
[机器学习实战] 基于概率论的分类方法:朴素贝叶斯
1. 原理:
假设用p1(x,y)表示数据点(x,y)属于类别1的概率,用p2(x,y)表示数据点(x,y)属于类别2的概率,那么对于一个新的数据点(x,y),
可以用下面的规则来判断它的类别:
1)如果p1(x,y) > p2(x,y),那么类别为1;
2)如果p1(x,y) < p2(x,y),那么类别为2;
即选择高概率对应的类别作为新数据的类别。
这里利用贝叶斯准则计算条件概率来对数据进行分类,计算方法为:
p(c|x) =p(x|c)p(c)/p(x)
2. 基本特点:
1)优点:在数据较少的情况下仍然有效,可以处理多类别问题;
2)缺点:对于输入数据的准备方式敏感;
3)适用数据类型:标称型数据,各个属性之间相互独立(关联越大,误差可能越大);
3. 一般流程:
1)收集数据:可以使用任何方法。比如RSS源;
2)准备数据:需要数值型或者布尔型数据;
将每个词的出现与否作为一个特征,这个描述为词集模型;
一个词在文档中出现不止一次,即词的出现不能表达这种信息了,这个描述为词袋模型;
词袋模型与词集模型相比,无非就是增加相应向量位置的值。
3)分析数据:有大量特征时,绘制特征作用不大,此时使用直方图效果更好;
4)训练算法:计算不同的独立特征的条件概率;
对于文本分类例子,每个文本要么是侮辱性文字,要么代表正常言论,据此判断新文本属于哪种:


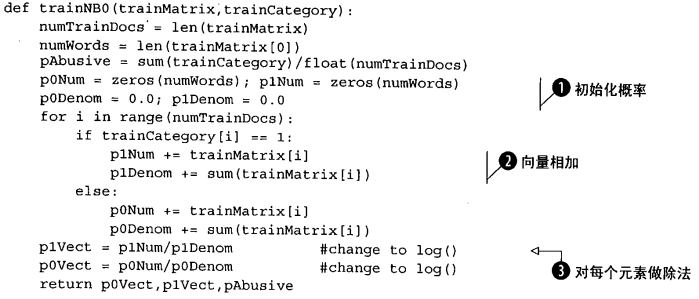

5)测试算法:计算错误率;
为了防止因数太小引起的下溢,可以调整初始值;
利用ln(a*b) = ln(a) + ln(b)的性质,可以避免下溢出或者浮点数舍入导致的错误;
6)使用算法:不一定非要是文件,常见应用为文本分类,如垃圾邮件判断。


