

《CUDA C 编程指南》学习笔记
CUDA是什么?
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。是一种通用并行计算架构,该架构使GPU能够解决复杂的计算问题。说白了就是我们可以使用GPU来并行完成像神经网络、图像处理算法这些在CPU上跑起来比较吃力的程序。通过GPU和高并行,我们可以大大提高这些算法的运行速度。有的同学可能知道,在CPU和GPU上跑同一个神经网络,由于其大量的浮点数权重计算以及可高并行化,其速度的差距往往在10倍左右,原本需要睡一觉才能看到的训练结果也许看两集动漫就OK了。
GPU并行在图像处理方面更是应用广泛,大家知道图像处理实际上是对图像的二维矩阵进行处理,图像的尺寸都是几百乘几百的,很容易就是上万个像素的操作,随便搞个什么平滑算法,匹配算法等等的图像算法在CPU上跑个几十秒都是很正常的,对于图像处理,神经网络这种大矩阵计算,往往是可以并行化的,通过GPU并行化处理往往能够成倍的加速。
综上所述,去学习一下怎么在GPU上开个几千个线程过把优化瘾还是一件很惬意的事情,更何况CUDA为我们提供了这么优秀的计算平台,可以直接使用C/C++写出在显示芯片上执行的程序,还是一件很赞的事情。
不过CUDA编程需要注意的点是很多的,有很多因素如果忽略了会大大降低速度,写的不好的CUDA程序可能会比CPU程序还慢。所以优化和并行是一门很大的学问,需要我们去不断学习与了解。
关于本文
学习资料主要来源:
1. https://blog.csdn.net/luoganttcc/article/details/123474189 这里整理了各种cuda资料
2.《CUDA C 编程指南》
3. 人工智能编程 | 谭升的博客 (face2ai.com) 前人的学习总结
GPU编程
内存管理
只读缓存
只读缓存最初是留给纹理内存加载用的,在3.5以上的设备,只读缓存也支持使用全局内存加载代替一级缓存。也就是说3.5以后的设备,可以通过只读缓存从全局内存中读数据了。
只读缓存粒度32字节,对于分散读取,细粒度优于一级缓存
有两种方法指导内存从只读缓存读取:
- 使用函数 _ldg
- 在间接引用的指针上使用修饰符

//实现方式
__global__ void copyKernel(float * in,float* out) { int idx=blockDim*blockIdx.x+threadIdx.x; out[idx]=__ldg(&in[idx]); }
//或者
void kernel(float* output, const float* __restrict__ input) {
...
output[idx] += input[idx];
}
全局内存
//AOS struct A a[N]; //SOA struct A{ int a[N]; int b[N] }a;
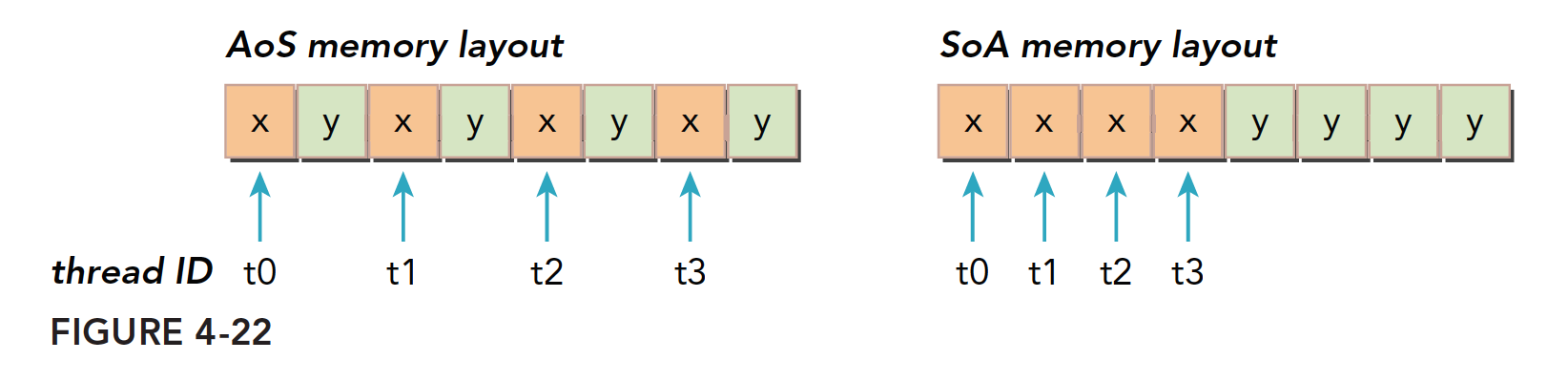
并行编程范式,尤其是SIMD(单指令多数据)对SoA更友好。CUDA中普遍倾向于SoA因为这种内存访问可以有效地合并。
实现并发内存访问量最大化是通过以下方式得到的:
- 增加每个线程中执行独立内存操作的数量 ---->展开技术
- 对核函数启动的执行配置进行试验,已充分体现每个SM的并行性 --->增大并行性(通过调整块的大小实现)
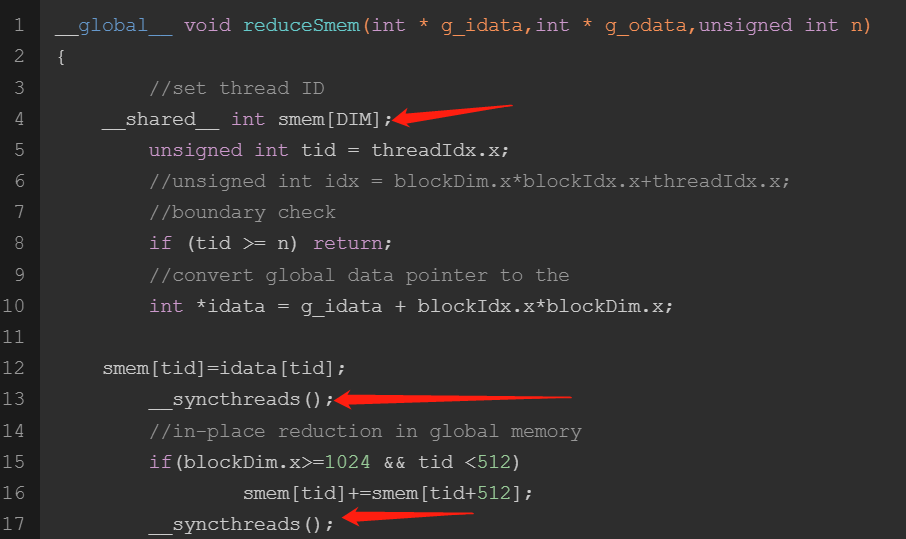
