
生产者和消费者模式
生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发中,若生产者处理的速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完才能继续生产数据。同理,若消费者的处理能力大于生产者,那么消费者就必须等待生产者。生产者和消费者模式通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通信,而是通过阻塞队列来进行通信,所以生产者生产完之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
多生产者和多消费者场景
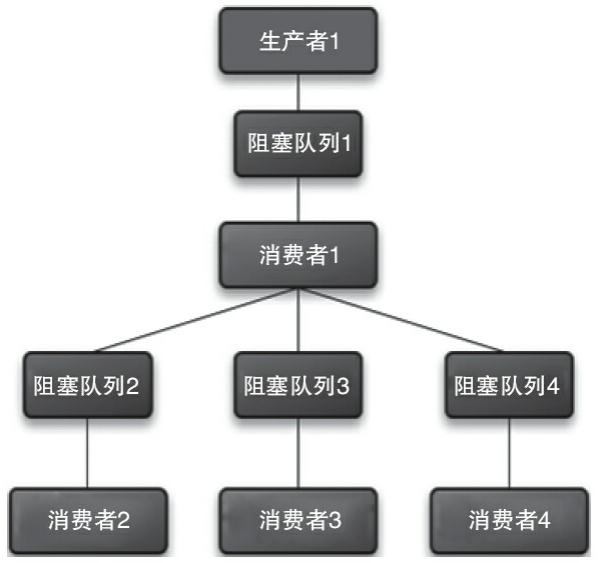
生产者1负责将所有客户端发送的消息存放在阻塞队列1里,消费者1从队列里读消息,然后通过消息ID进行散列得到N个队列中的一个,然后根据编号将消息存放到不同的队列里,每个阻塞队列会分配一个线程来消费阻塞队列里的数据。若消费者2无法消费消息,就将消息再抛回到阻塞队列1中,交给其他消费者处理。public class MsgQueueManager implements IMsgQueue{ private static final Logger LOGGER = LoggerFactory.getLogger(MsgQueueManager.class);
public final BlockingQueue<Message> messageQueue; private MsgQueueManager(){ messageQueue = new LinkedTransferQueue<Message>(); } public void put(Message msg){ try{ messageQueue.put(msg); }catch(InterruptedException e){ Thread.currentThread().interrupt(); } }
public Message take(){
try{
return messageQueue.take();
}catch(InterruptedException e){
Thread.currentThread().interrupt();
}
return null;
}
}
static class DispatchMessageTask implements Runnable{
public void run(){
BlockingQueue<Message> subQueue;
for(;;){
Message msg = MsgQueueFactory.getMessageQueue().take();
while((subQueue = getInstance().getSubQueue()) == null){
try{
Thread.sleep(1000);
}catch(InterruptedException e){
Thread.currentThread().interrupt();
}
}
try{
subQueue.put(msg);
}catch(InterruptedException e){
Thread.currentThread().interrupt();
}
}
}
}
使用Hash算法获取一个子队列
public BlockingQueue<Message> getSubQueue(){ int errorCount = 0; for(;;){ if(subMsgQueues.isEmpty()) return null; int index = (int) (System.nanoTime() % subMsgQueue.size()); try{ return subMsgQueue.get(index); }catch(Exception e){ LOGGER.error("fail to get sub queue", e); if((++errorCount) < 3) continue; } } }
CPU参数含义
us:用户空间占用CPU百分比
sy:内核空间占用CPU百分比
ni:用户进程内改变过优先级的进程占用CPU百分比
id:空闲CPU百分比
wa:等待输入/输出的CPU时间百分比
根绝TOP命令的显示结果,可能会出现以下3种情况:
1.某个线程CPU利用率一直100%,则说明这个线程可能会有死循环。用jstat查看下GC情。还可以把线程dump下来查看具体原因
2.某个线程一直在TOP10的位置,说明这个线程可能有性能问题
3.CPU利用率高和几个线程在不停变化,说明并不是由某一个线程导致CPU偏高
异步线程池
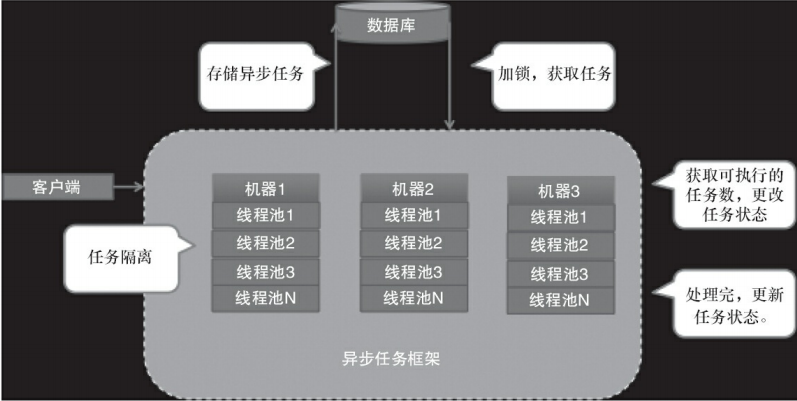
任务池的主要处理流程是每台机器会启动一个任务池,每个任务池里有多个线程池。当某台机器将一个任务交给任务池后,任务池会先将这个任务保存到数据中,然后某台机器上的任务池会从数据库中获取待执行的任务,再执行这个任务。每个人任务有几种状态,分别是创建(NEW),执行中(EXECUTING),重试(RETRY),挂起(SUSPEND),终止(TEMINER)和执行完成(FINISH)。
任务池的任务隔离。异步任务有很多种类型,不同类型的任务优先级是不一样,但是系统的资源是有限的,若低优先级的任务非常多,高优先级的任务可能就得不到执行,所以必须对任务进行隔离执行。使用不同的线程池处理不同的任务或不同的线程池处理不同优先级的任务,若任务类型非常少,建议用任务类型来隔离,若任务类型非常多,建议采用优先级的方式来隔离。
任务的重试策略。根据不同的任务类型设置不同的重试策略,有的任务对实时性要求高,那么每次的重试间隔就会非常短;若对实时性要求不高,可以采用默认的重试策略,重试间隔随着次数的增加,时间不断增长,比如间隔几秒,几分钟到几小时。每个任务类型可以设置执行该任务类型线程池的最小和最大线程数,最大重试次数。
使用任务池的注意事项。任务必须无状态:任务不能在执行任务的机器中保存数据,比如某个任务是处理上传的文件,任务的属性里有文件的上传路径,若文件上传到机器1,机器2获取到了任务就会失败,所以上传的文件必须存在其他的集群里,如OSS或SFTP。
异步任务的属性。包括任务名称,下次执行时间,已执行次数,任务类型,任务优先级和执行时的报错信息。
