
《程序员的自我修养》读书笔记 - 第十一章 运行库
11.1 入口函数和程序初始化
11.1.1 程序从main开始吗?
先看3个程序
程序1(C):
#include <stdio.h>
#include <stdlib.h>
int a = 3;
int main(int argc, char *argv[])
{
int *p = (int *)malloc(sizeof(int));
scanf("%d", p);
printf("%d", a + *p);
free(p);
}
程序执行到main时,全局变量a已经初始化完毕了(能确定a值)。main的2个参数argc和argv也被正确传入。另外,堆和栈的初始也完成了,系统IO也初始化了。因此可以使用printf, scanf和malloc。
程序2(C++):
#include <string>
using namespace std;
string v;
double foo()
{
return 1.0;
}
double g = foo();
int main() {}
main之前,对象v的构造函数,用于初始化全局变量g的函数foo都会在main之前调用。
程序3(C):
void foo(void)
{
printf("bye!\n");
}
int main()
{
atexit(&foo);
pritnf("endof main\n");
}
atexit注册的函数是在main结束之后,进程退出之前调用的。因此程序输出是:
endof main
bye!
这3个程序足以说明main函数不是程序的第一行代码,而是别的,这部分代码负责准备好main执行所需环境,负责调用main,main返回后记录其返回值,并且调用atexit注册的函数,然后结束进程。运行这些代码的函数称为入口函数或入口点(Entry Point)(不同平台函数名可能不同)。
一个典型的程序运行步骤:
1)OS创建进程后,把控制器交给程序入口,该入口往往是运行库的某个入口函数;
2)入口函数对运行库和程序运行环境进行初始化,包括堆、I/O、线程、全局变量构造等;
3)入口函数在完成初始化之后,调用main函数,正式开始执行程序的主体部分;
4)main函数执行完毕后,返回到入口函数,入口函数进行清理工作,包括全局变量析构、堆销毁、关闭I/O等,然后进行系统调用结束进程;
11.1.2 入口函数如何实现?
- GLIBC入口函数
glibc启动过程在不同的情况下差别很大,如静态的glibc和动态的glibc,glibc用于可执行文件和用于共享库的差别,就可以组合出4种情况。这里只选取最简单的静态glibc用于可执行文件的时候作为例子,其他情况参考glibc和gcc源码。
glibc官网 源码下载地址: https://www.gnu.org/software/libc/sources.html
下面默认为静态/可执行文件链接的情况为例。其中,libc/csu中,有关于程序启动的代码。glibc程序入口_start,由ld链接器默认的链接脚本指定。_start由汇编实现,和平台相关,下面是i386的_start实现:
glibc\sysdeps\i386\elf\start.S
ENTRY (_start)
/* Clearing frame pointer is insufficient, use CFI. */
cfi_undefined (eip) // cfi_ 指令 取消eip寄存器之前的值,不能再恢复
/* Clear the frame pointer. The ABI suggests this be done, to mark
the outermost frame obviously. */
xorl %ebp, %ebp // ebp = 0 ( ebp = ebp ^ ebp ), ebp我们知道代表的是栈底, ebp为0体现出这是最外层函数
/* Extract the arguments as encoded on the stack and set up
the arguments for `main': argc, argv. envp will be determined
later in __libc_start_main. */
popl %esi /* Pop the argument count. */
movl %esp, %ecx /* argv starts just at the current stack top.*/
/* Before pushing the arguments align the stack to a 16-byte
(SSE needs 16-byte alignment) boundary to avoid penalties from
misaligned accesses. Thanks to Edward Seidl <seidl@janed.com>
for pointing this out. */
andl $0xfffffff0, %esp
pushl %eax /* Push garbage because we allocate
28 more bytes. */
/* Provide the highest stack address to the user code (for stacks
which grow downwards). */
pushl %esp
pushl %edx /* Push address of the shared library
termination function. */
#ifdef PIC
/* Load PIC register. */
call 1f
addl $_GLOBAL_OFFSET_TABLE_, %ebx
/* This used to be the addresses of .fini and .init. */
pushl $0
pushl $0
pushl %ecx /* Push second argument: argv. */
pushl %esi /* Push first argument: argc. */
# ifdef SHARED
pushl main@GOT(%ebx)
# else
/* Avoid relocation in static PIE since _start is called before
it is relocated. Don't use "leal main@GOTOFF(%ebx), %eax"
since main may be in a shared object. Linker will convert
"movl main@GOT(%ebx), %eax" to "leal main@GOTOFF(%ebx), %eax"
if main is defined locally. */
movl main@GOT(%ebx), %eax
pushl %eax
# endif
/* Call the user's main function, and exit with its value.
But let the libc call main. */
call __libc_start_main@PLT
#else
/* This used to be the addresses of .fini and .init. */
pushl $0
pushl $0
pushl %ecx /* Push second argument: argv. */
pushl %esi /* Push first argument: argc. */
pushl $main
/* Call the user's main function, and exit with its value.
But let the libc call main. */
call __libc_start_main
#endif
hlt /* Crash if somehow `exit' does return. */
#ifdef PIC
1: movl (%esp), %ebx
ret
#endif
END (_start)
可以看到_start函数最终调用了__libc_start_main函数。
-
cfi_undefined (eip): 取消eip寄存器之前的值,不能再恢复 参考as 使用手册 CFI directives之.cfi_undefined register
-
xorl %ebp, %ebp:ebp寄存器清零。xorl是2个操作数做异或运算,结果存储在第一个操作数里。ebp我们知道代表的是栈底, ebp为0体现出这是最外层函数。
-
