
Effective STL~7 在程序中使用STL
第43条:算法调用优先于手写的循环
对于许多C++程序员来说,编写一个循环比调用一个算法更自然,而且读懂循环代码比读懂mem_fun_ref或mem_fun更容易。为什么要优先调用算法,而不是手写循环呢?
因为三个理由:
- 效率:算法通常比程序员自己写的循环效率更高。
- 正确性:自己写循环比使用算法更容易出错。
- 可维护性:使用算法的代码通常比手写循环更加简洁明了。
效率方面,有3个理由比显式循环更好:
1)很次要性能增益:使用算法可以减少冗余的计算
class Widget
{
public:
void redraw();
...
}
list<Widget> lw;
... // 往lw插入数据
// 手写循环, 每次都要检查i是否等于lw.end()
for (list<Widget>::iterator i = lw.begin(); i != lw.end(); ++i)
{
i->redraw();
}
上面的手写循环中,每次循环都要检查i是否等于lw.end(),也就是说list::end()每次都要被调用。但我们并不需要多次调用它,因为并没有改变链表。该函数只调用一次就够了。
// 使用for_each算法遍历list容器
for_each(lw.begin(), lw.end(), mem_fun_ref(&Widget::redraw));
STL实现者很清楚,begin、end及类似函数(如size)都是被频繁使用的函数,所以尽最大可能提高其效率。几乎肯定会使用inline来编译这些函数,并且努力改善这些函数的代码,让大多数编译器都能将循环中的计算提到外面来,以避免重复计算。当然,实践表明实现者并不是每次都能成功,不过因使用算法而避免重复计算所得到的性能优势,比手写循环来就很值得了。
2)主要性能增益:类库实现者可以根据他们对于容器实现的了解程度对遍历过程进行优化,这是库使用者难以做到的。
例如,deque中的对象(在内部)通常被分发在一个或多个固定大小的数组中。对于这些数组,基于指针的变量比基于迭代器的遍历要快得多。但只有库的实现者才能使用基于指针的遍历,因为只有他们才知道内部数组的大小,才知道如何从一个数组转移到另一个数组。而且有些STL包含的算法实现考虑到了deque内部数据结构,其实现比“普通”算法实现快了20%以上。
3)次要性能增益:除了一些不太重要的算法外,其他几乎所有STL算法都用了复杂的计算机科学算法,而有些非常复杂,并非一般C++程序员所能达到。
例如,你很难在算法级别上写出比STL的sort或类似算法更高效的代码,使用erase-remove习惯用法所得获得的性能也比一般程序员编写的循环要高效得多。
正确性方面
手写循环时,最要紧的是保证所使用的迭代器:a)都是有效的;b)指向你所希望的地方。
例如,假设有一个数组(可能是某个遗留下来的C API造成的),你要让每个数组元素+41,然后将它插入到一个deque的前部。如果你自己编写循环,很可能会这样实现:
// 错误代码:手写循环插入数据,这段代码会让插入deque的数据与原数组顺序相反
// C API:向数组写入数据
// 输入参数pArray是指向一个double数组,arraySize是数组大小
// 返回值是实际写入数组元素的格式
size_t fillArray(double *pArray, size_t arraySize);
const int maxNumDoubles = 1000; // 初始化maxNumDoubles值
double data[maxNumDoubles]; // 创建足够大的局部数组
deque<double> d; // 创建deque并加入数据
...
size_t numDoubles = fillArray(data, maxNumDoubles);
// 从API取得数组把data中每个数据+41,然后插入d的前面
for (size_t i = 0; i < numDoubles; i++)
{
d.insert(d.begin(), data[i] + 41);
}
这段代码会造成新插入的数据与data中相应数据排列顺序相反,因为每次插入位置都是d.begin(),最后插入的元素跑到deque的最前面了。
或许,你会用以下方法对它进行修改:
// 仍然有问题的代码
deque<double>::iterator insertLocation = d.begin();
for (size_t i = 0; i < numDoubles; i++)
{
d.insert(insertLocation++, data[i] + 41);
}
每次insert数据时,都会使deque中所有迭代器无效,其中也包括insertLocation。
参考:https://en.cppreference.com/w/cpp/container/deque/insert
虽然insert导致原来的迭代器失效,不过我们可以利用其返回的迭代器,因为deque::insert返回的迭代器是指向插入数据的,因此我们可以得到下面的代码:
// OK
deque<double>::iterator insertLocation = d.begin();
for (size_t i = 0; i < numDoubles; i++)
{
insertLocation = d.insert(insertLocation, data[i] + 41);
++insertLocation;
}
但如果使用STL算法,一行代码就搞定了:
// 将data中的元素拷贝到d的前部,每个元素 + 41
transform(data, data + numDoubles,
inserter(d, d.begin()),
bind2nd(plus<double>(), 41)); // C++11以后可以直接使用std::bind绑定器
可维护性
从长远看,最好的软件是代码最简洁、可读性最好、最容易扩展功能、最容易维护和适用于新环境的软件。而算法显然比手写循环更具竞争力。
算法的名称表明了其功能,而for、while、do循环却不能。例如,当程序员看到transform调用时,应该会意识到某个函数将被应用到一个区间中的每个对象上。而看到for、while或do的时候,所知道的只不过是一个循环将出现。而要知道这个循环,必须检查具体的代码。
示例:假设你要确定一个向量中第一个大于x、小于y的元素。
如果使用循环:
vector<int> v;
int x, y;
...