共享内存
共享内存的展开能更高的提高效率,注意线程块内的同步。
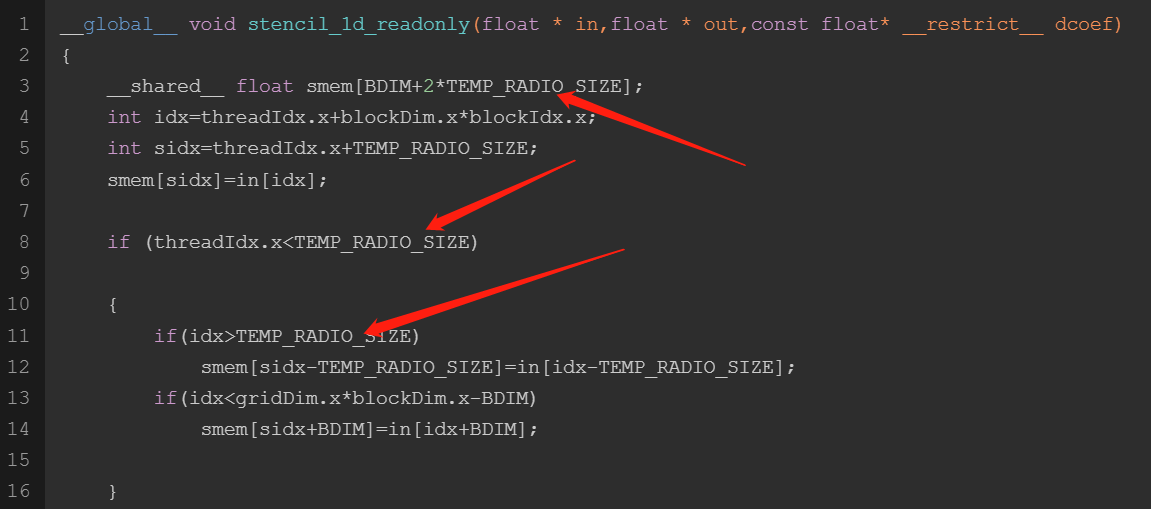
常量内存
常量内存是专用内存,他用于只读数据和线程束统一访问某一个数据,常量内存对内核代码而言是只读的,但是主机是可以修改(写)只读内存的,当然也可以读。
注意,常量内存并不是在片上的,而是在DRAM上,而其有在片上对应的缓存,其片上缓存就和一级缓存和共享内存一样, 有较低的延迟,但是容量比较小,合理使用可以提高内和效率,每个SM常量缓存大小限制为64KB。
我们可以发现,所有的片上内存,我们是不能通过主机赋值的,我们只能对DRAM上内存进行赋值。
常量内存和只读缓存区别:
- 对于核函数都是只读的
- SM上的资源有限,常量缓存64KB,只读缓存48KB
- 常量缓存对于统一读取(读同一个地址)执行更好
- 只读缓存适合分散读取
- 常量缓存喜欢小数据,而只读缓存加载的数据比较大
线程管理
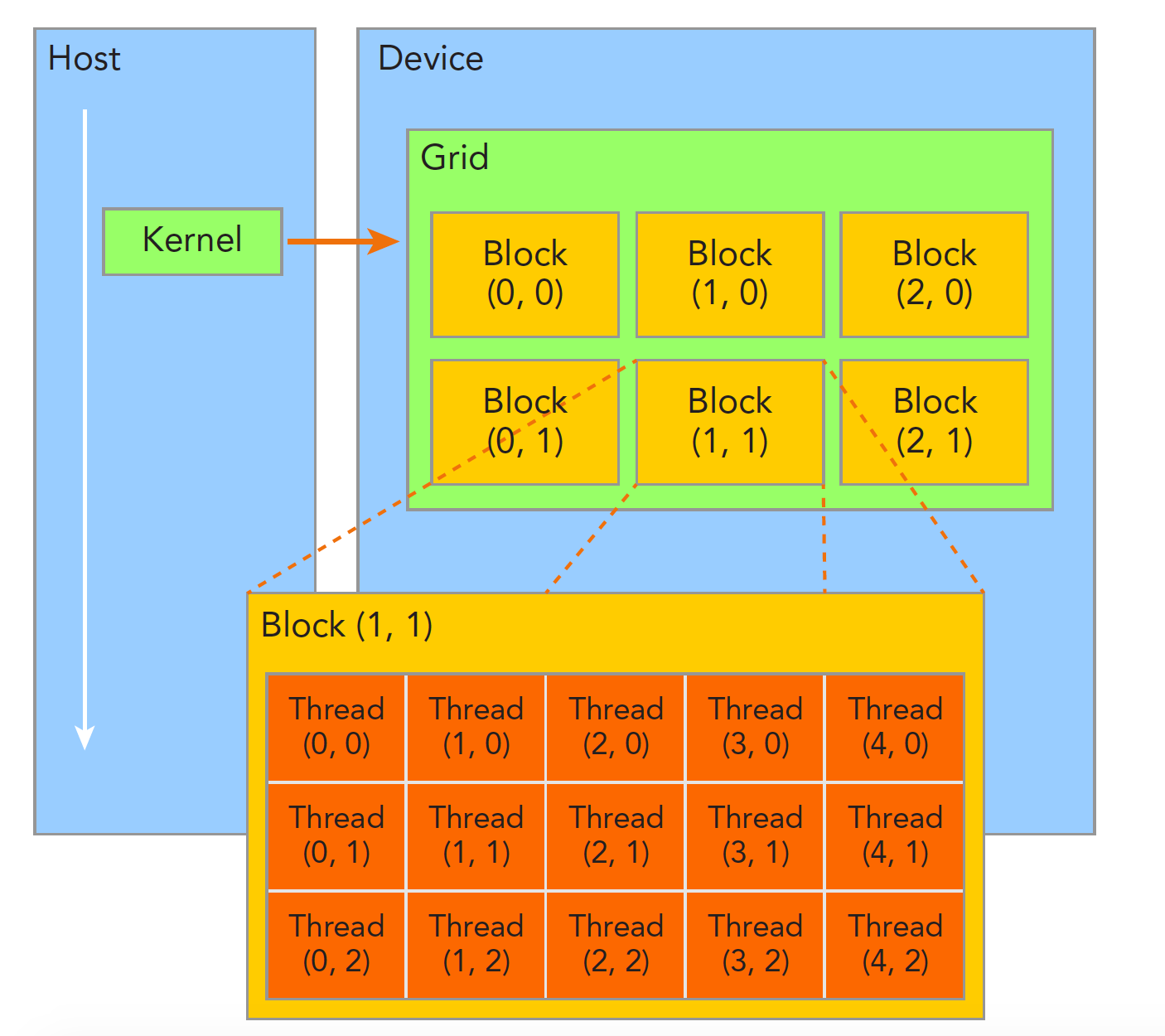
Example:
// __global__ void kernel_name<<<grid,block>>>(argument list);
kernel_name<<<4,8>>>(argument list);


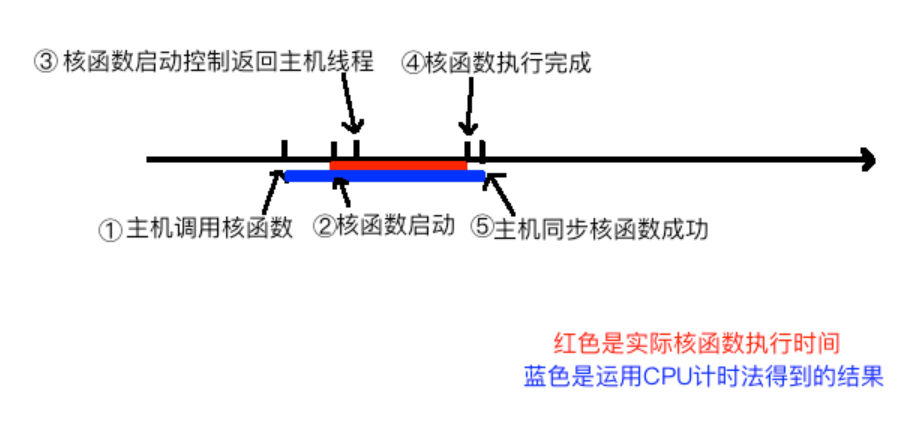
其中核函数计时逻辑:
线程组织
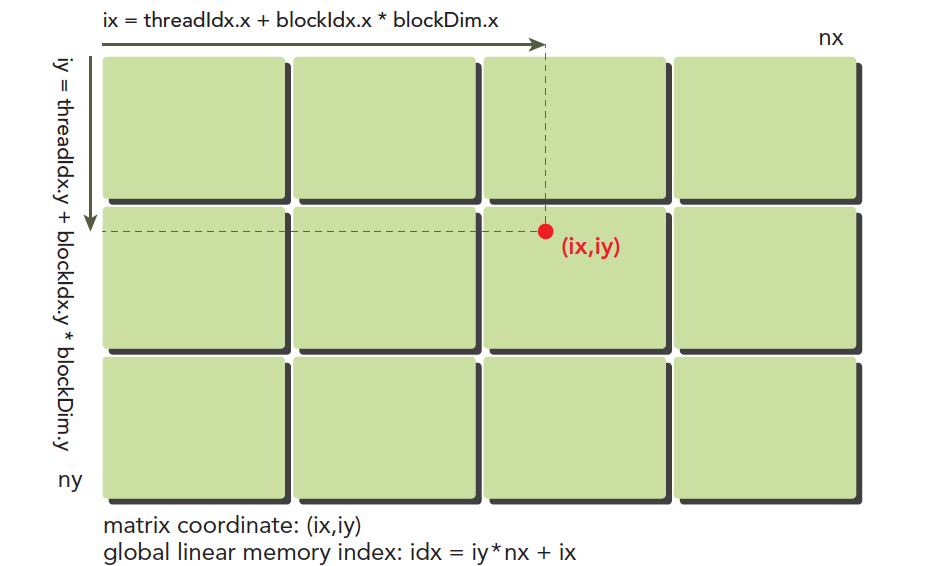
横坐标: ix=threadIdx.x+blockIdx.x×blockDim.x 纵坐标: iy=threadIdx.y+blockIdx.y×blockDim.y
设备内存或者主机内存都是线性存在的,比如一个二维矩阵(8×6),存储在内存中是这样的:

线性位置:
idx=ix+iy∗nx
线程束洗牌
洗牌指令,shuffle instruction作用在线程束内,允许两个线程见相互访问对方的寄存器。这就给线程束内的线程相互交换信息提供了了一种新的渠道,我们知道,核函数内部的变量都在寄存器中,一个线程束可以看做是32个内核并行执行,换句话说这32个核函数中寄存器变量在硬件上其实都是邻居,这样就为相互访问提供了物理基础,线程束内线程相互访问数据不通过共享内存或者全局内存,使得通信效率高很多,线程束洗牌指令传递数据,延迟极低,切不消耗内存
线程束洗牌指令是线程束内线程通讯的极佳方式。
我们先提出一个叫做束内线程的概念,英文名lane,简单的说,就是一个线程束内的索引,所以束内线程的ID在【0,31】 内,且唯一,唯一是指线程束内唯一,一个线程块可能有很多个束内线程的索引,就像一个网格中有很多相同的threadIdx.x 一样,同时还有一个线程束的ID,可以通过以下方式计算线程在当前线程块内的束内索引,和线程束ID:
unsigned int LaneID=threadIdx.x%32; unsigned int warpID=threadIdx.x/32;
根据上面的计算公式,一个线程块内的threadIdx.x=1,33,65等对应的laneID都是1