popl %esi及movl %esp, %ecx:调用_start前,装载器会把用户参数和环境变量压入栈中,按其压栈方法,实际上栈顶元素是argc,接着是argv和环境变量数组 (压栈顺序 环境变量 -> argv -> argc)。下图是此时栈布局,其中虚线箭头old esp是执行
popl %esi之前的栈顶(%esp),实线箭头esp是执行之后的栈顶(%esp)。
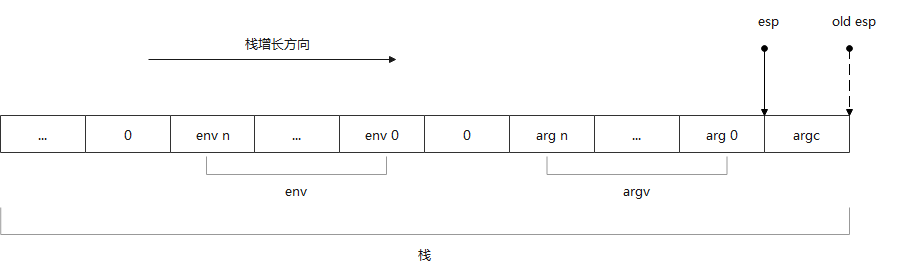
popl %esi将argc存入esi,而movl %esp, %ecx将栈顶地址(此时就是argv和环境变量(env)数组的起始地址)传给%ecx。现在%esi指向argc,%ecx指向argv及环境变量数组。
省去不重要的代码,可以把_start改写成可读性更强的伪代码:
void _start()
{
%ebp = 0;
int argc = pop from stack;
char **argv = top of stack;
__libc_start_main(main, argc, argv, __libc_csu_init, __libc_csu_fini, edx, top of stack);
}
其中,argv除了指向参数表外,还隐含紧接着环境变量表。这个环境变量表要在__libc_start_main中从argv内提取出来。
环境变量:
环境变量存在于系统中的一些公用数据,任何程序都可以访问。通常,环境变量存储的都是一些系统的公共信息,如系统搜索路径(PATH),当前OS版本等。格式为key=value字符串,C语言可用getenv函数来获取环境变量信息。
Windows下,可在控制面板->系统->高级->环境变量查阅当前的环境变量;Linux下,直接在命令行输入export即可。
_start实际执行代码的函数是__libc_start_main,代码比较长,下面一段段看:
_start -> __libc_start_main:
int __libc_start_main(
int (*main) (int, char **, char **),
int argc,
char *__unbounded *__unbounded ubp_av,
__typeof (main) int,
void (*fini) (void),
void (*rtld_fini) (void),
void *__unbounded stack_end
)
{
#if __BOUNDED_POINTERS__
char *argv;
#else
#define argv ubp_av;
#endif
int result;
这是__libc_start_main函数头部,与_start里的调用一致,共7个参数,main由第一个参数传入,然后是argc、argv(这里是ubp_av,因为包含了环境变量表)。除了main的函数指针外,外部还要传入3个函数指针:
1)init:main调用前的初始化工作;
2)fini:main结束后的收尾工作;
3)rtld_fini:和动态加载有关的收尾工作,rtld是runtime loader(运行时加载器)缩写;
最后一个参数stack_end,标明了栈底的地址,通常是最高的栈地址。
- bounded pointer
GCC支持bounded类型指针(bounded指针用__boundes关键字标出,若默认bounded指针,则普通指针用__unboundes标出),bounded指针占用3个指针的空间:第一个空间,存储原指针的值;第二个空间存储下限值;第三空间存储上限值。__ptrvalue、__ptrlow、__ptrhigh宏定义分别返回这3个值,有了这3各值以后,内存越界错误很容易查出来。并且要定义__BOUNDED_POINTERS__这个宏采有作用,否则这3个宏定义是空的。
尽管bounded指针看上去很有用,但这个功能在2003年被去掉了。因此,现在所有关于bounded指针的关键字其实都是一个空宏。因此,接下来讨论libc代码时,都默认不使用bounded指针(<=>不定义__BOUNDED_POINTERS__)。
接下来代码:
char **ubp_ev = &ubp_av[argc + 1];
INIT_ARGV_and_ENVIRON;
__libc_stack_end = stack_end;
INIT_ARGV_and_ENVIRON宏定义 位于libc/sysdeps/generic/bp-start.h,展开后本段代码变成:
char **ubp_ev = &ubp_av[argc + 1];
__environ = ubp_ev;
__libc_stack_end = stack_end;
注意:INIT_ARGV_and_ENVIRON和bp-start.h在新版本glibc(2.34)中已经移除了,而是直接利用__environ。
这段代码设置了全局环境变量指针__environ,还将栈底地址stack_end存储在了全局变量__libc_stack_end中。
为什么要分两步给__envion赋值?
这是为了兼容bounded,因为INIT_ARGV_and_ENVIRON根据bounded支持的情况有多个版本,以上仅仅是假定不支持bounded的版本。
栈上环境变量和参数数组内存布局:
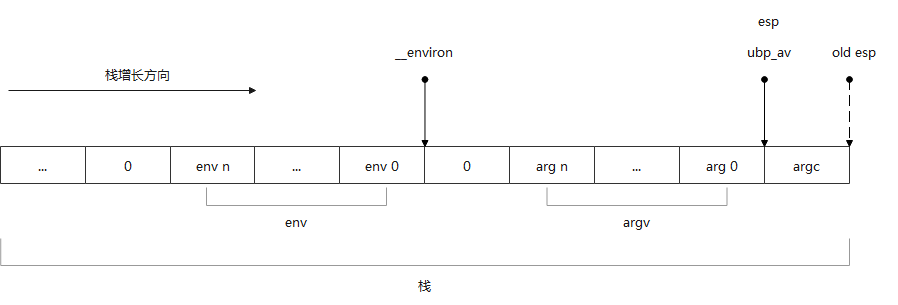
接下来有另一个宏:
DL_SYSDEP_OSCHECK (__libc_fatal);
用来检查OS版本,具体内容不再列出。 接下来代码较繁琐,过滤掉大量信息保留关键函数调用:
__pthread_initialize_minimal();
__cxa_atexit(rtld_fini, NULL, NULL);
__libc_init_first(argc, argv, __environ);
__cxa_atexit(fini, NULL, NULL);
(*init)(argc, argv, __environ);
__cxa_init_first是glibc内部函数,等同于atexit,用于将参数指定的函数在main结束后调用(i.e. 注册退出清理函数),让以参数传入fini和rtld_fini均是用于main结束之后调用的。
在__libc_start_main末尾:
result = main(argc, argv, __environ);
exit(result);
} // !end __libc_start_main
在最后,main函数被调用,并退出。
接下来看看exit实现:
_start -> __libc_start_main -> exit:
void exit(int status)
{
while (__exit_funcs != NULL)
{
...
__exit_funcs = __exit_funcs->next;
}
...
_exit(status);
}
__exit_funcs是存储由__cxa_atexit和atexit注册的(退出清理)函数的链表,这里的while循环遍历该链表并逐个调用这些注册的函数。
可以明显看到,exit函数会在末尾调用_exit,这与OS描述“库函数exit内部调用系统调用_exit退出进程” 一致。而_exit实现由汇编实现,与平台相关,下面i386实现:
_start -> __libc_start_main -> exit -> _exit:
_exit:
movl 4(%esp), %ebx
movl $__NR_exit, %eax
int $0x80
hlt
_exit作用仅仅是调用了__NR_exit这个系统调用。_exit调用后,进程就会直接结束。
程序正常结束两种情况:
1)main函数返回;
2)程序中,调用exit退出;
2种情况都会调用exit,atexit注册的退出清理函数交给exit来做是没有问题的。
注意:_start和_exit末尾都有一个hlt指令,是因为在linux里,进程必须使用exit系统调用结束。而一旦exit被调用,程序运行就终止,因此实际上_exit末尾hlt不会执行,从而__libc_start_main不会放,_start末尾hlt指令也不会执行。_exit末尾hlt指令使程序停止运行,处理器进入暂停状态,不执行任何操作,不影响标志。hlt指令的存在是为了检测exit系统调用是否成功。如果失败,程序就不会终止,hlt指令可以发挥作用强行把程序停下来。而_start里的htl作用也如此,但为了预防某种没有调用exit(非exit系统调用),就回到_start的情况(如有人误删__libc_main_start末尾的exit)。
- MSVC CRT入口函数
- 为什么MSVC的Win32程序入口使用的是WinMain?
