1、说说你所知道的MySQL数据库存储引擎,InnoDB存储引擎和MyISM存储引擎的区别?
主要有
MyISM:MyISAM存储引擎:不支持事务、也不支持外键,优势是访问速度快,对事务完整性没有 要求或者以select,insert为主的应用基本上可以用这个引擎来创建表
InnoDB:支持事务
Memory:Memory存储引擎使用存在于内存中的内容来创建表。每个memory表只实际对应一个磁盘文件,格式是.frm。memory类型的表访问非常的快,因为它的数据是放在内存中的,并且默认使用HASH索引,但是一旦服务关闭,表中的数据就会丢失掉。
Merge:Merge存储引擎是一组MyISAM表的组合,这些MyISAM表必须结构完全相同,merge表本身并没有数据,对merge类型的表可以进行查询,更新,删除操作,这些操作实际上是对内部的MyISAM表进行的。
BLACKHOLE:黑洞存储引擎,可以应用于主备复制中的分发主库。
MyISM和InnoDB的区别
InnoDB支持事务,而MyISM不支持事务
InnoDB支持行级锁,而MyISM支持表级锁
InnoDB支持外键,而MyISM不支持
InnoDB支持全文索引,而MyISM不支持
InnoDB是索引组织表,MyISM是堆表 (堆表的数据是随机插入的,索引组织表的数据是有序的)
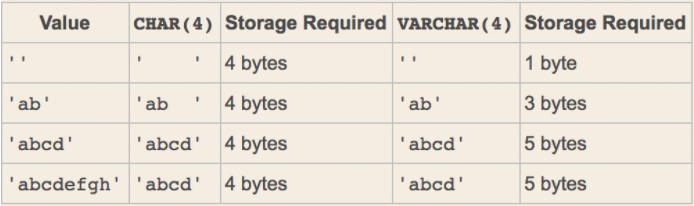
2、MySQL中char和varchar的区别,varchar(50)和char(50)分别代表什么意思?
char(50): 定长,字符的长度为50,浪费空间,存取速度快,数据不足时,会往右填充空格来满足长度。
varchar(50): 变长,字符的长度为50,节省空间,存取速度慢,存储数据的真实内容,不会填充空格,且会在真实数据前加1-2bytes,表示真实数据的bytes字节数。
length:查看字节数
char_length:查看字符数
1. char填充空格来满足固定长度,但是在查询时却会很不要脸地删除尾部的空格(装作自己好像没有浪费过空间一样),然后修改sql_mode让其现出原形
2. 虽然 CHAR 和 VARCHAR 的存储方式不太相同,但是对于两个字符串的比较,都只比 较其值,忽略 CHAR 值存在的右填充,即使将 SQL _MODE 设置为 PAD_CHAR_TO_FULL_ LENGTH 也一样
3、MySQL中int类型存储多少个字节?
int存储4字节 有符号:(-2147483648,2147483647)
无符号:(0,4294967295)
4、主键具有什么特征?
不为空为唯一
5、简述你对inner join、left join、right join、full join的理解;
多表连接查询: inner join: 内连接,只连接匹配的行,找两张表共有的部分; left join: 外连接之左连接,优先显示左表全部记录,在内连接的基础上增加左表有右表没有的结果; right join: 外连接之右连接,优先显示右表全部记录,在内连接的基础上增加右表有左表没有的结果; full join: = left join on union right join on ... mysql 不支持full join 但是可以用 union ... 全外连接,显示左右两个表全部记录,在内连接的基础上增加左表有右表没有和右表有左表没有的结果;
6、concat, group_concat函数的作用是什么?
