muduo笔记 线程池ThreadPool
muduo线程池ThreadPool,采用的是固定线程数目的线程池方案。
线程池模型
模型图如下:
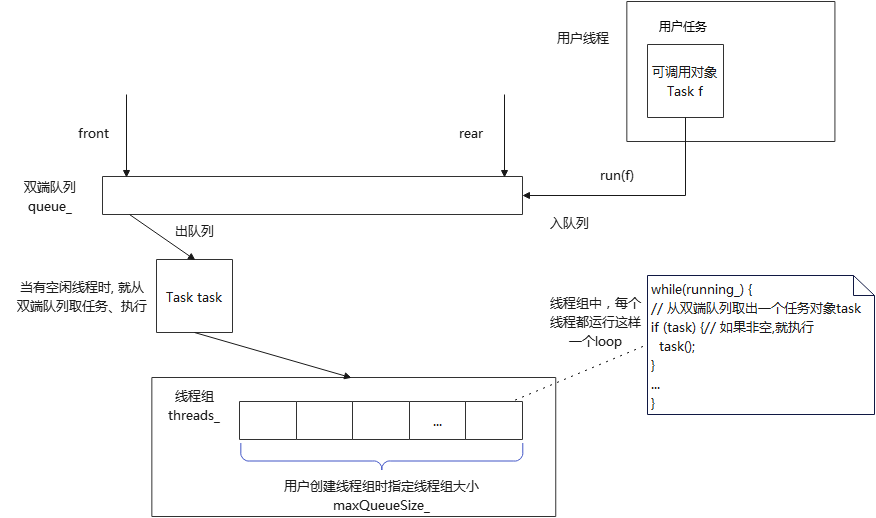
这个是通用线程池,双端队列存放的是多个可调用对象(即用户任务),而非函数指针,因此可以通过std::bind配接器传参。双端队列queue_,有时也称为工作队列。
工作原理:首先创建并启动一组线程,称为线程池threads_,由用户指定其大小maxQueueSize_,每个元素对对应一个线程。每个线程函数都是一样的,在其中会运行一个loop循环:从双端队列取出一个任务对象task,如果非空,就执行之,如此往复。
当有一个用户线程想要通过线程池运行一个用户任务时,就可以将用户任务函数及参数封装成一个可调用对象Task f,然后通过线程池接口,将f加入双端队列末尾。当线程池有线程空闲时(未执行用户任务),就会从双端队列头部取出一个Task对象task,然后执行之。
[======]
线程池的组成
线程池主要由以下几个部分组成:
1)工作队列queue_,用双端队列实现,能从尾部加入用户任务对应的可调用对象;
2)用户任务Task f,封装了用户任务,包含任务函数和参数;
3)线程组threads_,用于管理工作的线程数组;
4)工作线程,执行回调函数。
[======]
ThreadPool接口
ThreadPool提供以下public接口,供用户使用:
class ThreadPool : noncopyable
{
public:
typedef std::function<void ()> Task;
explicit ThreadPool(const string& nameArg = string("ThreadPool")); // 构造函数, 初始化各数据成员
~ThreadPool();
// Must be called before start().
void setMaxQueueSize(int maxSize); // 设置工作队列最大大小
void setThreadInitCallback(const Task& cb); // 设置线程初始化完成后回调函数
void start(int numThreads); // 指定创建线程个数, 启动线程池中的所有线程
void stop(); // 停止线程池各线程
const std::string& name() const; // 当前线程池名称
size_t queueSize() const; // 返回工作队列大小
void run(Task f); // 运行用户任务f
...
}
ThreadPool使用的线程Thread是Linux下NPTL线程库(Pthreads)的封装。ThreadPool将线程池的创建(构造)与启动(start())分隔开来,并没有直接在构造函数中启动线程组;将停止(stop())与析构分隔开。
[======]
ThreadPool实现
数据成员
private:
...
