redis之zset解析
zset是Redis提供的一个非常特别的数据结构,常用作排行榜等功能,以用户id为value,关注时间或者分数作为score进行排序。
常用命令:
# 向有序集合添加一个或多个成员,或者更新已存在成员的分数
ZADD key score1 member1 [score2 member2]
# 计算在有序集合中指定区间分数的成员数
ZCOUNT key min max
# 有序集合中对指定成员的分数加上增量 increment
ZINCRBY key increment member
#返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序
ZREVRANK key member
#返回有序集合中指定成员的索引
ZRANK key member
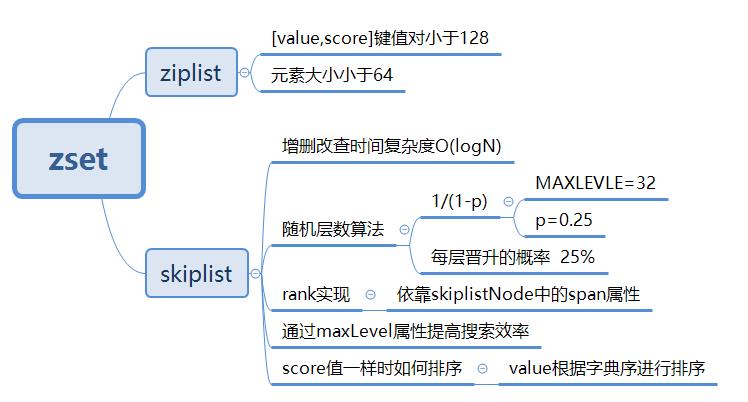
与其他数据结构相似,zset也有两种不同的实现,分别是zipList和skipList。zipList前面我们已经介绍过了,这里就不再介绍了。具体使用哪种结构进行存储,规则如下:
zipList:满足以下两个条件[score,value]键值对数量少于128个;- 每个元素的长度小于64字节;
skipList:不满足以上两个条件时使用跳表、组合了hash和skipListhash用来存储value到score的映射,这样就可以在O(1)时间内找到value对应的分数;skipList按照从小到大的顺序存储分数skipList每个元素的值都是[socre,value]对
使用zipList的示意图如下所示:

使用跳表时的示意图:
1|0 跳表 skipList
跳表skipList在Redis中的运用场景只有一个,那就是作为有序列表zset的底层实现。跳表可以保证增、删、查等操作时的时间复杂度为O(logN),这个性能可以与平衡树相媲美,但实现方式上却更加简单,唯一美中不足的就是跳表占用的空间比较大,其实就是一种空间换时间的思想。跳表的结构如下所示:

Redis中跳表一个节点最高可以达到64层,一个跳表中最多可以存储2^64个元素。跳表中,每个节点都是一个skiplistNode,
每个跳表的节点也都会维护着一个score值,这个值在跳表中是按照从小到大的顺序排列好的。
跳表的结构定义如下所示:
typedf struct zskiplist{
//头节点
struct zskiplistNode *header;
//尾节点
struct zskiplistNode *tail;
// 跳表中元素个数
unsigned long length;
//目前表内节点的最大层数 int level;
}zskiplist; header:指向跳表的头节点,通过这个指针可以直接找到表头,时间复杂度为O(1);
tail:指向跳表的尾节点,通过这个指针可以直接找到表尾,时间复杂度为o(1);
length:记录跳表的长度,即不包括头节点,整个跳表中有多少个元素;
level:记录当前跳表内,所有节点中层数最大的level;
zskiplist的示意图如下所示:

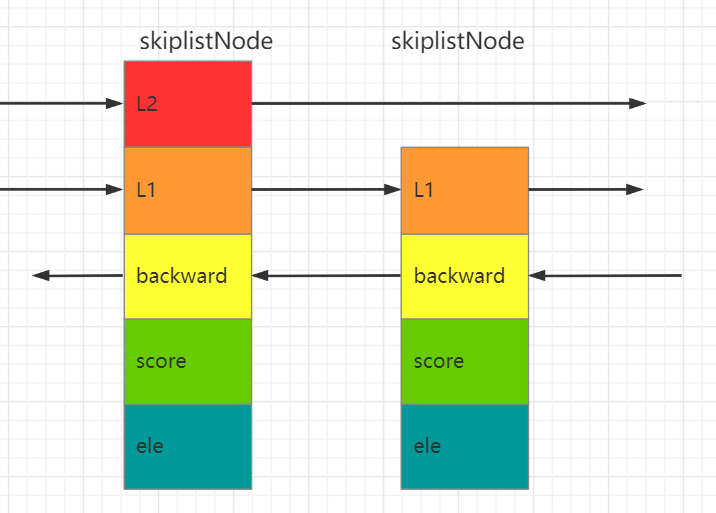
zskiplistNode的结构定义如下:
typedf struct zskiplistNode{
sds ele;
// 具体的数据
double score;
// 分数
struct zskiplistNode *backward;
//后退指针
struct zskiplistLevel{
struct zskiplistNode *forward;
//前进指针forward
unsigned int span;
//跨度
span
}level[];
//层级数组 最大32
}zskiplistNode; ele:真正的数据,每个节点的数据都是唯一的,但节点的分数score可以是一样的。两个相同分数score的节点是按照元素的字典序进行排列的;
score:各个节点中的数字是节点所保存的分数score,在跳表中,节点按照各自所保存的分数从小到大排列;
backward:用于从表尾向表头遍历,每个节点只有一个后退指针,即每次只能后退一步;
层级数组:这个数组中的每个节点都有两个属性,forward指向下一个节点,span跨度用来计算当前节点在跳表中的一个排名,这就为zset提供了一个查看排名的方法。数组中的每个节点中用1、2、3等字样标记节点的各个层,L1代表第一层,L2代表第二层,L3代表第三层;,以此类推;
skiplistNode的示意图如下所示:
2|0 增删改查
以下图为例,讲解一下skiplist的增删改查过程。

2|1 查
假设现在要查找7这个节点,步骤如下:
- 从
head开始遍历,指针指向4这个节点,由于4<7,且同层的下一个指针指向NULL,所以下级一层; - 跳到6节点所在的层,同理,6<7,且同层的下一个指针指向
NULL,再下降一层; - 此时到了第一层,第一层是一个双向链表,由于6<7,所以开始向后遍历,查找到7就返回,不然就返回
NULL;
2|2 删
删除的过程前期与查找相似,先定位到元素所在的位置,再进行删除,最后更新一下指针、更新一下最高的层数。
2|3 改
先是判断这个 value 是否存在,如果存在就是更新的过程,如果不存在就是插入过程。在更新的过程是,如果找到了Value,先删除掉,再新增,这样的弊端是会做两次的搜索,在性能上来讲就比较慢了,在 Redis 5.0 版本中,Redis 的作者 Antirez 优化了这个更新的过程,目前的更新过程是如果判断这个 value是否存在,如果存在的话就直接更新,然后再调整整个跳跃表的 score 排序,这样就不需要两次的搜索过程。
2|4 增
比如要插入的值为 6
- 从 head 节点开始,先是在 head 开始降层来查找到最后一个比 6 小的节点;
- 等到查到最后一个比 6 小的节点的时候(假设为 5 );
- 然后需要引入一个随机层数算法来为这个节点随机地建立层数;
- 把这个节点插入进去以后,同时更新一遍最高的层数即可;
2|5 随机层数算法
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF)) level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
} #define ZSKIPLIST_MAXLEVEL 32
#define ZSKIPLIST_P 0.25 3|0 总结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号