定义显示格式: concat() 用于连接字符串 eg: select concat('姓名:',name,'年薪:',salasy*12) as annual_salary from employee;
concat_ws() 第一个参数为分隔符 eg: select concat_ws(':',name,salary*12) as annual_salary from employee; group by 与 group_concat() 函数一起使用 select post,group_concat(name) as emp_members from employee group by post;
一、concat()函数 1、功能:将多个字符串连接成一个字符串。 2、语法:concat(str1, str2,...) 返回结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null。
例1:select concat (id, name, score) as info from tt2;
二、concat_ws()函数
1、功能:和concat()一样,将多个字符串连接成一个字符串,但是可以一次性指定分隔符~(concat_ws就是concat with separator)
2、语法:concat_ws(separator, str1, str2, ...)
说明:第一个参数指定分隔符。需要注意的是分隔符不能为null,如果为null,则返回结果为null。
三 group_concat()函数
1、功能:将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
2、语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator '分隔符'] )
说明:通过使用distinct可以排除重复值;如果希望对结果中的值进行排序,可以使用order by子句;separator是一个字符串值,缺省为一个逗号。
7、请介绍事务的实现原理;
事务:用于将某些操作的多个sql作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据的完整性。
原子性:一堆sql语句,要么同时执行成功,要么同时失败!
8、索引的本质是什么?索引有什么优点,缺点是什么?
索引是帮助MySQL高效获取数据的数据结构。因此,索引的本质是一种数据结构。
在数据之外,数据库系统还可以维护满足特定查找算法的数据结构,这些数据结构以某种方式指向真实数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
优点:
1、提高数据检索效率,降低数据库的IO成本;
2、通过索引对数据进行排序,降低了数据排序的成本,降低了CPU的利用率;
缺点:
1、索引实际上也是一张表,索引会占用一定的存储空间;
2、更新数据表的数据时,需要同时维护索引表,因此,会降低insert、update、delete的速度;
9、哪些情况下需要创建索引,哪些情况下不需要创建索引?
1、主键自动创建唯一非空索引;
2、频繁作为查询条件的字段应该创建索引;
3、频繁更新的字段不适合简历索引,因为每次更新不仅仅更新数据表同时还会更新索引表;
4、查询中经常排序的字段,可以考虑创建索引;
5、如果某个字段的重复数据较多,不适合创建普通索引;
10、请分别介绍ACID代表的意思,什么业务场景需要支持事务,什么业务场景不需要支持事务?
ACID,指数据库事务正确执行的四个基本要素的缩写。
包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
一个支持事务(Transaction)的数据库,必须要具有这四种特性,否则在事务过程(Transaction processing)当中无法保证数据的正确性。
使用场景:
银行的交易系统
eg:
start transaction;
update user set balance = 900 where name = 'wsb'; #买支付100元
update user set balance = 1010 where name = 'egon'; #中介拿走10元
uppdate user set balance = 1090 where name = 'ysb'; #卖家拿到90元,出现异常没有拿到
rollback;
commit;
11、什么是触发器,请简述触发器的使用场景?
使用触发器可以定制用户对表进行【增、删、改】操作时前后的行为,注意:没有查询。 触发器无法由用户直接调用,而知由于对表的【增/删/改】操作被动引发的。 eg: create trigger tri_before_insert_tb1 before insert on tb1 for each row begin ... end
12、什么是存储过程,存储过程的作用是什么?
存储过程包含了一系列可执行的sql语句,存储过程存放于MySQL中,通过调用它的名字可以执行其内部的一堆sql。 优点: 1. 用于替代程序写的SQL语句,实现程序与sql解耦 2. 基于网络传输,传别名的数据量小,而直接传sql数据量大 缺点: 1. 程序员扩展功能不方便 eg: delimiter // create procedure p1() begin select * from blog; insert into blog(name,sub_time) values('xxx',now()); end // delimiter ;
13、什么是视图,简单介绍视图的作用和使用场景?
视图是一个虚拟表(非真实存在),其本质是【根据SQL语句获取动态的数据集,并为其命名】, 用户使用时只需使用【名称】即可获取结果集,可以将该结果集当做表来使用。 视图取代复杂的sql语句,方便用来查询。 eg: create view teacher_view as select tid from teacher where tname='李平老师';
14、如何查看SQL语句的执行计划?