mutable MutexLock mutex_; // 用于线程安全保护数据成员的互斥锁
Condition notEmpty_ GUARDED_BY(mutex_); // 工作队列非空条件(元素个数为0)
Condition notFull_ GUARDED_BY(mutex_); // 工作队列非满条件(元素个数未达到上限值)
std::string name_;
Task threadInitCallback_; // 线程初始化完成后的回调对象
std::vector<std::unique_ptr<muduo::Thread>> threads_; // 线程组指针
std::deque<Task> queue_ GUARDED_BY(mutex_); // 工作队列
size_t maxQueueSize_; // 工作队列最大大小
bool running_; // 线程(循环)是否运行标志
主要成员:工作队列queue_,以及限制工作队列大小的maxQueueSize_,线程组指针threads_, 线程运行标志,以及用于保护它们的互斥锁mutex_,用于唤醒阻塞线程的条件变量notEmpty_, notFull_。
每个线程中都有一个loop,用running表示是否运行的标志,running只有在线程池停止的时候,才会被其他线程调用,可以用锁来保护,其他时候,只会被同一个线程访问,因此无需使用原子类型。
线程池的构造
ThreadPool::ThreadPool(const string &nameArg)
: mutex_(),
notEmpty_(mutex_),
notFull_(mutex_),
name_(nameArg),
maxQueueSize_(0),
running_(false)
{
}
用户可以指定线程池名称,默认为"ThreadPool",便于调试跟踪,日志诊断问题;值得注意的是工作队列最大大小maxQueueSize_初值0,用户可通过setMaxQueueSize修改其大小;
启动与停止
用户可通过start()启动线程池,需要指定线程组中子线程数量,一旦创建成功后,各子线程就会投入运行,直到调用stop() 停止线程池运行。
由于 Thread已内含一个门阀,会让调用线程等待新线程函数启动,因此,这里不必再设置门阀等待线程池中线程的启动。相反,如果有子线程运行所需要的数据,就需要在创建之前就准备好,比如running_,要在线程循环前就设置为true,否则子线程loop不会运行,而是直接退出。
void ThreadPool::start(int numThreads)
{
assert(threads_.empty());
running_ = true;
threads_.reserve(static_cast<size_t>(numThreads));
for (int i = 0; i < numThreads; ++i)
{
char id[32];
snprintf(id, sizeof(id), "%d", i + 1);
threads_.emplace_back(new muduo::Thread(
std::bind(&ThreadPool::runInThread, this), name_ + id));
threads_[i]->start();
}
if (numThreads == 0 && threadInitCallback_)
{
threadInitCallback_();
}
}
void ThreadPool::stop()
{
{
MutexLockGuard lock(mutex_);
running_ = false;
notEmpty_.notifyAll();
notFull_.notifyAll();
}
for (auto& thr : threads_)
{
thr->join();
}
}
为什么start()中不加锁,而stop()却要加锁?
因为start() 中,在子线程启动后,并没有对共享数据进行访问,也就不存在竞态条件。而stop()中,有对共享数据,如running_、notEmpty、notFull,因此,需要加锁对这些数据进行保护。
这里,子线程退出方式是连接(join)线程,而非分离(detach)线程。个人认为两种方案都可以,不过,join更容易在开发阶段,排查问题,因为如果线程无法正常退出,调用线程会阻塞在join调用上。
往工作队列加入任务对象
调用线程通过run(),向线程池的请求运行用户指定的任务对象,该对象会被加入到工作队列末尾,空闲子线程会自动从工作队列中取任务对象执行。
void ThreadPool::run(Task task)
{
if (threads_.empty()) // 子线程数量为0
{
task();
}
else
{ // 子线程数量非0
MutexLockGuard lock(mutex_);
while (isFull() && running_)
{
notFull_.wait();
}
if (!running_) return;
assert(!isFull());
queue_.push_back(std::move(task));
notEmpty_.notify();
}
}
这里有2个特殊情况需要注意:
1)threads_为空,即没有创建线程,可能是用户指定线程数为0或非法数量(如负数),也有可能是进程创建的线程数达到系统限制,从而创建线程失败。
不论什么原因,为避免进程崩溃,可以直接在当前线程中调用用户任务。
2)采用的是isFull()成员来判断工作队列是否满,而不是容器自带的size()来判断。
在isFull()内部,添加了一个互斥锁断言,确保isFull()的调用线程已经取得了mutex_锁;否则,一旦有其他线程在未取得锁的情况下,访问应受锁保护工作队列成员,可能导致意外情况。
bool ThreadPool::isFull() const
{
mutex_.assertLocked();
return maxQueueSize_ > 0 && queue_.size() >= maxQueueSize_;
}
从工作队列取任务对象
用take从工作队列头部取出一个任务对象。通常是子线程空闲时调用,取出后,用来执行用户任务。
ThreadPool::Task ThreadPool::take()
{