//在线程束内交换整形变量,其基本函数如下: int __shfl(int var,int srcLane,int width=warpSize); //从与调用线程相关的线程中复制数据 int __shfl_up(int var,unsigned int delta,int with=warpSize); int __shfl_down(int var,unsigned int delta,int with=warpSize); //跨线程束的蝴蝶交换 int __shfl_xor(int var,int laneMask,int with=warpSize);
线程束洗牌指令完成归约,可减少线程间数据传递的延迟。
常用API
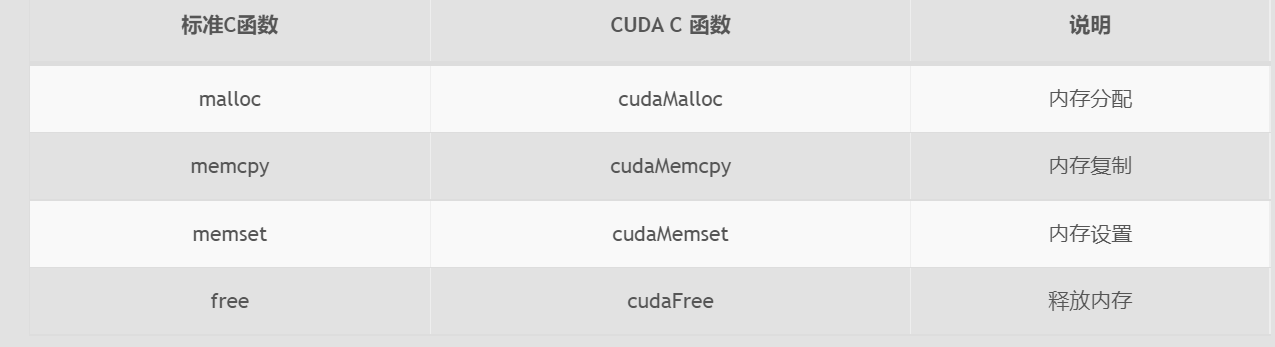
//设备信息相关API cudaSetDevice cudaGetDeviceProperties cudaDriverGetVersion cudaRuntimeGetVersion cudaGetDeviceCount //内存操作 cudaError_t cudaMalloc(void ** devPtr,size_t count) cudaError_t cudaMemset(void * devPtr,int value,size_t count) cudaError_t cudaFree(void * devPtr) cudaError_t cudaMemcpy(void *dst,const void * src,size_t count,enum cudaMemcpyKind kind) //分配count字节的固定内存,这些内存是页面锁定的,可以直接传输到设备的 //固定内存的释放和分配成本比可分页内存要高很多,但是传输速度更快,所以对于大规模数据,固定内存效率更高。 //尽量使用流来使内存传输和计算之间同时进行 cudaError_t cudaMallocHost(void ** devPtr,size_t count) cudaError_t cudaFreeHost(void *ptr) //申请常量内存 cudaError_t cudaMemcpyToSymbol(const void *symbol, const void * src, size_t count, size_t offset, cudaMemcpyKind kind)
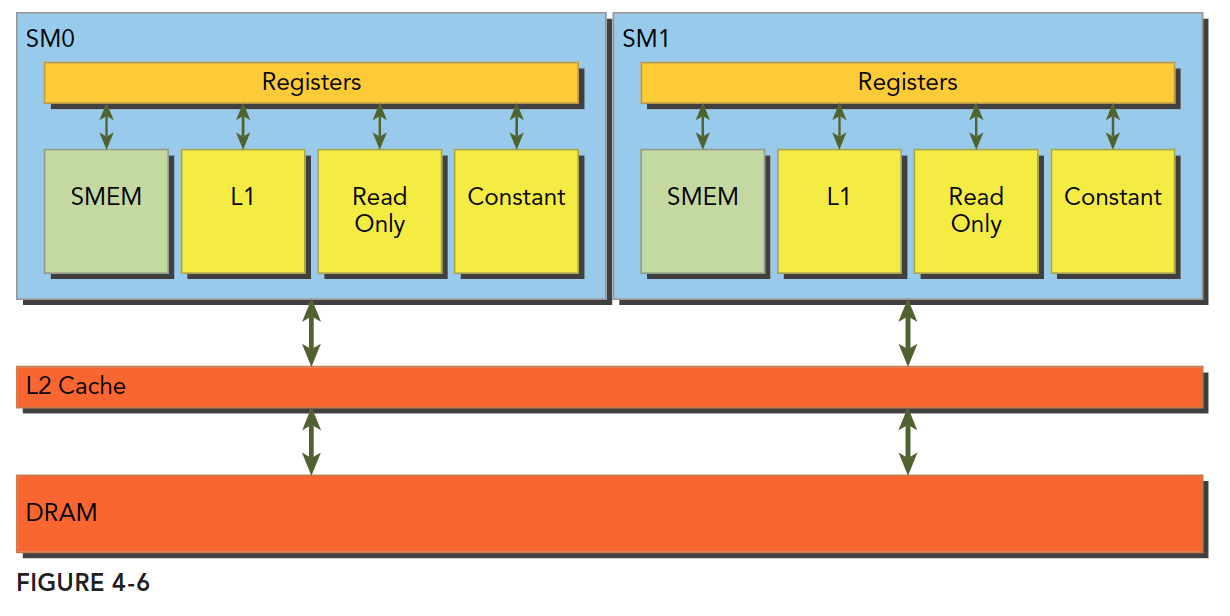
GPU架构
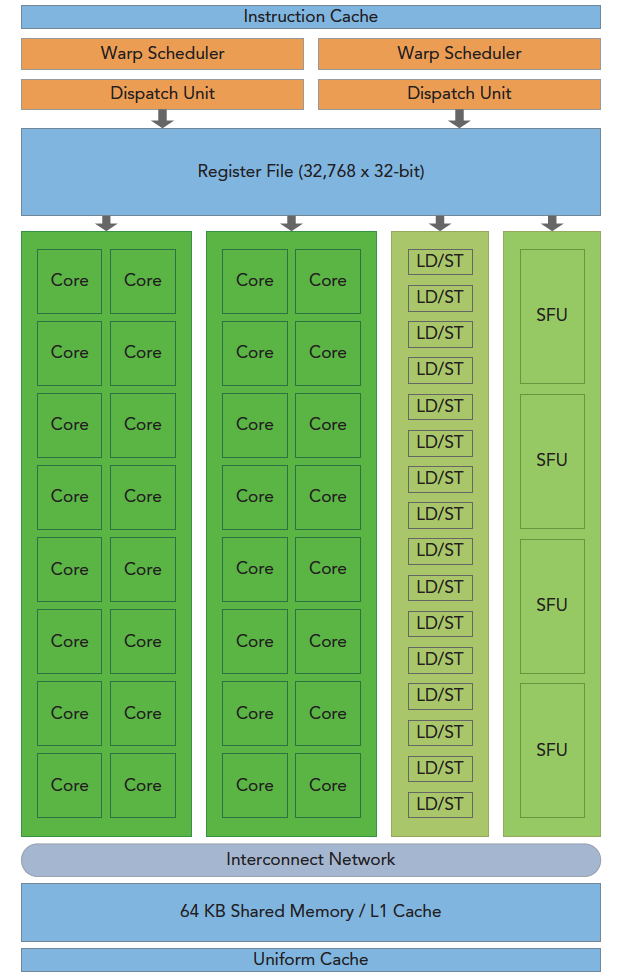
上图包括关键组件:
- CUDA核心
- 共享内存/一级缓存
- 寄存器文件
- 加载/存储单元
- 特殊功能单元
- 线程束调度器
SM
GPU中每个SM都能支持数百个线程并发执行,每个GPU通常有多个SM,当一个核函数的网格被启动的时候,多个block会被同时分配给可用的SM上执行。
注意: 当一个blcok被分配给一个SM后,他就只能在这个SM上执行了,不可能重新分配到其他SM上了,多个线程块可以被分配到同一个SM上。
在SM上同一个块内的多个线程进行线程级别并行,而同一线程内,指令利用指令级并行将单个线程处理成流水线。
线程束
CUDA 采用单指令多线程SIMT架构管理执行线程,不同设备有不同的线程束大小,但是到目前为止基本所有设备都是维持在32,也就是说每个SM上有多个block,一个block有多个线程(可以是几百个,但不会超过某个最大值),但是从机器的角度,在某时刻T,SM上只执行一个线程束,也就是32个线程在同时同步执行,线程束中的每个线程执行同一条指令,包括有分支的部分,这个我们后面会讲到,
