#------------知识点整理-------------------
1、字符编码

- UTF-8: 使用1、2、3、4个字节表示所有字符;优先使用1个字符、无法满足则使增加一个字节,最多4个字节。英文占1个字节、欧洲语系占2个、东亚占3个,其它及特殊字符占4个。
总结:UTF 是为unicode编码 设计 的一种 在存储 和传输时节省空间的编码方案。
* 存到硬盘上时是以何种编码存的,再从硬盘上读出来时,就必须以何种编码读,要不然就乱了。
encode 编码-------------------------------------decode 解码
*中国的windows,默认编码依然是gbk,而不是utf-8。
*python 3 以utf-8编码 utf-8编码之所以能在我们的windows gbk的终端下显示正常,是因为到了内存里python解释器把utf-8转成了unicode
>>> u = '中文' # 指定字符串类型对象u
>>> str1 = u.encode('gb2312') # 以gb2312编码对u进行编码,获得bytes类型对象
>>> print(str1)
b'\xd6\xd0\xce\xc4'
>>> u1 = str1.decode('gb2312') # 以gb2312编码对字符串str进行解码,获得字符串类型对象
>>> print('u1')
'中文'
>>> u2 = str1.decode('utf-8') # 报错,因为str1是gb2312编码的
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd6 in position 0: invalid continuation byte
bit 位,计算机中最小的表示单位
8bit = 1bytes 字节,最小的存储单位,1bytes缩写为1B
1KB=1024B
1MB=1024KB
ascll码表:只能对英文和若干类似语言进行编码(2的8次方)
8位---------1个字节,可以存放256个字符
Unicode码表:国际标准字符集,把所有语言都统一到一套编码里(2的32次方)
32位--------4个字节
UTF-8编码:就是一种压缩编码方式,针对常见字符使用8位,其他的使用32位或者16位,ascii码中的内容用1个字节保存,欧洲的字符用2个字节保存,东亚的字符用3个字节保存。
windowns系统中文版默认编码是GBK
Mac os\Linux系统默认编码是UTF-8
电脑中x64表示64位系统,反之则是32位系统
十进制转换成八进制和十六进制的方法,分别是oct和hex。八进制前面以‘0o’标示,十六进制以‘0x’标示
>>> bin(10) '0b1010' >>> oct(10) '0o12' >>> hex(10) '0xa'
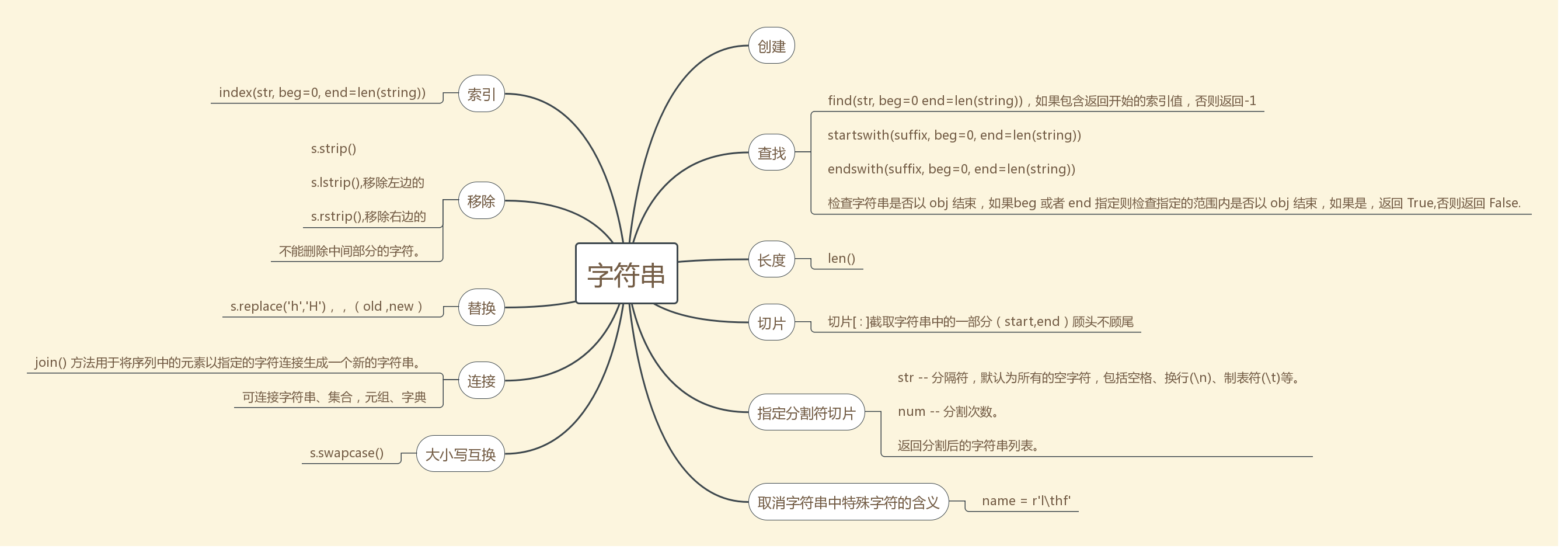
