SPSS基础分析
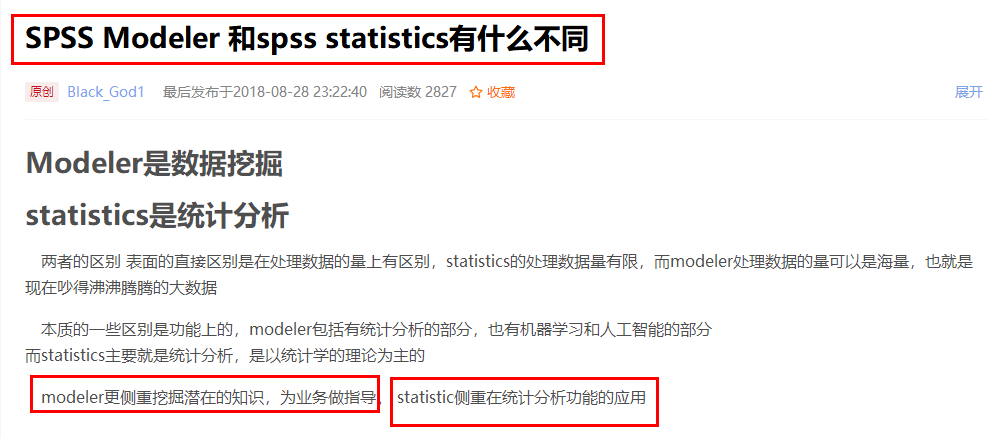

SPSS基础分析
SPSS预分析
建模分析
案例分析
第一章 数据分析基础知识
什么是数据分析?
什么是数据分析?
统计学( Statistics )
收集、处理、分析、解释数据,并从数据中得出结论来指导实际生活和生产。分为描述统计学和推断统计学。
其中,描述性统计研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法;推断统计是研究如何利用样本数据进行推断总体的特征。
数据分析( Data Analysis )
用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论,对数据加以详细研究和概括总结的过程。
数据类型有哪些?
数据类型
分类数据(定性数据)
只能归于某一类别的非数字型数据,是对事物进行分类的结果数据,表现为类别,用文字来表示。
如人口按性别分为男、女;高中教育,分为文科、理科。
顺序数据
只能归于某一有序类别的非数字型数据,数据表现为类别,但这些类别是有序的。如产品分为一等品,二等品,三等品,次品等;奖学金。
数值型数据
对事物的精确测度,结果表现为具体的数值。如身高175CM,160CM,183CM;微信运动步数。
注:日期型数据用于表示日期或时间,可以进行算数运算,是一种特殊的数值型数据。
基础概念了解吗?
平均数(算术平均数)、几何平均数(mean)
算术平均数:An=(a1+a2+...+an)/n
几何平均数:Gn=(a1a2...an)^(1/n)
中位数(median)、众数(mode)
四分位数、四分位差
对数据进行排序,处于25%和75%位置上的值。如1、8、3、2、5、5、4、7、2,2和6处于这组数据的25%和75%位置,为这组数据的下四分位数和上四分位数,也成1/4分位数和3/4分位数。
四分位差=上四分位数-下四分位数
异众比例
非众数的个数占总个数的比例。 如1、2、4、4、5、6、4、8。
极差=最大值-最小值
平均差
各变量值与平均数离差绝对值的平均数。
平均差 = (∑|x-x’|)÷n,
例如1、2、3、4、5、6、7、8,平均差为?
方差、标准差:反映一个数据集的离散程度,用σ表示标准差。
方差 s=[(x1-x)^2 +(x2-x)^2 +(xn-x)^2]/n
总体:所研究的全部元素的集合。
样本:从总体中抽取的一部分元素的集合。其中样本的元素数目成为样本容量。
参数:描述总体的特征。如总体均值、标准差、总体比例等。
统计量:描述样本特征。如样本标准差,样本均值等。
变量:被观察单位的特征,是指可变的数量标志和所有的统计指标。在校生人数、商品销售额、产品质量等级...等都是变量。
举例:
对一千个灯泡进行寿命测试,从中抽取一百个进行检测。则这一千个灯泡的集合就是总体,一百个灯泡的集合就是样本
。这一千个灯泡的寿命的平均值、标准差、合格率等描述特征的数值就是参数,
这一百个灯泡的寿命的平均值、标准差、合格率等描述特征的数值就是统计量,寿命就是变量。
第二章 SPSS软件概述
SPSS发展简史
SPSS的基本特点