因为WinMain和main一样,都不是程序的实际入口。MSVC的程序入口是同一段代码,但根据不同的编译参数被编译成了不同的版本。不同版本的入口函数在其中会调用不同名字的函数。不同版本的入口函数在其中会调用不同名字的函数,包括main/wmain/WinMain/wWinMain等。
其他略。
11.1.3 运行库与I/O
IO(或I/O)指输入和输出(Input/Output)。对于计算机,I/O代表了计算机与外界交互,交互对象可以是人或其他设备。
而对于程序,I/O涵盖范围更广。一个程序的I/O指程序与外界的交互,包括文件、管道、网络、命令行、信号等。广义上,I/O代指任何OS理解为“文件”的事务。Linux和Windows都将各种具有输入、输出概念的实体(设备、磁盘文件、命令行等),统称为文件。
C库使用文件简单代码:
#include <stdio.h>
int main(int argc, char *argv[])
{
FILE* f = fopen("test.data", "wb");
if (f == NULL)
return -1;
fwrite("1230", 3, 1, f);
fclose(f);
return 0;
}
OS层面,文件操作也有类似于FILE的概念,Linux下叫文件描述符(File Descriptor),Windows下句柄(Handle),代表一个文件。以下统称(文件)句柄。
为什么要设计句柄?
因为句柄可以防止用户随意读写OS内核的文件对象,文件句柄总是和内核的文件对象关联,但如何关联的细节对用户是透明的。
Linux中,值为0/1/2的fd,分别代表标准输入、标准输出、标准错误输出,在<unistd.h>中定义为STDIN_FILENO(0)、STDOUT_FILENO(1)、STDERR_FILENO(2),对应FILE指针stdin、stdout、stderr。每个进程都有一个私有的文件描述符表,每个元素都指向一个内核打开的文件对象,fd就是这个表的下标。
11.1.4 MSVC CRT的入口函数初始化
略
11.2 C/C++运行库
11.2.1 C语言运行库
任何一个语言的程序,背后都有一套庞大代码来支撑,以使得程序正常运行,这套代码包括入口函数,及其所依赖的函数所构成的函数集合,各种标准库函数的实现。这样的代码集合称为运行时库(Runtime Library)。而C语言的运行库,称为CRT。
CRT大致包含如下功能:
1)启动与退出:包括入口函数,及入口函数所依赖的其他函数等;
2)标准函数:由C语言标准规定的C语言标准库所拥有的函数实现;
3)I/O:I/O功能的封装和实现,参见上一节I/O初始化部分;
4)堆:堆的封装和实现,参见第十章堆初始化部分;
5)语言实现:语言中一些特殊功能的实现;
6)调试:实现调试功能的代码;
11.2.2 C语言标准库
本节介绍C语言标准库的基本函数集合,并对其中一些特殊函数进行详细的介绍。ANSI C标准库由24个.h头文件组成,仅包含数学函数、字符/字符串处理、I/O等基本方面,如:
1)标准输入输出(stdio.h);
2)文件操作(stdio.h);
3)字符操作(ctype.h);
4)字符串操作(string.h);
5)数学函数(math.h);
6)资源管理(stdlib.h);
7)格式转换(stdlib.h);
8)断言(assert.h);
9)各种类型上的常熟(limits.h & float.h);
【特殊库】
10)变长参数(stdarg.h);
11)非局部跳转(setjmp.h);
这里仅介绍两组特殊函数细节。
- 变长参数
C语言特殊参数形式,如printf
int printf(const char *format, ...);
printf函数除了第一个参数类型为const char*外,其后可追加任意数量、任意类型的参数。在函数实现部分,可以使用stdarg.h里多个宏来访问各个额外参数:假设lastarg是变长参数列表最后一个有名字的参数(如printf的format),那么在函数内部定义类型va_list的变量:
va_list ap;
该变量以后会依次指向各个可变参数。ap必须用宏va_start初始化一次,其中lastarg必须是函数的最后一个具有名称的参数。
va_start(ap, lastarg);
va_start之后,就可以用va_arg宏来获得下一个不定参数了(假设已经知道其类型为type,type可以是int, char, char *, struct 等等):
type next = va_arg(ap, type);
在具有可变长参数的函数结束前,还必须用宏va_end来清理现场。
- 先介绍一下变长参数的实现原理
变长参数实现得益于C默认的cdecl调用惯例,自右向左压栈传递方式。设想如下函数:
int sum(unsigned num, ...);
函数语义是:第一个参数传递一个整数num,后面会传递num个整数,返回num个整数的和。
当调用int n = sum(3, 16, 38, 53);时,参数在栈上布局:
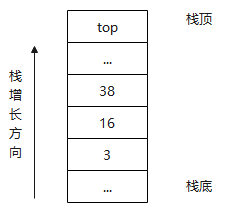
在函数内部,sum函数可以使用名称num(其实是地址)来访问数字3,但无法使用任何名称来访问其他几个不定参数。但此时粘上其他几个参数实际恰好依序排列在参数num的高地址方向,因此可以简单通过num地址计算出其他参数的地址。sum函数实际相当于:
int sum(unsigned num, ...)
{
int *p = &num + 1;
int ret = 0;
while (num--)
ret += *p++; // nums靠近栈底,通常属于低地址部分,因此p++可以访问位于栈高地址其他参数
return ret;
}
可以看到2个事实:
1)sum获取参数的数量仅取决于num参数的值,因此如果num参数值 ≠ 实际传递不定参数数量,那么sum可能取到错误或不足的参数;
2)cdecl调用惯例保证了参数的正确清除。如stdcall是由被调用方负责清除堆栈的参数,而被调用方根本不知道有多少参数被传递进来,所有无法清除堆栈。而cdecl是调用方负责清除堆栈,因此没有这个问题。
printf的不定参数比sum更复杂,因为printf参数不仅数量不定,而且类型不定。因此printf需要在格式字符串中注明参数的类型,如用%d表明是一个整数。printf里的格式字符串如果将类型描述错误,因为不同参数大小不同,不仅可能导致这个参数输出错误,还有可能导致其后一系列参数错误。
printf错误输出:
#include <stdio.h>
int main()
{
printf("%lf\t%d\t%c\n", 1, 666, 'a');
}
示例中,printf第一个输出参数是int(4byte),而格式字符串%ld告诉printf要在堆栈上取一个8byte的double数据,因此printf输出会出错。因为printf在读取double时,实际造成越界,后面几个参数的输出也会失败。
注意:有的现代编译器,可能已经修复了这个问题,无法复现问题。
- va_list等宏如何实现?
va_list 实际是一个指针,用来指向各个不定参数。由于类型不明,因此该va_list以void *或char *为最佳选择。
va_start 将va_list定义的指针指向函数的最后一个有名参数后面的位置,这个位置就是第一个不定参数。
va_arg 获取当前不定参数的值,并根据当前不定参数的大小,将指针移向下一个参数。因此va_arg需要获知参数类型信息(类型长度)。
va_end 将指针清0。
按以上思路,va系列宏一个最简单实现:
#define va_list char *
#define va_start(ap, arg) (ap=(va_list)&arg + sizeof(arg))
#define va_arg(ap, t) (*(t*)(ap += sizeof(t)) - sizeof(t))
#define va_end(ap) (ap = (va_list)0)
- 变长参数宏
很多时候希望定义宏的时候,也能像printf一样可以使用变长参数,即宏的参数可以是任意个,该功能可由编译器的变长参数宏实现。
GCC编译器下,变长参数宏可以使用“##”宏字符串连接操作实现,如:
#define printf(args...) fprintf(stdout, ##args)
那么printf("%d %s", 123, "hello")会被展开为:
fprintf(stdout, "%d %s", 123, "hello")
而在MSVC下,可以使用编译器内置宏__VA_ARGS__,跟上面GCC使用“##”效果一样,如:
#define printf(...) fprintf(stdout, __VA_ARGS__)
- 非局部跳转
非局部跳转在C语言里是一个备受争议的机制。使用非局部跳转,可以实现一个函数体内向另一个事先登记过的函数体内跳转,而不用担心堆栈混乱。
示例:
#include <setjmp.h>
#include <stdio.h>
jmp_buf b;
void f()
{
longjmp(b, 1); // 跳转到事先登记的跳转点b
}
int main()
{
if (setjmp(b)) // setjmp(b) 登记跳转点b
printf("World!");
else
{
printf("Hello ");
f();
}
}
按常理,不论setjmp返回什么,也只会打印"Hello "和"World!"二者之一,然而事实却输出:
Hello World!