#字符串的操作 1、创建:#单引号、双引号、三引号 s = 'hello' 2、索引: index(str, beg=0, end=len(string)) s.index('e') ==1 跟find()方法一样,只不过如果str不在字符串中会报一个异常. 3、查找 find(str, beg=0 end=len(string)) 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 s.find('e') == 1 s.find('i') == -1 if i.startswith('a') : startswith(suffix, beg=0, end=len(string)) endswith(suffix, beg=0, end=len(string)) 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. 4、移除 strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。 s.strip() s.lstrip(),移除左边的 s.rstrip(),移除右边的 5、长度 len() 6、替换 replace s.replace('h','H'),,(old ,new)
s = 'hello word' s = s.replace(' ', '%20') print(s)
7、切片[ : ]截取字符串中的一部分(start,end)顾头不顾尾 实际end-1 8、 join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。 '-'.join(sequence)函数中的 sequence 中的元素必须的字符串,否则会报错,可连接字符串、集合,元组、字典 9、isdigit() 如果字符串只包含数字则返回 True 否则返回 False.. 11、split()通过指定分隔符对字符串进行切片 str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。 num -- 分割次数。 返回分割后的字符串列表。 12、大小写互换s.swapcase() 13、r/R 取消字符串中特殊字符的含义 name = r'l\thf'
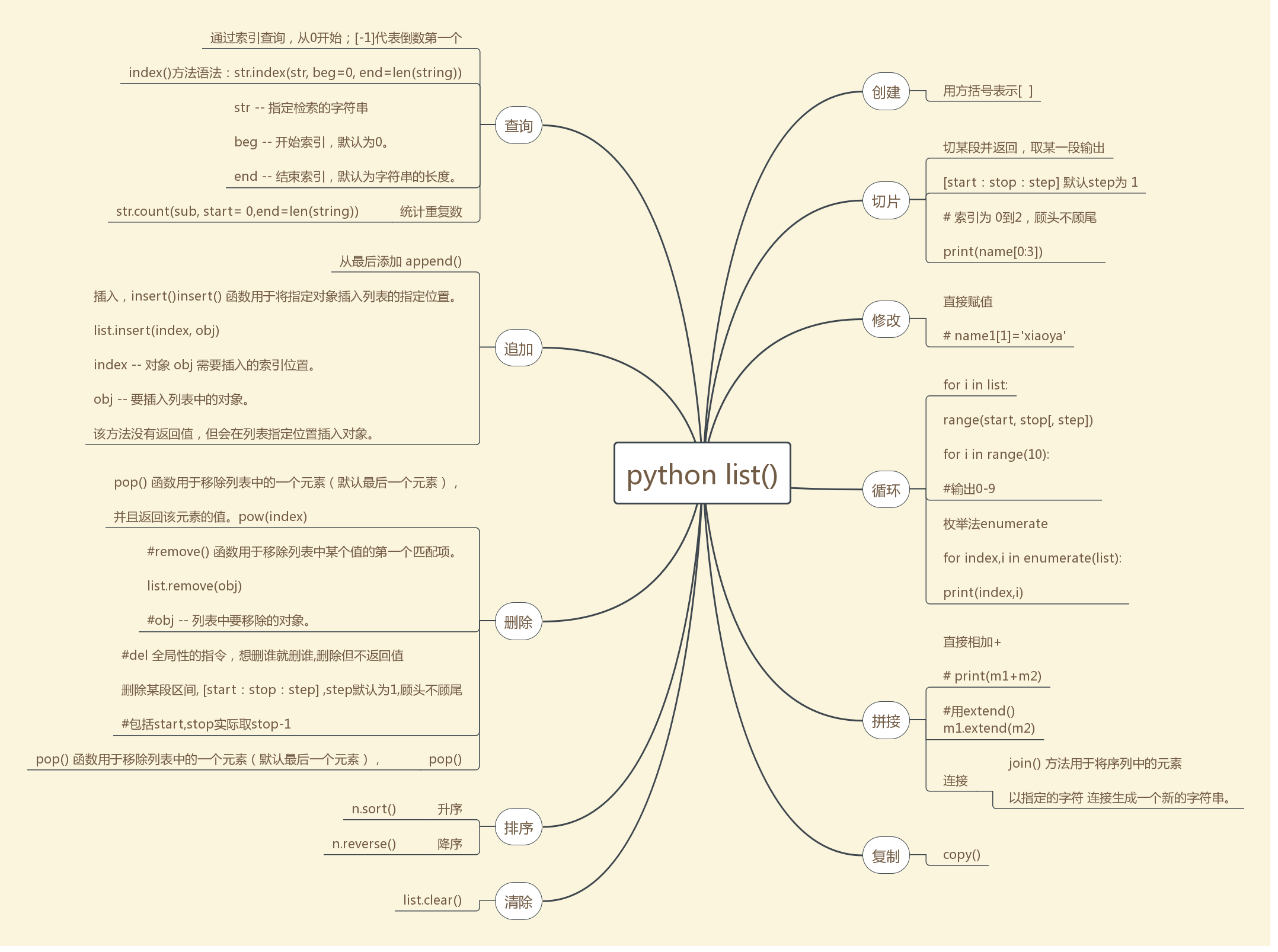
#--------列表总结----------
1、创建 list_test = ['aa',11,'ss' ] 方括号,以逗号分隔,按照索引存放各种数据类型 2、追加 list.append(obj) list.insert(index,obj) 3、连接 join() 方法用于将序列中的元素