SIMD vs SIMT
单指令多数据的执行属于向量机,比如我们有四个数字要加上四个数字,那么我们可以用这种单指令多数据的指令来一次完成本来要做四次的运算。这种机制的问题就是过于死板,不允许每个分支有不同的操作,所有分支必须同时执行相同的指令,必须执行没有例外。
相比之下单指令多线程SIMT就更加灵活了,虽然两者都是将相同指令广播给多个执行单元,但是SIMT的某些线程可以选择不执行,也就是说同一时刻所有线程被分配给相同的指令,SIMD规定所有人必须执行,而SIMT则规定有些人可以根据需要不执行,这样SIMT就保证了线程级别的并行,而SIMD更像是指令级别的并行。
SIMT包括以下SIMD不具有的关键特性:
- 每个线程都有自己的指令地址计数器
- 每个县城都有自己的寄存器状态
- 每个线程可以有一个独立的执行路径
而上面这三个特性在编程模型可用的方式就是给每个线程一个唯一的标号(blckIdx,threadIdx),并且这三个特性保证了各线程之间的独立
Cuda同步
- 线程块内同步
- __syncthread();
- 系统级别
Cuda流
我们的所有CUDA操作都是在流中进行的,虽然我们可能没发现,但是有我们前面的例子中的指令,内核启动,都是在CUDA流中进行的,只是这种操作是隐式的,所以肯定还有显式的,所以,流分为:
- 隐式声明的流,我们叫做空流
- 显式声明的流,我们叫做非空流
//这是个异步操作,cudaMemcpy是同步操作 cudaError_t cudaMemcpyAsync(void* dst, const void* src, size_t count,cudaMemcpyKind kind, cudaStream_t stream = 0); //创建流 cudaError_t cudaStreamCreate(cudaStream_t* pStream); //回收资源 cudaError_t cudaStreamDestroy(cudaStream_t stream); //阻塞操作,直到流完成 cudaError_t cudaStreamSynchronize(cudaStream_t stream); //查询 cudaError_t cudaStreamQuery(cudaStream_t stream);
/// Demo for (int i = 0; i < nStreams; i++) { int offset = i * bytesPerStream; cudaMemcpyAsync(&d_a[offset], &a[offset], bytePerStream, streams[i]); kernel<<grid, block, 0, streams[i]>>(&d_a[offset]); cudaMemcpyAsync(&a[offset], &d_a[offset], bytesPerStream, streams[i]); } for (int i = 0; i < nStreams; i++) { cudaStreamSynchronize(streams[i]); }
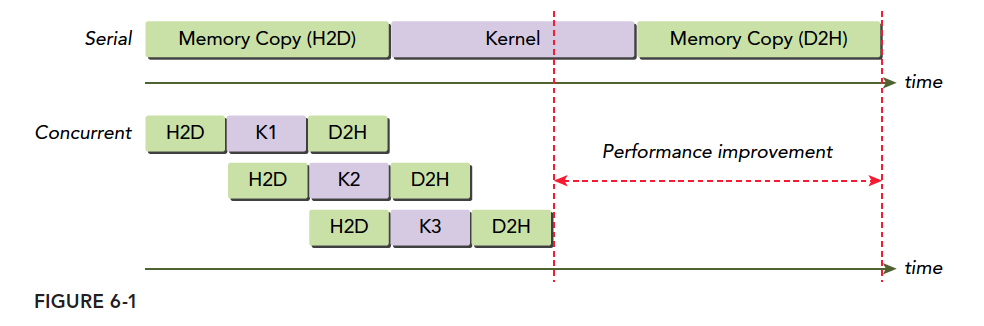
可以用事件监控流的进展,同步流的执行:
