
吴恩达序列模型——循环序列模型
对于自然语言和音频等前后相关联的数据,需要使用循环神经网络进行处理
1. 数据表示
序列数据:对于一个序列数据 x,用符号xt来表示这个数据中的第t个元素,用yt来表示第 t个标签,用 Tx和 Ty来表示输入和输出的长度。可以是单词也可以是字符,音频的一段元素。第 i个序列数据的第t 个元素用符号x(i)(t),第 t个标签即为y(i)(t)。对应即有T(i)x和 T(i)y 。
词汇表(Vocabulary):字典(Dictionary)。将需要表示的所有词语变为一个列向量,可以根据字母顺序排列,然后根据单词在向量中的位置,用 one-hot 向量(one-hot vector)来表示该单词的标签,如果出现词汇表之外的单词,可以使用UNK或其他字符串来表示。将每个单词编码成一个R|v|x1向量,其中 |V|<是词汇表中单词的数量。一个单词在词汇表中的索引在该向量对应的元素为 1,其余元素均为 0。例如,'zebra'排在词汇表的最后一位,因此它的词向量表示为:wzebra=[0,0,0,...,1]T
2. 循环神经网络
对于序列数据,使用标准神经网络存在以下问题:
- 对于不同的示例,输入和输出可能有不同的长度,因此输入层和输出层的神经元数量无法固定。
- 从输入文本的不同位置学到的同一特征无法共享。
- 模型中的参数太多,计算量太大。
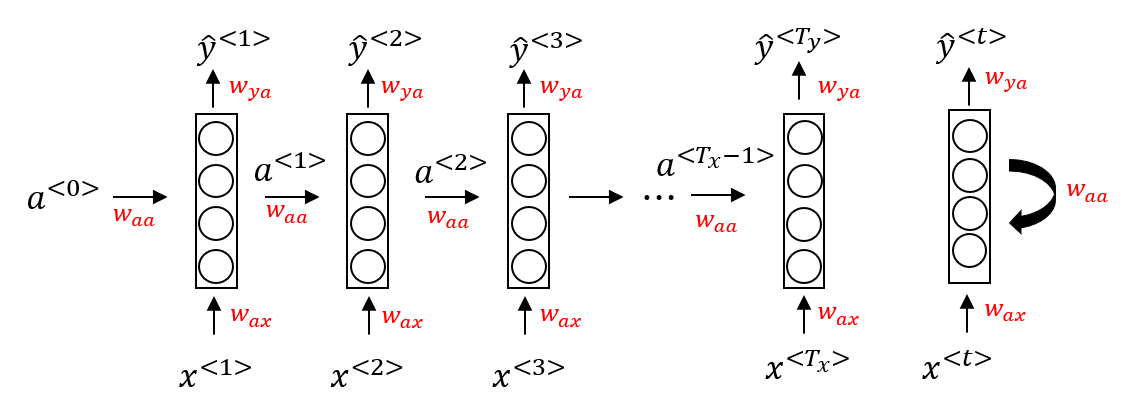
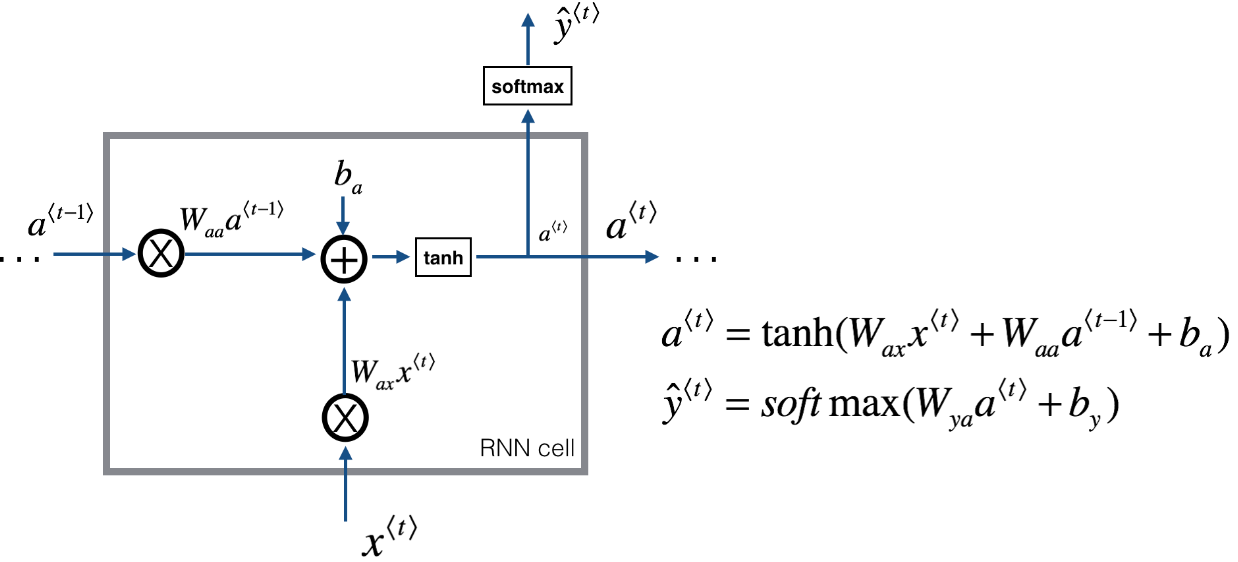
