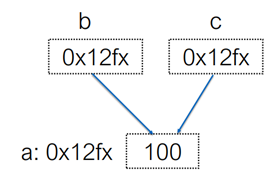
3.1 Go语言基础之指针
区别于C/C++中的指针,Go语言中的指针不能进行偏移和运算,是安全指针。
要搞明白Go语言中的指针需要先知道3个概念:指针地址、指针类型和指针取值。
一、Go语言中的指针
Go语言中的函数传参都是值拷贝,当我们想要修改某个变量的时候,我们可以创建一个指向该变量地址的指针变量。传递数据使用指针,而无须拷贝数据。类型指针不能进行偏移和运算。Go语言中的指针操作非常简单,只需要记住两个符号:&(取地址)和*(根据地址取值)。
二、指针地址
每个变量在运行时都拥有一个地址,这个地址代表变量在内存中的位置。Go语言中使用&字符放在变量前面对变量进行“取地址”操作。
取变量指针的语法如下:
ptr := &v // v的类型为T
其中:
- v:代表被取地址的变量,类型为
T - ptr:用于接收地址的变量,ptr的类型就为
*T,称做T的指针类型。*代表指针。
举个例子:
func main() {
a := 10
b := &a
fmt.Printf("a:%d ptr:%p\n", a, &a) // a:10 ptr:0xc00001a078
fmt.Printf("b:%p type:%T\n", b, b) // b:0xc00001a078 type:*int
fmt.Println(&b) // 0xc00000e018
}
我们来看一下b := &a的图示: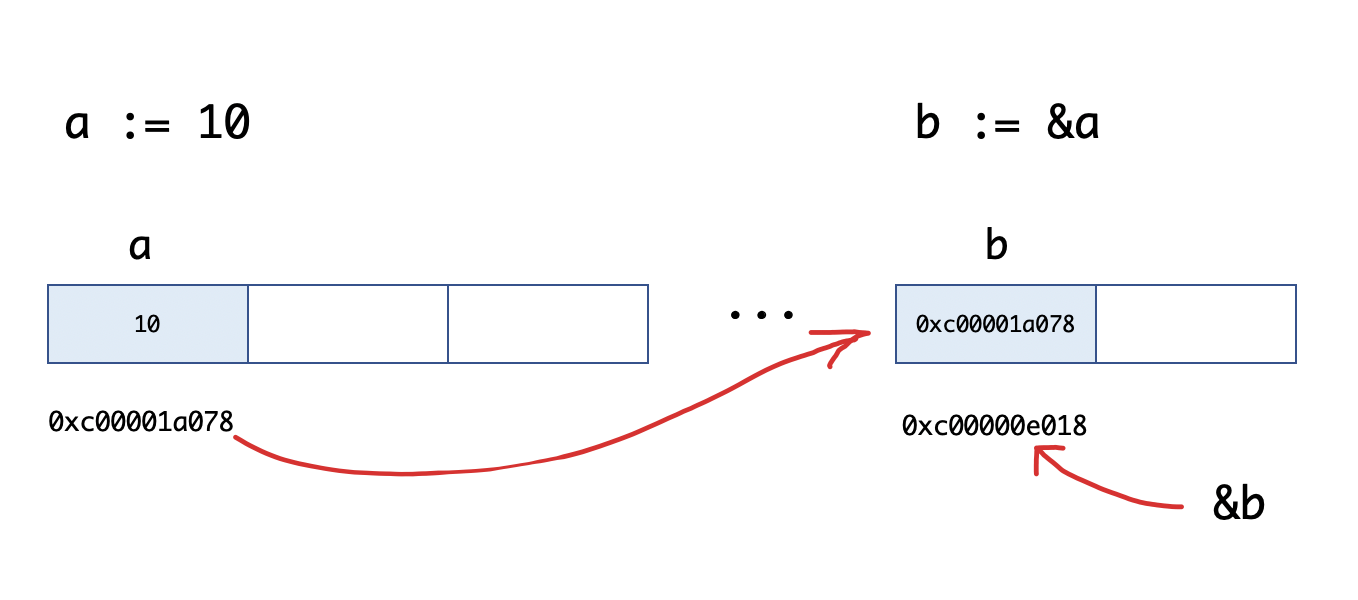
三、指针类型
3.1 定义
-
普通变量存储的是对应类型的值,这些类型就叫值类型;
-
指针类型的变量存储的是一个地址,所以又叫指针类型或引用类型;(任何类型都可以有指针类型,对于所有类型指针类型都生效)比如说:Go语言中的值类型(int、float、bool、string、array、struct)都有对应的指针类型,如:int、int64、*string等。
-
指针类型默认值为nil(空内存地址0x0)
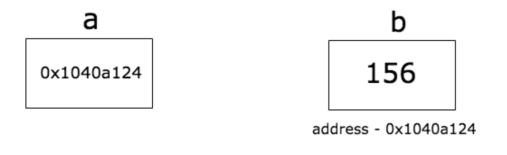
a就是一个指针类型,存储的是内存地址,b是一个值类型,存储的是对应的值。
下面通过一个实例再来理解一下:
package main
import (
"fmt"
)
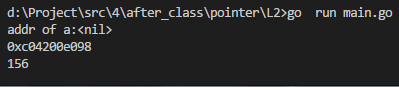
func main() {
var b int32 //b为值类型,存储的是对应的值
b = 156
var a *int32 //a为指针类型,存储的是内存地址
fmt.Printf("addr of a:%v\n", a) //指针a未赋值,其的默认值为nil,也就是空内存地址0x0
a = &b //a目前是一个指针,打印出来的也就是b(通过&取的内存地址)的内存地址
fmt.Printf("%v\n", a)
fmt.Printf("%v\n", *a) //*a表示取指针类型里指向的那块内存地址所对应的值
}