cudaError_t cudaEventCreate(cudaEvent_t* event) cudaError_t cudaEventDestroy(cudaEvent_t event); cudaError_t cudaEventRecord(cudaEvent_t event, cudaStream_t stream = 0); cudaError_t cudaEventQuery(cudaEvent_t event); cudaError_t cudaEventElapsedTime(float* ms, cudaEvent_t start, cudaEvent_t stop); //cudaStreamDefault;// 默认阻塞流 //cudaStreamNonBlocking: //非阻塞流,对空流的阻塞行为失效。 cudaError_t cudaStreamCreateWithFlags(cudaStream_t* pStream, unsigned int flags); //Demo // create two events cudaEvent_t start, stop; cudaEventCreate(&start); cudaEventCreate(&stop); // record start event on the default stream cudaEventRecord(start); // execute kernel kernel<<<grid, block>>>(arguments); // record stop event on the default stream cudaEventRecord(stop); // wait until the stop event completes cudaEventSynchronize(stop); // calculate the elapsed time between two events float time; cudaEventElapsedTime(&time, start, stop); // clean up the two events cudaEventDestroy(start); cudaEventDestroy(stop);
//显示同步 cudaError_t cudaDeviceSynchronize(void); cudaError_t cudaStreamSynchronize(cudaStream_t stream); cudaError_t cudaStreamQuery(cudaStream_t stream); cudaError_t cudaEventSynchronize(cudaEvent_t event); cudaError_t cudaEventQuery(cudaEvent_t event); cudaError_t cudaStreamWaitEvent(cudaStream_t stream, cudaEvent_t event); //流回调 cudaError_t cudaStreamAddCallback(cudaStream_t stream,cudaStreamCallback_t callback, void *userData, unsigned int flags); //Demo void CUDART_CB my_callback(cudaStream_t stream,cudaError_t status,void * data) { printf("call back from stream:%d\n",*((int *)data)); } /// for(int i=0;i<N_SEGMENT;i++) { int ioffset=i*iElem; CHECK(cudaMemcpyAsync(&a_d[ioffset],&a_h[ioffset],nByte/N_SEGMENT,cudaMemcpyHostToDevice,stream[i])); CHECK(cudaMemcpyAsync(&b_d[ioffset],&b_h[ioffset],nByte/N_SEGMENT,cudaMemcpyHostToDevice,stream[i])); sumArraysGPU<<<grid,block,0,stream[i]>>>(&a_d[ioffset],&b_d[ioffset],&res_d[ioffset],iElem); CHECK(cudaMemcpyAsync(&res_from_gpu_h[ioffset],&res_d[ioffset],nByte/N_SEGMENT,cudaMemcpyDeviceToHost,stream[i])); CHECK(cudaStreamAddCallback(stream[i],my_callback,(void *)(stream+i),0)); }
内存模型
现代计算机的内存结构主要如下:
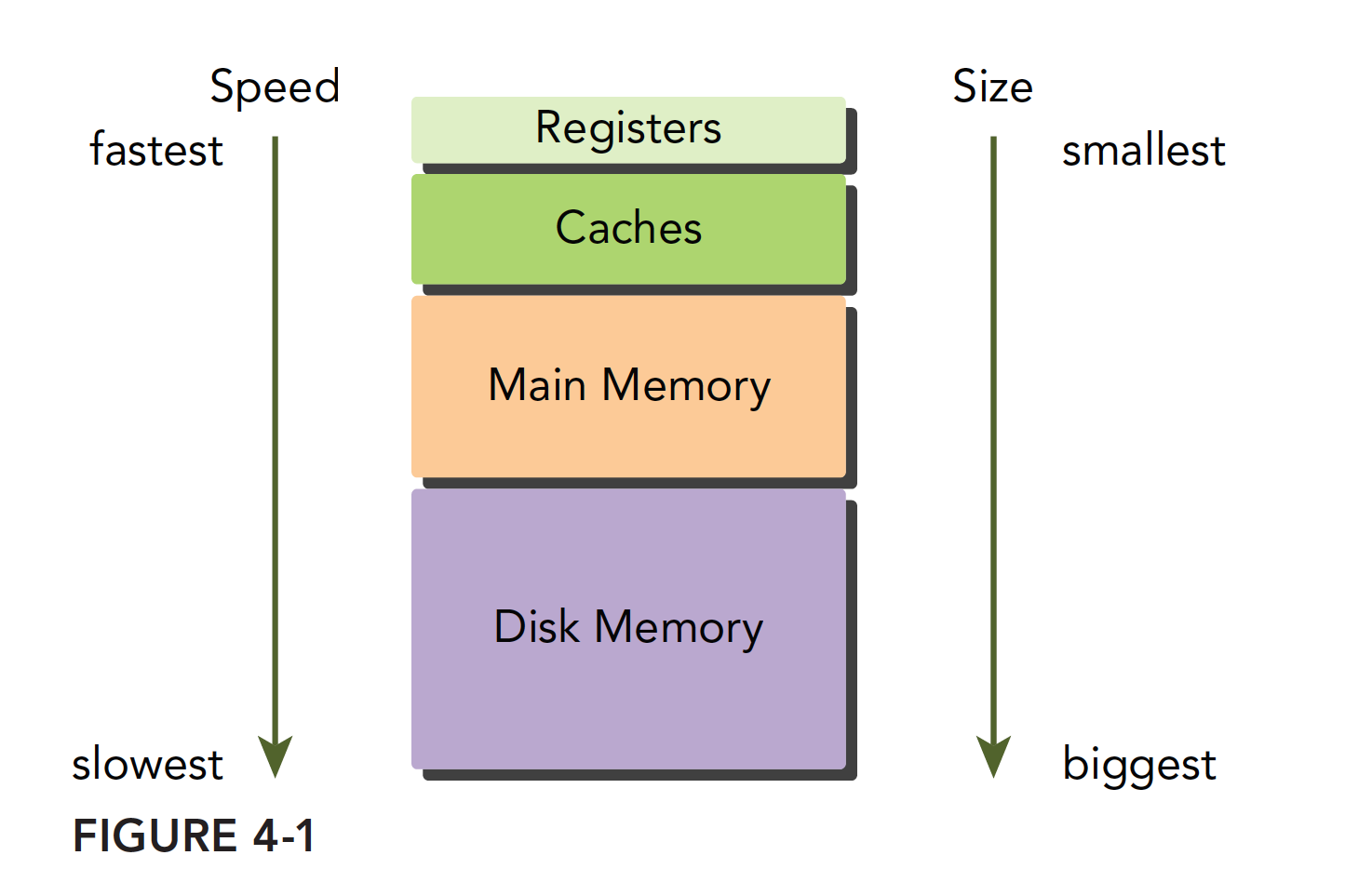
Cuda内存模型如下:
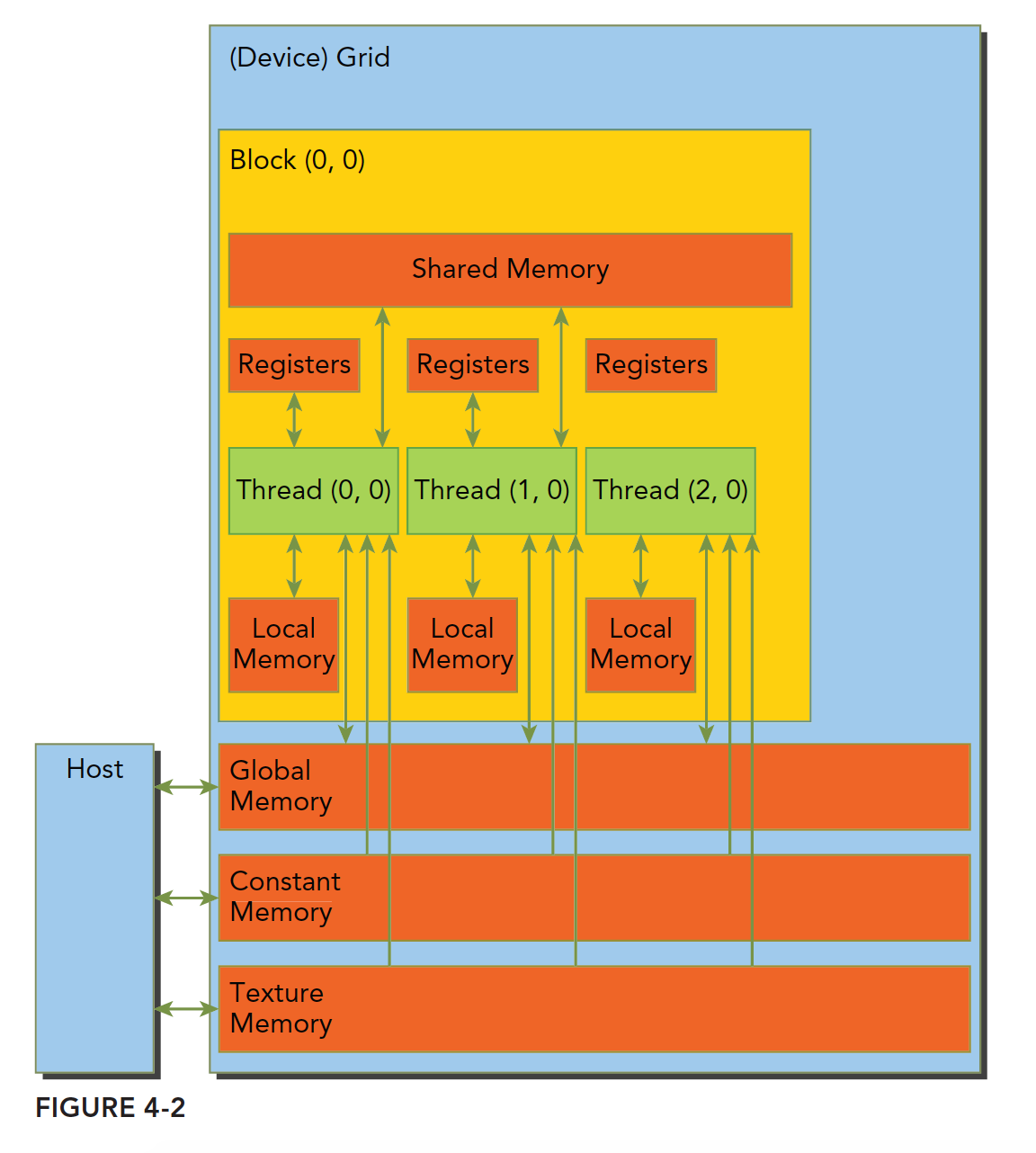
- 一级缓存
- 二级缓存
- 只读常量缓存
- 只读纹理缓存
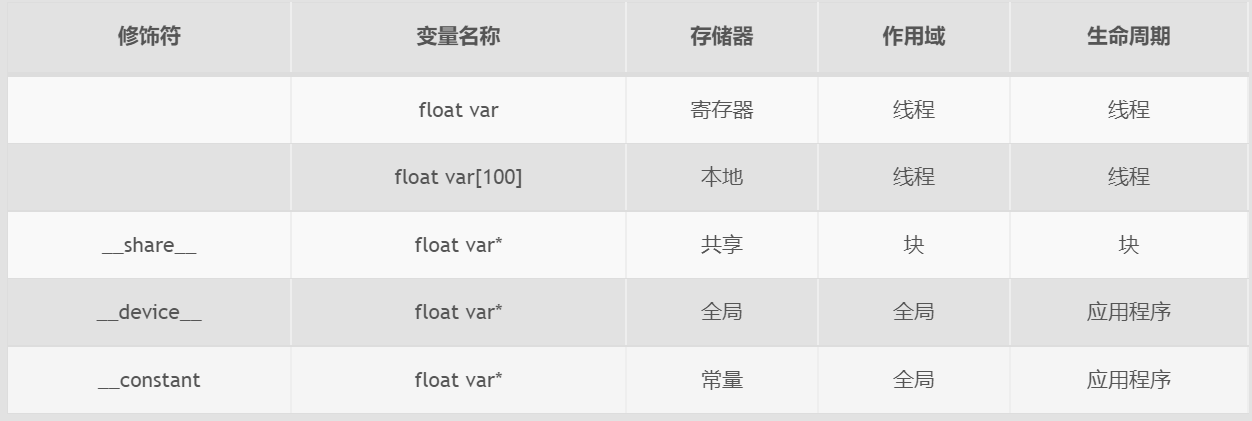
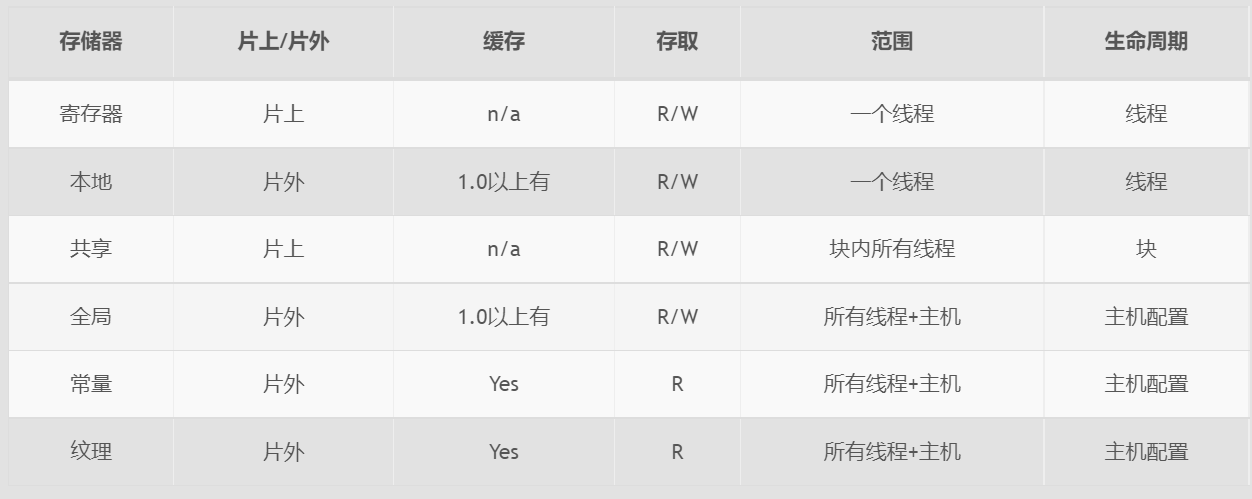
影响性能的因素
- 改变执行配置(线程组织)能得到不同的性能
- 传统的核函数可能不能得到最好的效果
- 一个给定的核函数,通过调整网格和线程块大小可以得到更好的效果
- 存储带宽
- 计算资源
- 指令和内存延迟
- 大部分情况,单一指标不能优化出最优性能
- 总体性能直接相关的是内核的代码本质(内核才是关键)
- 指标与性能之间选择平衡点
- 从不同的角度寻求指标平衡,最大化效率
- 网格和块的尺寸为调节性能提供了一个不错的起点
- 避免分支分化
- 并行规约
- 交错配对规约(性能好些)
- 性能对比:
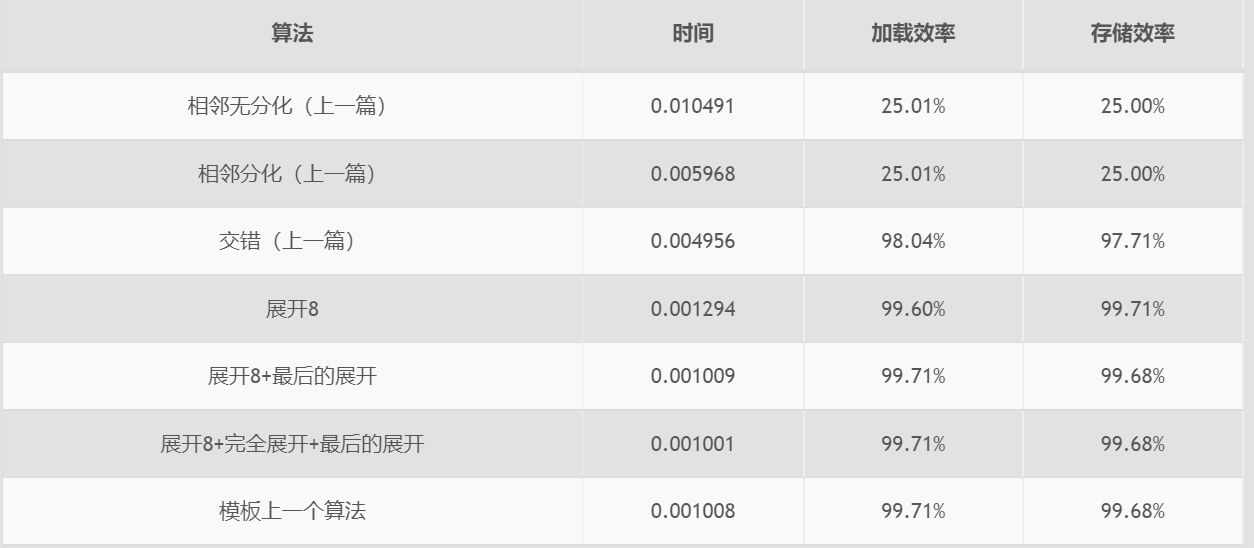
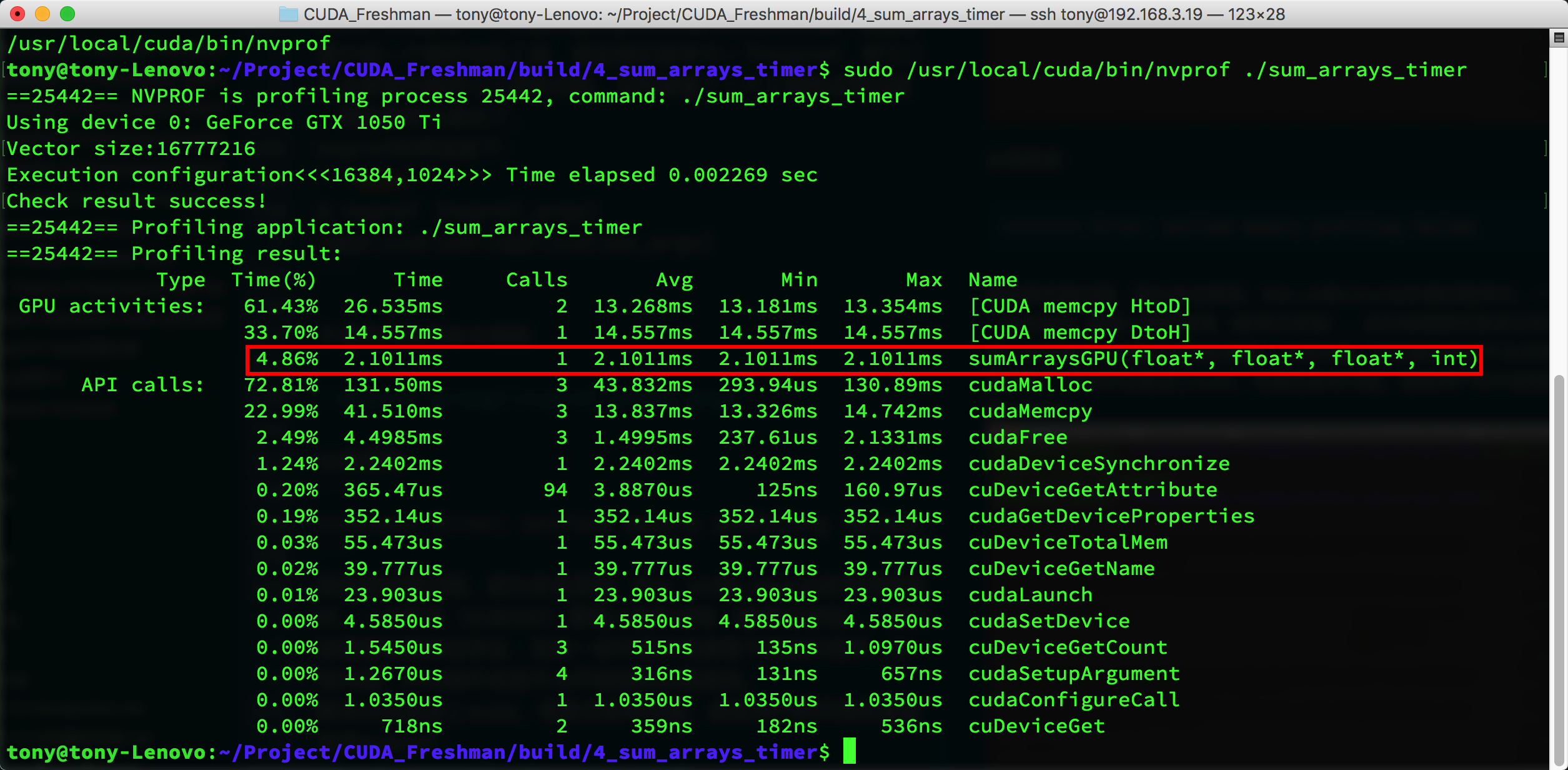
性能分析工具
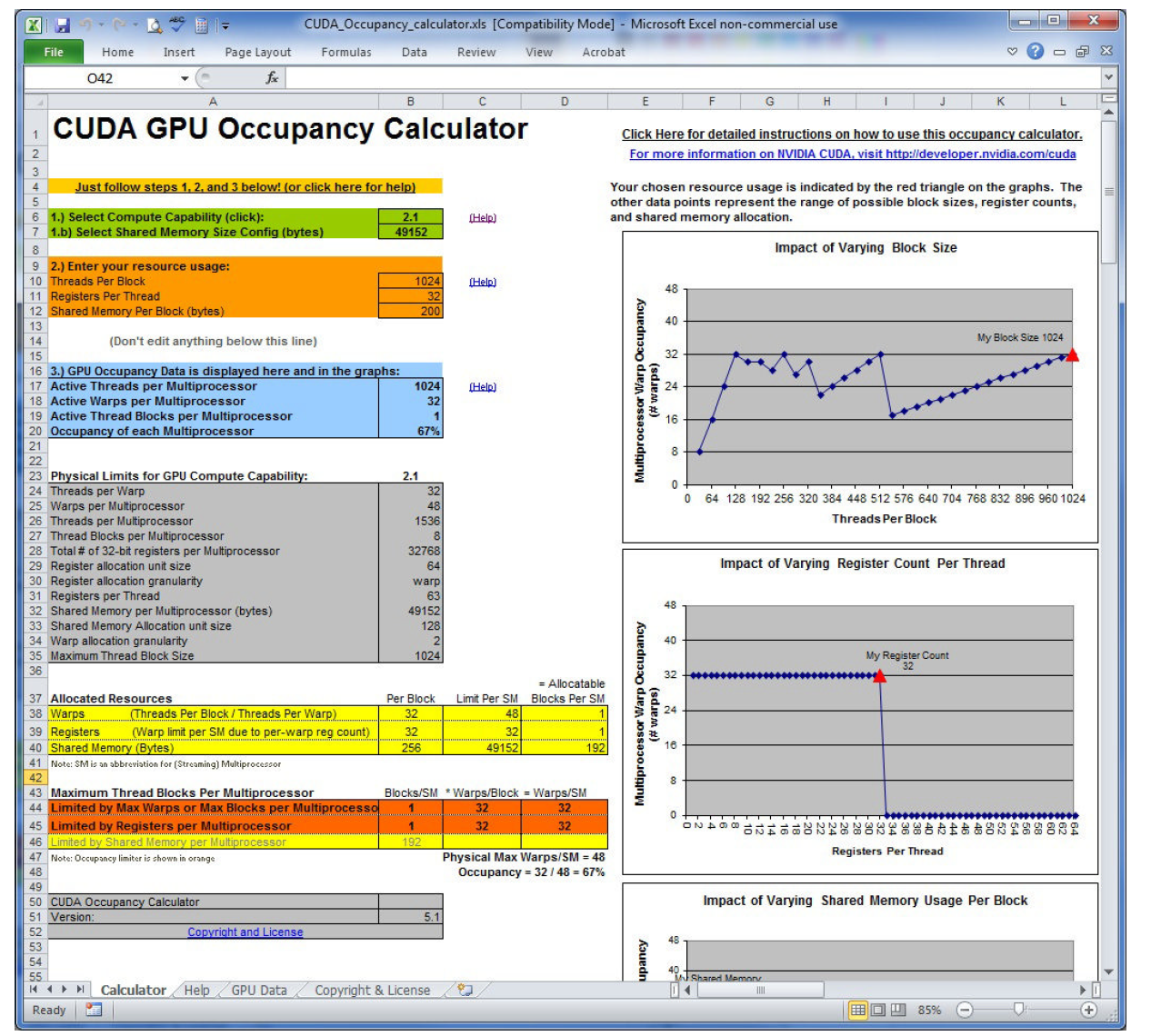
CUDA工具包中提供一个叫做UCDA占用率计算器的电子表格,填上相关数据可以帮你自动计算网格参数:
多GPU卡通信
最初的Caffe只支持单块GPU卡,后来就增加了NCCL的feature,可以支持多GPU卡。对于多个GPU卡之间相互通信,硬件层面上的实现有Nvlink、PCIe switch(不经过CPU)、Infiniband、以及PCIe Host Bridge(通常就是借助CPU进行交换)这4种方式。而NCCL是Nvidia在软件层面对这些通信方式的封装。
使用NCCL库:
gemfield@ai:/bigdata/gemfield$ nvidia-smi topo -m
GPU0 GPU1 CPU Affinity
