
Effective STL~5 算法
插入迭代器
当通过insert、push_front、push_back等方式加入新对象到STL容器时,容器会自动扩充存储空间以存储这些对象。但STL容器并不总是能正确管理其存储空间。
例如,
int transmogrify(int x); // 根据x生成一个新值
vector<int> values;
vector<int> results;
// 向values插入一些数据
for (size_t i = 0; i < 5; i++)
{
values.push_back(i);
}
// 这段代码有个错误。将transmogrify作用在values的每个对象上,并把返回值追加在results的末尾
transform(values.begin(), values.end(), results.end(), transmogrify);
上面代码中,transform任务是对values每个元素调用transmogrify,并将结果写到results.end()开始的目标区间中。而将值写到results.end()会导致灾难性后果,因为results.end()中并没有对象,*(results.end() + 1)中更没有对象。
解决办法:使用尾后插入迭代器back_inserter。
...
vector<int> results;
// 将transmogrify作用在values的每个对象上,并将返回值插入到results末尾
transform(values.begin(), values.end(), back_inserter(results), transmogrify);
back_inserter返回的迭代器将使得push_back被调用,因此back_inserter可适用于所有提供了push_back方法的容器(如所有标准顺序容器:vector、string、deque和list)。
如果要在头部插入对象,可以使用头部插入迭代器front_inserter。注意:vector不支持push_front操作,因而不能使用front_inserter,将对象插入vector容器。
...
list<int> results; // results现在是list,values可以是vector或者list
// 将transmogrify作用在values的每个对象上,并将返回值插入到results开头
transform(values.begin(), values.end(), front_inserter(results), transmogrify);
上面代码会导致values中对象在results逆序存储。如果既然用front_inserter在results头部插入,又要保留对象原来的顺序,可以反序遍历values即可:
...
list<int> results;
// 将transform结果插入到results头部,并保存对象的相对顺序
transform(values.rbegin(), values.rend(), front_inserter(results), transmogrify);
back_inserter导致算法将结果插入到容器尾部,front_inserter导致将结果插入到容器头部,而inserter将导致算法把结果插入到容器中特定位置:
...
list<int> results;
// 将transform结果插入到results中间位置
transform(values.begin(), values.end(), inserter(results, std::next(results.begin(), results.size() / 2)), transmogrify);
注意:这里results.begin()并不能直接加上results.size() / 2,因为没有为iterator定义 operator+运算,因此原书这里的代码是错误的。通过使用std::next将迭代器移动指定距离,可以解决这个问题。
如果插入操作的目标容器是vector或string,该怎么办?
1)可以遵从条款14建议,预先调用reserve,避免频繁扩容,提高插入性能。但仍然要承受移动元素带来的开销。
vector<int> values;
vector<int> results;
...
resutls.reserve(results.size() + values.size()); // 在results中为results预留存储空间
// 这次results插入数据不需要重新分配内存空间
transform(values.begin(), values.end(), inserter(results, std::next(results.begin(), results.size() / 2)), transmogrify);
2)为解决每次插入元素都带来的移动元素的开销问题,可以改用back_inserter
vector<int> values;
vector<int> results;
...
resutls.reserve(results.size() + values.size()); // 在results中为results预留存储空间
// 向results末尾插入数据
transform(values.begin(), values.end(), back_inserter(results), transmogrify);
[======]
第31条:了解各种与排序有关的选择
对一组数据,如何进行排序?
sort是一个不错排序算法,但并非任何场合下都是完美无缺的。
有时,我们不需要一个完全的排序操作。比如,你有一个vector
// 提供给paritial_sort的比较函数,用于比较2个Widget对象大小
bool qualityCompare(const Widget& lhs, const Widget& rhs)
{
return lhs.less(rhs);
}
// Widget class声明
class Widget
{
public:
explicit Widget(int key) : key(key) { }
bool less(const Widget& other) const
{
return key < other.key;
}
int getKey() const
{
return key;
}
private:
int key; // 用key代表质量,key值越小质量越好
...
};
// 客户端
vector<Widget> widgets;
...
