Java八股复习指南-Redis
Redis基础:
Redis为什么快
- 基于内存,内存访问速度比磁盘快
- 基于Reactor 模式设计开发单线程事件模型和io多路复用
- 内置了多种优化的数据类型
- 通信协议实现简单且解析高效
Redis基本数据类型
String
-
需要存储常规数据的场景:缓存 Session、Token、图片地址、序列化后的对象(相比较于 Hash 存储更节省内存)。
-
需要计数的场景:用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数。
-
分布式锁:
SETNX key value
List
List 实现为一个双向链表
Hash
Hash 是一个 String 类型的 field-value(键值对) 的映射表,特别适合用于存储对象
Set
Set 类型是一种无序集合,集合中的元素没有先后顺序但都唯一
- 需要获取多个数据源交集、并集和差集的场景
- 需要随机获取数据源中的元素的场景
Sorted Set
和 Set 相比,Sorted Set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列
Redis持久化
使用缓存的时候,我们经常需要对内存中的数据进行持久化也就是将内存中的数据写入到硬盘中。因为Redis是存储在内存中,而每次重启内存中的数据都会丢失,因此需要通过一种方式将数据保存在磁盘中。
Redis支持三种持久化方式
- RDB:快照
- AOF:只追加文件,每次执行命令,都会写入AOF文件
- RDB和AOF的混合持久化
RDB持久化:
Redis可以通过创建快照来获得在内存里面的数据在某个时间点上的副本。
Redis提供了两个命令生成RDB快照
save:同步保存,会阻塞主线程bgsave:fork出一个子进程,子进程执行,不会阻塞Redis主线程。
生成快照时,如果执行的是bgsave命令,由于不会阻塞主进程,仍然可以修改redis中的数据。
这是因为:bgsave通过fork出一个子进程后,二者共用的一片内存地址,因此修改会同步进行。
AOF持久化
什么是AOF持久化
AOF持久化的实时性更好
开启AOF持久化后,每执行一条会更改Redis中的数据的命令,Redis就会将命令写入AOF缓冲区,然后再写入到AOF文件中,最后再根据持久化方式的配置决定何时同步到硬盘中。
AOF的工作流程
- 命令追加:将所有的写命令追加到AOF缓冲区。
- 文件写入:将AOF缓冲区的数据写入AOF文件。需要调用