SPSS的安装与激活

SPSS的启动与退出
SPSS界面介绍
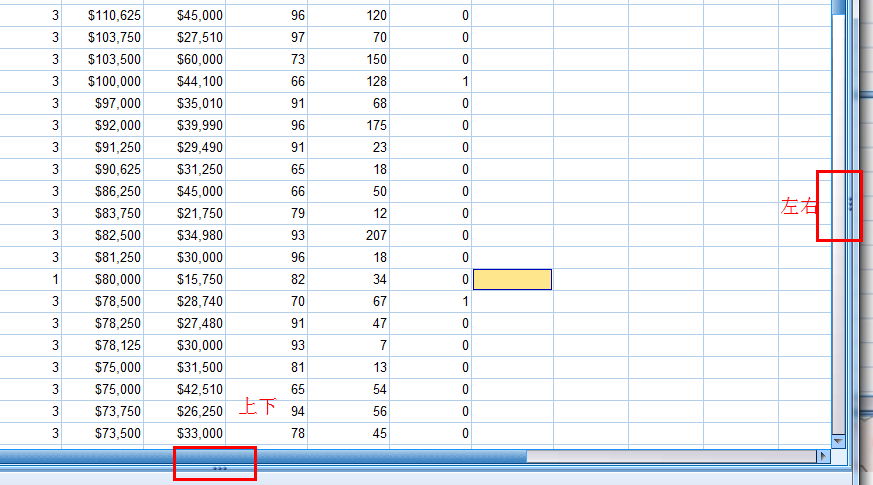
分屏操作:出现左后符号拉动即可,上下左右
spss文件保存格式 .sav格式
第三章 数据的导入与录入
数据的种类:
1.一种是已经被录入为其他数据格式的资料,实现其与SPSS文件的转换。
例如:如何直接读取Excel类型和文本格式的数据,demo.xls,demo.txt
2.另一种是非电子化的原始数据资料,直接将调查问卷中的数据录入
SPSS,建立数据文件。
练习
练习:
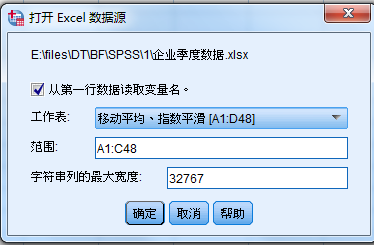
1.将企业季度数据.xlsx 的移动平均、指数平滑表导入SPSS中,仅包含:时间、销售额、推广费用几个变量;
总共四列信息,包含前三列信息
2.将用户明细.txt文件导入到SPSS中并保存成用户明细.sav的格式
数据录入技巧
连续多个相同值的输入
用“复制、选择、粘贴”功能
成批变量的定义
隔开指定的距离输入首尾行,回车后自动填充变量名
快速查找异常值(极端值)
充分利用排序功能
数据的录入的步骤:
1.定义变量名
2.指定每个变量的各种属性
3.录入数据
4.随时存盘以防断电
变量属性
数据类型:分类、顺序、数值
数值型
应用最为广泛,如工资、年龄、成绩等都可定义为数值型
字符型(分类型变量)
也是SPSS较常用的数据类型,但由于分析、整理都较困难,建议尽量少用,改为编码录入,如性别用1、2代表男女,用变量值标签加以解释说明
日期型
实际上是特殊的数值型变量,尽量少用。日期型数据主要在时间序列分析中比较有用,在较为简单的分析问题中完全可以用数值型变量进行操作:如201610
调查问卷的数据录入
调查问卷的数据录入
问卷调查的方法用的很广泛,对于没有接触过SPSS的人来说第一步面临的就是问卷数据录入的问题。
注意:
(1)区分变量的度量,Measure的值,其中Scale是定量、Ordinal是定序、Nominal是指定类;
(2)注意定义不同的数据类型Type。
问卷数据的录入
问卷题目的类型大致:
(1)单选 (2)多选 (3)排序 (4)开放题目
它们的变量的定义和处理的方法各有不同。
点击视图,值标签打勾

单选题:答案只能有一个选项
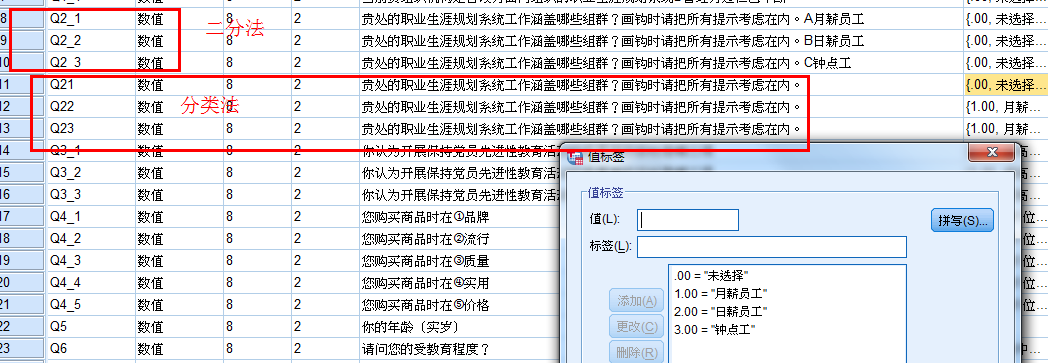
1.当前贵组织机构是否设有面向组织的职业生涯规划系统?
A有 B 正在开创 C没有 D曾经有过但已中断
编码:只定义一个变量,Value值1、2、3、4分别代表A、B、C、D 四个选项。
录入:录入选项对应值,如选C则录入3。
采用分类法或者二分法录入信息

