机器学习第四章学习记录和心得
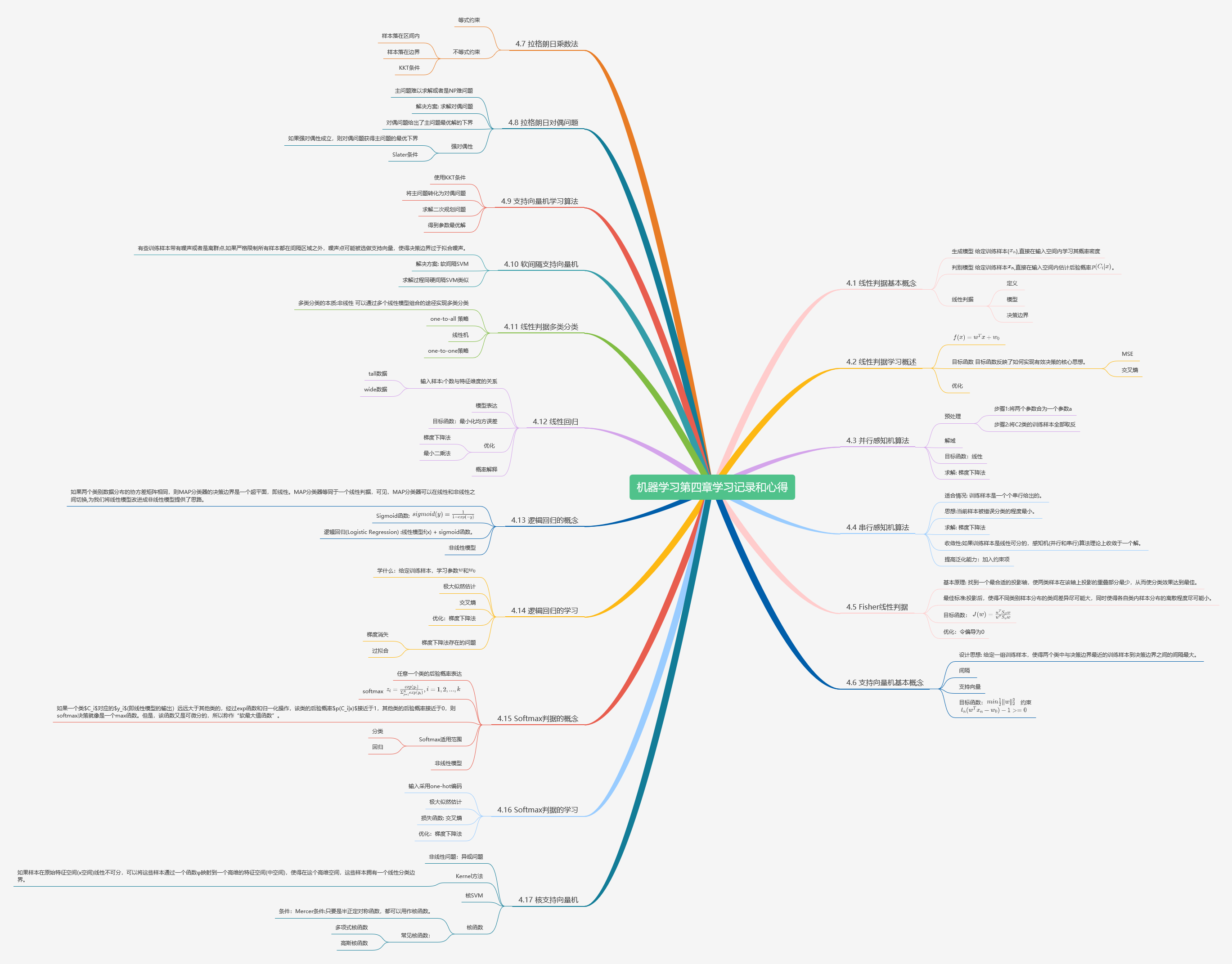
4.1 线性判据基本概念
-
判别模型:给定训练样本\({x_n}\),直接在输入空间内估计后验概率\(p(C_i|x)\)。
-
优势: 快速直接、省去了耗时的高维观测似然概率估计。
线性判据
定义: 如果判别模型f(x)是线性函数,则f(x)为线性判据。
- 可以用于两类分类,决策边界是线性的。
- 也可以用于多类分类,相邻两类之间的决策边界也是线性的。