GPU0 X PHB 0-11
GPU1 PHB X 0-11
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe switches (without traversing the PCIe Host Bridge)
PIX = Connection traversing a single PCIe switch
NV# = Connection traversing a bonded set of # NVLinks///////
root@ai.gemfield.org:~# git clone https://github.com/NVIDIA/nccl.git Cloning into 'nccl'... remote: Counting objects: 651, done. remote: Total 651 (delta 0), reused 0 (delta 0), pack-reused 651 Receiving objects: 100% (651/651), 1.38 MiB | 619.00 KiB/s, done. Resolving deltas: 100% (411/411), done. Checking connectivity... done.
root@ai.gemfield.org:~# cd nccl/ root@ai.gemfield.org:~/nccl# make CUDA_HOME=/usr/local/cuda test Grabbing src/nccl.h > /root/nccl/build/include/nccl.h Compiling src/libwrap.cu > /root/nccl/build/obj/libwrap.o Compiling src/core.cu > /root/nccl/build/obj/core.o Compiling src/all_gather.cu > /root/nccl/build/obj/all_gather.o Compiling src/all_reduce.cu > /root/nccl/build/obj/all_reduce.o Compiling src/broadcast.cu > /root/nccl/build/obj/broadcast.o Compiling src/reduce.cu > /root/nccl/build/obj/reduce.o Compiling src/reduce_scatter.cu > /root/nccl/build/obj/reduce_scatter.o Linking libnccl.so.1.3.5 > /root/nccl/build/lib/libnccl.so.1.3.5 Building test/single/all_gather_test.cu > /root/nccl/build/test/single/all_gather_test Building test/single/all_gather_scan.cu > /root/nccl/build/test/single/all_gather_scan Building test/single/all_reduce_test.cu > /root/nccl/build/test/single/all_reduce_test