多选题:答案可以有多个选项,其中又有项数不定多选和项数定多选
方法一(二分法):在编码时,对应每一个选项都要定义一个变量,有几个选项就有几个变量,且所有变量值标签的定义应该一致
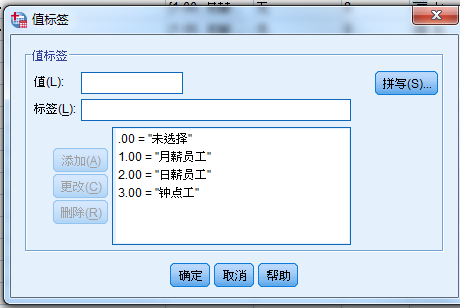
例:贵处的职业生涯规划系统工作涵盖哪些组群?画钩时请把所有提示考虑在内。
A月薪员工 B日薪员工 C钟点工
编码:把每一个相应选项定义为一个变量,每一个变量Value值均如下定义:“0” 未选,“1” 选。
录入:被调查者选了的选项录入1、没选录入0,如被调查者选AC,则三个变量分别录入为1、0、1。
分类法:多选有未选的用 0来填充
定向多选择题
多选题:答案可以有多个选项,其中又有项数不定多选和项数定多选
方法二(分类法):利用多个变量来对一个多选题的答案进行定义,应该用多少个变量由被访者实际可能给出的最多答案数而定。
这些变量必须为数值型变量,利用值标签将答案标出,所有变量采用一套值标签。
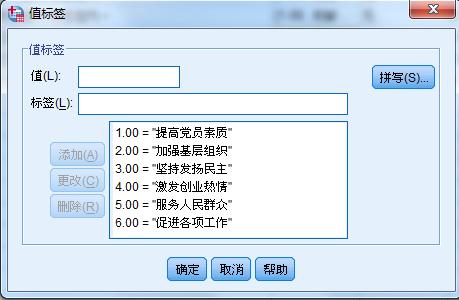
例:你认为开展保持党员先进性教育活动的最重要的目标是哪三项:1() 2() 3()
A、提高党员素质 B、加强基层组织 C、坚持发扬民主
D、激发创业热情 E、服务人民群众 F、促进各项工作
编码:定义三个变量分别代表题目中的1、2、3三个括号,三个变量Value值均同样的以对应的选项定义,
即:“1”A,“2”B,“3”C,“4”D,“5”E,“6”F
录入:录入的数值1、2、3、4、5、6分别代表ABCDEF,相应录到每个括号对应的变量下。如被调查者三个
括号分别选ACF,则在三个变量下分别录入1、3、6。