当元素x(t)输入对应时间步(Time Step)的隐藏层的同时,该隐藏层也会接收来自上一时间步的隐藏层的激活值 a(t-1),其中 a(0)一般直接初始化为零向量。一个时间步输出一个对应的预测结果y^(t)。循环神经网络从左向右扫描数据,同时每个时间步的参数也是共享的,输入、激活、输出的参数对应为 Wax、Waa、Wya。下图是一个 RNN 神经元的结构:

为了计算反向传播过程,需要先定义一个损失函数。单个位置上(或者说单个时间步上)某个单词的预测值的损失函数采用交叉熵损失函数
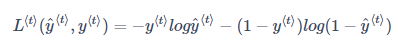
将单个位置上的损失函数相加,得到整个序列的成本函数如下
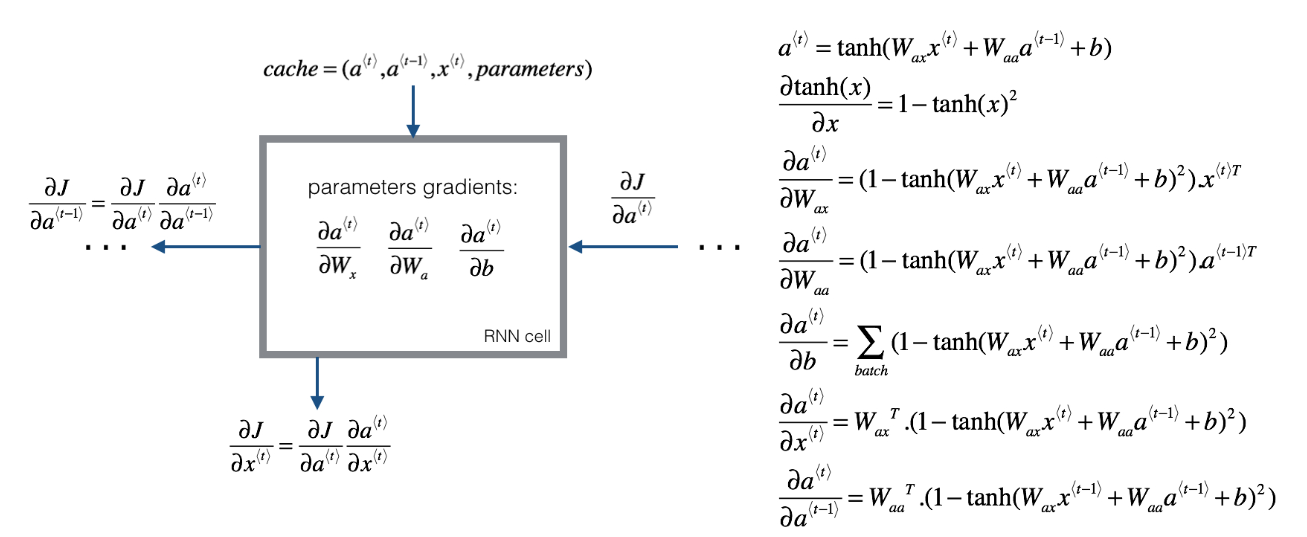