执行结果如下:
3.2 声明定义
指针类型定义, var 变量名 *类型
实例:
package main
import (
"fmt"
)
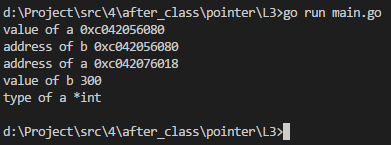
func main() {
var a *int
var b int = 200
a = &b
fmt.Printf("value of a %v\n", a) //打印的是指针a的值
fmt.Printf("address of b %v\n", &b) //打印的是变量b的内存地址
fmt.Printf("address of a %v\n", &a) //打印指针a的内存地址
*a = 300 //修改指针a存的内存地址所对应的值的值(其实就是修改b)
fmt.Printf("value of b %v\n", b) //打印变量b看是否修改成功
fmt.Printf("type of a %T\n", a) //%T能够打印变量的类型
}
执行结果:
3.3 指针初始化
3.3.1 方法1
var a *int = &b
再定义指针a之后,我们必须要为其初始化(不初始化,是一个空内存地址,程序会直接崩溃),也就是为其赋值,这里我们为指针a传入的是一个内存地址(也就分配了内存了),因为变量b在定义时已经为其分配了内存,这里是把变量b的内存地址赋值给了指针a;
3.3.2 方法2 new
var p *int = new(int)
变量p此时为指针,其指向的是一个类型为int的内存地址(底层new为其分配内存地址,做了初始化),然后就可以对指针p进行操作了
3.4 指针类型变量的默认值
指针类型变量的默认值为nil,也就是空地址0x0。所有操作都是有内存才能操作。
下面通过一个实例来验证下对一个空地址操作,程序就会崩溃:
实例:
package main
import (
"fmt"
)
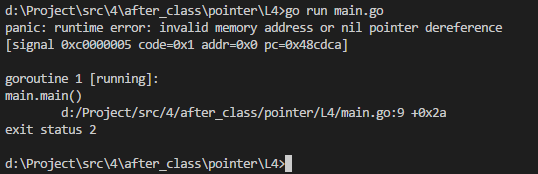
func main() {
var a *int //只是定义了一个指针a
*a = 100 //现在修改指针a,但指针a是空,必然会报错
fmt.Printf("%d\n", *a)
}
执行结果如下:
所以我们写程序一定要严谨,加上判断,可见如下例子:
package main
import (
"fmt"
)
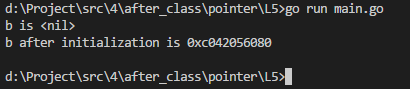
func main() {
a := 25
var b *int
if b == nil { //如果指针b是空地址,就为其赋值,不然程序会崩溃
fmt.Printf("b is %v\n", b)
b = &a
fmt.Printf("b after initialization is %v\n", b)
}
}
执行结果如下:
四、指针取值
4.1 操作指针变量指向的地址里面的值
注意:
通过* 符号可以获取指针变量指向的变量
*指针变量:就能够获得指针变量中存的内存地址对应的值。
如果想要修改指针变量的存的内存地址所对应的值?