Building test/single/all_reduce_scan.cu > /root/nccl/build/test/single/all_reduce_scan Building test/single/broadcast_test.cu > /root/nccl/build/test/single/broadcast_test Building test/single/broadcast_scan.cu > /root/nccl/build/test/single/broadcast_scan Building test/single/reduce_test.cu > /root/nccl/build/test/single/reduce_test Building test/single/reduce_scan.cu > /root/nccl/build/test/single/reduce_scan Building test/single/reduce_scatter_test.cu > /root/nccl/build/test/single/reduce_scatter_test Building test/single/reduce_scatter_scan.cu > /root/nccl/build/test/single/reduce_scatter_scan root@ai.gemfield.org:~/nccl# find . -name "*.so" ./build/lib/libnccl.so root@ai.gemfield.org:~/nccl# make install removed '/usr/local/lib/libnccl.so' '/root/nccl/build/lib/libnccl.so' -> '/usr/local/lib/libnccl.so' removed '/usr/local/lib/libnccl.so.1' '/root/nccl/build/lib/libnccl.so.1' -> '/usr/local/lib/libnccl.so.1' '/root/nccl/build/lib/libnccl.so.1.3.5' -> '/usr/local/lib/libnccl.so.1.3.5' '/root/nccl/build/include/nccl.h' -> '/usr/local/include/nccl.h'
GPU加速
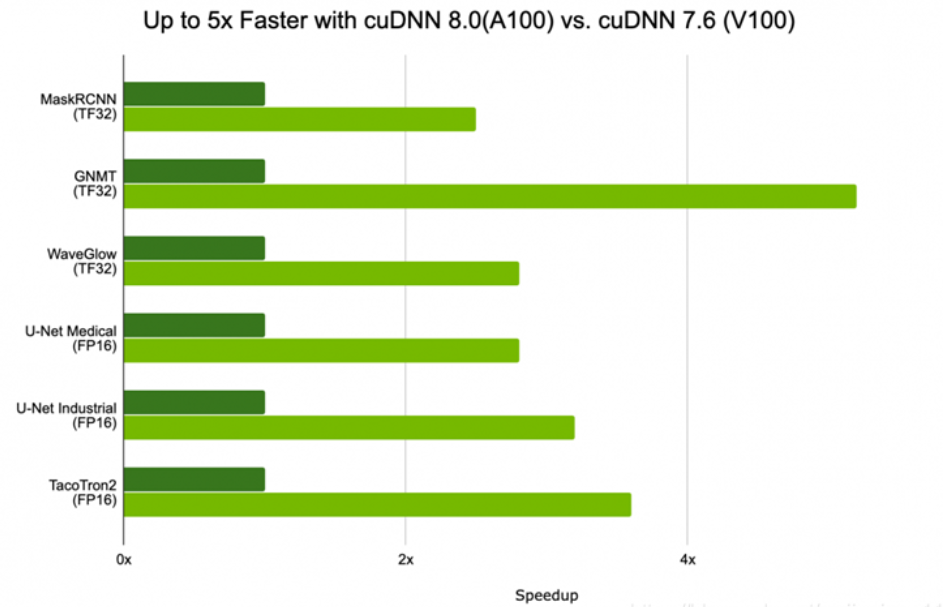
NVIDIA CUDA ®深度神经网络库(cuDNN)是GPU加速的用于深度神经网络的原语库。cuDNN为标准例程提供了高度优化的实现,例如向前和向后卷积,池化,规范化和激活层。
全球的深度学习研究人员和框架开发人员都依赖cuDNN来实现高性能GPU加速。它使他们可以专注于训练神经网络和开发软件应用程序,而不必花时间在底层GPU性能调整上。cuDNN的加快广泛使用的深度学习框架,包括Caffe2,Chainer,Keras,MATLAB,MxNet,PyTorch和TensorFlow。已将cuDNN集成到框架中的NVIDIA优化深度学习框架容器,访问NVIDIA GPU CLOUD了解更多信息并开始使用。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通