总结:
单选题分类法
不定项多选题分类法或者二分法
定向多选题分类法

排序题:对选项重要性进行排序
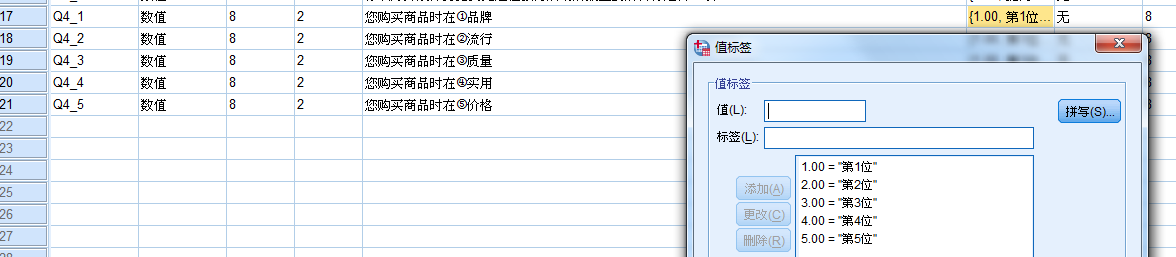
例:您购买商品时在①品牌 ②流行 ③质量 ④实用 ⑤价格
中对它们的关注程度先后顺序是(请填代号重新排列)第一位 第二位 第三位 第四位 第五位
编码:定义五个变量,分别可以代表第一位到第五位,每个变量的Value都做如下定义:“1” 品牌,“2” 流行,“3” 质量,“4” 实用,“5” 价格
录入:录入的数字1、2、3、4、5分别代表五个选项,如被调查者把质量排在第一位则在代表第一位的
变量下输入“3”。
采用分类法:
开放题:这类题目要求被调查者自己填入数值,或者打分
例:你的年龄(实岁):______
编码:一个变量,不定义Value值
录入:即录入被调查者实际填入的数值。
注意:对于开放性文字题,如果可能的话可以按照含义相似的答案进行编码,转换成为封闭
式选项进行分析。如果答案内容较为丰富、不容易归类的,应对这类问题直接做定性分析。
第四章 数据的准备
标志重复个案
选择个案
数据验证模块
数据的分类汇总
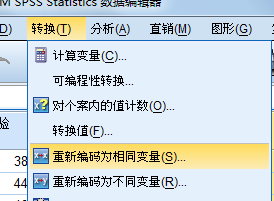
重新编码为不同变量
转置
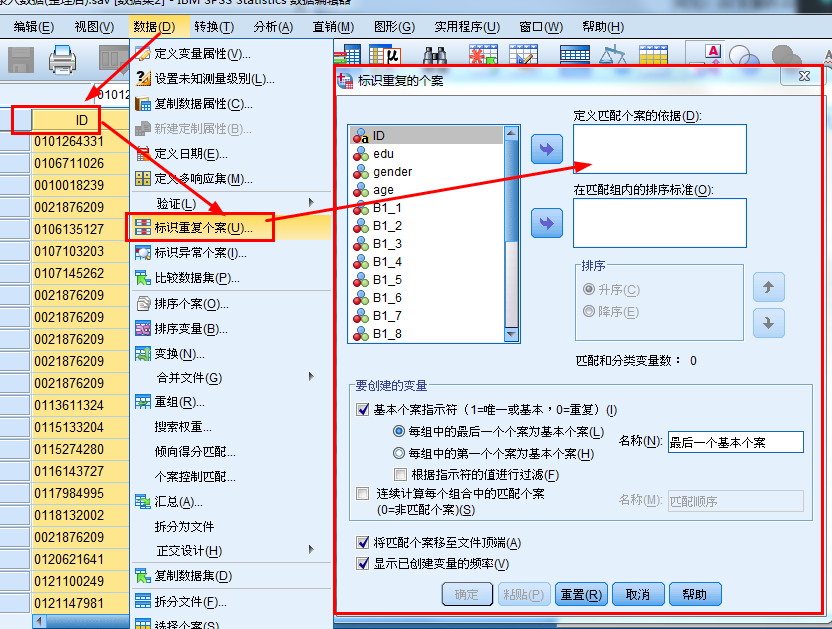
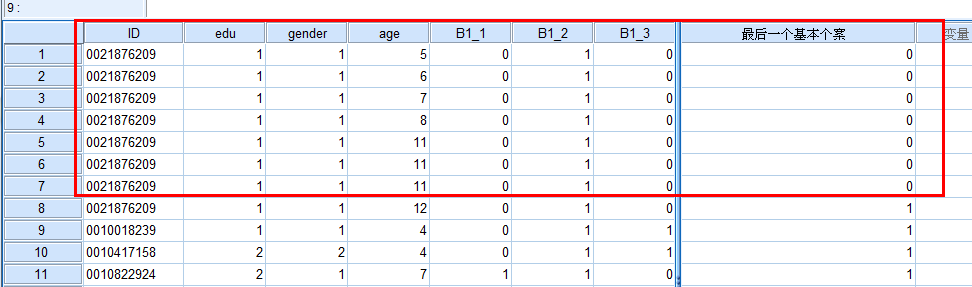
标志重复个案:
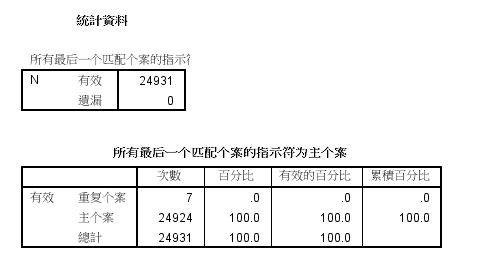