http://blog.itpub.net/12679300/viewspace-1394985/ 执行计划的查看是进行数据库的sql语句调优时依据的一个重要依据. eg: explain select * from class; +----+-------------+-------+------+---------------+------+---------+------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-------+ | 1 | SIMPLE | class | ALL | NULL | NULL | NULL | NULL | 12 | NULL | +----+-------------+-------+------+---------------+------+---------+------+------+-------+ Id:包含一组数字,表示查询中执行select子句或操作表的顺序; 执行顺序从大到小执行; 当id值一样的时候,执行顺序由上往下; Select_type:表示查询中每个select子句的类型(简单OR复杂),有以下几种: SIMPLE:查询中不包含子查询或者UNION PRIMARY:查询中若包含任何复杂的子部分,最外层查询则被标记为PRIMARY SUBQUERY:在SELECT或WHERE列表中包含了子查询,该子查询被标记为SUBQUERY DERIVED:在FROM列表中包含的子查询被标记为DERIVED(衍生) 若第二个SELECT出现在UNION之后,则被标记为UNION; 若UNION包含在FROM子句的子查询中,外层SELECT将被标记为:DERIVED 从UNION表获取结果的SELECT被标记为:UNION RESULT Type:表示MySQL在表中找到所需行的方式,又称“访问类型”,常见有以下几种: ALL:Full Table Scan, MySQL将进行全表扫描; index:Full Index Scan,index与ALL区别为index类型只遍历索引树; range:range Index Scan,对索引的扫描开始于某一点,返回匹配值域的行,常见于between、<、>等的查询; ref:非唯一性索引扫描,返回匹配摸个单独值的所有行。常见于使用非唯一索引或唯一索引的非唯一前缀进行的查找; eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描 const、system:当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量 NULL:MySQL在优化过程中分解语句,执行时甚至不用访问表或索引 possible_keys:指出MySQL能使用哪个索引在表中找到行,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用; key:显示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL。当查询中若使用了覆盖索引,则该索引仅出现在key列表中 key_len:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度 ref:表示上述表的连接匹配条件,即那些列或常量被用于查找索引列上的值; rows:表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数; Extra:包含不适合在其他列中显示但十分重要的额外信息; Using where:表示MySQL服务器在存储引擎受到记录后进行“后过滤”(Post-filter),如果查询未能使用索引,Using where的作用只是提醒我们MySQL将用where子句来过滤结果集 Using temporary:表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询; Using filesort:MySQL中无法利用索引完成的排序操作称为“文件排序”;
15、在你本地数据库中查看select from student*的执行计划,并解释每个字段分别代表什么意思?
ysql> explain select * from student; +----+-------------+---------+------+---------------+------+---------+------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+---------+------+---------------+------+---------+------+------+-------+ | 1 | SIMPLE | student | ALL | NULL | NULL | NULL | NULL | 16 | NULL | +----+-------------+---------+------+---------------+------+---------+------+------+-------+ id: 表示查询中执行select子句或操作表的顺序。 select_type: simple 表示查询中不包含子查询或者union table: student type: all 表示mysql将进行全表扫描 possible_keys: 指出MySQL能使用哪个索引在表中找到行,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用; key: 显示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL。当查询中若使用了覆盖索引,则该索引仅出现在key列表中; ey_len:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度; ref:表示上述表的连接匹配条件,即那些列或常量被用于查找索引列上的值; rows:表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数; Extra:包含不适合在其他列中显示但十分重要的额外信息;
16、数据备份分为哪几种类型?增量备份和差异备份的区别是什么?