这是因为,当setjmp正常返回时,返回0,因此会打印"Hello "字样。而longjmp的作用,就是让程序的执行流回到当初setjmp登记的跳转点,并且返回由longjmp(参数2)指定的返回值1,自然接着打印出"World!"并退出。
注意:这不是结构化编程,通常情况下,不推荐使用setjmp、longjmp。
11.2.3 glibc与MSVC CRT
略
11.3 运行库与多线程
11.3.1 CRT的多线程困扰
线程的访问权限
线程可以访问进程内存里所有数据,包括其他线程的堆栈(前提是知道其他线程的堆栈地址)。实际应用中,线程也有自己的私有存储空间,包括:
- 栈(虽然可以被其他线程访问,但通常仍被认为是私有数据);
- 线程局部存储(Thread Local Storage,TLS)。某些OS为线程单独提供的私有空间,通常尺寸有限;
- 寄存器(包括PC),寄存器是执行流的基本数据,因此为线程私有;
C程序员角度,线程私有和非私有数据:
| 线程私有 | 线程之间共享(进程所有) |
|---|---|
| 局部变量(栈) 函数参数(栈) TLS数据(线程局部存储) |
全局变量 堆上的数据 函数里的静态变量 程序代码,任何线程都有权利读取并执行任何代码 打开文件,A线程打开的文件可由B线程读写 |
多线程运行库
C++03、C89、C99都不支持多线程。我们常说的“多线程相关”主要指2个方面:1)提供那些多线程操作的接口,如创建线程、退出线程、设置线程优先级等函数接口;2)C运行库本身要能在多线程环境下正确运行;
对于1),Windows下的MSVC CRT提供了诸如_beginthread(), _endthread()等函数,Linux下的glibc提供了可选线程库pthread,提供诸如pthread_create(), pthread_exit()等函数,用于线程的创建和退出。但都不属于标准运行库,和平台相关。
对于2),CRT最初设计时,没有考虑多线程环境(因为当时没多线程概念),例如:
(1)errno:系统调用的错误代码在函数返回前,赋值给errno全局变量。多线程并发时,A线程的errno值可能会被B线程覆盖。
(2)strtok()等函数:内部使用了static局部变量,来存储字符串位置,不同线程调用该函数会造成static 局部变量混乱。
(3)malloc/new,free/delete:堆分配/释放函数或关键字在不加锁时,线程不安全。由于这些函数/关键字的调用十分频繁,因此在保证线程安全时显得很繁琐。
(4)异常处理:早期C++运行库里,不同线程抛出的异常会彼此冲突,从而造成信息丢失。
(5)printf/fprintf及其他IO函数:流输出函数同样线程不安全,因为它们共享了一个控制台或文件输出。不同的输出并发时,信息会混杂在一起。
(6)其他线程不安全函数:包括与信号相关的一些函数。
通常情况下,C标准库中在不进行线程安全保护的情况下,自然地具有线程安全属性的函数(不考虑errno):
(1)字符处理(ctype.h):包括isdigit, toupper等,也是可重入的;
(2)字符串处理函数(string.h):包括strlen、strcmp等,但其中涉及对参数中的数组进行写入的函数(如strcpy),仅在参数中数组各不相同时可以并发;
(3)数学函数(math.h):包括sin、pow等,也是可重入的;
(4)字符串转整数/浮点数(stdlib.h):包括atof、atoi、atol、strtod、strtol、strtoul;
(5)获取环境变量(stdlib.h):包括getenv,也是可重入的;
(6)变长数组辅助函数(stdarg.h);
(7)非局部跳转函数(setjmp.h):包括setjmp和longjmp,前提是longjmp仅跳转到本线程设置的jmpbuf上;
为了解决C标准库在多线程环境下的问题,许多编译器附带了多线程版本运行库。
11.3.2 CRT改进
使用TLS(线程局部存储)
对于全局变量errno,多线程运行库如何改进?
首先,让errno称为各个线程的私有成员。glibc中,errno被定义为一个宏,如:
#define errno (*__errno_location ())
函数__errno_location在不同库版本有不同定义,在单线程版本中,直接返回全局变量errno的地址;在多线程版本中,不同线程调用__errno_location返回的地址则各不相同。MSVC中,errno实现方式和glibc类似。
加锁
多线程版本的运行库中,线程不安全的函数内部都会自动地进行加锁,包括malloc、printf等,而异常处理的错误也早解决了。因此使用多线程版本的运行库时,即使应用程序员在malloc/new前后不加锁,也不会出现并发冲突。
注意:加锁只能确保确保线程安全,并不能保证函数可重入。因为可重入还要求信号处理程序中调用也是安全的。
改进函数调用方式
一种改进方是:修改所有线程不安全的函数的参数列表,改成某种线程安全的版本。如MSVC CRT提供strtok_s作为strtok的线程安全版本,它们原型:
char *strtok(char *strToken, const char *strDelimit);
char *strtok_s(char *strToken, const char *strDelimit, char **context);
改进后的strtok_s增加了一个context参数,是由调用者提供的一个char *指针,strtok_s每次调用后的字符串位置保存在这个指针中。而之前版本的strtok函数,会将这个位置保存在一个函数内部的静态局部变量中,如果有多个线程同时调用这个函数,就可能出现混乱。Glibc提供类似线程安全版本,不过函数名是strtok_r()。
注意:改变标准库函数的做法有一定局限性,因为标准库不能随意修改,如果修改了,那么所有遵循该标志的程序都需要程序修改。更好的做法是,不改变标准库函数的原型,只对实现修改,使得在多线程环境下也能顺利进行,做到向后兼容。
11.3.3 线程局部存储实现
为什么有了栈和寄存器,还要线程局部存储?
因为栈和寄存器存储不可靠,栈会在函数退出和进入时改变,而寄存器的数量太少了。
假设要在线程中使用一个全局变量,但希望这个全局变量是线程私有,而不是所有线程共享的。怎么办?
可以用到线程局部存储(TLS,Thread Local Storage)机制。
TLS用法:
如果要定义一个全局变量为TLS类型,只需要在定义前加上相应的关键字即可。对于GCC,关键字就是__thread:
__thread int number;
对于MSVC,关键字是__declspec(thread):
__declspec(thread) int number;
一旦定义了一个TLS类型全局变量,那么每个线程都会拥有这个变量的一个副本,线程对它的修改都是相互独立的。
Windows TLS实现
- Windows如何实现TLS变量,每个线程一个副本?