vector<int>::iterator i = v.begin();
for (; i != v.end(); ++i) {
if (*i > x && *i < y) break;
}
... // 现在i指向找到的值或者为v.end()
如果把测试容器元素值的逻辑放到一个单独的函数子类中,则find_if调用就会简单得多。
template<typename T>
class BetweenValues : public unary_function<T, bool>
{
public:
BetweenValues(const T& lowValue, const T& highValue)
: lowVal(lowValue), highVal(highValue) { }
bool operator()(const T& val) const
{
return val > lowVal && val < highVal;
}
private:
T lowVal;
T highVal;
};
...
vector<int>::iterator it = find_if(v.begin(), v.end(), BetweenValues<int>(x, y));
... // 现在it指向找到的值或者为v.end()
当然,使用算法这种方式也有其局限性,比如试图将模板类放到函数内部,会发现无法编译,因为模板不能被声明在函数内部。如果把BetweenValues变成一个类而不是模板来避免这个问题,会发现这是一个局部类(local class),而局部类不能作为模板的类型实参(find_if所需要的函数子类型)。
综上,如果你手写循环要做的事情与算法接近,那么使用算法;如果循环中要做很多工作,而非复杂,那最好使用算法调用。
[======]
第44条:容器的成员函数优先于同名的算法
STL容器提供一些与算法同名的成员函数,如关联容器提供count、find、low_bound、upper_bound、equal_range,list提供remove、remove_if、unique、sort、merge、reverse。
大多数情况下,应该优先使用这些成员函数,而不是STL算法。原因:
1)成员函数速度快;
2)成员函数通常与容器结合得更紧密;
例如,在关联容器set
set<int> s;
...
// 使用find成员函数
set<int>::iterator i = s.find(727);
if (i != s.end())
{
...
}
// 使用find算法
set<int>::iterator i2 = find(s.begin(), s.end(), 727);
if (i2 != s.end())
{
...
}
使用find成员函数具有O(logn)时间复杂度,而find算法具有O(n)时间复杂度。出于效率考虑,显然应该使用find成员函数。
对于标准关联容器,选择成员函数而不是对应同名算法,有几方面好处:
1)可以获得对数时间性能,而不是线性;
2)可以使用等价性来确定2个值是否“相同”,等价性是关联容器的一个本质定义;
3)在使用map和multimap时,将很自然地只考虑元素的键部分,而不是完整的(key/value)对;
[======]
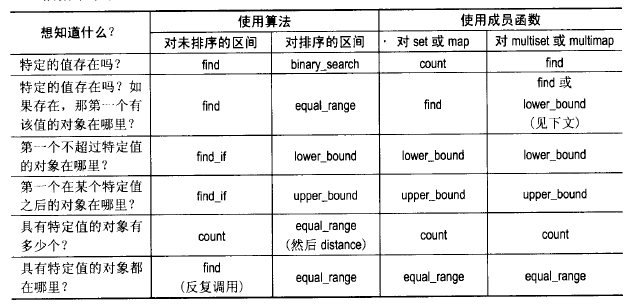
第45条:正确区分count、find、binary_search、lower_bound、upper_bound和equal_range
我们在容器或区间中查找信息时,选择成员函数或算法的目标是快速和简单,希望越快、越简单越好。
现在,假设我们有一对指定搜索区间的迭代器,如果选择查找策略?