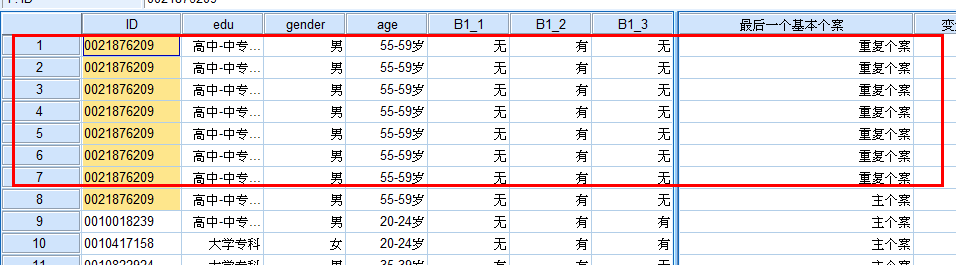
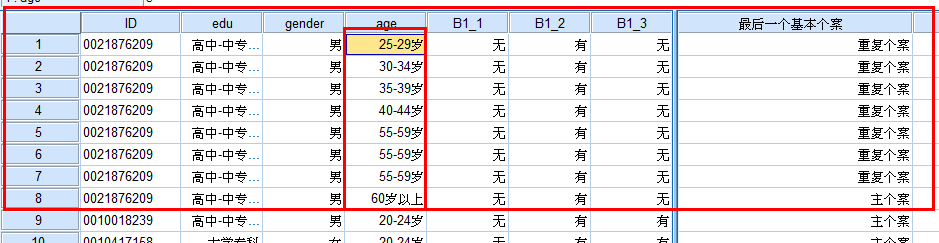
原因:在一些测验统计结果中,经常会出现重复个案,即用户名、选项完全相同的个案,如果不作处理,显然会影响统计结果。
案例文件:问卷录入数据(整理后).sav,然后按照id相同的标准查找重复记录。
操作步骤:数据——标识重复个案
删除个案:法一,直接在变量视图界面删除;
法二,数据——选择个案。
(注:在选择个案中有详细介绍)
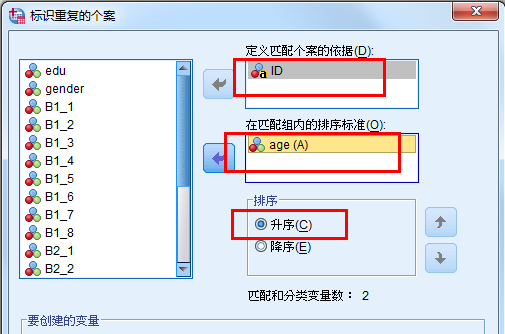
在ID相同的条件下按年龄进行排序,选择升序排序
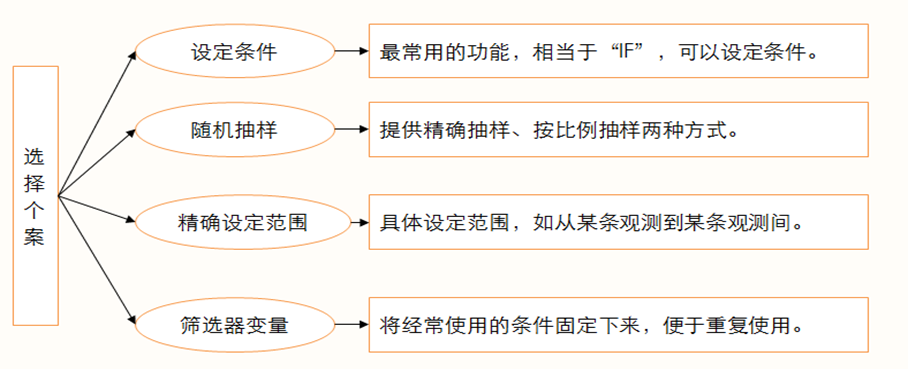
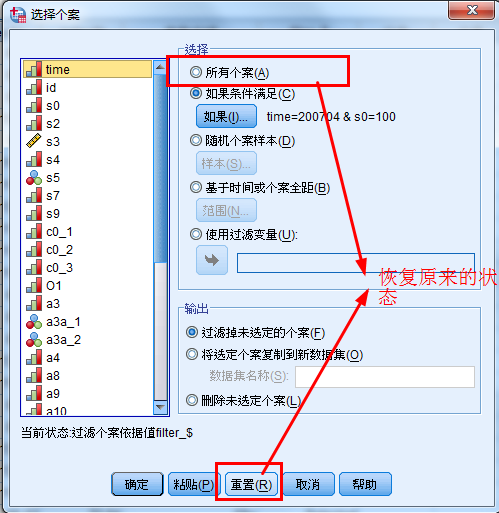
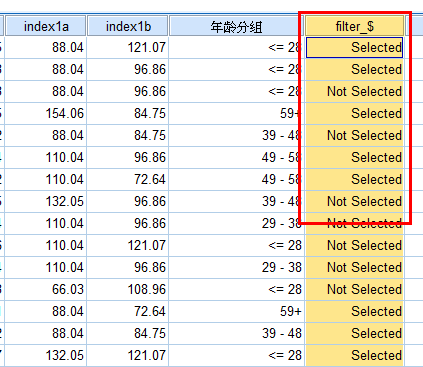
选择个案:
主要内容:筛选出符合要求的个案。
解决的问题:不需要对整体进行处理,这时可以设置条件语句,选择符合要求的样本进行处理。
用途:
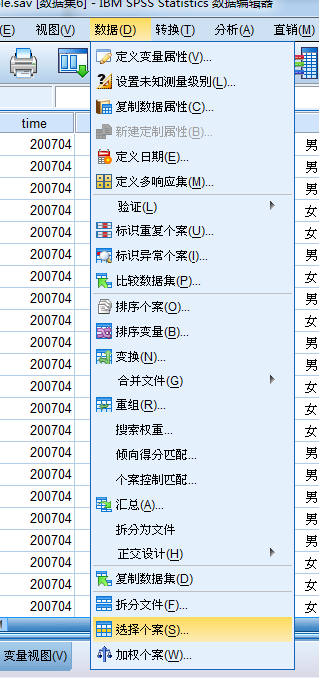
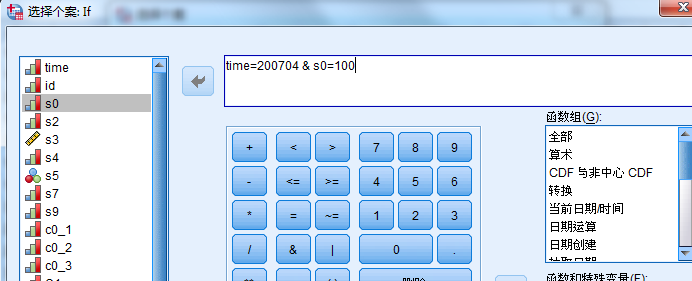
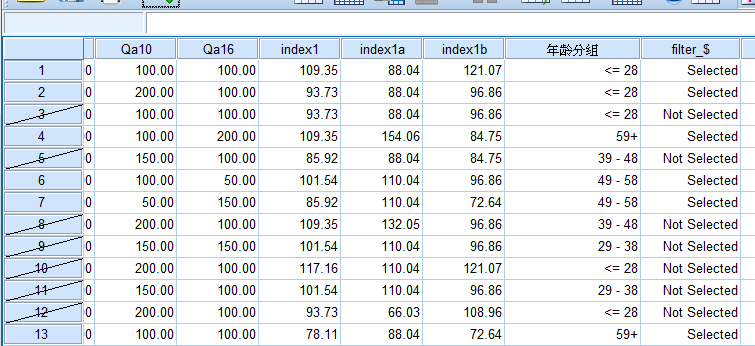
点击所有个案或者重置或者删除filter列
先选着id 排序 再删除重复个案

