获取云硬盘列表bug
有段时间没写博客了,主要还是刚进新公司,多少有点不适应(真会给自己找理由,明明是手里没技术,肚子里没货,能写啥!)。前面几个星期都在修一修horizon的bug,这个没啥很大难度,就是用了一个django的框架,然后再嵌套一些js框架,简明易懂。不扯远了,来点干货。。
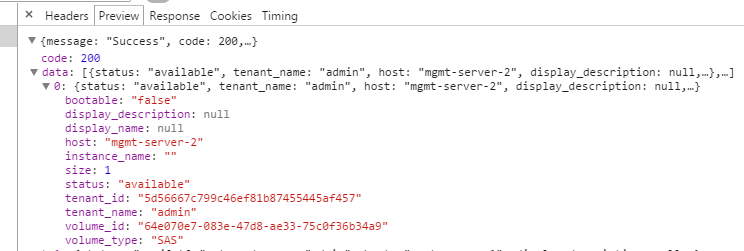

浏览器抓包可以看到,这样一个请求耗时2.4秒,再把日志打到horizon代码中,看下结果如何:
class GetVolumes(APIMeta): def handle(self): status = self.request.POST.get('status', '') tenant_id = self.request.POST.get('tenant_id', '') data = [] instances_info = {} LOG.error("step1:%s" % time.time()) # import pdb # pdb.set_trace() volumes_obj = api.cinder.volume_list(self.request, {'all_tenants': 1}) LOG.error("step2:%s" % time.time()) volumes = filters.add_tenant_info(self.request, volumes_obj, "os-vol-tenant-attr:tenant_id") LOG.error("step3:%s" % time.time()) instances = api.nova.server_list(self.request, all_tenants=True) LOG.error("step4:%s" % time.time()) for ins in instances[0]: instances_info[ins.id] = ins.name if status: volumes = filter(lambda x: status in x.status, volumes) if tenant_id: volumes = filter(lambda x: \ getattr(x, 'os-vol-tenant-attr:tenant_id') == tenant_id, volumes) LOG.error("step5:%s" % time.time()) for volume in volumes: if volume.attachments: instance_id = volume.attachments[0]['server_id'] instance_name = instances_info.get(instance_id, instance_id) else: instance_name = '' tenant = getattr(volume, 'tenant', '') data.append({'volume_id': volume.id, 'display_name': volume.display_name, 'display_description': volume.display_description, 'bootable': volume.bootable, 'size': volume.size, 'status': volume.status, 'volume_type': volume.volume_type, 'host': getattr(volume, "os-vol-host-attr:host", None), 'tenant_name': getattr(tenant, "name", None), 'tenant_id': getattr(tenant, "id", None), 'instance_name': instance_name, }) LOG.error("step6:%s" % time.time()) return sorted(data, key = lambda x: x['display_name'], reverse = False)
测试结果如下:
2015-05-07 09:44:23,153 openstack_dashboard.dashboards.admin.volumes.json_views[line:26] ERROR step1:1430963063.15 2015-05-07 09:44:24,708 openstack_dashboard.dashboards.admin.volumes.json_views[line:31] ERROR step2:1430963064.71 2015-05-07 09:44:24,802 openstack_dashboard.dashboards.admin.volumes.json_views[line:35] ERROR step3:1430963064.8 2015-05-07 09:44:26,289 openstack_dashboard.dashboards.admin.volumes.json_views[line:37] ERROR step4:1430963066.29 2015-05-07 09:44:26,289 openstack_dashboard.dashboards.admin.volumes.json_views[line:46] ERROR step5:1430963066.29 2015-05-07 09:44:26,290 openstack_dashboard.dashboards.admin.volumes.json_views[line:68] ERROR step6:1430963066.29
可以看到,主要的耗时在step1-step2 step3-step4时间,定位到相应代码段:
# step1与step2之间耗时: volumes_obj = api.cinder.volume_list(self.request,{'all_tenants': 1}) # step3与step4之间耗时: instances = api.nova.server_list(self.request, all_tenants=True)
再在cinderclient做时间戳:
def volume_list(request, search_opts=None): """ To see all volumes in the cloud as an admin you can pass in a special search option: {'all_tenants': 1} """ c_client = cinderclient(request) if c_client is None: return [] import time LOG.error("horizon_start time: %s " % time.time()) result = c_client.volumes.list(search_opts=search_opts) LOG.error("horizon_end time: %s " % time.time()) return result # return c_client.volumes.list(search_opts=search_opts)