完整备份:备份系统中的所有数据。特点:占用空间大,备份速度慢,但恢复时一次恢复到位,恢复速度快。
增量备份:只备份上次备份以后有变化的数据。
特点:因每次仅备份自上一次备份(注意是上一次,不是第一次)以来有变化的文件,
所以备份体积小,备份速度快,但是恢复的时候,需要按备份时间顺序,逐个备份版本进行恢复,恢复时间长。
差异备份:只备份上次完全备份以后有变化的数据。
特点:占用空间比增量备份大,比完整备份小,恢复时仅需要恢复第一个完整版本和最后一次的差异版本,恢复速度介于完整备份和增量备份之间。
简单的讲,完整备份就是不管三七二十一,每次都把指定的备份目录完整的复制一遍,不管目录下的文件有没有变化;
增量备份就是每次将之前(第一次、第二次、直到前一次)做过备份之后有变化的文件进行备份;
差异备份就是每次都将第一次完整备份以来有变化的文件进行备份。
17、请介绍select语句的执行顺序;
from
where
group by
having
select
distinct
order by
limit
说明:
1.找到表:from
2.拿着where指定的约束条件,去文件/表中取出一条条记录
3.将取出的一条条记录进行分组group by,如果没有group by,则整体作为一组
4.将分组的结果进行having过滤
5.执行select
6.去重
7.将结果按条件排序:order by
8.限制结果的显示条数
18、请问存储引擎MyISM和InnoDB的适合什么样的使用场景?
Innodb与Myisam引擎的区别与应用场景:
1. 区别:
(1)事务处理:
MyISAM是非事务安全型的,而InnoDB是事务安全型的(支持事务处理等高级处理);
(2)锁机制不同:
MyISAM是表级锁,而InnoDB是行级锁;
(3)select ,update ,insert ,delete 操作:
MyISAM:如果执行大量的SELECT,MyISAM是更好的选择
InnoDB:如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表
(4)查询表的行数不同:
MyISAM:select count(*) from table,MyISAM只要简单的读出保存好的行数,注意的是,当count(*)语句包含 where条件时,两种表的操作是一样的
InnoDB : InnoDB 中不保存表的具体行数,也就是说,执行select count(*) from table时,InnoDB要扫描一遍整个表来计算有多少行
(5)外键支持:
mysiam表不支持外键,而InnoDB支持
2. 为什么MyISAM会比Innodb 的查询速度快。
INNODB在做SELECT的时候,要维护的东西比MYISAM引擎多很多;
1)数据块,INNODB要缓存,MYISAM只缓存索引块, 这中间还有换进换出的减少;
2)innodb寻址要映射到块,再到行,MYISAM 记录的直接是文件的OFFSET,定位比INNODB要快
3)INNODB还需要维护MVCC一致;虽然你的场景没有,但他还是需要去检查和维护
MVCC ( Multi-Version Concurrency Control )多版本并发控制
3. 应用场景
MyISAM适合:(1)做很多count 的计算;(2)插入不频繁,查询非常频繁;(3)没有事务。
InnoDB适合:(1)可靠性要求比较高,或者要求事务;(2)表更新和查询都相当的频繁,并且行锁定的机会比较大的情况。
19、请举出MySQL中常用的几种数据类型;
mysql常用数据类型:
1.数值类型:
整数类型:tinyint smallint int bigint
浮点型:float double decimal
float :在位数比较短的情况下不精准(一般float得精确度也够用了)
double :在位数比较长的情况下不精准
0.000001230123123123
存成:0.000001230000
decimal:(如果用小数,则推荐使用decimal)
精准 内部原理是以字符串形式去存
2.日期类型:
最常用:datetime year date time datetime timestamp
3.字符串类型:
char(6) varchar(6)
char(10):简单粗暴,浪费空间,存取速度快,定长;
root存成root000000
varchar:精准,节省空间,存取速度慢,变长;
sql优化:创建表时,定长的类型往前放,变长的往后放
比如性别 比如地址或描述信息
>255个字符,超了就把文件路径存放到数据库中。
比如图片,视频等找一个文件服务器,数据库中只存路径或url。
4.枚举类型与集合类型:
enum('male','female') # 性别(单选)
set('play','music','read','study')# 爱好(多选)
20、什么情况下会产生笛卡尔乘积,如何避免?