以指定的字符 连接生成一个新的字符串。 s = ['hello','python'] print('!'.join(s)) -----> hello!python------>字符串输出 4、列表无----------分割 split() 5、索引 list.index('aa') ------>0 6、切片 [start:stop:step] 默认step为 1,顾头不顾尾 7、删除: pop() 函数用于移除列表中的一个元素(默认最后一个元素), remove() 函数用于移除列表中某个值的第一个匹配项。 list.remove(obj) del 全局性的指令,想删谁就删谁,删除但不返回值 删除具体某个值,或者区间值 8、统计count()重复出现的子字符的个数, str.count(sub, start= 0,end=len(string)) 9、循环 range(start, stop[, step]) 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5) 计数到 stop 结束,但不包括 stop step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1) # for i in range(10): # #输出0-9 # print(i) 10、升序排列 sort,降序排列n.reverse() 11、两个列表拼接: (1)直接相加+ (2)list.extend(seq) 12、清除clear() 13、复制 copy()
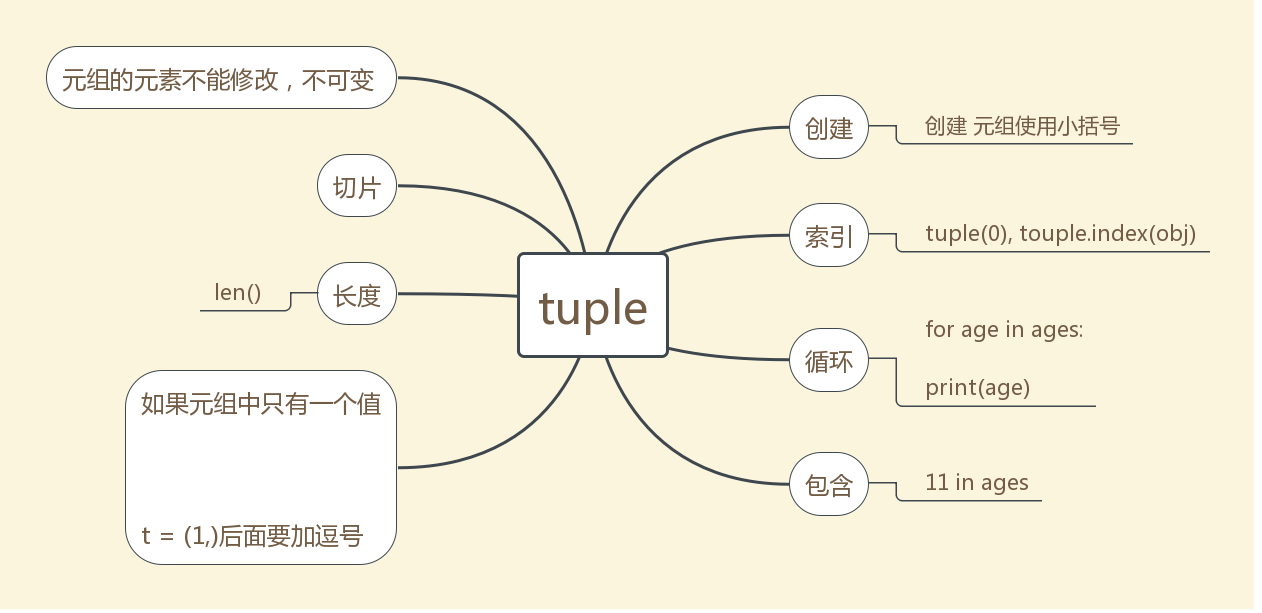
#---------元组- tuple--------- 元组的元素不能修改,不可变 1、创建 元组使用小括号 ages = (11, 22, 33, 44, 55) 2、索引 print(ages.index(11))------〉0 print(ages[0]) ------> 11 3、切片 同list 4、循环: for age in ages: print(age) 5、长度 len() 6、包含 11 in ages----->True 7、元组的特性详解 如果元组中只有一个值 t = (1,)后面要加逗号 元组中不仅可以存放数字、字符串,还可以存放更加复杂的数据类型 元组本身不可变,如果元组中还包含其他可变元素,这些可变元素可以改变 ages = (11, 22, 33, 44, 55,['aa','bb']) ages[5][0] = 22 print(ages)------> (11, 22, 33, 44, 55, [22, 'bb'])
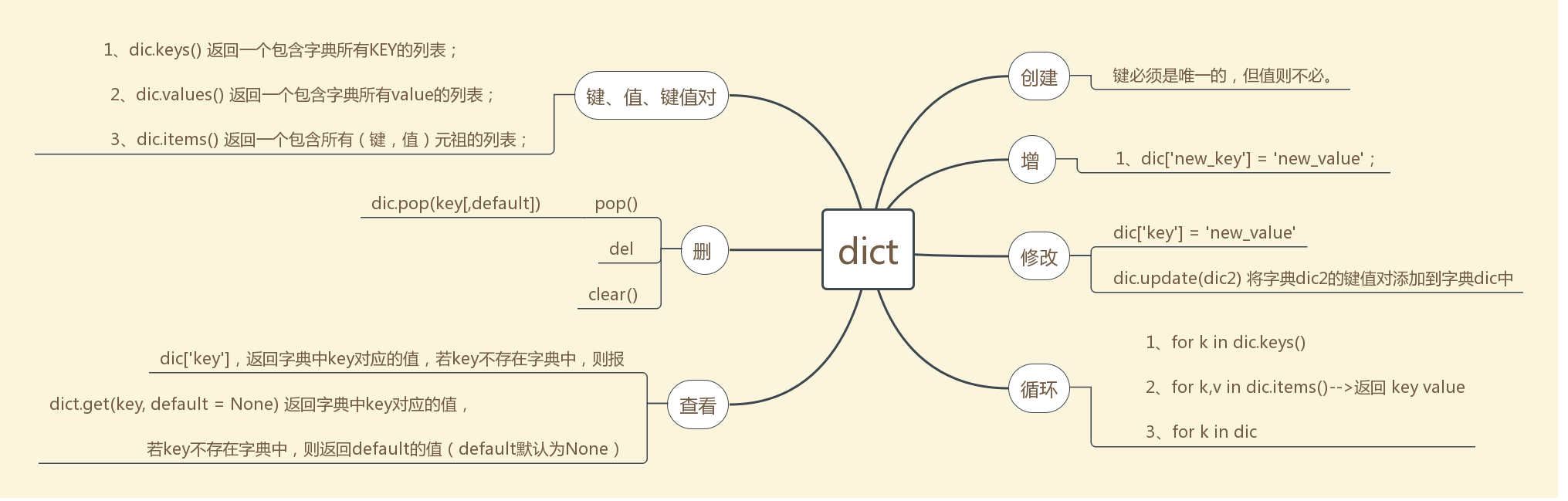
