐一前进
while (n--) ++i;
}
// 如果迭代器类型是forward_iterator_tag,就会dispatch至此
// 这是一个单纯的传递调用函数(trivial forwarding function), 稍后讨论如何免除之
template <class ForwardIterator, class Distance>
inline void __advance(ForwardIterator& i, Distance n, forward_iterator_tag)
{
// 单纯地进行传递调用(forwarding)
advance(i, n, input_iterator_tag());
}
// 如果迭代器类型是bidirectional_iterator_tag,就会dispatch至此
template<class BidirectionalIterator, class Distance>
inline void __advance(BidirectionalIterator& i, Distance n, bidirectional_iterator_tag)
{
// 双向, 逐一前进
if (n >= 0)
while (n--) ++i;
else
while (n++) --i;
}
template<class RandomAccessIterator, class Distance>
inline void __advance(RandomAccessIterator& i, Distance n, random_access_iterator_tag)
{
// 双向, 跳跃前进
i += n;
}
注意:每个__advanec()最后一个参数都只声明类型,而未指定参数名称,因为纯粹只是用来激活重载机制,函数中不使用该参数。如果要加上参数名也可以,但不会用到。
至此,还需要对外提供一个上层控制接口,调用上述各个重载的__advance()。接口只需要两个参数,当它准备将工作转给上述的__advance()时,才自行加上第三参数:迭代器类型。因此,这个上层接口函数必须有能力从它所获得的迭代器中推导出其类型,这个工作可以交给traits机制:
// 接口函数, 利用iterator_traits萃取迭代器的类型特性iterator_category
template<class InputIterator, class Distance>
inline void advance(InputIterator& i, Distance n)
{
__advance(i, n, iterator_traits<InputIteartor>::iterator_category());
}
iterator_traits
关于iterator_category(),SGI STL 定义于<stl_iterator.h>。源码如下:
// iterator_category() 返回一个临时对象,类型是参数I的迭代器类型(iterator_category)
template<class I>
inline typename iterator_traits<I>::iterator_category // 一整行是含返回型别
iterator_category(const I&)
{
typedef typename iterator_traits<I>::iterator_category category;
return category(); // 返回临时对象
}
相应地,也应该在traits添加一个可萃取的类型特性(iterator_category),并针对native pointer和pointer-to-const设计偏特化版本:
// 通用版traits, 可用于萃取I的iterator_category
template<class I>
struct iteartor_traits
{
...
typedef typename I::iterator_category iterator_category; // 为traits添加萃取特性iterator_category
};
// 针对原生指针设计的 偏特化版本
template<class T>
struct iterator_traits<T*>
{
...
//注意, 原生指针是一种Random Access Iterator. why?
typedef random_access_iterator_tag iterator_category;
};
// 针对原生的pointer-to-const设计的偏特化版本
template<class T>
struct iterator_traits<const T*>
{
...
// 注意, 原生的pointer-to-const是一种Random Access Iterator
typedef random_access_iterator_tag iterator_category;
};
问题:注释里面提到“原生指针是一种Random Access Iterator. ?”为什么?
任何迭代器,其类型永远应该落在“该迭代器所隶属之各种类型中,最强化的那个”。例如,int*,既是Random Access Iterator,又是Bindirectional Iterator,同时也是Forward Iterator,而且是Input Iterator,那么其类型应该是最强化的random_access_iterator_tag。
问题:为什么advance()的template参数名称,是最低阶的InputIterator?而不是最强化的那个?
advance()能接受各种类型的迭代器,但其型别参数命名为InputIterator,这是STL算法的一个命名规则:以算法锁能接受的最低阶迭代器类型,来为其迭代器型别参数命名。
- 消除“单纯传递调用的函数”
用class来定义迭代器的各种分类标签,不仅可以促成重载机制运作,是的编译器能正确执行重载决议,还可以通过继承,我们不必再写“单纯只做传递调用的函数”,如前面__advance()的ForwardIterator版。
为什么?
因为编译器会优先匹配实参与形参完全匹配的函数版本,然后是从继承关系来匹配。这也是为什么5个迭代器类型中,存在继承关系。
...
// 前面提到的这个单纯的传递调用函数的__advance()版本,无需定义,因为forward_iterator_tag继承自input_iterator_tag,编译器没有匹配到与forward_iterator_tag严格匹配的版本时,就会从继承关系来匹配input_iterator_tag版的__advance()
// 如果迭代器类型是forward_iterator_tag,就会dispatch至此
// 这是一个单纯的传递调用函数(trivial forwarding function)
template <class ForwardIterator, class Distance>
inline void __advance(ForwardIterator& i, Distance n, forward_iterator_tag)
{
// 单纯地进行传递调用(forwarding)
advance(i, n, input_iterator_tag());
}
...