// 将质量最好(key最小)的20个元素按顺序放在widgets的前20个位置上
partial_sort(widgets.begin(), widgets.begin() + 20, widgets.end(), qualityCompare);
... // 使用部分排序后的widgets
测试用例生成:
...
default_random_engine e;
uniform_int_distribution<int> u(0, 2000); // 0~2000的均匀分布
for (size_t i = 0; i < 100; i++)
{
widgets.push_back(Widget(u(e)));
}
如果你只想要找到最好的20个Widget,并不关心它们的排列顺序,可以使用nth_element算法。nth_element用于排序一个区间,使得位置n上的元素正好是全排序情况下的第n个元素(n由调用者指定)。当函数返回时,所有按全排序规则(即sort结果)排在位置n之前的元素,也都排在位置n之前;而所有按全排序规则排在位置n之后的元素,则都排在位置n之后。
与使用partial_sort区别在于用nth_element函数替换,调用基本相同:
...
nth_element(widgets.begin(), widgets.begin() + 19, widgets.end(), qualityCompare);
...
partial_sort和nth_element的差别在于:partial_sort对位置1~20的元素进行了排序,而nth_element没有对它们进行排序。相同点是2个算法都将质量最后的20个Widget放到了向量的前端。
对于等价的元素,这些算法会如何处理?
等价的概念可以查看条款19。
在排列时,对于等价元素,partial_sort和nth_element算法有自己的做法,你无法控制它们的行为。
对于完全排序而言,你可以有更多的控制权,因为有些排序算法是稳定的。partial_sort、nth_element、sort都是不稳定的排序算法,而stable_sort是稳定排序算法;STL中没有与partial_sort和nth_element功能相同的稳定排序算法。
找中间元素
除了可以用来找排名前n个元素外,nth_element还可以用来找一个区间的中间值,或者找到某个特定百分比上的值:
vector<Widget> widgets;
...
// 定义2个便捷变量,分别代表widges的begin和end迭代器
vector<Widget>::iterator begin(widgets.begin());
vector<Widget>::iterator end(widgets.end());
vector<Widget>::iterator goalPosition; // 用于定位感兴趣的元素
// case1:找到具有中间质量级别(50%)的Widget
goalPosition = begin + widgets.size() / 2;
// 找到指向中间质量基本的Widget,并放到goalPosition迭代器位置
nth_element(begin, goalPosition, end, qualityCompare);
... // 现在goalPosition所指元素具有中间质量
// case2:找到具有75%质量的Widget
vector<Widget>::size_type goalOffset = 0.25 * widgets.size();
nth_element(begin, begin + goalOffset, end, qualityCompare);
... // 现在goalPosition所指元素具有75%质量级别
找枢轴位置,并将元素按大小关系移动到枢轴两侧
有时,我们并不想进行完全排序,只是想找到比某个Widget质量更好的所有对象,比nth_element更好的策略是使用partition算法。partition算法把所有满足某个特定条件的元素放在区间的前部,不满足的放在区间后半部,并返回分割点的迭代器。 ---- 这很像快速排序中,每次排序找枢轴。
bool hasAcceptableQuality(const Widget& w)
{
// 判断w的质量是否为2或者更好
}
// 客户端,将判别函数传给partition算法
...
// 将满足hasAcceptableQuality的所有元素移动到前部,然后返回一个迭代器,指向第一个不满足判别条件的Widget vector<Widget>::iterator goodEnd =
partition(
widgets.begin(),
widgets.end(),
hasAcceptableQuality);
priority_queue 优先队列
要保持元素的顺序关系,也可以考虑使用非STL容器优先队列priority_queue(C++11中已经是STL容器)。
priority_queue使用大顶堆或小顶堆存储(取决于所用的比较类型),如果是大顶堆,总是能保证下一个出队列的是堆顶(最大的元素);如果是小顶堆,下一个出队列的总是最小的元素。
// 降序队列, 默认是大顶堆
priority_queue<Widget> q;
// 降序队列
priority_queue<Widget, less<Widget>> q1;
// 升序队列
priority_queue<Widget, greater<Widget>> q2;
排序算法使用要求
sort、stable_sort、partial_sort和nth_element算法都要求随机访问迭代器,因此这些算法只能用于于vector、string、deque和数组。
对标准关联容器元素进行排序没有实际意义,因为容器总是使用比较函数来维护内部的有序性。
list是唯一需要排序却无法使用这些排序算法的容器,不过,list特别提供了sort成员函数,而且是稳定排序。
资源消耗(小->大):
1)partition;
2)stable_partition;
3)nth_element;
4)partial_sort;
5)sort;
6)stable_sort;
[======]
第32条:如果确实需要删除元素,则需要在remove这一类算法之后调用erase
remove
remove算法很容易让人误解。remove需要一对迭代器来指定要操作的元素区间,不接受容器作为参数,因此无法推断出是什么容器。
// remove算法声明