- 决策边界
给定\(x_p\)表示任意样本\(x\)投影到决策边界的点\(r\)表示从\(x到\)x_p$ (即到决策边界)的距离(有正负) 则x可以重新表达:
4.2 线性判据学习概述
- 目标函数

- 目标函数的求解:最小化/最大化目标函数。
- 涉及优化技术。
- 解析求解:求关于训练参数的偏导,并设置偏导为0.
- 迭代求解:先猜测参数初始值,然后不断的根据当前计算得到的更新值迭代更新参数。
4.3 并行感知机算法
并行感知机
-
预处理
-

-
思想: 被错误分类的样本最少。被错误分类的样本,输出值\(f(y_n)\)是负数。
同时,根据几何意义,输出值的绝对值越大,错误的程度越大。 -
目标函数:针对所有被错误分类的训练样本(即输出值小于0的训练样本),其输出值取反求和:
\(J(a)=-\Sigma a^Ty, Y=\{y|a^Ty<=0\}\) -
该目标函数是关于a的一次线性函数。
求解
梯度下降法

更新的方向(正负) : 假设在k= 1迭代时刻,参数取值a1情况下,每个维度的梯度反方向就是该维度往目标函数最小值收敛的最速下降方向。
更新的大小:每个维度的梯度幅值代表参数在该维度上的更新程度。
通常加入步长来调整更新的幅度。每次迭代可以用不同的步长。
4.4 串行感知机算法
-
适合情况: 训练样本是一个个串行给出的。
-
目标函数
思想:当前样本被错误分类的程度最小。

收敛性
收敛性:如果训练样本是线性可分的,感知机(并行和串行)算法理论上收敛于一个解。
提高感知机泛化能力


4.5 Fisher线性判据
基本原理
找到一个最合适的投影轴,使两类样本在该轴上投影的重叠部分最少,从而使分类效果达到最佳。
最佳标准之一:投影后,使得不同类别样本分布的类间差异尽可能大,同时使得各自类内样本分布的离散程度尽可能小。

- 类间散度 \(S_b=(\mu_1-\mu_2)(\mu_1-\mu_2)^T\)
- 类内散度\(S_w=N_1\Sigma_1+N_2\Sigma_2\)
得到目标函数 \(J(w)=\frac{w^TS_Bw}{w^TS_ww}\)

最优解

4.6 支持向量机基本概念
- 设计思想: 给定一组训练样本,使得两个类中与决策边界最近的训练样本到决策边界之间的间隔最大。


- 目标函数 \(min\frac{1}{2}\Vert w\Vert^2_2\) 约束\(t_n(w^Tx_n+w_0)-1>=0\)
4.7 拉格朗日乘数法


-
不等式约束
KKT条件

4.8 拉格朗日对偶问题

-
主问题难以求解或者是NP难问题
-
解决方案: 求解对偶问题

- 对偶问题给出了主问题最优解的下界
强对偶性
- 如果强对偶性成立,则对偶问题获得主问题的最优下界
Slater条件
- \(f(x)\)是凸函数
- \(g_i(x)\)是凸函数
- \(h_j(x)\)是仿射函数
- 在可行域至少有一点使得不等式约束严格成立
4.9 支持向量机学习算法



- 该问题是一个二次优化问题,可以直接调用相关算法求解



4.10 软间隔支持向量机
有些训练样本带有噪声或者是离群点.如果严格限制所有样本都在间隔区域之外,噪声点可能被选做支持向量,使得决策边界过于拟合噪声。
解决方案: 软间隔SVM

求解过程同硬间隔SVM类似


4.11 线性判据多类分类
-
多类分类的本质:非线性
可以通过多个线性模型组合的途径实现多类分类
- one-to-all 策略
针对每个类\(C_i\) ,单独训练一个线性分类器\(f(x)= w^Tx + W_{i0}\)
每个分类器f(x)用来识别样本x是属于C1类还是不属于C2类。
设类别个数为K,总共需要训练K个分类器。