write函数,将数据写入系统内核缓冲区之后直接返回。 - 文件同步:根据对应的持久化方式向硬盘做同步操作。这一步调用
fsync函数,强制刷新系统内核缓冲区,同步到硬盘。
可以是执行命令后立即写入,也可以定时1s写入,或者交给系统决定何时写入。差别就在宕机时丢失的数据多少了。 - 文件重写:随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的。
AOF存储的是每次执行的命令,当执行的命令越来越多,AOF文件就会越来越大,因此需要通过重写的方式进行压缩,重写的过程可以理解为:用一条命令达到几条命令同样的效果,以此压缩空间。 - 重启加载:当Redis重启时,可以加载AOF文件进行数据恢复。
重写的过程:
会有单独的子线程处理重写。在生成文件过程中,主进程仍在执行命令,为了与主进程保持一致,主进程会同步将命令写入重写缓冲区,以此进行同步。当执行重写操作时,主进程再将缓冲区的内容写入重写后的AOF文件,然后再覆盖原有的AOF文件
AOF重写
工作流程
- 创建快照
AOF会创建当前数据集的一个数据快照,并以最小的命令集合重写所有数据。也就是说,它能根据当前数据库状态生成能够重建当前数据的最小集合命令。
- 写入新文件
Redis将新生成的命令集合写入新的AOF文件,这样极大的缩减了文件的大小。
- 原子替换:
- 在重写过程中,Redis继续将新的写操作追加到现有AOF文件和新AOF文件中,确保在重写阶段数据不丢失。
- 重写完成后,用新的AOF文件代替旧AOF文件,这一操作是原子的,确保数据不丢失。完成重写
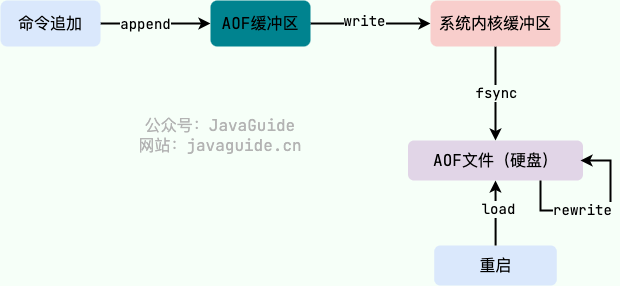
AOF在执行写命令后记录日志
关系型数据与Redis之所以不同,主要由于他们的设计目标和适用场景的差异
mysql在执行命令之前记录日志是因为:注重数据的完整性和一致性,虽然增加了写入操作的开销,但保证了数据的完整性和一致性,也方便了故障恢复到一致的状态。
Redis是在执行命令之后记录日志,要求最大限度提高性能,保证了高性能和低延时的特点。
好处
- 避免额外的检查开销,AOF记录日志不会对命令进行语法检查
- 在命令执行之后再记录日志,不会阻塞当前命令执行。
不足
- 如果刚执行完命令发生宕机,会导致对应的修改丢失
- 可能会阻塞后续其他命令的执行
混合持久化
即综合AOF与RDB两种持久化方式,在AOF文件中,前一部分是RDB内存快照的全量数据,而后一部分则是AOF日志的增量数据。