template<class ForwardIterator, class T>
ForwardIterator remove(ForwardIterator first, ForwardIterator last, const T& value);
remove并不能从容器中真正删除元素,而是将需要的元素往前移动到删除位置处。一个显而易见的现象是:remove删除容器元素后,容器大小并未改变。
vector<int> v;
v.reserv(10);
for (int i = 1; i <= 10; ++i) {
v.push_back(i);
}
cout << v.size(); // 打印10
v[3] = v[5] = v[9] = 99; // 使得3个元素值为99
remove(v.begin(), v.end(), 99); // 删除所有值为99的元素
cout << v.size(); // 打印10
remove并不真正删除元素,因为它做不到。这是因为remove并不知道所操作的元素在哪个容器,自然就不看调用它的成员函数来完成真正的删除功能。
remove的真正工作是元素移动:将不需要删除的元素往前移动到需要删除的元素的位置。
详细可以参见:https://www.cnblogs.com/fortunely/p/15694743.html
erase-remove
如果想要真正删除元素,改变容器大小(fit to size),可以使用erase成员函数。
例如,想要删除vector中值为99的所有元素,并改变容器大小:
vector<int> v;
...
v.erase(remove(v.begin(), v.end(), 99), v.end()); // 真正删除所有值为99 的元素
cout << v.size(); // 现在打印7
remove返回的是第一个“不被需要”的元素对应的迭代器。
list::remove
list::remove是STL中唯一一个名为remove真正删除了容器元素的函数:
list<int> li;
...
list.remove(99); // 真正删除所有值为99的元素,因此li大小会改变
严格来说,这是list容器的成员函数,而非remove算法。list::remove应该被称为erase,然而并没有被命名为erase,因此只好习惯这种不一致。
在关联容器中,类似的成员函数被称为erase。
其他删除函数
remove和remove_if非常类似,区别在于remove_if需要提供判别式,为true则删除元素;而remove是通过operator==来判断与给定元素是否相等,如果相等则删除。
unique和remove行为相似,在没需要任何容器信息的情况下,从容器中删除一些相邻的、重复的值。也就是说,必须在unique之后再调用erase,才能真正删除元素。
类似于list::remove,list::unique也会真正删除元素,而且比erase-unique更高效。
[======]
第33条:对包含指针的容器使用remove这一类算法时要特别小心
当容器中要删除的元素是指针时
假设你有一些动态分配的Widget,每个Widget可能已被验证过(这里用key值 > 5 来模拟),然后把已验证过的结果指针存放到一个向量中。
// 存在资源泄漏问题
class Widget
{
public:
explicit Widget(int key) : key(key) { }
bool isCertified() const // 判断该Widget对象是否已被验证过
{
if (key > 5) return true;
return false;
}
int getKey() const
{
return key;
}
private:
int key;
};
// 客户端
vector<Widget*> v;
for (size_t i = 0; i < 10; i++)
v.push_back(new Widget(i));
...
// 删除未被验证过的Widget对象的指针
// mem_fun见条款41, not1是构造一个与谓词结果相反的一元函数对象
v.erase(remove_if(v.begin(), v.end(), not1(mem_fun(&Widget::isCertified))),
v.end());
for (auto &e : v)
cout << e->getKey() << " ";
cout << endl;
示例对v做了一些工作后,打算剔除那些没有被验证过的Widget对象。根据条款43建议,尽量使用算法而不是编写显示循环,因此用erase-remove习惯用法。
然而,不仅erase调用会导致删除元素的指针所指对象无法正常释放,而且这之前调用的remove_if也会导致内存泄漏。
remove_if调用之前,v的内存布局示意:
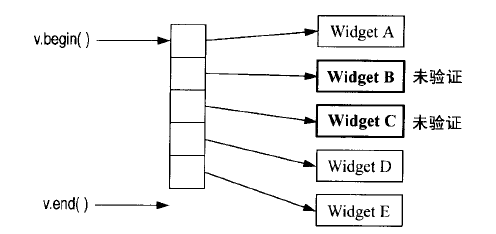
remove_if调用以后,v的内存布局示意:

这样,没有指针指向尚未验证的Widget B和C对象,而Widget D和E却同时有2个指针指向,从而产生资源泄漏问题。
因此,应当避免对这种容器使用remove。如果不得已使用,可以在进行erase-remove习惯用法之前,先把那些指向未被验证过的Widget的指针删除并置空,然后清除该容器中所有的空指针。
// OK:解决资源泄漏问题的代码,删除所有的空置指针
// 如果*pWidget是一个未被验证的Widget,则删除该指针,并置空
void delAndNullifyUncertified(Widget*& pWidget)
{
// 如果未验证,就删除指针并置空
if (!pWidget->isCertified())
{
delete pWidget; // 删除指针(释放指针所指对象资源)
pWidget = nullptr; // 指针置空
}
}
// 将所有指向未被验证的Widget对象的指针删除,并置空
for_each(v.begin(), v.end(), delAndNullifyUncertified);
// 删除v中的空指针
v.erase(remove(v.begin(), v.end(), static_cast<Widget*>(nullptr)), v.end());
如果使用智能指针,则不需要手动删除指针,直接用erase-remove习惯用法即可:
// OK
vector<shared_ptr<Widget>> v;
...