如果区间是排序的,那么通过binary_search、lower_bound、upper_bound和equal_range查找速度更快(对数时间);
如果迭代器没有指定排序区间,那么选择只能是count、count_if、find及find_if,查找速度是线性时间。
假设你仅仅想知道list容器中是否存在某个特定Widget对象值w。如果使用count,代码如下:
list<Widget> lw;
Widget w;
...
if (count(lw.begin(), lw.end(), w))
{ // w在lw中
...
}
else
{ // w不在lw中
...
}
如果使用find,代码如下:
if (find(lw.begin(), lw.end(), w) != lw.end())
{ // w在lw中
...
}
else
{ // w在lw中
...
}
从功能性(找到list容器中是否存在指定元素值)角度来讲,两者一样,count习惯用法编码甚至更容易一些。但在效率上,count效率更差,因为find找到第一个匹配结果后立马返回,而count必须达到区间末尾,以找到所有的匹配。
另外,如果还想要指定区间中第一个匹配的值,用find更合适,因为find返回找到的那个元素的迭代器,count仅仅统计值出现次数。
对于已排序区间,选择对数时间运行的查找算法(binary_search、lower_bound、upper_bound和equal_range),比线性时间运行的count和find性能更好。
用binary_search在vector容器中查找元素:
vector<Widget> vw;
...
sort(vw.begin(), vw.end(), less<Widget>());
Widget w;
...
if (binary_search(vw.begin(), vw.end(), w))
{ // w在vw中
...
}
else
{ // w不在vw中
...
}
binary_search只能返回true or false,而lower_bound可以找到第一个不小于指定值的元素:
vector<Widget> vw;
...
// 先sort排序,后二分查找
sort(vw.begin(), vw.end(), less<Widget>());
Widget w;
...
if (binary_search(vw.begin(), vw.end(), w))
{ // w在vw中
...
}
else
{ // w不在vw中
...
}
如果我们想知道第一个找到的值在哪儿,可以先用lower_bound找到元素对应迭代器,然后测试之。可能会这样做:
vector<Widget> vw;
...
sort(vw.begin(), vw.end(), less<Widget>());
Widget w;
...
// 找到第一个这样的迭代器i, 满足*i 不小于 w
vector<Widget>::iterator i = lower_bound(vw.begin(), vw.end(), w);
if (i != vw.end() && *i == w) // 需要为Widget重载operator==
{ // 成功找到
...
}
else
{ // 没有找到
...
}
上面代码大多数情况下,能正常工作,但不完全正确。因为lower_bound是用等价性搜索,而上面的“*i == w”是相等性测试,如果两者没有保持一致,那就是错误的。
因此,正确的做法是,检查lower_bound返回的的迭代器所指对象是否等价于要查找的值。
条款19告诉我们,对于2个对象,等价性应该用下面的表达式测试
!(w1 < w2) && !(w2 < w1) // w1 < w2和w2 < w1都不为真
因此,
if (i != vw.end() && *i == w) // 应该修改成:
if (i != vw.end() && (!(*i < w) && !(w < *i)) // 需要为Widget重载operator<
注意:如果修改了lower_bound的比较函数,那么用于等价性检查的代码应该同步修改,以保持一致。
还有一个更容易的办法:用equal_range。equal_range返回一对迭代器,第一个等于lower_bound返回的迭代器,第二个等于upper_bound返回的迭代器。
vector<Widget> vw;
...
sort(vw.begin(), vw.end(), less<Widget>());
typedef vector<Widget>::iterator VWIter;
typedef pair<VWIter, VWIter> VWIterPair;
Widget w;
...
VWIterPair p = equal_range(vw.begin(), vw.end(), w);
if (p.first != p.second) // p.first指向第一个与w等价的对象, p.second指向最后一个与w等价的对象的下一个位置
{ // 成功找到
...
}
else
{ // 没有找到
...
}
注意:equal_range返回的迭代器之间的距离与这个区间中对象数目是相对的,也就是原始区间中与被查找的值等价的对象数目。也就是说,equal_range不仅完成了find的工作,也完成了count的工作。
例如,在vw找与w等价的Widget对象的位置,并找出有多少个这样的对象,可以这样:
VWIterPair p = equal_range(vw.begin(), vw.end(), w);
cout << "There are " << distance(p.first, p.second)
<< " elements in vm equivalent to w.";
不过,如果在关联容器中统计个数,使用count更安全。特别是,它比先调用equal_range,再在结果迭代器上调用distance的做法要好很多。因为,1)它的用法显得非常清晰,count含义就是“计数”;2)使用count更简单,没有必要先创建一对迭代器,然后再讲first、second两个迭代器传给distance;3)count速度可能更快。
结论:
[======]
第46条:考虑使用函数对象而不是函数作为STL算法的参数
原因在于
1)将函数对象传递给STL算法往往比传递实际的函数更高效。
例如,假如需要将一个vector
vector<double> v;
...