#---------------------字典总结----------------------------- 1、创建 d = {key1 : value1, key2 : value2 } 键必须是唯一的,但值则不必。 值可以取任何数据类型, 键必须是不可变的,如字符串,数字或元组。 2、键、值、键值对 1、dic.keys() 返回一个包含字典所有KEY的列表; 2、dic.values() 返回一个包含字典所有value的列表; 3、dic.items() 返回一个包含所有(键,值)元祖的列表; d = {'key1' : 'value1', 'key2' : 'value2' } print(d.items())------>dict_items([('key1', 'value1'), ('key2', 'value2')]) 3、新增 1、dic['new_key'] = 'new_value'; 2、dic.setdefault(key, None) ,如果字典中不存在Key键,由 dic[key] = default 为它赋值; 4、删除 1、dic.pop(key[,default]) 和get方法相似。如果字典中存在key,删除并返回key对应的vuale;如果key不存在,且没有给出default的值,则引发keyerror异常; key: 要删除的键值 default: 如果没有 key,返回 default 值 2、dic.clear() 删除字典中的所有项或元素;
3、del 5、修改 1、dic['key'] = 'new_value',如果key在字典中存在,'new_value'将会替代原来的value值; 2、dic.update(dic2) 将字典dic2的键值对添加到字典dic中 6、查看 1、dic['key'],返回字典中key对应的值,若key不存在字典中,则报错; 2、dict.get(key, default = None) 返回字典中key对应的值,若key不存在字典中,则返回default的值(default默认为None) 7、循环 1、for k in dic.keys() 2、for k,v in dic.items() 3、for k in dic d = {'key1' : 'value1', 'key2' : 'value2' } print(d.items()) for k,v in d.items(): print(k,v) #------------------------------------ dict_items([('key1', 'value1'), ('key2', 'value2')]) key1 value1 key2 value2 #--------------------------------- for k in d: print(k) for k in d.keys(): print(k) 这两种是一个结果都是输出 key的值 #----------------------- 8、长度 1、len(dic)
长度代表key 的个数