// 删除所有未被验证的Widget对象
v.erase(remove_if(v.begin(), v.end(), [](const shared_ptr<Widget>& ptr) {
return !ptr->isCertified();
}),
v.end());
[======]
第34条:了解哪些算法要求使用排序的区间作为参数
使用排序区间的算法
要求排序区间的STL算法:
binary_search, lower_bound, upper_bound, equal_range, set_union, set_intersection, set_difference, set_symmetric_difference, merge, inplace_merge, includes
不一定要求排序区间,但通常与排序区间一起使用:
unique, unique_copy
- binary_search, lower_bound, upper_bound, equal_range
用于使用二分法查找数据,要保证对数时间的查找效率,前提是数据已排好顺序。当然,只有接受随机访问迭代器的时候,才能保证对数查找效率,如果提供迭代器不具备随机方的能力(如list的双向迭代器),那么执行过程仍需要线性时间。
- set_union, set_intersection, set_difference, set_symmetric_difference
提供线性时间效率的集合操作。如果不是已排序的数据,就无法在线性时间内完成工作。
- merge和inplace_merge
实现了合并和排序的联合操作,读入2个排序的区间,然后合并成一个新的排序区间,其中包含了原来2个区间中的所有函数。类似于归并排序的合并操作,具有线性时间性能。
- include
可用来判断一个区间中所有对象是否都在另一个区间中。因为includes总是假设这2个区间是排序的,所以承诺线性时间效率。没有这一前提,通常会运行得更慢。
- unique和unique_copy
删除每一组连续相等的元素,仅保留第一个。即使对于未排序区间,也有很好的行为。unique通常用于删除一个区间中的所有重复值,所以总是要确保给传unique的区间是排序的。
一个区间被排序的含义
如果为一个算法提供了一个排序的区间,而这个算法也带一个比较函数作为参数,那么一定要保证你传递的比较函数和这个区间所用的比较函数有一致的行为。通常STL算法默认使用less比较类型,因此,如果排序区间使用greater作为比较类型,就要显式指出。
// 错误代码:二分查找算法binary_search默认使用less比较类型(升序),而排序区间使用greater比较类型得到降序区间
vector<int> vec;
...
sort(vec.begin(), vec.end(), greater<int>());
...
bool a5Exists = binary_search(vec.begin(), vec.end(), 5); // binary_search假设区间是升序排列的
必须将区间使用的比较函数作为参数,传递给算法
bool a5Exists = binary_search(vec.begin(), vec.end(), 5, greater<int>()); // binary_search使用greater作为比较函数
[======]
第35条:通过mismatch或lexicographical_compare实现简单的忽略大小写的字符串比较
如何用STL实现忽略大小写的字符串比较?