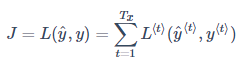 循环神经网络的反向传播被称为通过时间反向传播(Backpropagation through time),因为从右向左计算的过程就像是时间倒流。
循环神经网络的反向传播被称为通过时间反向传播(Backpropagation through time),因为从右向左计算的过程就像是时间倒流。
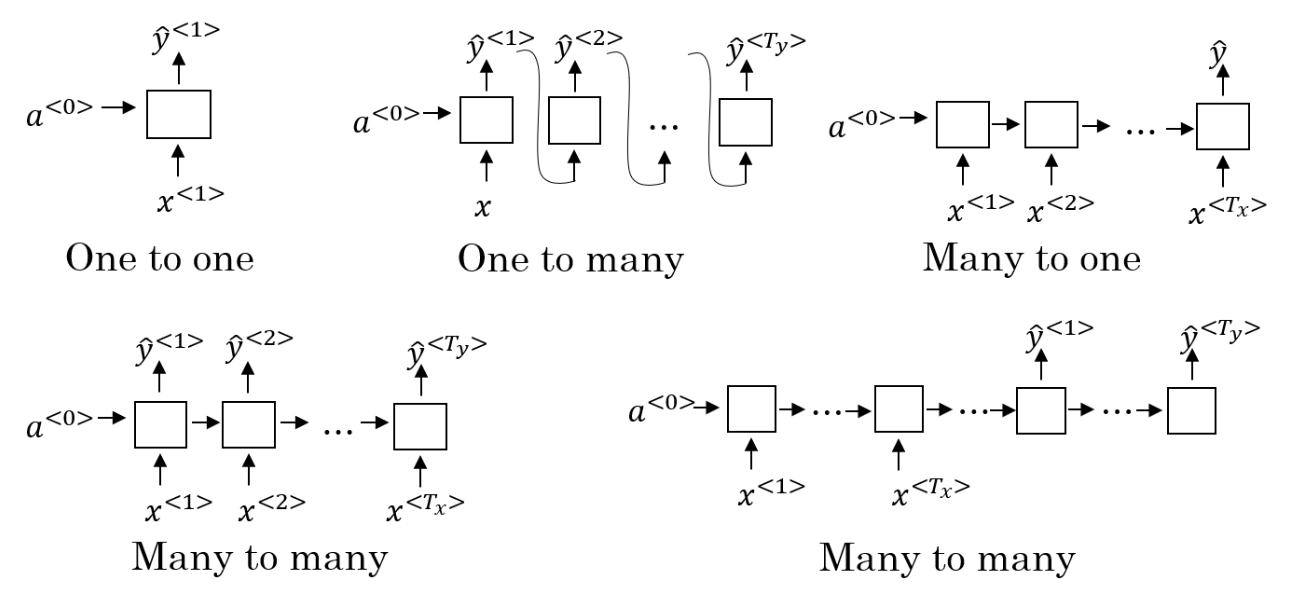
3. RNN结构
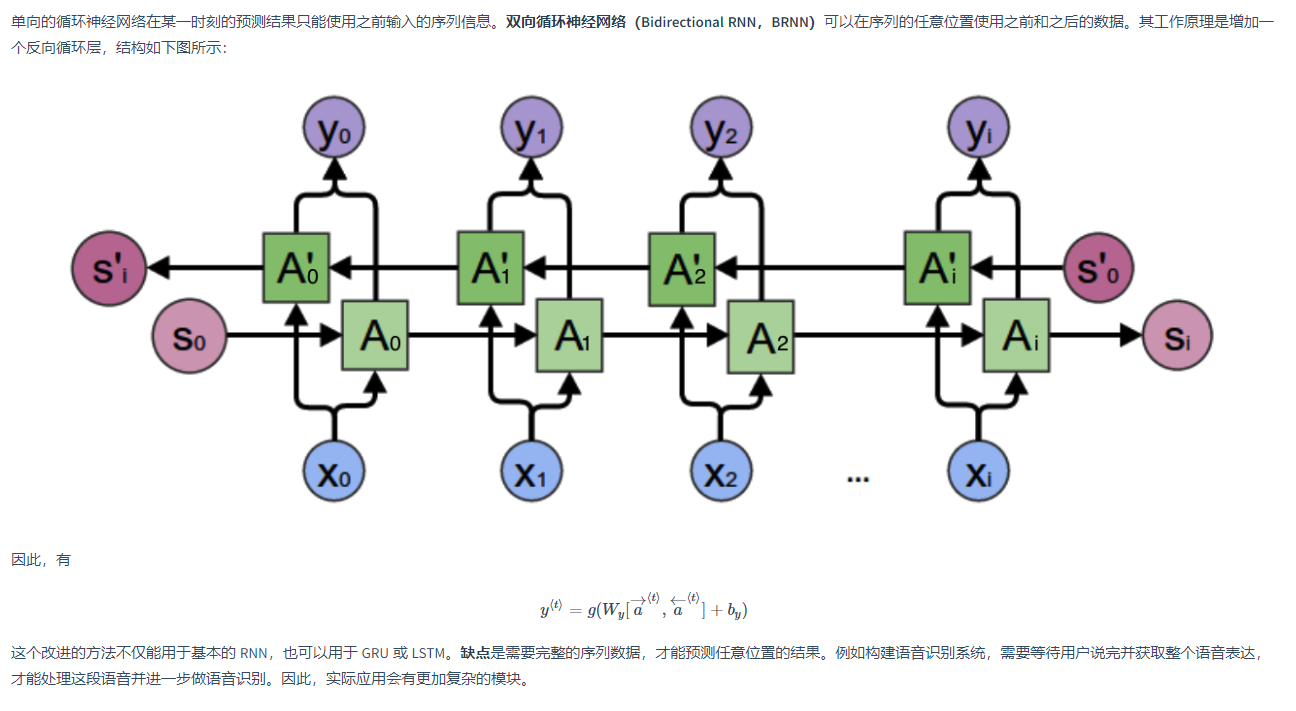
还可以通过双向RNN 实现
4. 语言模型
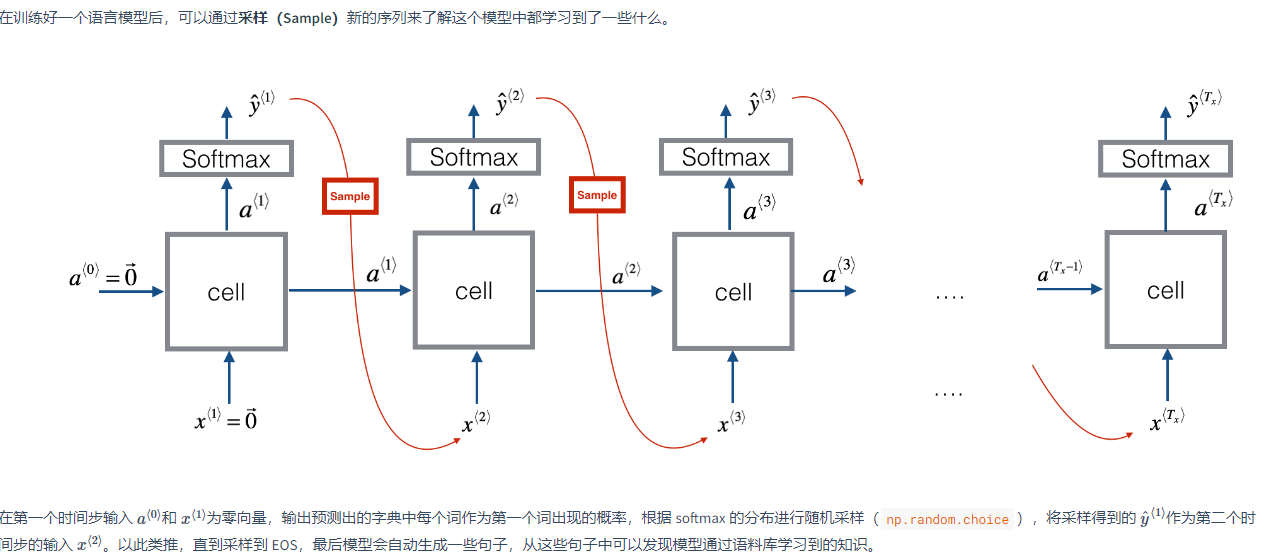
语言模型(Language Model)是根据语言客观事实而进行的语言抽象数学建模,能够估计某个序列中各元素出现的可能性。