MutexLockGuard lock(mutex_);
// always use a while-loop, due to spurious wakeup
while (queue_.empty() && running_)
{
notEmpty_.wait();
}
Task task;
if (!queue_.empty())
{
task = queue_.front();
queue_.pop_front();
if (maxQueueSize_ > 0)
{
notFull_.notify();
}
}
return task;
}
子线程loop
主要工作:从工作队列取用户任务,然后执行之。循环往复,直到线程池停止工作。
实现该工作的runInThread()是在用户调用start()时,自动启动的,不需要用户自行调研。
void ThreadPool::runInThread()
{
try
{
if (threadInitCallback_)
{
threadInitCallback_();
}
while (running_)
{
Task task(take());
if (task)
{
task();
}
}
}
catch (const Exception& ex)
{
fprintf(stderr, "exception caught in ThreadPool %s\n", name_.c_str());
fprintf(stderr, "reason: %s\n", ex.what());
fprintf(stderr, "stack trace: %s\n", ex.stackTrace());
abort();
}
catch (const std::exception& ex)
{
fprintf(stderr, "exception caught in TheadPool %s\n", name_.c_str());
fprintf(stderr, "reason: %s\n", ex.what());
abort();
}
catch (...)
{
fprintf(stderr, "unknown exception caught in ThreadPool %s\n", name_.c_str());
throw ; // rethrow
}
}
这里,用了try-catch语句块将代码包裹起来,因为不知道用户代码会干些什么,很有可能会产生异常,因此需要捕获异常。对于不确定的异常,可以rethrow(继续上抛)。
另外,threadInitCallback_让用户有机会在线程初始化完成后,运行用户任务之前,做一些事情。
[======]
ThreadPool的使用、测试
基本流程:
// 创建线程池对象
ThreadPool pool("MyThreadPool");
// 设置工作队列最大尺寸
pool.setMaxQueueSize(maxSize);
// 启动线程池线程组, 指定线程数量
pool.start(threadNum);
// 运行用户指定任务
pool.run(userTask); // userTask是用户任务(可调用对象)
...
// 停止线程池(如有需要)
pool.stop();
截取自muduo的部分代码,对ThreadPool进行测试:
// from muduo project
// muduo/base/tests/ThreadPool_test.cc
void print()
{
printf("tid=%d\n", muduo::CurrentThread::tid());
}
void printString(const std::string& str)
{
LOG_INFO << str;
usleep(100*1000);
}
void test(int maxSize)
{
LOG_WARN << "Test ThreadPool with max queue size = " << maxSize;
muduo::ThreadPool pool("MainThreadPool");
pool.setMaxQueueSize(maxSize);
pool.start(5);
LOG_WARN << "Adding";
pool.run(print);
pool.run(print);
for (int i = 0; i < 100; ++i) {
char buf[32];
snprintf(buf, sizeof(buf), "task %d", i);
pool.run(std::bind(printString, std::string(buf))); // 演示了如何向线程池加入含参的可调用对象
}
LOG_WARN << "Done";
// 演示了如何等待线程池运行完用户任务
muduo::CountDownLatch latch(1);
pool.run(std::bind(&muduo::CountDownLatch::countDown, &latch));
latch.wait(); // wait for pool running latch.countDown()
pool.stop();
}
int main()
{
test(0);
test(1);
test(5);
test(10);
test(50);
return 0;
}
有2点问题:
1)run只接受一个参数,那么调用线程如何向线程池传参?
解决方案有很多,一种是使用模板函数,为向工作队列加用户任务的run函数添加不定参数的重载版本;另一种,是使用std::bind配机器,向run传递一个新的可调用对象。muduo采用的是后者。
2)调用线程端的用户,如何获取用户任务执行结果?
run()没有任何返回值,用户只能自行设计用户任务函数及参数,通过参数状态取得结果。
当然,还有另外的办法就是,让run()返回一个std::future<return_type>,通过future异步获取结果。
[======]
小结
1)线程池为避免频繁创建、销毁线程,提供一组子线程,能从工作队列取任务、执行任务,而用户可以向工作队列加入任务,从而完成用户任务。
[======]
参考
muduo库其它部分解析参见:muduo库笔记汇总

 浙公网安备 33010602011771号
浙公网安备 33010602011771号