简单还是困难,取决于所要求的通用性如何。
本条款以实现像strcmp这样的功能为例,不考虑国际化问题。
方法一:使用mismatch算法,进行忽略大小写的字符串比较
1)首先需要一个忽略大小写的字符比较函数
#include <algorithm>
// 忽略大小写地比较字符c1和c2
// 如果c1 < c2, 返回-1;
// 如果c1 > c2, 返回1;
// 如果c1 == c2, 返回0
int ciCharCompare(char c1, char c2)
{
int lc1 = tolower(static_cast<unsigned char>(c1));
int lc2 = tolower(static_cast<unsigned char>(c2));
if (lc1 < lc2) return -1;
else if (lc1 > lc2) return 1;
return 0;
}
2)ciStringCompare 只是简单地确保传入的实参有正确的顺序; ciStringCompareImpl 根据2个字符串之间关系返回一个负数、0或整数。
// 确保传入的实参有正确的顺序
int ciStringCompare(const string& s1, const string& s2)
{
if (s1.size() < s2.size()) return ciStringCompareImpl(s1, s2);
else return -ciStringCompareImpl(s2, s1);
}
// 比较忽略大小写的字符串
// 要求s1的长度 <= s2的长度
int ciStringCompareImpl(const string& s1, const string& s2)
{
typedef pair<string::const_iterator, string::const_iterator> PSCI;
// mismatch标识出2个区间第一个对应值不相同的位置
PSCI p = mismatch(s1.begin(), s1.end(), s2.begin(), not2(ptr_fun(ciCharCompare)));
if (p.first == s1.end())
{
if (p.second == s2.end()) return 0; // s1和s2相等
else return -1; // s1比s2短
}
// 字符串之间的关系取决于第一个不相等的字符之间的关
return ciCharCompare(*p.first, *p.second); 系
}
ciStringCompareImpl 主要工作由mismatch完成,传递给mismatch的判别式 not2(ptr_fun(ciCharCompare)),判别式负责在2个字符匹配时返回true,不匹配时返回false且mismatch会停下。mismatch最终返回一对迭代器,指示2个区间中对应字符第一次比较失败的位置。
ptr_fun负责将函数指针转换为函数对象,not2放在ciCharCompare前面,用来构造一个谓词结果相反的二元函数对象。
方法二:使用lexicographical_compare比较忽略大小写的字符串是否相等
bool ciCharLess(char c1, char c2)
{
return tolower(static_cast<unsigned char>(c1)) < tolower(static_cast<unsigned char>(c2));
}
bool ciStringCompare(const string& s1, const string& s2)
{
return lexicographical_compare(s1.begin(), s1.end(), s2.begin(), s2.end(), ciCharLess);
}
lexicographical_compare是strcmp的一个泛化版本,strcmp只能与字符数组一起工作,lexicographical_compare 则能与任何类型的值的区间一起工作。strcmp总是通过比较2个字符来判断它们的关系(==,< or >),而lexicographical_compare 则可以接受一个判别式,由判别式来决定2个值是否满足一个用户自定义的准则。而上面的调用中,ciCharLess就是这个判别式。
方法三:不使用STL,牺牲移植性,并且明确指定字符串中不会包含内嵌的空字符('\0'),而且不考虑国际化支持,那么可以将string转化成const char*指针,调用C库函数strcmp或者strcmpi。如果是linux平台,还可以直接用strcasecmp;Windows平台,可以用stricmp(或者_stricmp)。
#ifdef _MSC_VER // MSVC编译器
#define strcmp_ignorecase _stricmp
#elif defined(__GNUC__) // GCC编译器
#define strcmp_ignorecase strcasecmp
#else
#define strcmp_ignorecase stricmp
#endif
int ciStringCompare2(const string& s1, const string& s2)
{
return strcmp_ignorecase(s1.c_str(), s2.c_str());
}
strcmp/strcmpi通常是被优化过的,在长字符串的处理上一般比通用算法mismatch和lexicographical_compare都要快得多。
[======]
第36条:理解copy_if算法的正确实现
STL中11个包含“copy”的算法:
copy, replace_copy, replace_copy_if, remove_copy, remove_copy_if, uninitialized_copy, copy_backward, reverse_copy, unique_copy, rotate_copy, partial_sort_copy
注意:C++11以后,STL已经加入了copy_if。
copy_if的自定义实现:
// copy_if的一个正确实现
template<typename InputIterator,
typename OutputIterator,
typename Predicate>
OutputIterator copy_if(InputIterator begin,
InputIterator end,
OutputIterator destBegin,
Predicate p)
{
while (begin != end)
{
if (p(*begin)) *destBegin++ = *begin;