建立语言模型所采用的训练集是一个大型的语料库(Corpus),指数量众多的句子组成的文本。建立过程的第一步是标记化(Tokenize),即建立字典;然后将语料库中的每个词表示为对应的 one-hot 向量。另外,需要增加一个额外的标记 EOS(End of Sentence)来表示一个句子的结尾。标点符号可以忽略,也可以加入字典后用 one-hot 向量表示。对于语料库中部分特殊的、不包含在字典中的词汇,例如人名、地名,可以不必针对这些具体的词,而是在词典中加入一个 UNK(Unique Token)标记来表示。

语言模型模拟了任意特定单词序列的概率,要做的是对这些概率分布进行采样来生成一个新的单词序列。
5. 梯度消失
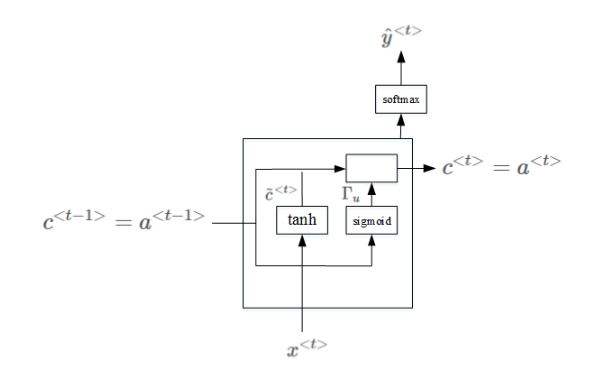