方法:*指针变量 = 要修改的值
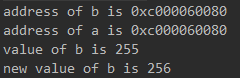
实例:
package main
import "fmt"
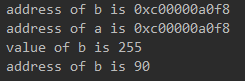
func main() {
b := 255
a := &b
fmt.Println("address of b is", &b)
fmt.Println("address of a is", a)
fmt.Println("value of b is", *a) //获取指针变量中存的内存地址对应的值
*a = 90 //修改指针变量的存的内存地址所对应的值
fmt.Println("address of b is", b)
}
执行结果如下图所示:
4.2 通过指针修改变量的值
如果想要修改指针变量的存的内存地址所对应的值?
方法:*指针变量 = 要修改的值
实例:
package main
import (
"fmt"
)
func main() {
b := 255
a := &b
fmt.Println("address of b is", &b)
fmt.Println("address of a is", a)
fmt.Println("value of b is", *a)
*a++ //修改指针变量的存的内存地址所对应的值
fmt.Println("new value of b is", b)
}
执行结果如下:
4.3 指针变量传参
1、如果是一个值类型,通过函数是改不了他的值。
2、无论是指针类型还是值类型,函数传参都是值拷贝,只不过指针类型拷贝的是内存地址,无论指针类型的内存地址指向的那个值有多大,指针类型永远是拷贝8个字节(64位操作系统 int64 32位操作系统是4个字节 int32),所以说如果指针类型指向的那块内存地址存的值很大的话,指针传值性能更高。
下面通过这个例子来详细解释下:
实例1:
package main
import (
"fmt"
)
func modify(a int) {
fmt.Printf("2. address of a=%p, value of a:%v\n", &a, a)
a = 1000
}
func modify2(a *int) {
fmt.Printf("4. address of a:%v, value of a :%v\n", &a, a)
*a = 1000
}
func main() {
var b int = 100
fmt.Printf("1. address of b=%p, value of b:%v\n", &b, b)
modify(b)
var p *int = &b
fmt.Printf("3. address of p:%v, value of p:%v\n", &p, p)
modify2(p)
fmt.Printf("b=%d\n", b)
}
执行结果如下:
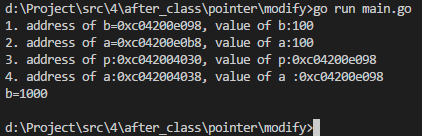
解释:
1、函数传参是值的拷贝,只不过值类型传递的是值,指针类型(引用类型)传递的是内存地址。
2、定义b为100,当首先执行modify函数时,传递的是b的副本,所以无论函数中怎么修改,是不影响变量b值本身的。在经过modify2函数执行后,虽然传递的也是副本,但是传递的是b的内存地址,而函数又是基于该内存地址进行修改的,所以值由100修改为了1000
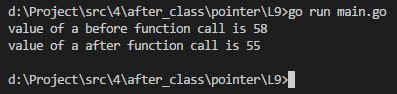
实例2:
package main
import (
"fmt"
)
func change(val *int) {
*val = 55 //修改指针多存的内存地址对应的值
}
func main() {
a := 58
fmt.Println("value of a before function call is", a)
b := &a //传入a的内存地址
change(b)
fmt.Println("value of a after function call is", a)
}
执行结果如下:
实例3:
package main
import (
"fmt"
)
func modify(arr *[3]int) {
(*arr)[0] = 90
}
func main() {
a := [3]int{89, 90, 91}
modify(&a) //传递的是内存地址所以可以修改