关于编译器在函数重载决议时,如何选择与实参类型匹配的版本。且看下面这个例子:
#include <iostream>
#include <string>
using namespace std;
struct B {};
struct D1 : public B {};
struct D2 : public D1 {};
template<class I>
void func(I& p, B)
{
cout << "B version" << endl;
}
template<class I>
void func(I& p, D2)
{
cout << "D2 version" << endl;
}
int main()
{
int* p;
func(p, B()); // 参数完全吻合, 输出"B version"
func(p, D1()); // 参数未能完全吻合, 因继承关系自动传递调用输出"B version"
func(p, D2()); // 参数完全吻合, 输出"D2 version"
return 0;
}
其中,func(p, D1())没有找到类型严格相同的函数版本时,会从继承关系中找。
以distance()为例
distance() 是一个常用迭代器操作函数,用来计算两个迭代器之间的距离。针对不同迭代器类型,有不同的计算方式,带来不同的效率。
这里不再详述推导出distance的过程,而是直接贴出源码:
// 2个__distance()重载函数
// 如果迭代器类型是input_iterator_tag,就dispatch至此
template<class InputIterator>
inline typename iterator_traits<InputIterator>::difference_type
__distance(InputIterator first, InputIterator last,
input_iterator_tag) {
typename iterator_traits<InputIterator>::difference_type n = 0;
// 逐一累计距离
while (first != last) {
++first; ++n;
}
return n;
}
// 如果迭代器类型是random_access_iterator_tag,就dispatch至此
template<class RandomAccessIterator>
inline typename iterator_traits<RandomAccessIterator>::difference_type
__distance(RandomAccessIterator first, RandomAccessIterator last,
random_access_iterator_tag)
{
// 直接计算差距
return last - first;
}
// 对用户接口, 可以自动推导出类型, 然后编译器根据推导出的iterator_category特性,
// 自动选择调用__distance()重载函数版本
/* 上层函数, 从所得的迭代器中推导出类型 */
template<class InputIterator>
inline typename iterator_traits<InputIterator>::difference_type
distance(InputIterator first, InputIterator last)
{
typedef typename iterator_traits<InputIterator>::iterator_category category; // 萃取迭代器类型iterator_category
return __distance(first, last, category()); // 根据迭代器类型,选择不同的__distance()重载版本
}
std::iterator的约定
前面讲过,为了符合规范,任何迭代器必须遵守一定的约定,提供5个内嵌关联类型,以便于traits萃取;否则,无法兼容STL。但如果每写一个迭代器,都要提供这5个内嵌关联类型,谁能保证每次都不漏掉或者出错?有没有一种更简便方式?
答案是有的,SGI STL在<stl_iterator.h>中提供一个公共iterator class,每个新设计的迭代器只需要继承它,就可以保证符合STL所需要规范:
template <class _Category, class _Tp, class _Distance = ptrdiff_t,
class _Pointer = _Tp*, class _Reference = _Tp&>
struct iterator {
typedef _Category iterator_category;
typedef _Tp value_type;
typedef _Distance difference_type;
typedef _Pointer pointer;
typedef _Reference reference;
};
iterator class不含任何成员,纯粹只是类型定义。因此继承自它并不会有任何额外负担(无运行负担、无内存负担)。而且后三个模板参数由于有默认值,新迭代器可以无需提供实参。
例如,前面自定义ListIter,改用继承自iterator方式,可以这些编写:
template<class Item>
struct ListIter : public iteratr<forward_iterator_tag, Item>
{
// ...
};
这样的好处是很明显的,可以极大地简化自定义迭代器类ListIter的设计,使其专注于自己的事情,而且不容易出错。
当然,我们也可以从SGI STL源码中看到,为5个迭代器类型input_iterator、output_iterator、forward_iterator、bidirectional_iterator、random_access_iterator都提供了各自的定义。这是为了向后兼容HP STL,实际上目前已经被struct iterator替代了。
总结
-
设计适当的关联类型(associated types),是迭代器的责任;设计适当的迭代器,是容器的责任。因为只有容器本身,才知道设计出怎样的迭代器来遍历自己,并执行迭代器的各种行为(前进,后退,取值,取用成员,...),至于算法,完全可以独立于容器和迭代器之外,只要设计以迭代器为对外接口即可。
-
traits编程技法大量应用于STL实现中,利用“内嵌类型”的编程技巧和编译器template参数推导功能,增强了C++未能提供的关于类型认证方面的能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号