交叉连接:不适用任何匹配条件。生成笛卡尔积; select * from employee,department; 避免: select employee.id,employee.name,employee.age,employee.sex,department.name from employee,department where employee.dep_id=department.id;
21、请列举MySQL中常用的函数;
聚合函数:
聚合函数聚合的是组的内容,若是没有分组,则默认一组
count()
max()
min()
avg()
sum()
22、请说明group by的使用场景;
什么是分组,为什么要分组?
1、首先明确一点:分组发生在where之后,即分组是基于where之后得到的记录而进行的
2、分组指的是:将所有记录按照某个相同字段进行归类,比如针对员工信息表的职位分组,或者按照性别进行分组等
3、为何要分组呢?
取每个部门的最高工资
取每个部门的员工数
取男人数和女人数
小窍门:‘每’这个字后面的字段,就是我们分组的依据
4、大前提:
可以按照任意字段分组,但是分组完毕后,比如group by post,只能查看post字段,如果想查看组内信息,需要借助于聚合函数
23、请介绍hash索引和B+树索引的实现原理;
哈希索引基于哈希表实现,只有精确匹配索引的所有列的查询才有效。对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码,哈希码
是一个较小的值,并且不同键值的行计算出来的哈希码也不一样。哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行
的指针。也就是说,由于哈希查找比起B-Tree索引,其本身对于单行查询的时间复杂度更低,有了哈希索引后明显可加快单行查询速度。 但是哈希索引也有它自己的限制: 哈希索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行。不过,访问内存中的行的速度很快,所以大部分情
况下这一点对性能的影响并不明显。 哈希索引数据并不是按照索引值顺序存储的,所以也就无法用于排序。 哈希索引也不支持部分索引列匹配查找,因为哈希索引始终是使用索引列的全部内容来计算哈希值的。例如,在数据列(A, B)上建立哈希索引,
如果查询只有数据列A,则无法使用该索引。 哈希索引只支持等值比较查询,包括=、in()、<=>。不支持任何范围查询,例如where price > 100。 访问哈希索引的数据非常快,除非有很多哈希冲突。如果哈希冲突很多的话,一些索引维护操作的代价也很高。 B+树索引是B树索引的变体,本质上也是多路平衡查找树
编程题:
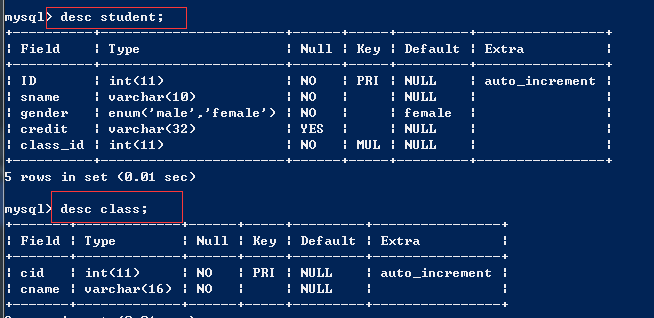
1、创建一个表student,包含ID(学生学号),sname(学生姓名),gender(性别),credit(信用卡号),四个字段,要求:ID是主键,且值自动递增,sname是可变长字符类型,gender是枚举类型, credit是可变长字符类型;
1. 是否允许为空,默认NULL,可设置NOT NULL,字段不允许为空,必须赋值 2. 字段是否有默认值,缺省的默认值是NULL,如果插入记录时不给字段赋值,此字段使用默认值 sex enum('male','female') not null default 'male' age int unsigned NOT NULL default 20 必须为正值(无符号) 不允许为空 默认是20
create table student( ID int primary key auto_increment, sname varchar(10) not null, gender enum('male','female') not null default 'female', credit varchar(32) );
2、在上面的student表中增加一个名为class_id的外键,外键引用class表的cid字段;
create table 表名( 字段名1 类型[(宽度) 约束条件], 字段名2 类型[(宽度) 约束条件], 字段名3 类型[(宽度) 约束条件] ); #注意: 1. 在同一张表中,字段名是不能相同 2. 宽度和约束条件可选 3. 字段名和类型是必须的 语法: 1. 修改表名 ALTER TABLE 表名 RENAME 新表名; 2. 增加字段 ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…], ADD 字段名 数据类型 [完整性约束条件…]; ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…] FIRST; ALTER TABLE 表名 ADD 字段名 数据类型 [完整性约束条件…] AFTER 字段名; 3. 删除字段 ALTER TABLE 表名 DROP 字段名; 4. 修改字段 ALTER TABLE 表名 MODIFY 字段名 数据类型 [完整性约束条件…]; ALTER TABLE 表名 CHANGE 旧字段名 新字段名 旧数据类型 [完整性约束条件…]; ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新数据类型 [完整性约束条件…];