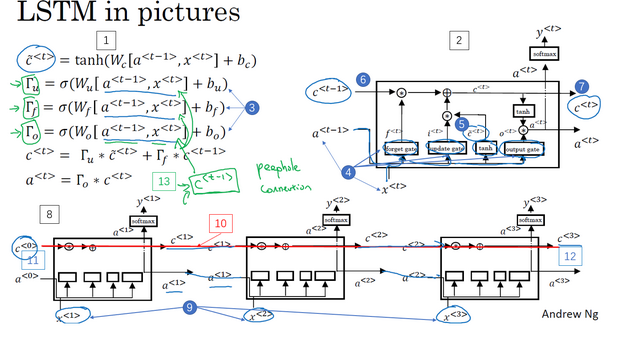
LSTM长短期记忆
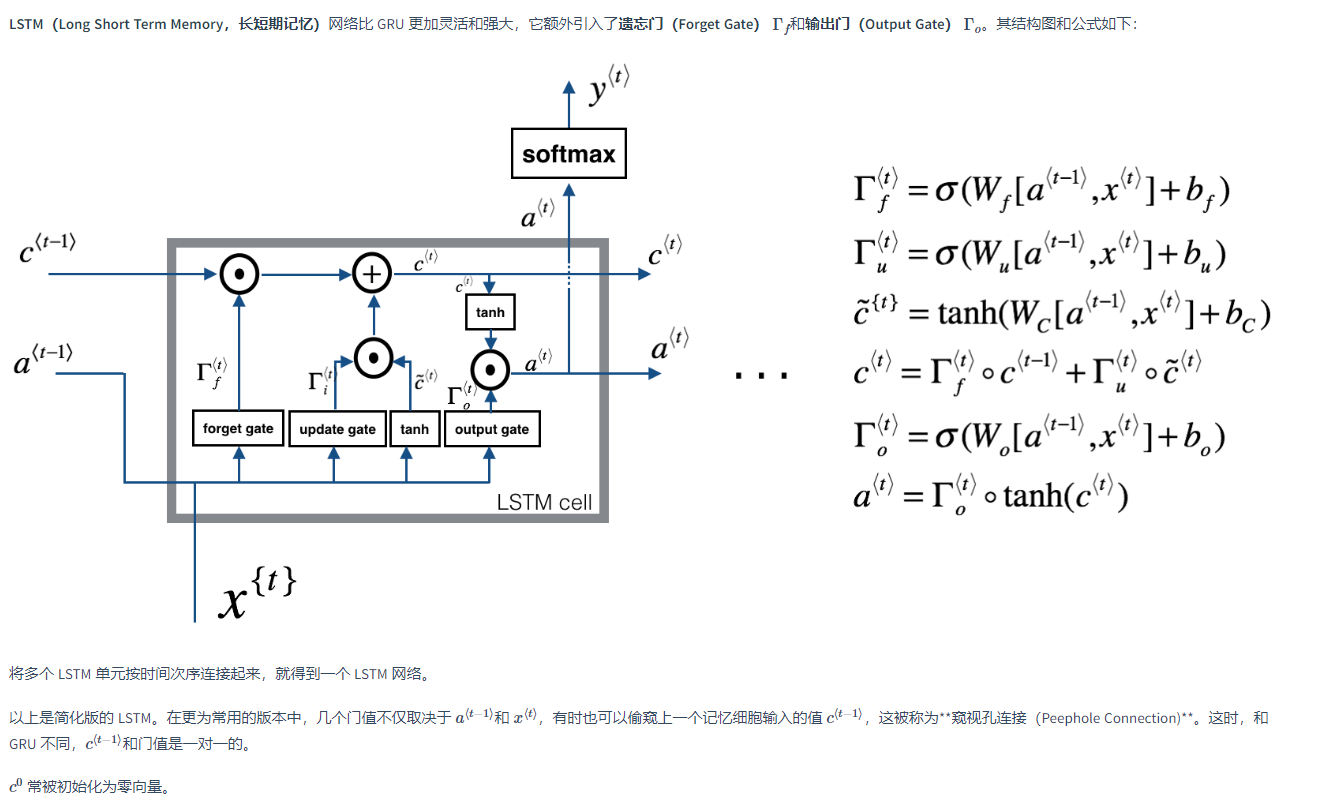
“窥视孔连接”(peephole connection):门值不仅取决于a<t−1>和x<t>,也取决于上一个记忆细胞的值c<t−1>,即c<t−1>也能影响门值
双向循环神经网络 Bidirectional RNN
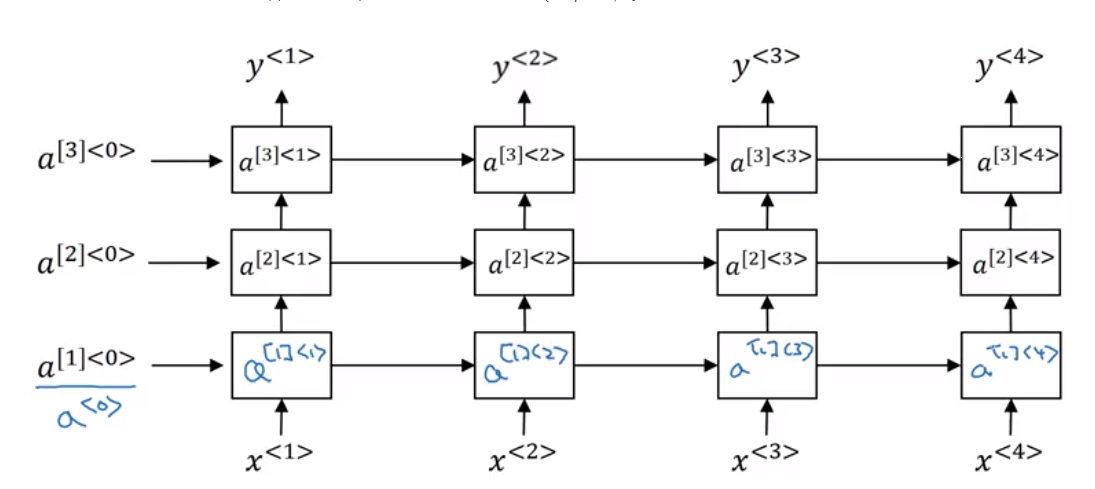
深层循环神经网络(多个隐藏层构成DRNN)
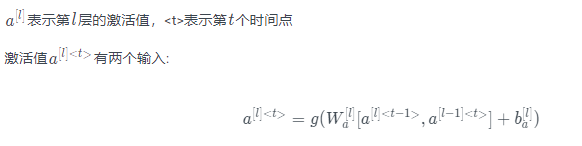


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现