数据验证模块
单变量规则-交叉变量规则
实现数据核查功能,用户通过自定义数据验证规则,并运行数据验证规则对数据进行检查,以确定个案取值是否有效。验证规则有以下两种:
(1)单变量规则:包含一组应用于单个变量的数值检查的规则。如,数码产品顾客购买习惯问卷调查项目性别:只有1,2两个取值编码,年龄为14到53;
(2)交叉变量规则:交叉变量规则是用户定义的涉及多个变量间逻辑关系的规则,是标记无效值的逻辑表达式,可以应用于单个变量,也可以应用于变量组合。
如:B3选中在网上购物,B5_1至B5_5中任一项选择了网上购物的支付方式或B4每月网络购物的消费不为空,否则,问卷应视为存在逻辑错误,作为废卷处理。



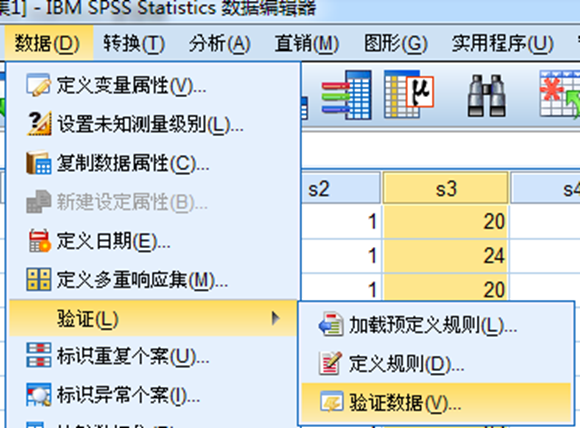
练习:
CCSS_Sample.sav ,年龄:取值应当在18~65岁之间;性别:只有1,2两个取值编码,
定义规则识别年龄、性别取值违规或者说异常的个案;
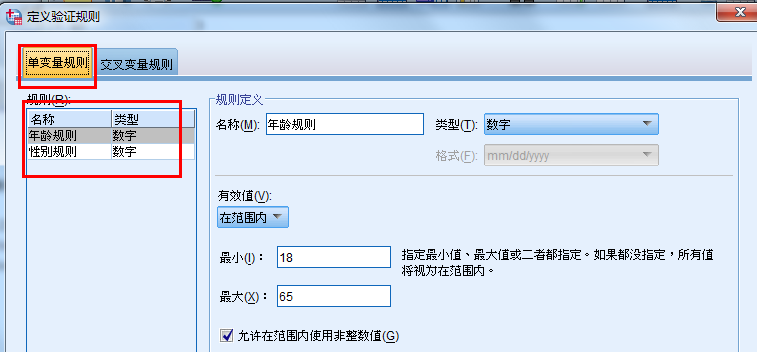
定义交叉变量规则,关键题目A3、A4、A8取值不应当同时选择9,否则应作废卷处理。

验证数据:

在单变量规则 和 交叉变量规则对应
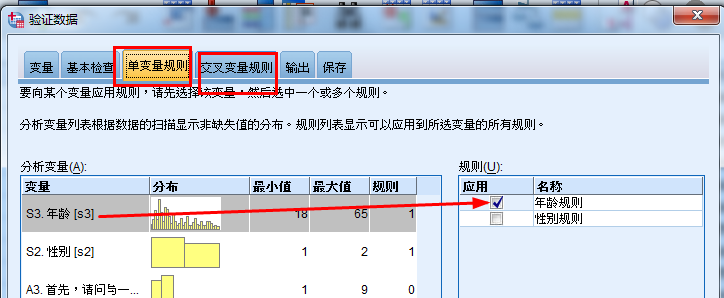
保存:

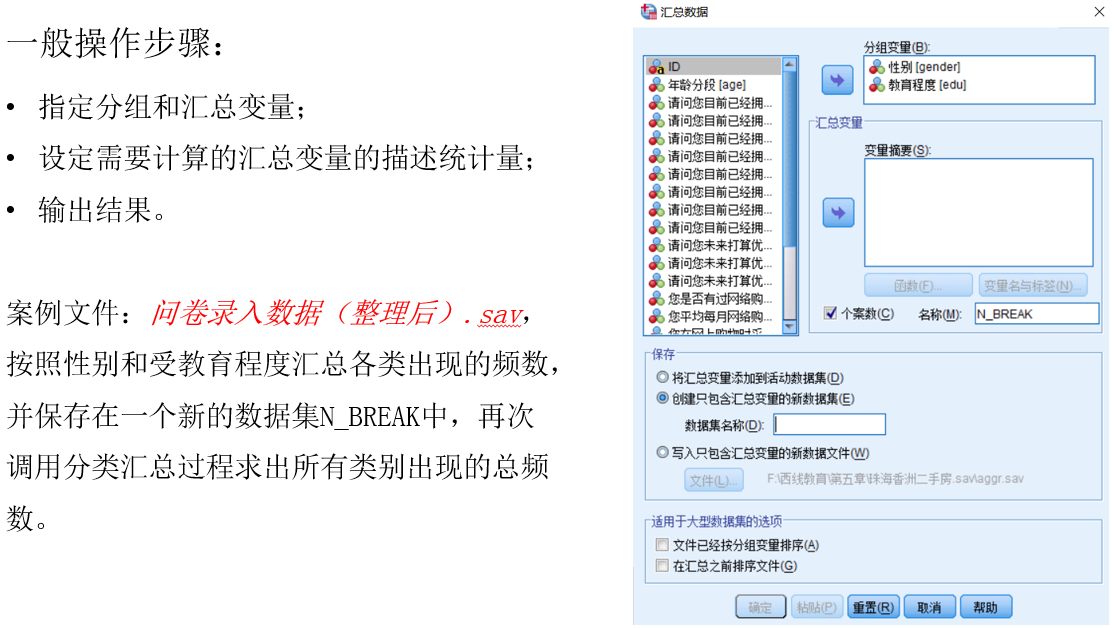
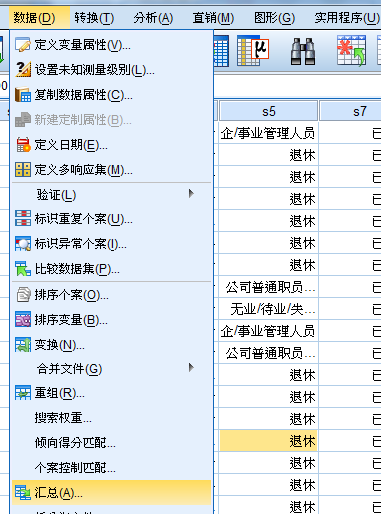
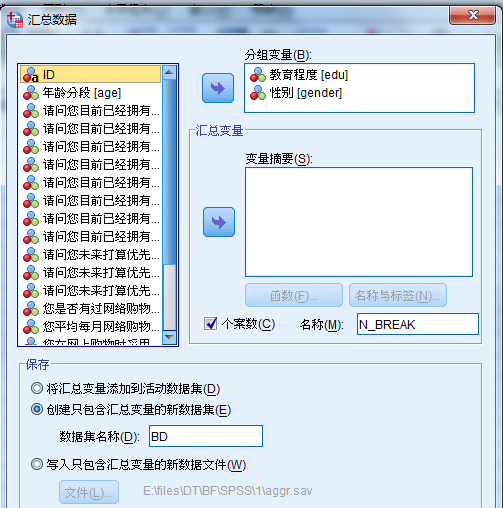
数据的分类汇总
主要内容:数据太乱而不好进行分析,用SPSS软件对数据进行分类汇总,从而使数据更加直观,清晰。
也就是说,对变量不同取值进行分组,进而求得相关统计量。
解决的问题:有时我们感兴趣的是变量的不同取值内的相关统计信息,例如不同性别的均值、中位数等。
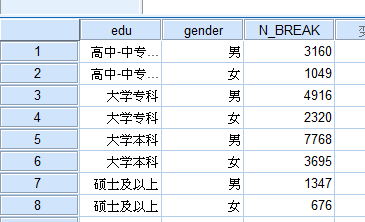
结果:
分类汇总