好处是当重新读取时,由于RDB速度更快,能更快加载数据,而在RDB加载完后,再执行AOF日志中的命令,这样就能综合二者的优势了。
Redis集群
如何实现服务高可用?
主从复制
将一台主服务器的数据复制到多台从服务器上。那么如何保持数据的一致性?
主服务器可以进行读写操作,而从服务器通常只执行读操作。当主服务器进行写操作后,再把写操作同步到从服务器。
无法保持强一致性。
哨兵模式
当主服务器宕机后,通过哨兵模式进行主从节点故障转移。主要是三点:
- 判断服务器是否宕机
- 选择一个从服务器作为主服务器
- 将更换主服务器的信息传达给其他从服务器以及客户端
如何判断是否宕机?
哨兵会定时向服务器发ping,因此判断是否宕机,为了防止某些网络不良等特殊情况,通常设置哨兵集群,即多个哨兵一起判断服务器是否宕机,这样就能避免怕判断失误。
如何进行故障转移
以下4个步骤:
- 在已下线的主服务器下选择一个从服务器作为新的主服务器
- 修改其他从服务器复制路径为新的主服务器
- 通知客户端主服务器的变更
- 监听已下线的主服务器,当该服务器上线时,将其改为从服务器
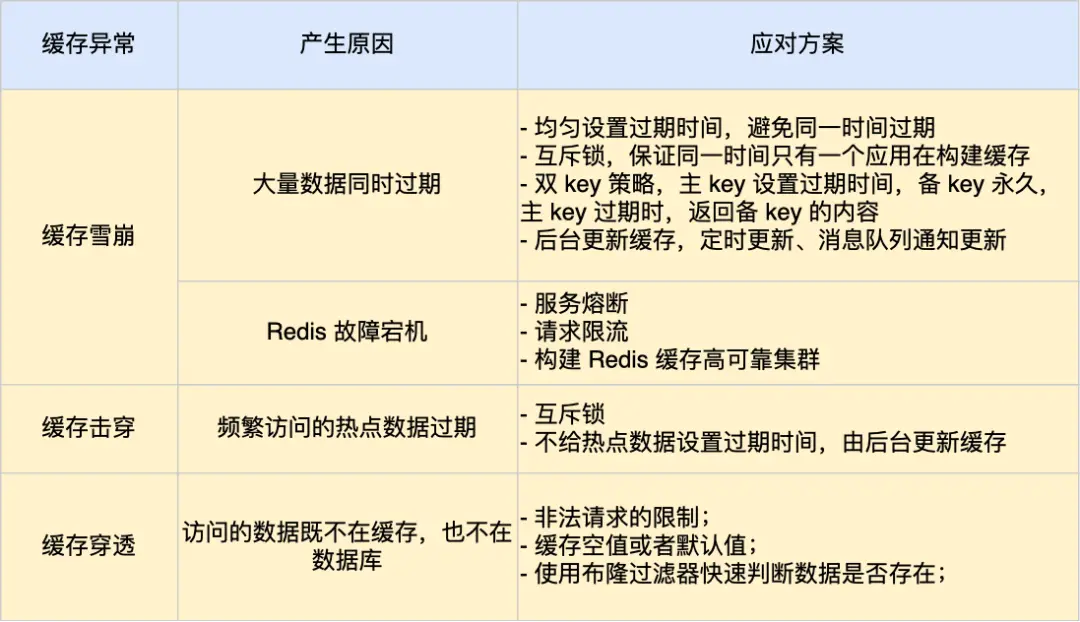
缓存问题
缓存与数据库保持一致性
结论:先更新数据库,再删除缓存
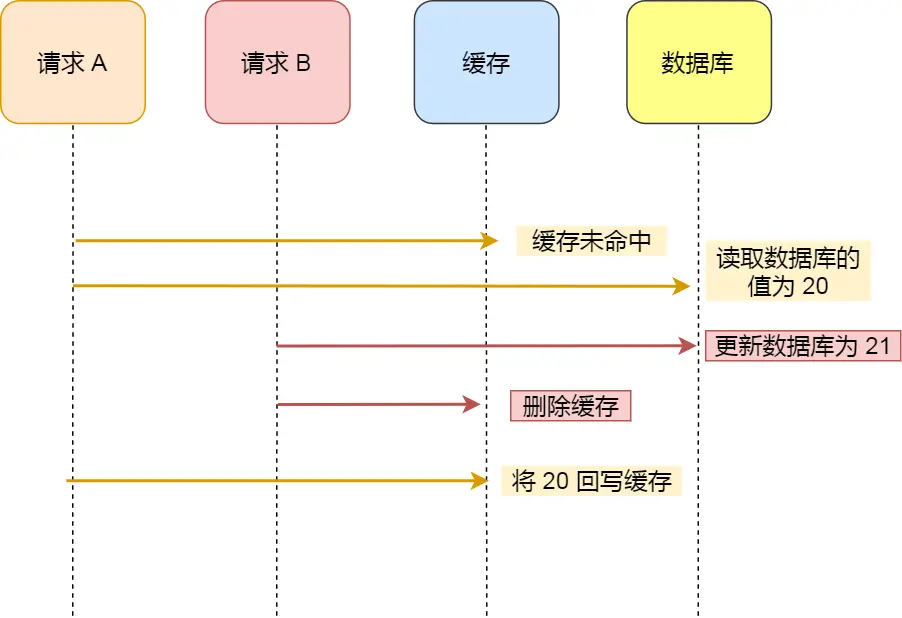
理论上仍然会存在不一致的情况。
然而实际上,由于写入缓存的速度比写入数据库的速度要快的多,基本不存在在写入缓存的过程中发生更新数据库等操作,因此可以保证数据一致。
如何确保两个操作都能执行成功?
无论是先操作数据库,还是先操作缓存,只要第二步操作失败,就会导致数据不一致。要确保两个操作均执行成功,有以下两种方法:
- 消息队列重试
将删除缓存要操作的数据放在消息队列中,由消费者来操作。
- 如果删除操作失败,则会从消息队列中取出数据重试删除操作,如果多次尝试还是失败,则会向业务层报错了。
- 如果操作成功,则会把数据从消息队列中移出。
缺点:这种方法对代码的侵入性比较强,需要改造原本业务的代码。
- 订阅Mysql binlog,再操作缓存
通过订阅Mysql binlog,在更新数据库后,binlog会记录更新操作。我们在订阅binlog后,通过将binlog中的日志信息采集发送到mq队列,如果操作失败,就从消息队列中取出事件,在成功删除缓存后,再向队列发送ACK处理这条log。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号