++begin;
}
return destBegin;
}
[======]
第37条:使用accumulate或者for_each进行区间统计
假设你想对一个区间元素进行统计,STL算法count告诉你一个区间等于某个值的有多少个元素,count_if统计出满足某个判别式的元素个数。区间中最小值可以用min_element获得,最大值可以用max_element获得。
如果需要按某种自定义方式对区间进行统计处理,可能会需要比count、count_if等更为灵活的算法。
例如,你可能想计算一个容器中的字符串长度的总和;你可能想计算一个区间中的数值的乘积;你可能想要计算一个区间中所有点的平均坐标。
以上每种情形下,你都需要对一个区间进行统计处理(summarize),必须能够定义自己的统计方法。STL提供了这样的方法accumulate。
accumulate对区间求累加和
accumulate 用于求区间累加和,第三个参数指定初值,同时也指示了内部运算时用于保存和的类型。
#include <numeric>
list<double> ld;
for (size_t i = 0; i < 5; i++)
{
ld.push_back(i * 0.01);
}
double sum = accumulate(ld.begin(), ld.end(), 0.0); // 注意这里的0.0
cout << sum << endl;
例子中,累加和初值指定为0.0,而不是0,因为0.0是double类型,因此accumulate内部使用一个double变量用来保存累加和;如果是0,内部就会用int保存累加和,最终和值可能不正确。
accumulate的另一种形式:带一个初值和一个任意的统计函数,更加通用。
为了计算一个容器中字符串长度总和,accumulate需要知道两件事:1)起始的总和值(初值),本例该值为0;2)每碰到一个字符串时,如何更新总和值。
为了做到2),我们需要编写一个函数stringLengthSum,接受当前的长度总和值和新的字符串,然后返回更新后的总和值。
string::size_type stringLengthSum(string::size_type sumSoFar,
const string& s)
{
return sumSoFar + s.size();
}
set<string> ss;
ss.insert("a");
ss.insert("aa");
ss.insert("bbb");
string::size_type lengthSum = accumulate(ss.begin(), ss.end(),
static_cast<string::size_type>(0),
stringLengthSum);
cout << lengthSum << endl;
accumulate对区间求累乘积
还可以利用accumulate对区间求累计乘积。multiplies是STL函数类型模板,用于求2个数的乘积。
vector<float> vf;
...
float product = accumulate(vf.begin(), vf.end(), 1.0f, multiplies<float>()); // 注意:初值为1.0f而非0
cout << product << endl;
accumulate计算一个区间中所有点的平均值
点Point结构
struct Point
{
Point(double initX, double initY): x(initX), y(initY) { }
double x, y;
};
统计函数是一个函数对象类型PointAverage,其在accumulate中调用方法:
list<Point> lp;
...
Point agv = accumulate(lp.begin(), lp.end(), Point(0, 0), PointAverage());
PointAverage的工作原理是,记住所有看到的点的个数,并计算出这些点的x、y坐标总和。每次它被调用时,都会更新这些值,并且返回当前所有看到过点的平均坐标。2个传入参数:到目前为止的累计值,当前迭代器指向的值,由于值类型是Point,因此形参用const Point&更合适。
class PointAverage
{
public:
PointAverage(): xSum(0), ySum(0), numPoints(0) { }
const Point operator()(const Point& avgSoFar, const Point& p)
{
++numPoints;
xSum += p.x;
ySum += p.y;
return Point(xSum / numPoints, ySum / numPoints);
}
private:
double xSum; // 记录x坐标总和
double ySum; // 记录y坐标总和
size_t numPoints; // 记录点总数
};
然而,accumulate的函数不允许有副作用,而修改numPoints、xSum、ySum的值会带来副作用,因此,从技术上来讲,上面的代码是不可预测的。从实践上来说,应该能正常工作。
我们可以使用另外一个允许副作用的for_each。for_each也是一个可被用来统计区间的算法,而且不受accumulate的那些限制。for_each也有2个参数:区间,函数(或函数对象)--对区间中的每个元素都要调用这个函数。
class PointAverage
{
public:
PointAverage(): xSum(0), ySum(0), numPoints(0) { }
void operator()(const Point& p)
{
++numPoints;
xSum += p.x;
ySum += p.y;
}
Point result() const
{
return Point(xSum / numPoints, ySum / numPoints);
}
private:
double xSum;
double ySum;
size_t numPoints;
};
list<Point> lp;
... // 往lp添加数据
// 对区间每个元素调用函数对象PointAverage,最后一个点返回Point
Point avg = for_each(lp.begin(), lp.end(), PointAverage()).result();
for_each的函数参数允许有副作用,accumulate的函数参数不允许。why?(书中并没有给出明确的描述)
[======]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号