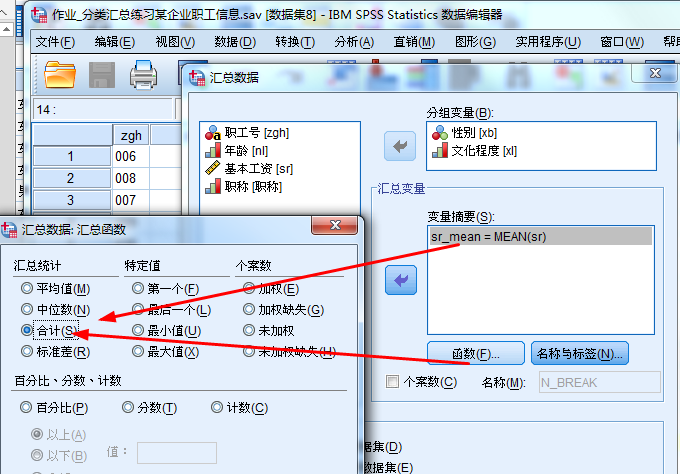
函数可选的功能:
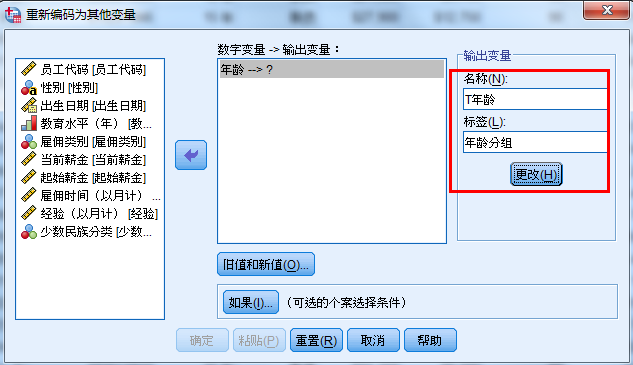
重新编码为不同变量--年龄分组
编码后的结果不会覆盖原有数据
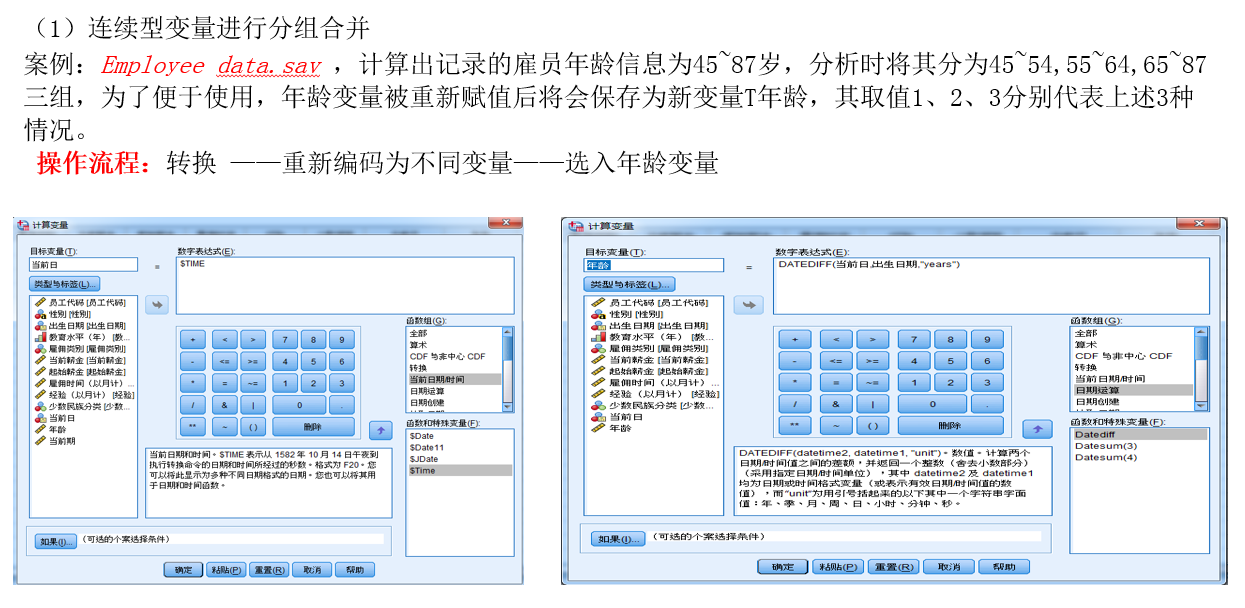
调用年龄信息并分成三组
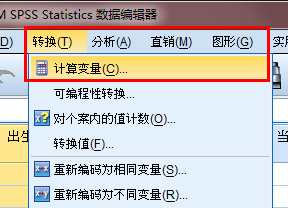