对于Windows,正常情况下一个全局变量或静态变量会被放到“.data”(初始化数据段)或“.bss”(未初始化数据段),但当使用__declspec(thread)定义一个线程私有变量时,编译器会把这些变量放到PE文件的“.tls”段中。当系统启动一个新线程时,会从进程的堆中分配一块足够大小的空间,然后把“.tls”段的内容复制到这块空间,于是每个线程都有自己独立的一个“.tls”副本。因此,虽然用__declspec(thread)定义同一个变量,但它们在不同线程中的地址是不一样的。
当一个TLS变量是C++全局对象时,那么每个线程启动时,不仅仅复制“.tls”的内容,还需要把这些TLS对象初始化,必须逐个地调用它们的全局构造对象,而当线程退出时,还有逐个对象地析构,如普通全局对象在进程启动和退出时都要构造、析构一样。
Windows PE文件结构中有个叫数据目录的结构,共有16个元素,其中有一个元素下标IMAGE_DIRECT_ENTRY_TLS,该元素保存的地址和长度就是TLS表的地址和长度。TLS表保存了所有TLS变量的构造函数、析构函数地址,Windows系统根据TLS表内容,在每次线程启动、退出时对TLS变量进行构造、析构。TLS表本身通常位于PE “.rdata”段中。
- TLS变量对每个线程来说,地址都不一样,那么线程如何访问这些变量呢?
对于每个Windows线程来说,系统都会建立一个关于线程信息的结构,叫线程环境块(TEB,Thread Environment Block)。该结构保存了线程的堆栈地址、线程ID等相关信息,其中有一个域是TLS数组(元素数量固定,一般是64),它在TEB中偏移0x2C。
对每个线程来说,x86的FS段寄存器所指的段就是该线程TEB,于是要得到一个线程的TLS数组的地址,就可以通过FS:[0x2C]访问到。
注意:TEB结构不公开,可能随Windows版本变化。
显式TLS
使用__thread或__declspec(thread)关键字定义全局变量为TLS变量的方法称为隐式TLS,即程序员无需关心TLS变量的申请、分配和释放,编译器+运行库+OS搞定这一切。
还有一种显式TLS的方法,程序员需要手工申请TLS变量,每次访问该变量时,都要调用相应的函数得到变量的地址,在访问完后释放变量。
Windows下,系统提供了TlsAlloc(), TlsGetValue(), TlsSetValue(), TlsFree()这4个API用于显式TLS变量申请、取值、赋值和释放;
Linux下,pthread提供库函数pthread_key_create(), pthread_getspecific(), pthread_setspecific(), pthread_key_delete() 。
显式TLS是如何存储的?也是使用TEB结构的TLS数组来保存TLS数据。因为TLS数组元素数量固定(64),显式TLS在实现时,如果发现该数组已经被用完了,就会额外申请4096byte作为二级TLS数组,使得在WindowsXP下最多能拥有1088(1024+64)个显式TLS变量(也包括隐式TLS占用部分)。
显式TLS的使用十分麻烦,不推荐使用,除非使用的元素数量超过TLS数组元素数上限。
C++全局构造与析构
本节主要阐述:glibc和MSVC CRT,如果在main前后完成全局变量的构造与析构?
11.4.1 glib全局构造与析构
glibc启动文件时的2个代码段“.init”和“.finit”段,最终会拼成2个函数_init()和_finit(),它们会先于/后于main函数的执行。但是,它们具体是在什么时候执行?由谁调用呢?又是如何对全局对象构造和析构呢?
下面从_start入口函数开始,逐渐找到这些问题的答案。
对下面这样的代码编译出来的可执行文件,进行分析:
class HelloWorld
{
public:
HelloWorld();
~HelloWorld();
};
HelloWorld Hw;
HelloWorld::HelloWorld()
{
...
}
HelloWorld::~HelloWorld()
{
...
}
int main()
{
return 0;
}
由_start传递进来的init函数指针指向__libc_csu_init函数,而init实际指向了__libc_csu_init函数(位于csu\Elf-init.c):
_start -> __libc_start_main -> __libc_csu_init
void __libc_csu_init(int argc, char **argv, char **envp)
{
...
_init();
const size_t size = __init_arrary_end - __init_array_start;
for (size_t i = 0; i < size; i++)
(*__init_array_start [i])(argc, argv, envp);
}
__libc_csu_init调用的是“.init”段,用户存放在“.init”段的代码在这里执行。_init是位于crti.o中的函数,是由各个输入目标文件中的“.init”段拼凑而来的。反汇编可执行文件,可以发现_init()调用了__do_global_ctors_aux,而后者来自GCC提供的一个目标文件crtbegin.o,说明这部分是与语言密切相关的函数。显然,C++全局对象的构造和析构是与语言密切相关的。
__do_global_ctors_aux位于gcc/Crtstuff.c:
_start -> __libc_start_main -> __libc_csu_init -> __do_global_ctors_aux
void __do_global_ctors_aux(void)
{
/* Call constructor functions */
unsigned long nptrs = (unsigned long) __CTRO_LIST__[0]; // 取得数组第一个元素
unsigned i;
for (i = nptrs; i >= 1; i--)
__CTRO_LIST__[i] (); // 调用第i个函数指针指向的函数
}
数组__CTRO_LIST__存放的是所有全局对象的构造函数的指针。问题来了:谁负责构建这个数组呢?
对于每个编译单元(.cpp),GCC编译器会遍历其中所有的全局对象,生成一个特殊的函数,其作用是对本编译单元里的所有全局对象进行初始化。GCC在目标代码中,生成了一个名为GLOBAL__I_Hw的函数,负责本编译单元所有全局/静态对象的构造和析构,其代码可以表示成:
static void GLOBAL__I_Hw(void) // 当前.cpp文件的全局构造函数
{
Hw::Hw(); // 构造对象
atexit(__tcf_1); // 一个神秘的函数__tcf_1__被注册到了exit
}
一旦一个目标文件里GLOBAL__I_Hw这样的特殊函数,编译器会在编译单元参数的目标文件(.o)的".ctors"段放置一个指针,指向GLOBAL__I_Hw。
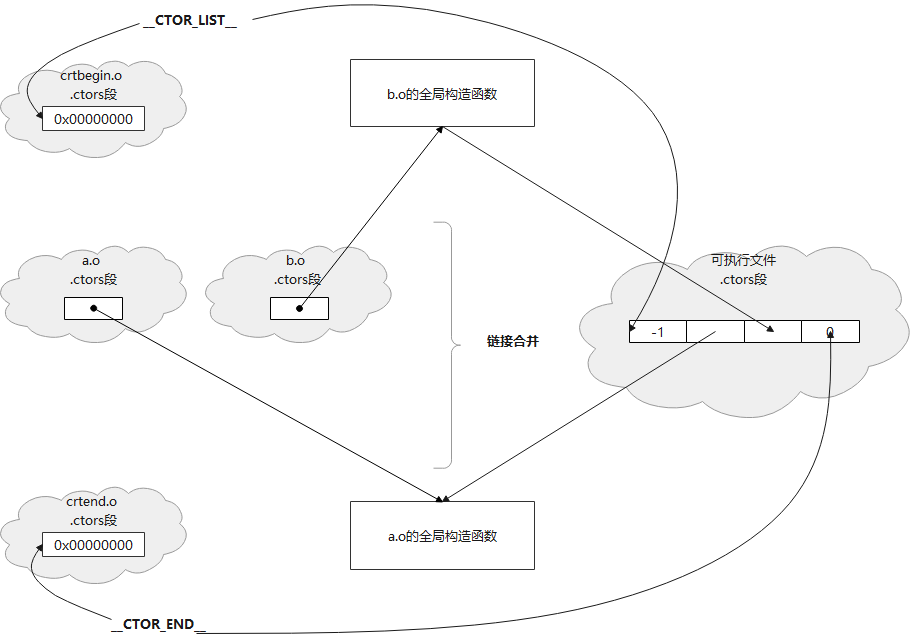
编译器为每个编译单元生成一份特殊函数后,链接器在连接这些目标文件时,会将这些同名的段合并在一起,这样,每个目标文件的.ctors段会被合并成一个.ctor段。每个目标文件的.ctors存储了一个指向该目标文件的全局构造函数(GLOBAL__I_Hw),因此,拼接起来的.ctors段就是一个函数指针数组,每个元素都指向一个目标文件的全局构造函数。
如何获取这个指针数组(的地址)呢?