结果如下:
2015-05-08 15:22:16,401 openstack_dashboard.api.cinder[line:95] ERROR horizon_start time: 1431069736.4 2015-05-08 15:22:19,846 openstack_dashboard.api.cinder[line:97] ERROR horizon_end time: 1431069739.85
再在cinder服务端设置时间戳:/cinder/api/v1/volumes.py
def _items(self, req, entity_maker): # import pdb # pdb.set_trace() """Returns a list of volumes, transformed through entity_maker.""" #pop out limit and offset , they are not search_opts LOG.debug(_("time1------------------------%s" % time.time())) search_opts = req.GET.copy() search_opts.pop('limit', None) search_opts.pop('offset', None) if 'metadata' in search_opts: search_opts['metadata'] = ast.literal_eval(search_opts['metadata']) context = req.environ['cinder.context'] remove_invalid_options(context, search_opts, self._get_volume_search_options()) volumes = self.volume_api.get_all(context, marker=None, limit=None, sort_key='created_at', sort_dir='desc', filters=search_opts) volumes = [dict(vol.iteritems()) for vol in volumes] LOG.debug(_("time2------------------------%s" % time.time())) for volume in volumes: self._add_visible_admin_metadata(context, volume) limited_list = common.limited(volumes, req)
LOG.debug(_("time3------------------------%s" % time.time())) req.cache_resource(limited_list) res = [entity_maker(context, vol) for vol in limited_list]
LOG.debug(_("time4------------------------%s" % time.time())) return {'volumes': res}
结果如下:
time1------------------------1431069737.57
time2------------------------1431069738.02
time3------------------------1431069738.02
time4------------------------1431069738.05
显而易见,时间都消耗在cinder服务端向cinder客户端返回数据上面了,下面分析一下返回的数据:
{'migration_status': None,
'availability_zone': u'nova',
'terminated_at': None,
'updated_at': datetime.datetime(2015, 5, 6, 8, 49, 51),
'provider_geometry': None,
'snapshot_id': None,
'ec2_id': None,
'mountpoint': None,
'deleted_at': None,
'id': u'69400200-6dea-41ec-ab7f-e3719fc9b18f',
'size': 3L,
'user_id': u'33d5edff940f4812b5368e54499991e4',
'attach_time': None,
'attached_host': None,
'display_description': u'',
'encryption_key_id': None,
'project_id': u'01f2a2e8594342d78865376cd81e2c67',
'launched_at': datetime.datetime(2015, 5, 6, 8, 49, 51),
'scheduled_at': datetime.datetime(2015, 5, 6, 8, 49, 51),
'status': u'available',
'volume_type_id': u'3a255382-1da3-4449-ad5b-5f37a4cf3d2c',
'deleted': False,
'provider_location': None,
'host': u'test1',
'source_volid': None,
'provider_auth': None,
'display_name': u'disk-102',
'instance_uuid': None,
'bootable': False,
'created_at': datetime.datetime(2015, 5, 6, 8, 49, 51),
'attach_status': u'detached',
'volume_type': <cinder.db.sqlalchemy.models.VolumeTypes object at 0x44277d0>,
'_name_id': None, 'volume_metadata': []},
上面字段基本都会用到,看来解决方案不能在精简数据上面了,或者可以在cinder客户端做一个缓存,未完待续。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号