接下来进行年龄的分组:
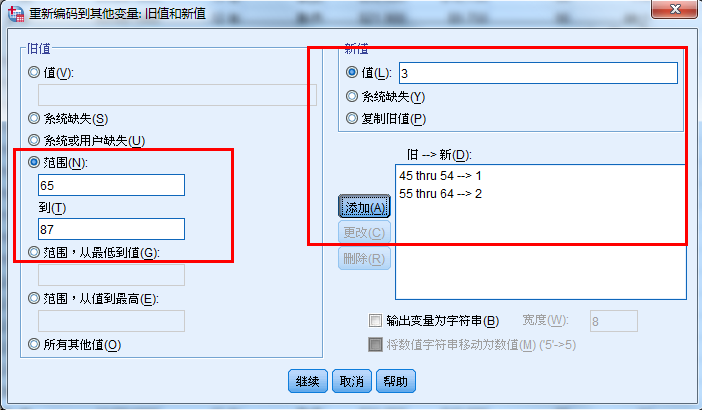
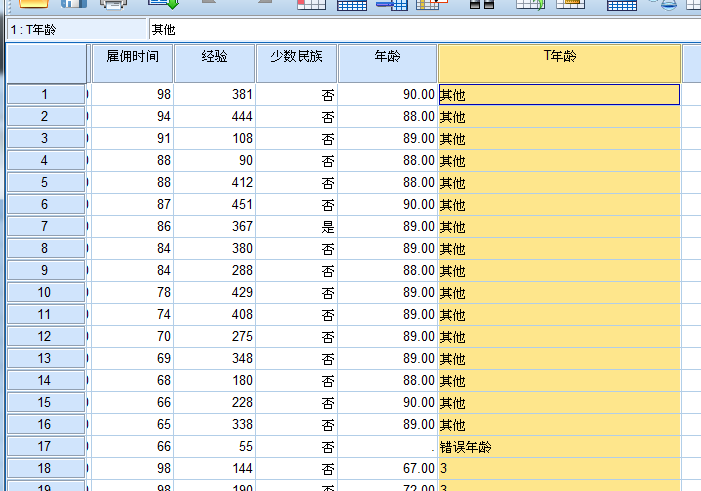
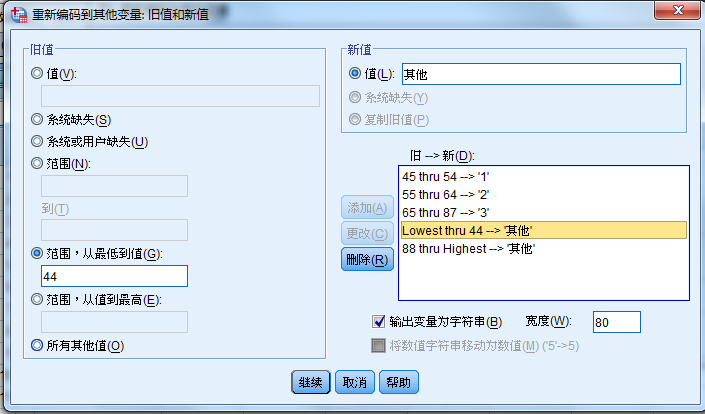
重新编码为相同变量
编码后的结果会覆盖原有数据
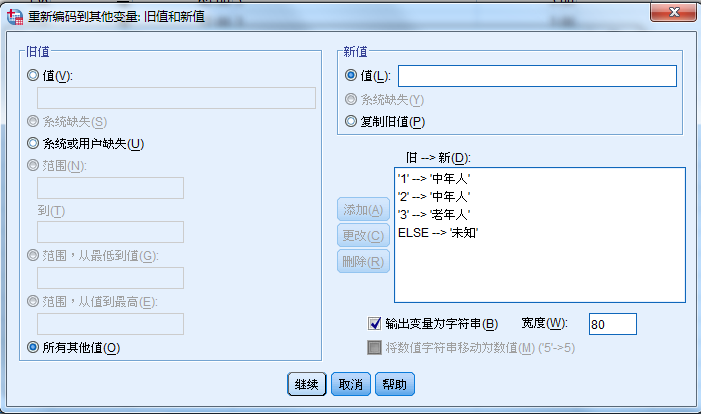
分类变量的类别合并--年龄段的合并 中年

对分类变量进行合并,例如区间35-43 和 45-54 两个区间的数据一起合并成中年人
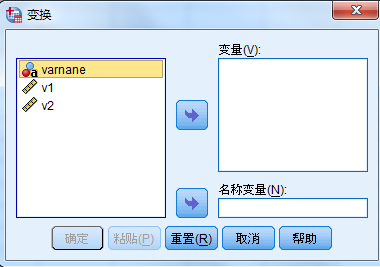
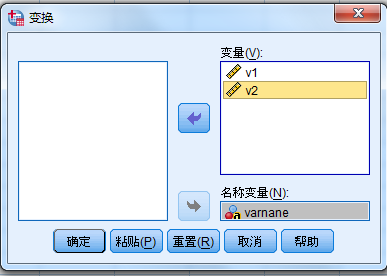
转置
数据框下的 变换

111
悟已往之不谏,知来者之可追。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号