链接的时候,各个用户产生的目标文件前后分别还要链接上2个glibc自身的目标文件crtbegin.o, crtend.o,这2个文件同样具有.ctors段,这2个文件的.ctors段内容也会被合并到最终的可执行文件中。
-
crtbegin.o: 作为所有.ctors段的开头部分,crtbegin.o的.ctor段内存储的是4byte -1(0xFFFFFFFF),由链接器负责将这个数字改成全局构造函数的数量。然后,这个段还将起始地址定义成符号
__CTOR_LIST__,代表所有.ctor段最终合并后的起始地址。 -
crtend.o: 文件内.ctors内容简单,就是一个0,然后定义了一个符号
__CTOR_END__,指向.ctor段末尾。
链接2个用户的目标文件a.o和b.o时,实际链接的目标文件顺序:crti.o crtbegin.o a.o b.o crtend.o crtn.o。其中,crti.o,crtn.o是用于提供main之前和之后执行代码的机制,与全局构造无关;合并crtbegin.o,用户目标文件(a.o和b.o),crtend.o时,链接器按顺序拼接这些文件的.ctors段。如下图所示:
TIPS:可以手动在.ctors段里添加函数指针,让这些函数在全局构造的时候(main之前)调用:
#include <stdio.h>
void my_init(void)
{
printf("Hello");
}
typedef void (*ctor_t)(void);
// 在.ctors段添加一个函数指针
ctor_t __attribute__((section (".ctors"))) my_init_p = &my_init;
int main()
{
printf("World!\n");
return 0;
}
运行程序,将打印:Hello World! (my_init函数在main之前被调用)。
gcc另一种更直接的方法,使用__attribute__((constructor)):
#include <stdio.h>
void my_init(void) __attribute__ ((constructor));
void my_init(void)
{
printf("Hello ");
}
int main()
{
printf("World!\n");
return 0;
}
析构
老的做法:
程序结束之前,crt还有进行对象的析构。其过程类似于前面的构造,所有函数、符号名一一对应,如".init" => ".finit",__do_global_ctor_aux => __do_global_dtor_aux, __CTOR_LIST__ => __DTOR_LIST__等。
入口函数,__libc_start_main将__libc_csu_fini通过__cxa_exit()注册到退出列表中,当进程退出当前,exit()就会调用__libc_csu_fini。而_fini原理同_init。
新的做法:
老做法要求链接器包装的所有".dtor"段合并顺序必须是".ctor"的严格反序,增加了链接器的工作量,后来放弃了这种做法,提出一种新的做法:通过__cxa_atexit()在exit()函数中注册进程退出回调函数来实现析构。
回到GLOBAL__I_Hw(),编译器对每个编译单元的全局对象,都会生成一个特殊的函数来调用这个编译单元的所有全局对象的析构函数,其调用顺序与GLOBAL__I_Hw()调用构造函数的顺序刚好相反。编译器生成的神秘函数__tcf_1大致内容:
static void __tcf_1(void) // 编译器生成的名字
{
Hw.~HelloWorld();
}
__tcf_1函数负责析构Hw对象,而在GLOBAL__I_Hw中,我们通过__cxa_exit()注册了__tcf_1,而通过__cxa_exit()注册的函数在进程退出时被调用顺序满足先注册后调用的特定,这样,析构顺序与构造顺序完全符合(先构造后析构)。
TIPS1:
全局对象的构建和析构都是由运行库完成的,因此在程序或共享库中有全局对象时,记得不能使用"-nonstartfiles"或"-nostdlib"选项;否则,构建与虚构将不能正常执行(除非手工构造和析构全局对象)。
11.4.2 MSVC CRT的全局构造与析构
略
11.5 fread实现
Windows下,fread利用系统API: ReadFile()来实现对文件的读取的,但是从fread到ReadFile之间发生了什么?
IO是CRT最复杂的部分之一。本小节介绍fread实现,来了解这个问题。
先来看fread函数声明:
size_t fread(void *buffer, size_t elementSize, size_t count, FILE *stream);
size_t : unsigned int, 表示数据大小的类型。
fread功能是尝试从文件流stream读取count个大小为elementSize byte的数据,存储在buffer里,返回实际读取的字节数。
ReadFile函数声明:
BOOL ReadFile(HANDLE hFile, LPVOID lpBuffer, DWORD nNumberOfBytesToRead, LPDWORD lpNumberOfBytesRead, LPOVERLAPPED lpOverlapped);
hFile: 要读取的文件句柄,对应fread里面的stream参数;
lpBuffer: 读取文件内容的缓冲区,对应fread的buffer参数;
nNumberOfBytesToRead: 要读取多少个字节,与之对应的是两个参数的乘积,即elementSize * count;
lpNumberOfBytesRead: 指向DWORD类型的指针,用于返回读取了多少个字节;
lpOverlapped: 没用的参数,可以忽略;
fread和ReadFile看似完全相似,实际上却有很大区别。
11.5.1 缓冲
glibc的fread实现过于复杂,这里选择MSVC的fread实现。先介绍下缓冲(Buffer)的概念。
将用户写入数据缓存起来,放入一个数组,等待数组填满时,再一次性完成系统调用写入,这就是缓存最基本的想法。
因为频繁直接调用系统调用开销过大,库缓冲可以有效降低调用次数,从而提高系统IO效率。
通过fwrite向我局写入一段数据时,如果此时系统崩溃或进程意外退出时,可能会导致数据丢失,这是由于数据可能还在缓冲中。因此,CRT提供了一系列与缓冲相关的操作,用来弥补缓冲带来的问题。
C标准库提供与缓冲的几个基本函数:
详见之前写的这篇文章:Linux 系统编程学习笔记 - 标准输入输出之缓冲
- fflush
指定文件的缓冲,若参数为NULL,则flush所有文件的缓冲。
int fflush(FILE *stream);
- setvbuf
设置指定文件的缓冲。
int setvbuf(FILE *stream, char *buf, int mode, size_t size);
mode 指定缓冲模式:
1)_IONBF 无缓冲模式,该文件不使用任何缓冲;
2)_IOLBF 行缓冲模式,仅对文件模式打开的文件有效,所谓行,即指每收到一个换行符(\n或\r\n),就将缓冲flush掉;
3)_IOFBF 全缓冲模式,仅当缓冲满时才进行flush;
- setbuf
设置文件的缓冲,等价于(void)setvbuf(stream, buf, _IOFBF, BUFSIZ)
void setbuf(FILE *stream, char *buf);
flush缓冲,指对写缓冲而言,将缓冲内的数据全部写入实际的文件,并将缓冲清空。这样可以保证文件处于最新的状态。flush可以在一定程度上避免因程序以为退出(异常或断电等),导致缓冲里的数据没有机会写入文件的问题。
11.5.2 fread_s
MSVC的fread定义在crt/fread.c:
size_t _fread_nolock(void *buffer, size_t elementSize, size_t count, FILE *stream)
{
return fread_s(buffer, SIZE_MAX, elementSize, count, stream);
}
可以看到,fread将所有工作都转交给了fread_s。fread_s定义:
fread --> fread_s:
size_t __cdecl fread_s(void *buffer, size_t bufferSize, size_t elementSize, size_t count, FILE *stream)
{
...
