Transformer
🥥 Table of Content
00 - Overview
01 - Input Data Preprocessing
02 - Encoder
- <1> Scaled Dot-Product Attention
- <2> Multi-Head Attention
- <3> FeedForward Layer
- <4> Encoder Layer
- <5> Encoder
03 - Decoder
04 - Transformer
🥑 Get Started!
00 - Overview
Article: Attention Is All You Need - Google Brain(2017)
Blog: The Illustrated Transformer - Jay Alammar
Use Both Encoder and Decoder: Text translation(Transformer)
Only use Encoder: Text classification(BERT), Image classification(VIT)
Only use Decoder: Text generation(GPT, LLAMA)
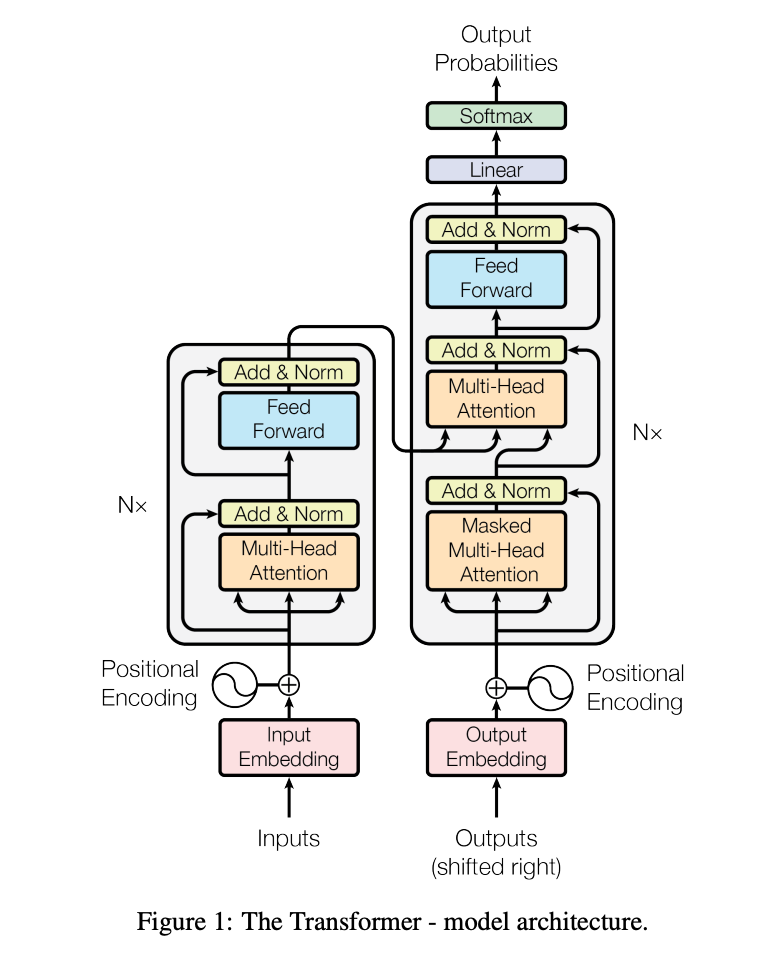
01 - Input Data Preprocessing
<1> Tokenization & Dataset & DataLoader
import math
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
# S: Symbol that shows starting of decoding input
# E: Symbol that shows starting of decoding output
# P: Symbol that will fill in blank sequence if current batch data size is short than time steps
sentences = [
# enc_input dec_input dec_output
['ich mochte ein bier P', 'S i want a beer .', 'i want a beer . E'],
['ich mochte ein cola P', 'S i want a coke .', 'i want a coke . E']
]
# Padding Should be Zero
src_vocab = {'P' : 0, 'ich' : 1, 'mochte' : 2, 'ein' : 3, 'bier' : 4, 'cola' : 5}
src_vocab_size = len(src_vocab)
tgt_vocab = {'P' : 0, 'i' : 1, 'want' : 2, 'a' : 3, 'beer' : 4, 'coke' : 5, 'S' : 6, 'E' : 7, '.' : 8}
idx2word = {i: w for i, w in enumerate(tgt_vocab)}
tgt_vocab_size = len(tgt_vocab)
src_len = 5 # enc_input max sequence length
tgt_len = 6 # dec_input(=dec_output) max sequence length
# Transformer Parameters
d_model = 512 # Embedding Size
d_ff = 2048 # FeedForward dimension
d_k = d_v = 64 # dimension of K(=Q), V
n_layers = 6 # number of Encoder of Decoder Layer
n_heads = 8 # number of heads in Multi-Head Attention
def make_data(sentences):
enc_inputs, dec_inputs, dec_outputs = [], [], []
for i in range(len(sentences)):
enc_input = [[src_vocab[n] for n in sentences[i][0].split()]] # [[1, 2, 3, 4, 0], [1, 2, 3, 5, 0]]
dec_input = [[tgt_vocab[n] for n in sentences[i][1].split()]] # [[6, 1, 2, 3, 4, 8], [6, 1, 2, 3, 5, 8]]
dec_output = [[tgt_vocab[n] for n in sentences[i][2].split()]] # [[1, 2, 3, 4, 8, 7], [1, 2, 3, 5, 8, 7]]
enc_inputs.extend(enc_input)
dec_inputs.extend(dec_input)
dec_outputs.extend(dec_output)
return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
enc_inputs, dec_inputs, dec_outputs = make_data(sentences)
class MyDataSet(Data.Dataset):
def __init__(self, enc_inputs, dec_inputs, dec_outputs):
super(MyDataSet, self).__init__()
self.enc_inputs = enc_inputs
self.dec_inputs = dec_inputs
self.dec_outputs = dec_outputs
def __len__(self):
return self.enc_inputs.shape[0]
def __getitem__(self, idx):
return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]