create table class( cid int primary key auto_increment, cname varchar(16) not null ); create table student add class_id int not null; alter table student add foreign key(class_id) references class(cid) on delete cascade on update cascade;
3、向该表新增一条数据,ID为1,学生姓名为alex,性别女,修改ID为1的学生姓名为wupeiqi,删除该数据;
先建立被关联的表 在建立表 insert into class values(1,'一班'),(2,'二班'); insert into student values(1,'alex','female','123',1); update student set sname='wupeiqi' where ID=1; delete from student where ID=1;
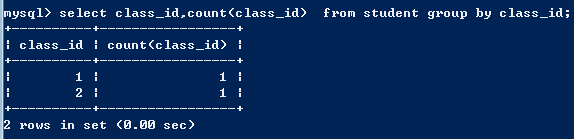
4、查询student表中,每个班级的学生数;
insert into student(sname,class_id) values('alex',1),('egon',2); select class_id,count(class_id) from student group by class_id;
5、修改credit字段为unique属性;
alter table student modify credit varchar(32) unique;
4. 修改字段
ALTER TABLE 表名
MODIFY 字段名 数据类型 [完整性约束条件…];
ALTER TABLE 表名
CHANGE 旧字段名 新字段名 旧数据类型 [完整性约束条件…];
ALTER TABLE 表名
CHANGE 旧字段名 新字段名 新数据类型 [完整性约束条件…];
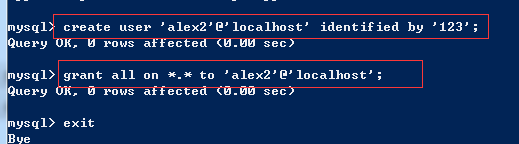
6、请使用命令在你本地数据库中增加一个用户,并给该用户授予创建表的权限;
复制代码 权限管理 1、创建账号 # 本地账号 create user 'egon1'@'localhost' identified by '123'; # mysql -uegon1 -p123 # 远程帐号 create user 'egon2'@'192.168.31.10' identified by '123'; # mysql -uegon2 -p123 -h 服务端ip create user 'egon3'@'192.168.31.%' identified by '123'; # mysql -uegon3 -p123 -h 服务端ip create user 'egon3'@'%' identified by '123'; # mysql -uegon3 -p123 -h 服务端ip 2、授权 权限控制力度依次降低 user:*.* db:db1.* tables_priv:db1.t1 columns_priv:id,name # 库级别 grant all on *.* to 'egon1'@'localhost'; # 授权grant *.* 授权所有级别 grant select on *.* to 'egon1'@'localhost'; revoke select on *.* from 'egon1'@'localhost'; # 回收权限revoke 授权库 grant select on db1.* to 'egon1'@'localhost'; revoke select on db1.* from 'egon1'@'localhost'; 授权表 grant select on db1.t2 to 'egon1'@'localhost'; revoke select on db1.t2 from 'egon1'@'localhost'; # 回收权限 授权表下的字段 grant select(id,name),update(age) on db1.t2 to 'egon1'@'localhost';
分步: 创建用户:create user 'alex2'@'localhost' identified by '123'; 授权: grant all on *.* to 'alex2'@'localhost' 一步到位: grant create on *.* to 'alex'@'localhost' identified by '123';
先登录全部授权的管理员账户 mysql -uroot -p123