- 线性机

- one-to-one策略

4.12 线性回归


- 目标函数: 均方误差
\(minJ(W|x)=min\frac{1}{2}\Sigma_{n-1}^{N}\Vert t_n-W^Tx_n\Vert_2^2=min\frac{1}{2}\Vert T-XW\Vert_F^2\)

使用梯度下降法求解

或者直接得出最优解\(W=(x^TX)^{-1}X^TT\)
4.13 逻辑回归的概念
- 如果两个类别数据分布的协方差矩阵相同,则MAP分类器的决策边界是一个超平面,即线性。MAP分类器等同于一个线性判据,可见,MAP分类器可以在线性和非线性之间切换,为我们将线性模型改进成非线性模型提供了思路。


在每类数据是高斯分布且协方差矩阵相同的情况下,x属于C1 类的后验概率与属于C2类的后验概率之间的对数比率就是线性模型f (x)的输出。

在每类数据是高斯分布且协方差矩阵相同的情况下,由于Logit变换等同于线性判据的输出,所以在此情况下Logit(z)是线性的。
-
Sigmoid函数: \(sigmoid(y)=\frac{1}{1+exp(-y)}\)
-
逻辑回归


总结
-
逻辑回归本身是一个非线性模型。
-
逻辑回归用于分类:仍然只能处理两个类别线性可分的情况。但是,sigmoid函数输出了后验概率,使得逻辑回归成为一个非线性模型。因此,逻辑回归比线性模型向前迈进了一步。
-
逻辑回归用于拟合:可以拟合有限的非线性曲线。
4.14 逻辑回归的学习
给定训练样本,学习参数w和w。

- 极大似然估计

-
目标函数
\[log L(w,w_0|X)=\sum_{n=1}^{N}t_nlogz_n+(1-t_n)log(1-z_n) \]
由于log是凹函数,所以对目标函数取反。相应的,最大化变为最小化。

目标函数优化:梯度下降法
- 对参数w0求偏导


梯度消失问题
-
当\(y = w^Tx+w_0\)较大时,sigmoid函数输出z会出现饱和:输入变化量△y很大时,输出变化量△z很小。
-
在饱和区,输出量z接近于1,导致sigmoid函数梯度值接近于0,出现梯度消失问题。
过拟合问题
-
如果迭代停止条件设为训练误差为0,或者所有训练样本都正确分类的时候才停止,则会出现过拟合问题。
-
所以,在达到一定训练精度后,提前停止迭代,可以避免过拟合。
4.15 Softmax判据的概念
- 逻辑回归是由Logit变换反推出来的。
- 由Logit变换可知:正负类后验概率比率的对数是一个线性函数。
- 分类K个类,可以构建K个线性判据。第i个线性判据表示\(C_i\)类与剩余类的分类边界,剩余类用一个参考负类(reference class) \(C_k\)来表达。

Softmax函数
-
如果一个类\(C_i\)对应的\(y_i\)(即线性模型的输出)远远大于其他类的,经过exp函数和归一化操作,该类的后验概率\(p(C_i|x)\)接近于1,其他类的后验概率接近于0,则softmax决策就像是一个max函数。但是,该函数又是可微分的,所以称作“软最大值函数”。
-
Softmax判据:K个线性判据+ softmax函数。
-
Softmax适用范围:分类/回归
-
前提:每个类和剩余类之间是线性可分的。
-
范围:可以拟合指数函数(exp)形式的非线性曲线。

4.16 Softmax判据的学习


-
求解方式:极大似然估计


优化: 梯度下降法

4.17 核支持向量机
- 非线性问题:异或问题
Kernel方法的基本思想
如果样本在原始特征空间(x空间)线性不可分,可以将这些样本通过一个函数φ映射到一个高维的特征空间(中空间),使得在这个高维空间,这些样本拥有一个线性分类边界。

- 核函数:在低维x空间的一一个非线性函数,包含向量映射和点积功能,即作为x空间两个向量的度量,来表达映射到高维空间的向量之间的点积: \(K(x,x_k)=\Phi(x)^T\Phi(x_k)\)
核SVM

- 求解类似于SVM

- 核函数的条件:Mercer条件:只要是半正定对称函数,都可以用作核函数。
常见核函数:
-
多项式核函数

-
高斯核函数


 浙公网安备 33010602011771号
浙公网安备 33010602011771号