loader = Data.DataLoader(MyDataSet(enc_inputs, dec_inputs, dec_outputs), 2, True)
<2> Positional Encoding
.
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
'''
x: [seq_len, batch_size, d_model]
'''
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
<3> Pad Mask
def get_attn_pad_mask(seq_q, seq_k):
'''
seq_q: [batch_size, seq_len]
seq_k: [batch_size, seq_len]
seq_len could be src_len or it could be tgt_len
seq_len in seq_q and seq_len in seq_k maybe not equal
'''
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # [batch_size, 1, len_k], True is masked
return pad_attn_mask.expand(batch_size, len_q, len_k) # [batch_size, len_q, len_k]
Since masking is required in both Encoder and Decoder, there is no way to determine the value of seq_len in the argument of this function. seq_len is equal to src_len if it is called in Encoder, and it may be equal to src_len or tgt_len if it is called in Decoder (since Decoder has two masks). seq_len may be equal to src_len or tgt_len (because Decoder has two masks).
The core code of this function is seq_k.data.eq(0), which returns a tensor of the same size as seq_k, except that the only values in it are True and False. if the value at a position of seq_k is equal to 0, then the corresponding position is True, otherwise it is False. for example, the input seq_k.data = [1, 2, 3, 3, 3], and seq_k.data = [1, 2, 2, 3]. data = [1, 2, 3, 4, 0], seq_data.data.eq(0) would return [False, False, False, False, False, True].
The rest of the code focuses on expanding the dimensions.
<4> Subsequence Mask
def get_attn_subsequence_mask(seq):
'''
seq: [batch_size, tgt_len]
'''
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequence_mask = np.triu(np.ones(attn_shape), k=1) # Upper triangular matrix
subsequence_mask = torch.from_numpy(subsequence_mask).byte()
return subsequence_mask # [batch_size, tgt_len, tgt_len]
Subsequence Mask is only used by Decoder, it is mainly used to block the information of words in future moments. First, np.ones() generates a square matrix with all 1's, and then np.triu() generates an upper triangular matrix, the following is how np.triu() is used.
# For k=0, it expresses the upper triangle matrix
# upper-triangle = np.triu(data, 0)
[[1, 2, 3, 4, 5],
[0, 5, 6, 7, 8],
[0, 0, 8, 9, 0],
[0, 0, 0, 7, 8],
[0, 0, 0, 0, 5]]
# For k=-1, it expresses the matrix that includes one below the main diagonal
# upper-triangle = np.triu(data, -1)
[[1, 2, 3, 4, 5],
[4, 5, 6, 7, 8],
[0, 7, 8, 9, 0],
[0, 0, 6, 7, 8],
[0, 0, 0, 4, 5]]
# For k=1, it expresses the matrix that includes one above the main diagonal
# upper-triangle = np.triu(data, 1)
[[0, 2, 3, 4, 5],
[0, 0, 6, 7, 8],
[0, 0, 0, 9, 0],
[0, 0, 0, 0, 8],
[0, 0, 0, 0, 0]]
02 - Encoder
<1> Scaled Dot-Product Attention
If you wanna know more details, click here.