----------------------------------------------------------------------------------------------------------------------------
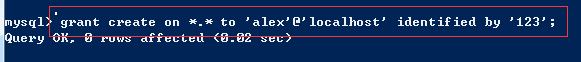
7、请使用pymsql模块连接你本地数据库,并向student表中插入一条数据;
import pymysql conn = pymysql.connect( host='127.0.0.1',#连接本机在本机上测试 port=3306, user='root', password='123', db='db1', charset='utf8' ) #游标 cursor=conn.cursor() # 1 增加一条记录 # sql = 'insert into student(sname,class_id) values(%s,%s)' # rows=cursor.execute(sql,('dd',2)) # print(rows) # 增加多条记录 # sql = 'insert into student(sname,class_id) values(%s,%s)' # rows=cursor.executemany(sql,[('a1',2),('a2',1),('a3',1)]) # print(rows) # conn.commit() # cursor.close() # conn.close() # 3 查询 # sql2='select * from student' # cursor.execute(sql2) # # print(cursor.fetchone()) # 每次只取一条记录 # # print(cursor.fetchmany(2)) #再上一次查询基础上取出指定的条数 # print(cursor.fetchall()) # 也是再上一次查询基础上取出剩余的 # cursor.close() # conn.close() # 4 删除 要提交 sql='delete from student where ID=8' rows=cursor.execute(sql) print(rows) conn.commit() cursor.close() conn.close()
8、请使用mysqldump命令备份student表;
1.导出整个数据库 mysqldump -u用户名 -p密码 数据库名 > 导出的文件名 例如:C:\Users\jack> mysqldump -uroot -pmysql sva_rec > e:\sva_rec.sql

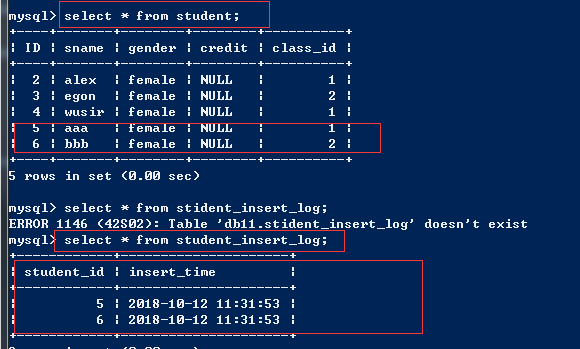
9、创建一张名为student_insert_log的表,要求每次插入一条新数据到student表时,都向student_insert_log表中插入一条记录,记录student_id, insert_time;
都向student_insert_log表中插入一条记录,记录student_id, insert_time; # 创建表 create table student_insert_log(student_id int not null,insert_time datetime not null); # 创建一个触发器 delimiter // create trigger tri_after_insert_student after insert on student for each row begin insert into student_insert_log values(new.ID,now()); end // delimiter ; insert into student(sname,class_id) values ('aaa',1),('bbb',2);
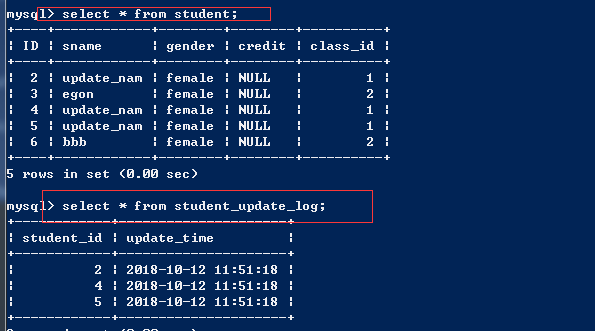
10、创建一张名为student_update_log的表,要求每次更新student表中的记录时,都向student_update_log表中插入一条记录,记录student_id, update_time;
# 创建表 create table student_update_log(student_id int not null,update_time datetime not null); # 创建触发器 delimiter // create trigger tri_after_update_student after update on student for each row begin insert into student_update_log values(new.ID,now()); end // delimiter; update student set sname='update_name' where class_id=1;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号