fmt.Println(a)
}
执行结果如下:

4.4 切片传参
实例:
package main
import (
"fmt"
)
func modify(sls []int) {
sls[0] = 90
}
func main() {
a := [3]int{89, 90, 91}
modify(a[:]) //切片是引用类型,所以底层也是指针,所以是可以修改的,修改是生效的
fmt.Println(a)
}
执行结果如下:

4.5 总结
在对普通变量使用&操作符取地址后会获得这个变量的指针,然后可以对指针使用*操作,也就是指针取值,代码如下。
func main() {
//指针取值
a := 10
b := &a // 取变量a的地址,将指针保存到b中
fmt.Printf("type of b:%T\n", b)
c := *b // 指针取值(根据指针去内存取值)
fmt.Printf("type of c:%T\n", c)
fmt.Printf("value of c:%v\n", c)
}
输出如下:
type of b:*int
type of c:int
value of c:10
总结: 取地址操作符&和取值操作符*是一对互补操作符,&取出地址,*根据地址取出地址指向的值。
变量、指针地址、指针变量、取地址、取值的相互关系和特性如下:
- 对变量进行取地址(&)操作,可以获得这个变量的指针变量。
- 指针变量的值是指针地址。
- 对指针变量进行取值(*)操作,可以获得指针变量指向的原变量的值。
指针传值示例:
func modify1(x int) {
x = 100
}
func modify2(x *int) {
*x = 100
}
func main() {
a := 10
modify1(a)
fmt.Println(a) // 10
modify2(&a)
fmt.Println(a) // 100
}
五、new和make
我们先来看一个例子:
func main() {
var a *int
*a = 100
fmt.Println(*a)
var b map[string]int
b["北京哈登"] = 100
fmt.Println(b)
}
执行上面的代码会引发panic,为什么呢? 在Go语言中对于引用类型的变量,我们在使用的时候不仅要声明它,还要为它分配内存空间,否则我们的值就没办法存储。而对于值类型的声明不需要分配内存空间,是因为它们在声明的时候已经默认分配好了内存空间。要分配内存,就引出来今天的new和make。 Go语言中new和make是内建的两个函数,主要用来分配内存。
5.1 new
new是一个内置的函数,它的函数签名如下:
func new(Type) *Type
其中,
- Type表示类型,new函数只接受一个参数,这个参数是一个类型
- *Type表示类型指针,new函数返回一个指向该类型内存地址的指针。
new函数不太常用,使用new函数得到的是一个类型的指针,并且该指针对应的值为该类型的零值。举个例子:
func main() {
a := new(int)
b := new(bool)
fmt.Printf("%T\n", a) // *int
fmt.Printf("%T\n", b) // *bool
fmt.Println(*a) // 0
fmt.Println(*b) // false
}
本节开始的示例代码中var a *int只是声明了一个指针变量a但是没有初始化,指针作为引用类型需要初始化后才会拥有内存空间,才可以给它赋值。应该按照如下方式使用内置的new函数对a进行初始化之后就可以正常对其赋值了:
func main() {
var a *int
a = new(int)
*a = 10
fmt.Println(*a)
}
5.2 make
make也是用于内存分配的,区别于new,它只用于slice、map以及chan的内存创建,而且它返回的类型就是这三个类型本身,而不是他们的指针类型,因为这三种类型就是引用类型,所以就没有必要返回他们的指针了。make函数的函数签名如下:
func make(t Type, size ...IntegerType) Type
make函数是无可替代的,我们在使用slice、map以及channel的时候,都需要使用make进行初始化,然后才可以对它们进行操作。这个我们在上一章中都有说明,关于channel我们会在后续的章节详细说明。