#---------------------集合总结--set------------------------ 集合(set)是一个无序不重复元素的序列。 1、创建 可以使用大括号 { } 或者 set() 函数创建集合 2、集合中的元素有三个特征: 1.确定性(元素必须可hash) 2.互异性(去重) 3.无序性(集合中的元素没有先后之分),如集合{3,4,5}和{3,5,4}算作同一个集合。 注意:集合存在的意义就在于去重和关系运算 l= {'张三','李四','老男孩'} p = {'张三','李四','alex'} 3、集合的关系运算: 交集 l&p 并集 l|p 差集 l-p 对称差集:l^p,,老男孩,alex 包含关系 in,not in:判断某元素是否在集合内 ==,!=:判断两个集合是否相等 两个集合之间一般有三种关系,相交、包含、不相交。在Python中分别用下面的方法判断: set.isdisjoint(s):判断两个集合是不是不相交 set.issuperset(s):判断集合是不是包含其他集合,等同于a>=b set.issubset(s):判断集合是不是被其他集合包含,等同于a<=b 4、元素的增加 单个元素的增加 : add(),add的作用类似列表中的append 对序列的增加 : update(),而update类似extend方法,update方法可以支持同时传入多个参数: >>> a={1,2} >>> a.update([3,4],[1,2,7]) >>> a {1, 2, 3, 4, 7} >>> a.update("hello") >>> a {1, 2, 3, 4, 7, 'h', 'e', 'l', 'o'} >>> a.add("hello") >>> a {1, 2, 3, 4, 'hello', 7, 'h', 'e', 'l', 'o'} 元素的删除 集合删除单个元素有两种方法: 元素不在原集合中时: set.discard(x)不会抛出异常 set.remove(x)会抛出KeyError错误 >>> a={1,2,3,4} >>> a.discard(1) >>> a {2, 3, 4} >>> a.discard(1) >>> a {2, 3, 4} >>> a.remove(1) Traceback (most recent call last): File "<input>", line 1, in <module> KeyError: 1 pop():由于集合是无序的,pop返回的结果不能确定,且当集合为空时调用pop会抛出KeyError错误, clear():清空集合 >>> a={3,"a",2.1,1} >>> a.pop() >>> a.pop() >>> a.clear() >>> a set() >>> a.pop() Traceback (most recent call last): File "<input>", line 1, in <module> KeyError: 'pop from an empty set'
悟已往之不谏,知来者之可追。
