
tensorflow---识别图像特征(吴恩达课程)
tensorflow---识别图像特征
解决:确定一张图是否是鞋子
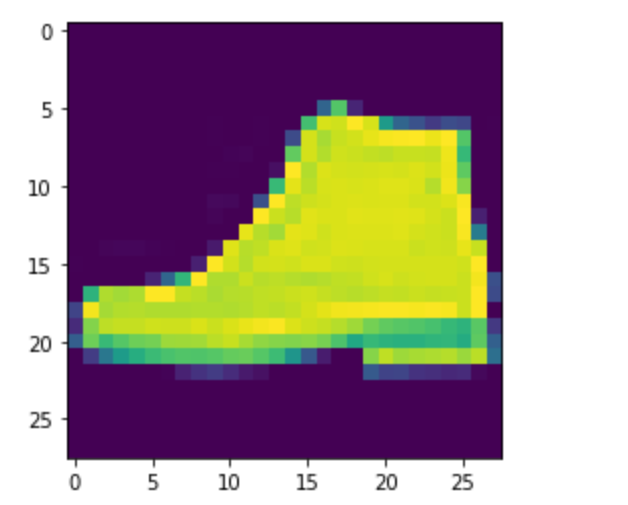
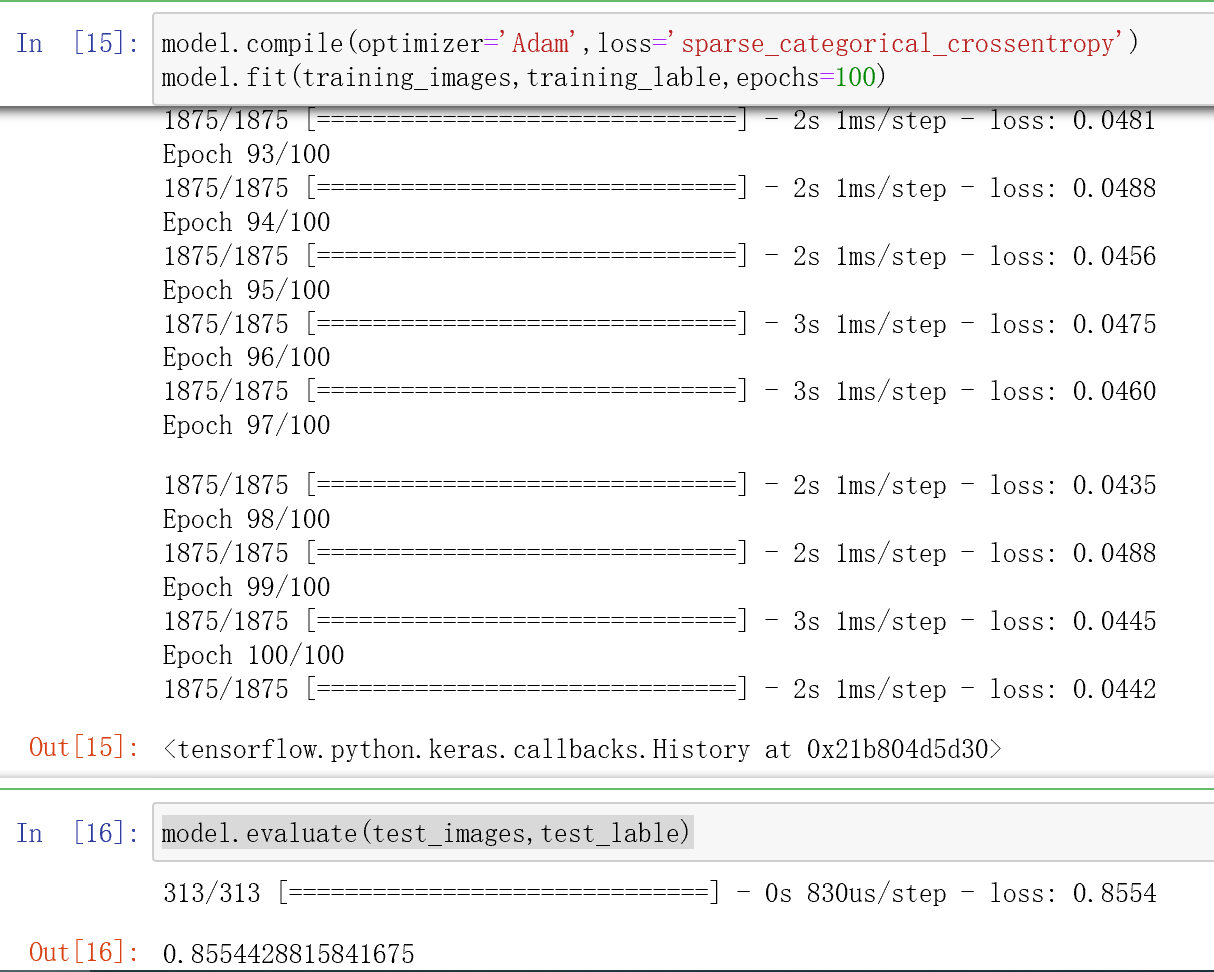
1 import matplotlib.pyplot as plt 2 import tensorflow as tf 3 #加载数据 4 mnist=tf.keras.datasets.fashion_mnist 5 (training_images,training_lable),(test_images,test_lable)=mnist.load_data() 6 #查看图片和数据 7 plt.imshow(training_images[42]) 8 print(training_lable[42]) 9 print(training_images[42]) 10 #标准化 11 training_images=training_images/255.0 12 test_images=test_images/255.0 13 #构建网络模型,自定义网络层 14 model=tf.keras.models.Sequential([tf.keras.layers.Flatten(), 15 tf.keras.layers.Dense(128,activation=tf.nn.relu), 16 tf.keras.layers.Dense(10,activation=tf.nn.softmax)]) 17 model.compile(optimizer='Adam',loss='sparse_categorical_crossentropy') 18 model.fit(training_images,training_lable,epochs=100) 19 #准确率 20 model.evaluate(test_images,test_lable)
注:
1、categorical_crossentropy loss(交叉熵损失函数)
交叉熵是用来评估当前训练得到的概率分布与真实分布的差异情况。
它刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近,不确定性越小,
准确率越高。
categorical_crossentropy 和 sparse_categorical_crossentropy 的区别
如果你的 targets 是 one-hot 编码,用 categorical_crossentropy
one-hot 编码:[0, 0, 1], [1, 0, 0], [0, 1, 0]
如果你的 tagets 是 数字编码 ,用 sparse_categorical_crossentropy
数字编码:2, 0, 1
2、Adam(自适应梯度下降法)
一种优化方式
附notebook_jupyter运行步骤结果:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号