本节开始的示例中var b map[string]int只是声明变量b是一个map类型的变量,需要像下面的示例代码一样使用make函数进行初始化操作之后,才能对其进行键值对赋值:
func main() {
var b map[string]int
b = make(map[string]int, 10)
b["哈登"] = 100
fmt.Println(b)
}
5.3 new与make的区别
- 二者都是用来做内存分配的。
- make只用于slice、map以及channel的初始化,返回的还是这三个引用类型本身;
- 而new用于类型的内存分配,并且内存对应的值为类型零值,返回的是指向类型的指针。
换一种说法:
简单来说,
1、make用来分配引用类型的内存,比如 map、 slice以及channel,make除了分配内存外,还为这些复杂的数据类型(底层结构复杂,有很多字段在里面)做初始化
2、new用来分配除引用类型的所有其他类型的内存,比如 int、数组等,其实new可以为任何类型的分配内存,只不过针对引用类型(切片、map)来说,new虽然可以为其分配内存,但是其还是需要借助make去初始化。
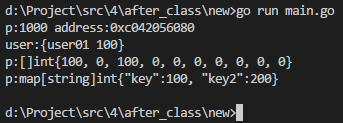
下面通过这个实例来深入理解下:
package main
import (
"fmt"
)
type User struct {
Name string
age int
}
func test1() {
var p *int = new(int)
*p = 1000
fmt.Printf("p:%v address:%v\n", *p, p)
var pUser *User = new(User)
(*pUser).age = 100
pUser.Name = "user01" //正常来说规范写应该是(*pUser).Name,但是go语言针对结构体这里做了优化(切片、map不可以,依然需要规范写),可以简化写。
fmt.Printf("user:%v\n", *pUser)
}
func test2() {
var p *[]int = new([]int) //new为切片分配内存
*p = make([]int, 10) //切片需要make为其初始化才能使用
(*p)[0] = 100
(*p)[2] = 100
fmt.Printf("p:%#v\n", *p)
var p1 *map[string]int = new(map[string]int) //new为map分配内存
*p1 = make(map[string]int, 10) //map需要make为其初始化才可以使用
(*p1)["key"] = 100
(*p1)["key2"] = 200
fmt.Printf("p:%#v\n", *p1)
}
func main() {
test1()
test2()
}
执行结果如下:
六、值拷贝和引用拷贝
6.1 值拷贝
值类型拷贝,相当于完全拷贝一份(有副本存在),当对副本进行修改时,无论如何是不影响变量本身的。
实例1:
package main
import (
"fmt"
)
func main() {
var a int = 100
fmt.Printf("a addr is %p\n", &a)
b := a
fmt.Printf("b addr is %p\n", &b)
a = 50
fmt.Printf("a addr is %p\n", &a)
fmt.Printf("a=%d b=%d", a, b)
}
执行结果如下:
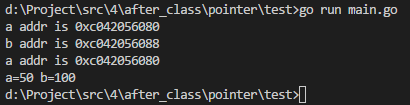
解释:
正如此题,a赋值给b,其做的就是一个值拷贝,b就相当于是拷贝的这个副本,无论b如何变化,是不影响a本身的,本身他们就是2块独立的内存地址。所以a的值在变化后,b是不受影响的。
6.2 引用拷贝
引用拷贝,拷贝的是内存地址,所以当其中一个变量修改了,另一个变量也会修改,因为他们对应的是同一个内存地址。
通过如下例子再来理解一下:
package main
import (
"fmt"
)
func main() {
var a int = 100
var b *int = &a
var c *int = b
*c = 200
fmt.Printf("a=%v b=%v c=%v", a, *b, *c)
}
执行结果如下:

解释:
我们可以发现a、b和c都是同事指向同一内存地址,一旦对任何一个变量修改,另外两个变量也会修改。