class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
'''
Q: [batch_size, n_heads, len_q, d_k]
K: [batch_size, n_heads, len_k, d_k]
V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask: [batch_size, n_heads, seq_len, seq_len]
'''
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size, n_heads, len_q, len_k]
scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is True.
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V) # [batch_size, n_heads, len_q, d_v]
return context, attn
What we do here is to compute scores from Q and K, and then multiply scores and V to get a context vector for each word.
The first step is to multiply the transpose of Q and K. The scores obtained after multiplication cannot immediately perform softmax, and it needs to be added with attn_mask to shield some information that needs to be masked. attn_mask is a tensor consisting of only True and False, and it must ensure that attn_mask and scores have the same four values of dimension (otherwise it cannot add the corresponding positions).
After the mask is finished, you can softmax scores. And then multiply that by V, and you get context vector
<2> Multi-Head Attention
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
def forward(self, input_Q, input_K, input_V, attn_mask):
'''
input_Q: [batch_size, len_q, d_model]
input_K: [batch_size, len_k, d_model]
input_V: [batch_size, len_v(=len_k), d_model]
attn_mask: [batch_size, seq_len, seq_len]
'''
residual, batch_size = input_Q, input_Q.size(0)
# (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W)
Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # Q: [batch_size, n_heads, len_q, d_k]
K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # K: [batch_size, n_heads, len_k, d_k]
V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size, n_heads, seq_len, seq_len]
# context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k]
context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)
context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_v) # context: [batch_size, len_q, n_heads * d_v]
output = self.fc(context) # [batch_size, len_q, d_model]
return nn.LayerNorm(d_model).cuda()(output + residual), attn
There must be three places in the complete code where MultiHeadAttention() is called. Encoder Layer is called once, and the input_Q, input_K, input_V are all enc_inputs; Decoder Layer is called twice, and the first time, all the inputs are dec_inputs, and the second time, the inputs are dec_outputs, enc_outputs, enc_outputs respectively.
<3> FeedForward Layer
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=False)
)
def forward(self, inputs):
'''
inputs: [batch_size, seq_len, d_model]
'''
residual = inputs
output = self.fc(inputs)
return nn.LayerNorm(d_model).cuda()(output + residual) # [batch_size, seq_len, d_model]
This code is very simple, it is to do two linear transformations, the residuals are connected and then followed by a Layer Norm
<4> Encoder Layer
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, enc_inputs, enc_self_attn_mask):
'''
enc_inputs: [batch_size, src_len, d_model]
enc_self_attn_mask: [batch_size, src_len, src_len]
'''
# enc_outputs: [batch_size, src_len, d_model], attn: [batch_size, n_heads, src_len, src_len]
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # enc_inputs to same Q,K,V
enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size, src_len, d_model]
return enc_outputs, attn
Putting the above components together makes a complete Encoder Layer.
<5> Encoder
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model)
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
def forward(self, enc_inputs):
'''
enc_inputs: [batch_size, src_len]
'''
enc_outputs = self.src_emb(enc_inputs) # [batch_size, src_len, d_model]
enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, src_len, d_model]
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # [batch_size, src_len, src_len]
enc_self_attns = []
for layer in self.layers:
# enc_outputs: [batch_size, src_len, d_model], enc_self_attn: [batch_size, n_heads, src_len, src_len]
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns
With nn.ModuleList(), the argument is a list of n_layers of Encoder Layers.
Since we control the dimensions of the inputs and outputs of the Encoder Layers to be the same, we can just use a for loop to nest the outputs of the previous Encoder Layer as the inputs of the next Encoder Layer.