_lock_str(stream);
retval = _fread_nolock_s(buffer, bufferSize, elementSize, count, stream);
_unlock_str(stream);
}
fread_s参数比fread多一个bufferSize,用于指定参数buffer大小。在fread中,该参数直接被定义为SIZE_MAX,即size_t最大值,表明fread不关心这个参数。用户使用fread_s时,可以指定该参数,防止越界(_s是safe的意思)。fread_s首先对各参数检查,然后用_lock_str对文件加锁,防止多个线程同时读取文件二导致缓冲区不一致。
11.5.3 fread_nolock_s
fread_nolock_s是实际工作的函数,下面分段列出其实现,并且省去所有参数检查和错误检查,以及64bit部分的代码。
fread -> fread_s -> fread_nolock_s:
size_t __cdecl _fread_nolock_s(void *buffer, size_t bufferSize, size_t elementSize, size_t num, FILE *stream)
{
char *data; // 指向buffer中尚未被写入的起始部分
size_t dataSize; // 记录buffer中还可以写入的字节数
size_t total; // 记录了总共要读取的字节数
size_t count; // 记录在读取过程中尚未读取的字节数
unsigned streambufsize; // 记录文件缓冲的大小
unsigned nbytes; // 当前要从缓冲区读取多少字节
unsigned nread; // 当前从缓冲区读取的字节数
int c;
data = buffer;
dataSize = bufferSize;
count = total = elementSize * num;
_fread_nolock_s的初始化部分。
文件类型FILE结构定义:
// stdio.h
struct _iobuf {
char *_ptr;
int _cnt;
char *_base;
int _flag;
int _file;
int _charbuf;
int _bufsiz;
char *_tmpfname;
};
typedef struct _iobuf FILE;
FILE结构成员含义:
_base字段指向一个字符数组,即这个文件的缓冲;_bufsiz记录这个缓冲的大小;_ptr和fread_nonlock_s的局部变量data一样,指向buffer中的第一个未读字节,而_cnt记录剩余未读字节的个数;_flag记录FILE结构所代表的打开文件的一些属性,目前感兴趣的3个标志:
#define _IOYOUBUF 0x0100 // 当前文件用户通过setbuf提供buffer
#define _IOMYBUF 0x0008 // 当前文件使用内部的缓冲
#define _IONBF 0x0004 // 当前文件使用1byte的缓冲, 该缓冲就是_charbuf变量,此时, _base无效
继续fread_nolock_s代码: ```c if (anybuf(stream)) {// 文件使用了缓冲(3种之一) streambufsize = stream->_bufsiz; } else {// 文件没有使用了缓冲 streambufsize = _INTERNAL_BUFSIZE; // _INTERNAL_BUFSIZE固定值4096 }
unsigned bufsize = streambufsize; // 自行补充, 否则下面的bufsize找不到定义
anybuf宏函数位于file2.h:
```c
#define anybuf(s) \
((s)->_flag * (_IOMYBUF | _IONBF | _IOYOUBUF))
anybuf用于检查FILE结构变量的_flag成员,有没有设置前面3个当中任意一个,如果有,则说明文件使用了缓冲。
这段代码,根据有没有使用缓冲,对streambufsize进行赋值。
接下来fread_nolock_s代码是一个循环(伪代码):
while (count != 0) {
read data
decrease count
}
这段循环意思:每次循环都从文件中读取一部分数据,并且相应地减少count(count代表还没读取的字节数)。当读取数据时,根据文件是否使用buffer及读取数据的多少,分为3种情况:
// fread_nolock_s内读取文件数据
// case 1
if (anybuf(stream) && stream->_cnt != 0)
{// 文件有缓冲,且(现有缓冲数据)不为空
nbytes = (count < stream->_cnt) ? count : stream->_cnt); // nbytes: 这次要从缓冲读取多少字节
memcpy_s(data, dataSize, stream->_ptr, nbytes); // 将streadm->_ptr指向缓冲内容复制到data指向位置, 即从流缓冲区拷贝nbytes字节数据到用户缓冲区data
/* 修正FILE结构成员和局部变量 */
count -= nbytes;
stream->_cnt -= nbytes;
stream->_ptr += nbytes;
data += nbytes;
dataSize -= nbytes;
}
case 1:anybuf判断文件是否有缓冲,stream->_cnt != 0判断当前缓冲是否为空。
memcpy_s 是memcpy安全版本(二者基本功能相同),相对于原始memcpy,memcpy_s接受一个额外的参数记录输出缓冲区的大小,防止越界。
上面代码处理了文件缓冲不为空的情况,而如果缓冲为空,那么又分为两种情况:
(1)需要读取的数据 > 缓冲的尺寸;
(2)需要读取的数据 <= 缓冲的尺寸;
对于(1),fread将试图一次读取可能多的整数个缓冲的数据,直接进入输出的数组中。如果缓冲尺寸0,则直接将剩下的数据一次性读取。
else if (count >= bufsize)
{// 剩余要读取的数据 > (文件)缓冲的尺寸
nbytes = (bufsize ? (unsigned)(count - count % bufsize) : (unsigned)count);
nread = _read(_fileno(stream), data, nbytes); // 真正从文件读取数据
if (nread == 0) {
stream->_flag | _IOEOF;
return (total - count) / size;
}
else if (nread == (unsigned)-1) {
stream->_flag |= _IOERR;
return (total - count) / size;
}
count -= nread;
data += nread;
}
对于(2),
else
{ // 剩余要读取的数据 <= (文件)缓冲的尺寸
if ((c = _filbuf(stream)) == EOF) {
return (total - count) / size;
}
*data++ = (char)c;
--count;
bufsize = stream->_bufsiz;
}
_filbuf函数负责填充缓冲,该函数具体实现重要部分之一一行:
// _filebuf()重要实现部分
stream->_cnt = _read(_fileno(stream), stream->_base, stream->_bufsiz);
可以看到所有的线索都指向了_read函数。_read函数主要负责两件事:
(1)从文件读取数据;
(2)对文本模式打开的文件,转换回车符;
11.5.4 _read
_read代码位于crt/src/read.c。省去无关紧要代码,内容如下:
fread -> fread_s -> _fread_nolock_s -> _read:
int __cdecl _read(int fh, void *buf, unsigned cnt)
{
// _read 函数的参数、局部变量和初始化部分
int bytes_read; /* number of bytes read */
char *buffer; /* buffer to read to */
int os_read; /* bytes read into buffer */
char *p, *q; /* pointers into buffer */
char peekchr; /* peek-ahead character */
ULONG filepos; /* file position after seek */
ULONG dosretval; /* o.s. return value */
bytes_read = 0; /* nothing read yet */
buffer = buf;
上面是_read 函数的参数、局部变量和初始化部分。下面是处理一个单字节缓冲(文件缓冲):
// 处理一个单字节缓冲(文件缓冲)
if ((_osfile(fh) & (FPIPE | FDBV)) && _pipech(fh) != LF)
{ // 当文件是设备和管道文件时
*buffer++ = _pipech(fh);
++bytes_read;
--cnt;
_pipech(fh) = LF;
}
_pipech: 对于设备和管道文件,ioinfo结构提供了一个单字节缓冲pipech字段用于处理一些特殊情况。
#define _pipech(i) ( _pioinfo(i)->pipech )
pipech字段的值等于LF('\n')的时候,表明该缓冲无效,这样设计原因:pipech的用途导致它永远不会被赋值为LF。
_read函数在每次读取管道设备数据的时候,必须先检查pipech,以免漏掉一个字节。接下来内容是实际的文件读取部分:
if (!ReadFile( (HANDLE)_osfhnd(fh), buffer, cnt, (LPDWORD | &os_read, NULL)))
{
// 获取Windows错误信息,并将其转化为CRT错误信息
if ((dosretval = GetLastError()) == ERROR_ACCESS_DENIED)
{
errno = EBADF;
_doserrno = dosretval;
return -1;
}
else if (dosretval == ERROR_BROKEN_PIPE)
{
return 0;
}
else
{
_dosmaperr(dosretval); // 将Windows错误信息转化为CRT错误信息
return -1;
}
}
ReadFile是Windows API,作用类似于_read,用于从文件里读取数据。ReadFile接管了_read的第一个职责。ReadFile返回后,_read要检查其返回值。值得注意的是:Windows使用的函数返回值系统和crt使用的返回值系统是不同的,如Windows使用ERROR_INVALID_PARAMETER(87)表示无效参数,而CRT用EBADF(9)表示相同的信息。因此,当ReadFile返回了错误信息之后,_read要把这个信息翻译为crt所使用的版本。_dosmaperr就是做这件工作的函数。
11.5.5 文本换行
接下来_read要以文本模式打开文件转化回车符。回车(换行的)在不同OS中,有所不同:
- Linux/Unix: 回车用\n表示
- Mac OS: 回车用\r表示
- Windows: 回车用\r\n表示
C语言中,回车始终用\n表示,因此以文本模式读取文件的时候,不同OS需要将各自回车符转换为C语言形式:
- Linux/Unix: 不做改变
- Mac OS: 每遇到\r就改为\n
- Windows: 将\r\n改为\n
// 简化版_read遇到\r\n将其转化为\n
if (_osfile(fh) & FTEXT)
{// 文件以文本模式打开
if ((os_read != 0) && (*(char *)buf == LF))// 从文件读取到LF
_osfile(fh) |= FCRLF; // 添加FCRLF标记
else
_osfile(fh) &= ~FCRLF; // 清空FCLRF标记
}
_osfile是一个宏,用于访问一个句柄对应ioinfo结构的osfile字段。当本次读文件读到的第一个字符是一个LF('\n')时,需要在该句柄的osfile字段中加入FCRLF标记,表明一个\r\n可能跨过了2次读文件。这个标记在一些特殊场合下会有作用(如ftell函数)。
接下来要进行实际的转换,需要经历一个循环:
p = q = buf;
while (p < (char *)buf + bytes_read)
{
处理p当前指向的字符
p和q后移
}
利用双指针p、q,将文本中CRLF("\r\n"),替换为LF("\n"):q是当前要写的位置,p是最新查找到的位置。
p和q一开始指向读取的数据数组的开头,每次循环做如下判断和操作:
(1)*p是CTRL-Z:表明文件已经结束,退出循环。
(2)*p是CR以为字符:把p指向的字符复制到q指向的位置。p和q各自后移1byte(*q++ = *p++)。
(3)*p是CR且(p+1)不是LF:同(2)。
(4)*p是CR且(p+1)是LF:p后移2byte,q指向的位置写LR,q后移1byte(p += 2; *q++ ='\n';)。
注意边界条件的处理。
下面是完整代码转换过程:
p = q = buf;
while (p < (char *)buf + bytes_read) {
if (*p = CTRLZ) { // EOF
if (!(_osfile(fh) & FDEV))
_osfile(fh) |= FEOFLAG;
break;
}
else if (*p != CR) /* 没有遇到CR,直接复制 */
*q++ = *p++;
else {
/* 遇到CR,检查下一个字符是否为LF(只替换连续的CRLF) */
if (p < (char *)buf + bytes_read - 1) {
/* CR不处于缓冲末尾 */
if (*(p + 1) == LF){
p += 2;
*q++ = LF;
}
else
*q++ = *p++;
}
else {
/* CR处于缓冲末尾,再读取一个字符 */
++p;
dosretval = 0;
if (!ReadFile((HANDLE)_osfhnd(fh), &peekchr, 1, (LPDWORD)&os_read, NULL))
dosretval = GetLasstError();
if (dosretval != 0 || os_read == 0) {
*q++ = CR;
}
else {
if (_osfile(fh) & (FDEV | FPIPE)) {
/* 管道或设备文件 */
if (peekchr == LF)
*q++ = LF;
else {
/* 如果预读的字符不是LF,使用pipech存储字符 */
*q++ = CR;
_pipech(fh) = peekchr;
}
}
else {
/* 普通文件 */
if (q == buf && peekchr == LF) {
*q++ = LF;
}
else {
/* 如果预读的字符不是LF,用seek回退文件指针 */
filepos = _lseek_lk(fh, -1, FILE_CURRENT);
if (peekchr != LF)
*q++ = CR;
}
}
}
}
}
bytes_read = (int)(q - (char *)buf);
}
11.5.6 fread 回顾
CRT的fread调用轨迹:
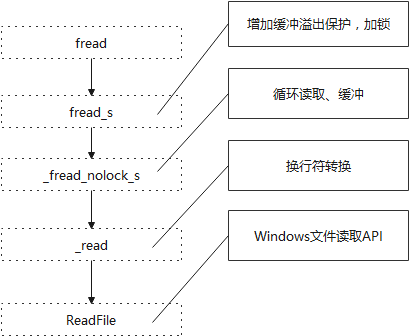
_fread_nolock_s实现最复杂,涉及缓冲区操作,是读取文件的主要部分。通过将文件数据读取到缓冲区,能减少系统调用的开销。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号