sort(v.begin(), v.end(), greater<double>());
如果担心函数对象的抽象性代价,可能会避开用函数对象,而用一个函数替代:
inline bool doubleGreater(double d1, double d2)
{
return d1 > d2;
}
...
sort(v.begin(), v.end(), doubleGreater);
但实际上,直接传递函数的方案比传递函数对象更慢。因为虽然函数声明为inline,但C/C++并不能真正将一个函数作为参数传递给另一个函数,也就是说,编译器会将它隐式转换为函数指针,并传递该指针。
因此,下面2条语句等价:
sort(v.begin(), v.end(), doubleGreater);
// 等价于
sort(v.begin(), v.end(), &doubleGreater);
sort模板实例化的时候,编译器生成函数声明如下:
void sort(vector<double>::iterator first, vector<double>::iterator last, // 待排序区间
bool(*comp)(double, double)); // 指向比较函数的指针
2)让程序正确通过编译。
由于种种原因,STL平台可能会拒绝一些完全合法的代码。
set<string> s;
...
// 部分编译器可能会报错
transform(s.begin(), s.end(), ostream_iterator<string::size_type>(cout, "\n"),
mem_fun_ref(&string::size));
该问题原因在于:特定STL平台在处理const成员函数(如string::size)的时候,有一个错误。
一种解决办法是用函数对象来替换,几乎所有STL平台都能通过编译:
struct StringSize
{
string::size_type operator()(const string& s) const
{
return s.size();
}
};
...
transform(s.begin(), s.end(), ostream_iterator<string::size_type>(cout, "\n"),
StringSize);
3)有助于避免一些微妙的、语言本身的缺陷。
例如, 当一个函数模板的实例化名称并不完全等于一个函数的名称时,可能会出现这样的问题:
template<typename FPType>
FPType average(FPType val1, FPType val2)
{
return (val1 + val2) / 2;
}
template<typename InputIter1, typename IntputIter2>
void writeAverage(InputIter1 begin1, InputIter1 end1, IntputIter2 begin2, ostream& s)
{
transform(begin1, end1, begin2,
ostream_iterator<typename iterator_traits<InputIter1>::value_type>(s, "\n"), // 注意:原书尖括号位置不对,value_type(s, "\n")> 是错误的写法
average<typename iterator_traits<InputIter1>::value_type>); // C++标准认为此处可能造成二义性
}
vector<int> v1, v2;
writeAverage(v1.begin(), v1.end(), v2.begin(), cout);
许多编译器可能会通过上面的代码,但C++标准并不认同。因为理论上可能存在一个名为average的函数模板,而且只带一个类型参数。如果这样,average<typename iterator_traits
如果改用函数对象来替代函数就没有这个问题:
template<typename FPType>
struct Average
{
public:
FPType operator()(FPType val1, FPType val2) const
{
return average(val1, val2);
}
};
template<typename InputIter1, typename IntputIter2>
void writeAverage(InputIter1 begin1, InputIter1 end1, IntputIter2 begin2, ostream& s)
{
transform(begin1, end1, begin2,
ostream_iterator<typename iterator_traits<InputIter1>::value_type>(s, "\n"),
Average<typename iterator_traits<InputIter1>::value_type>() // OK
);
}
...
[======]
第47条:避免产生“直写型”(write-only)的代码
何谓“直写型”(write-only)代码?
注意这里不是只写型。
先看一个例子,假设有一个vector
vector<int> v;
int x, y;
...