03 - Decoder
<1> Decoder Layer
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
'''
dec_inputs: [batch_size, tgt_len, d_model]
enc_outputs: [batch_size, src_len, d_model]
dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
dec_enc_attn_mask: [batch_size, tgt_len, src_len]
'''
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
# dec_outputs: [batch_size, tgt_len, d_model], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model]
return dec_outputs, dec_self_attn, dec_enc_attn
MultiHeadAttention is called twice in Decoder Layer, the first time is to compute the self-attention of Decoder Input and get the output dec_outputs, then dec_outputs is used as the element to generate Q, and enc_outputs is used as the element to generate K and V. Finally, dec_outptus is dimensionally transformed and returned as the context vector between Encoder and Decoder Layer. Then we call MultiHeadAttention again to get the context vector between Encoder and Decoder Layer, and finally we do a dimensional transformation on dec_outputs and return
<2> Decoder
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs):
'''
dec_inputs: [batch_size, tgt_len]
enc_intpus: [batch_size, src_len]
enc_outputs: [batch_size, src_len, d_model]
'''
dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]
dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1).cuda() # [batch_size, tgt_len, d_model]
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs).cuda() # [batch_size, tgt_len, tgt_len]
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs).cuda() # [batch_size, tgt_len, tgt_len]
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask), 0).cuda() # [batch_size, tgt_len, tgt_len]
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # [batc_size, tgt_len, src_len]
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attns
The Decoder not only masks out the "pad", but also masks information about future moments, hence the following three lines of code, where torch.gt(a, value) means to compare the element at each position in a with value, if it is greater than value, then the position takes 1, otherwise it takes 0
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) # [batch_size, tgt_len, tgt_len]
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs) # [batch_size, tgt_len, tgt_len]
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask), 0) # [batch_size, tgt_len, tgt_len]
04 - Transformer
<1> Transformer
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder().cuda()
self.decoder = Decoder().cuda()
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False).cuda()
def forward(self, enc_inputs, dec_inputs):
'''
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
'''
# tensor to store decoder outputs
# outputs = torch.zeros(batch_size, tgt_len, tgt_vocab_size).to(self.device)
# enc_outputs: [batch_size, src_len, d_model], enc_self_attns: [n_layers, batch_size, n_heads, src_len, src_len]
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
# dec_outpus: [batch_size, tgt_len, d_model], dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [n_layers, batch_size, tgt_len, src_len]
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
dec_logits = self.projection(dec_outputs) # dec_logits: [batch_size, tgt_len, tgt_vocab_size]
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
Transformer mainly calls Encoder and Decoder, and finally returns the dimension of dec_logits as [batch_size * tgt_len, tgt_vocab_size], which can be interpreted as a sentence with batch_size * tgt_len words, and each of them has tgt_vocab_size, take the one with the largest probability
<2> Models & Loss Functions & Optimizers
model = Transformer().cuda()
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.99)
Here in the loss function I set a parameter ignore_index=0, because the index of the word "pad" is 0, after this setting, the loss of "pad" will not be calculated (because originally "pad" is meaningless and does not need to be calculated).
<3> Training
for epoch in range(30):
for enc_inputs, dec_inputs, dec_outputs in loader:
'''
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
dec_outputs: [batch_size, tgt_len]
'''
enc_inputs, dec_inputs, dec_outputs = enc_inputs.cuda(), dec_inputs.cuda(), dec_outputs.cuda()
# outputs: [batch_size * tgt_len, tgt_vocab_size]
outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
loss = criterion(outputs, dec_outputs.view(-1))
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
<4> Testing
def greedy_decoder(model, enc_input, start_symbol):
"""
For simplicity, a Greedy Decoder is Beam search when K=1. This is necessary for inference as we don't know the
target sequence input. Therefore we try to generate the target input word by word, then feed it into the transformer.
Starting Reference: http://nlp.seas.harvard.edu/2018/04/03/attention.html#greedy-decoding
:param model: Transformer Model
:param enc_input: The encoder input
:param start_symbol: The start symbol. In this example it is 'S' which corresponds to index 4
:return: The target input
"""
enc_outputs, enc_self_attns = model.encoder(enc_input)
dec_input = torch.zeros(1, 0).type_as(enc_input.data)
terminal = False
next_symbol = start_symbol
while not terminal:
dec_input = torch.cat([dec_input.detach(),torch.tensor([[next_symbol]],dtype=enc_input.dtype).cuda()],-1)
dec_outputs, _, _ = model.decoder(dec_input, enc_input, enc_outputs)
projected = model.projection(dec_outputs)
prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1]
next_word = prob.data[-1]
next_symbol = next_word
if next_symbol == tgt_vocab["."]:
terminal = True
print(next_word)
return dec_input
# Test
enc_inputs, _, _ = next(iter(loader))
enc_inputs = enc_inputs.cuda()
for i in range(len(enc_inputs)):
greedy_dec_input = greedy_decoder(model, enc_inputs[i].view(1, -1), start_symbol=tgt_vocab["S"])
predict, _, _, _ = model(enc_inputs[i].view(1, -1), greedy_dec_input)
predict = predict.data.max(1, keepdim=True)[1]
print(enc_inputs[i], '->', [idx2word[n.item()] for n in predict.squeeze()])


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek “源神”启动!「GitHub 热点速览」
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· 我与微信审核的“相爱相杀”看个人小程序副业
· C# 集成 DeepSeek 模型实现 AI 私有化(本地部署与 API 调用教程)
· spring官宣接入deepseek,真的太香了~