

Lecture 4: Feasibility of Learning
1.学习是不可行的吗?
No Free Lunch

Learning就是对未知的 \(f\) 进行推论
2. 概率估计的方法(假设)
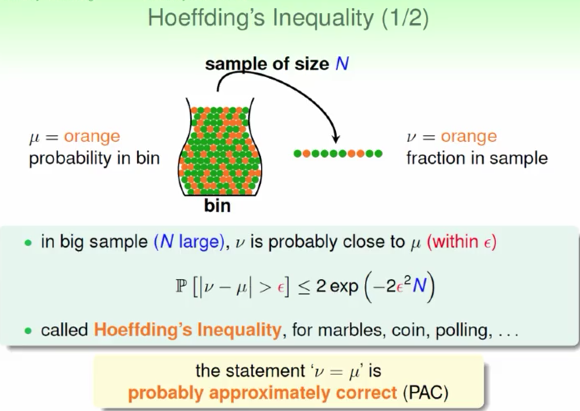
统计!!抽样估计
大数定理
霍夫丁不等式 \(N\) 越大, \(\nu\) 和 \(\mu\) 越接近
3.统计和Learning的联系(一个hypothesis)
通过抽样,估计 \(h\) 和 \(f\) 不一样的比率,类比于bin中对\(\mu\)的估计
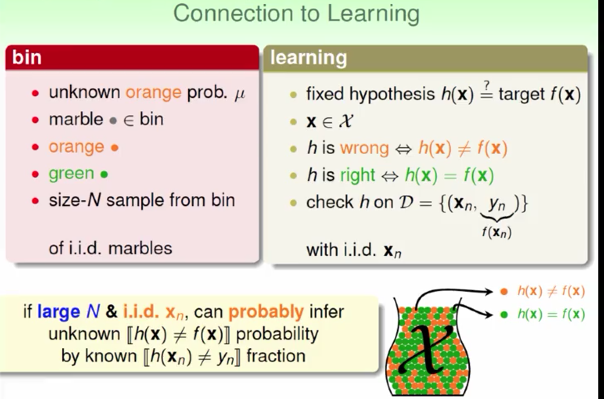
\(E_{out}\) out-of-sample error 类比于 \(\mu\)
\(E_{in}\) in-sample eroor 类比于\(\nu\)



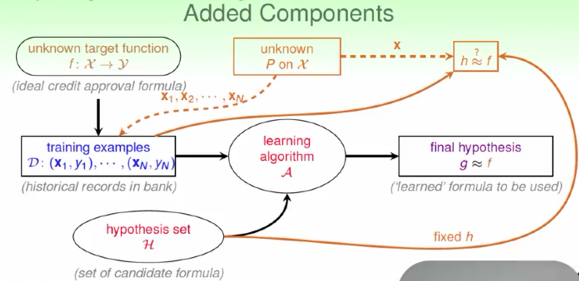
如果 \(A\)每次回传固定的 \(h\),

真正的学习是对 \(h\) 有选择的,

验证某个固定的 \(h\) 的表现好不好
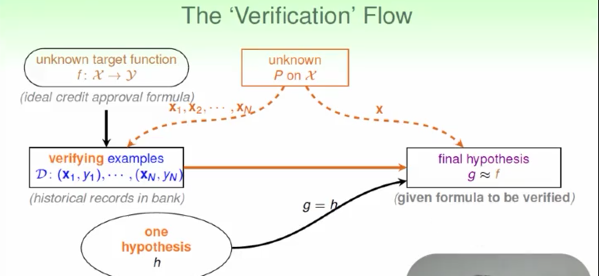

4.统计和Real Learning的联系(多个hypothesis)
用丢铜板的栗子来说明,当能够选择的 \(h\) 变多时,会恶化不好的情形。一个铜板丢5次,5次正面朝上的几率是1/32,150个铜板(150种 \(h\))丢5次,其中有一个铜板5次正面朝上的几率大于99%。
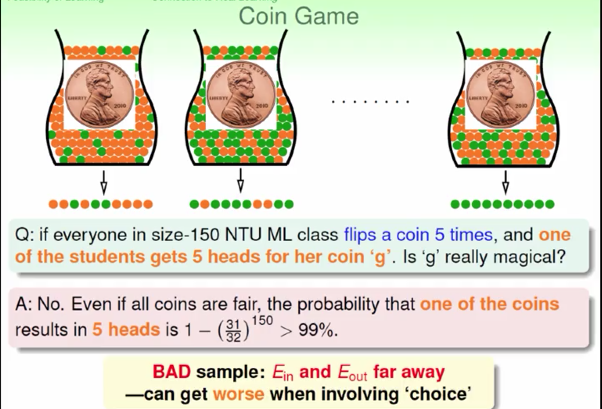
还是丢铜板的栗子,Hoffding要说明的是 BAD的Data是很少的,所以不好的几率 (\(E_{in}\) 和 \(E_{out}\) 差别很大)是很小的

如何有很多 \(h\) 呢?
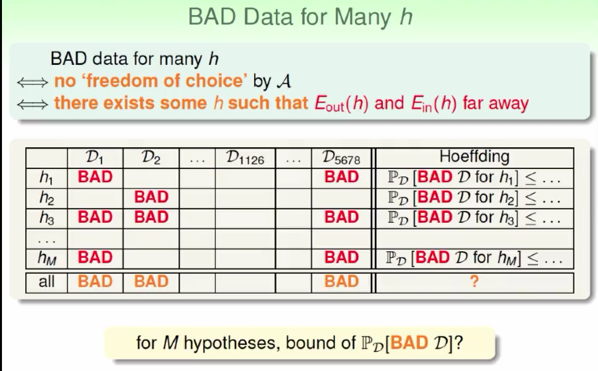
橘色的BAD表示 存在一个 \(h\) 对该组的 Data (\(D\))不好

找 \(E_{in}\) 最小的 \(h_m\) 作为 g
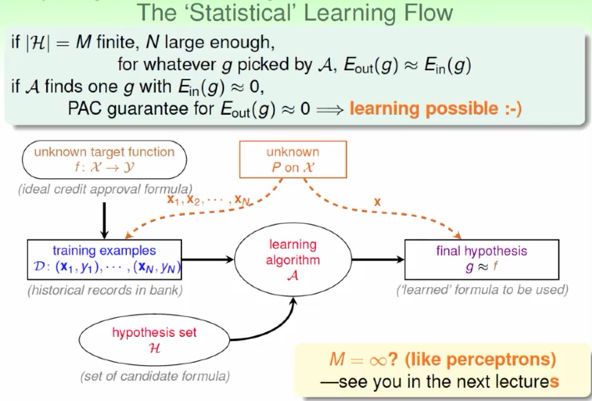
思考题


Summary