v.erase(
remove_if(find_if(v.rbegin(), v.rend(), bind2nd(greater_equal<int>(), y)).base(),
v.end(),
bind2nd(less<int>(), x)),
v.end());
v.erase这段代码的“套路”(伪代码))是:
v.erase(remove_if(find_if(v.rbegin(), r.end(), something).base(), v.end(), something)),
v.end());
要做的事情,就是写出something。写出这种语句很简单,因而通常被称为“直写型”代码。但读懂很困难。
于是,我们可以分段改写并添加必要注释:
typedef vector<int>::iterator VecIntIter;
// 从末尾向开头找第一个 >= y的元素, 返回普通iterator(非逆向迭代器)rangeBegin
VecIntIter rangeBegin = find_if(v.rbegin(), v.rend(), bind2nd(greater_equal<int>(), y)).base();
// 删除区间[rangeBegin, end) < x的元素
v.erase(remove_if(rangeBegin, v.end(), bind2nd(less<int>(), x)), v.end());
分段以后,就很容易理解。因此,请避免产生“直写型”的代码。
[======]
第48条:总是包含(#include)正确的头文件
下面总结了每个与STL有关的标准头文件所包含的内容:
- 几乎所有的标准STL容器都被声明在与之同名的头文件中,比如vector被声明在
中,list被声明在 - 中。但
和 - 除了4个STL算法外,其他所有算法都被声明在
中,这4个算法是accumulate(条款37)、inner_product、adjacent_difference和partial_sum,声明在 。 - 特殊类型迭代器,包括istream_iterator和istreambuf_iterator(条款29),声明在
。 - 标准函数子(如less
)和函数子配接器(如not1、bind2nd)声明在 。
任何时候,如果使用了某个头文件中的一个STL组件,那么一定要提供对应#include指令,即使当前STL平台允许省略。
[======]
第49条:学会分析与STL相关的编译器诊断信息
对于编译器报出的STL相关诊断信息,有以下处理技巧,可供参考:
1)用perl、python、ruby等脚本语言,将原始类型basic_string替换为熟悉的文本"string",以简化诊断结果信息。
2)尝试将用STL容器类型重定义的自定义类型,在诊断信息中也替换掉,对于不熟悉的部分,可以先用一个简要代号替换,不到万不得已,不应去翻看与特定实现相关的源代码。
3)vector和string的迭代器通常就是指针,所以当错误地使用了iterator的时候,编译器的诊断信息中可能会引用到指针类型。例如,如果源代码中引用了vector
4)如果诊断信息中提到back_inserter_iterator、front_insert_iterator或insert_iterator,则几乎总是意味着你错误地调用了back_inserter、front_inserter或inserter(back_inserter返回一个back_insert_iterator对象,front_inserter返回一个front_insert_iterator对象,insert返回一个insert_iterator对象,用法见条款30)。
5)类似地,如果诊断信息中提到了binder1st或bind2nd,那么你可能错误地使用了bind1st和bind2nd。
6)输出迭代器(如ostream_iterator、ostreambuf_iterator(条款29),以及那些由back_inserter、front_inserter和inserter函数返回的迭代器)在赋值操作符内部完成其输出或插入工作,所以,如果在使用这些迭代器的时候犯了错误,那么你所看到的错误消息中可能会提到赋值操作符有关的内容。
比如,可以编译以下代码,试图将string*指针的容器按string对象输出
vector<string*> v; // string*指针的容器
copy(v.begin(), v.end(), ostream_isterator<string>(cout, "\n")); // 按string对象输出
7)如果你得到的错误消息来源于某个STL算法的内部实现(如,引起错误的源代码在
list<int>::iteartor i1, i2; // 将一个双向迭代器传递给sort
sort(i1, i2); // sort算法需要随机访问迭代器
8)如果你正在使用一个很常见的STL组件,如vector、string或for_each算法,但从错误消息来看,编译器好像对此一无所知,那么可能是你没有包含相应的头文件。
[======]
第50条:熟悉与STL相关的Web站点
- SGI STL站点:http://www.rrsd.com/software_development/stl/stl/index.html
- STLport站点:http://stlport.com/
- Boost站点:https://boost.org/
SGI STL站点特点
为STL中所有组件都提供了详尽的文档,一个免费下载的STL实现,是另一个被广泛使用的STL本部STLport的基础。SGI STL实现提供了许多功能强大的非标准组件:
- 哈希关联容器 hash_set、hash_multiset、hash_map和hash_multimap。
- 单向链表容器 slist (C++11已加入forward_list表示单向链表)。
- 针对大文本与string类似的容器 rope(绳子)。底层采用树形结构,每个树节点是带有引用计数的子串,子串以char数组形式保存。
- 各种非标准的函数对象和配接器 如identity、project1st、project2nd、compose1、compose2等,select1st和select2nd,用于返回pair的第一、二部分。
STLport站点特点
提供一个可以在超过20种编译器上使用的SGI STL(拷贝iostream等)改进版本,免费下载。提供一种“调试模式”,可以检查到不正确使用STL的情形(特别通过编译但会导致未定义运行时行为的STL用法)。
Boost Web站点特点
为下一轮的C++标准化过程提供一个增补的基础,提供免费的、公开审视的C++库。换言之,可以认为是C++标准的先行测试版本。另外,提供一些与STL相关的函数对象,以及相关的设施。
[======]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号