hive正则
正则表达式描述了一种字符串匹配的模式,可以用来检查一个字符串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
正则表达式是由普通字符以及特殊字符组成的文字模式。
普通字符:包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号
^ 匹配输入字符串的开始位置。
$ 匹配输入字符串的结束位置。
[xyz] 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。
[^xyz] 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'、'l'、'i'、'n'。
\d 匹配一个数字字符。等价于 [0-9]。
\D 匹配一个非数字字符。等价于 [^0-9]。
\w 匹配字母、数字、下划线。等价于'[A-Za-z0-9_]'。
\W 匹配非字母、数字、下划线。等价于 '[^A-Za-z0-9_]'。
. 匹配除换行符(\n、\r)之外的任何单个字符。
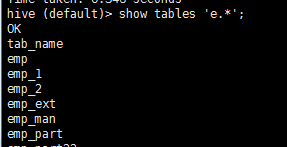
show tables 'e.*';
select ename from emp;
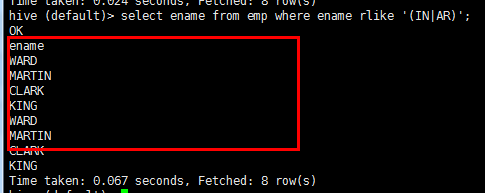
select ename from emp where ename rlike '(IN|AR)';
查询姓名 包含IN和AR的
select hiredate from emp;

4-1-1 只查询格式 1981-6-9
双斜线
select hiredate from emp where hiredate rlike '^\\d{4}-\\d-\\d$';
正则表达式替换函数:
regexp_replace(stringA,pattern,stringB)
select regexp_replace('foobar','oo|ar','77'); f77b77
select regexp_replace(ename,'IN|AR','99') from emp;
解析函数:
regexp_extract(string,pattern,index)
实例分析:
create table IF NOT EXISTS log_source ( remote_addr string, remote_user string, time_local string, request string, status string, body_bytes_sent string, request_body string, http_referer string, http_user_agent string, http_x_forwarded_for string, host string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ';
列分隔符 和 数据字段中的符号 是否冲突
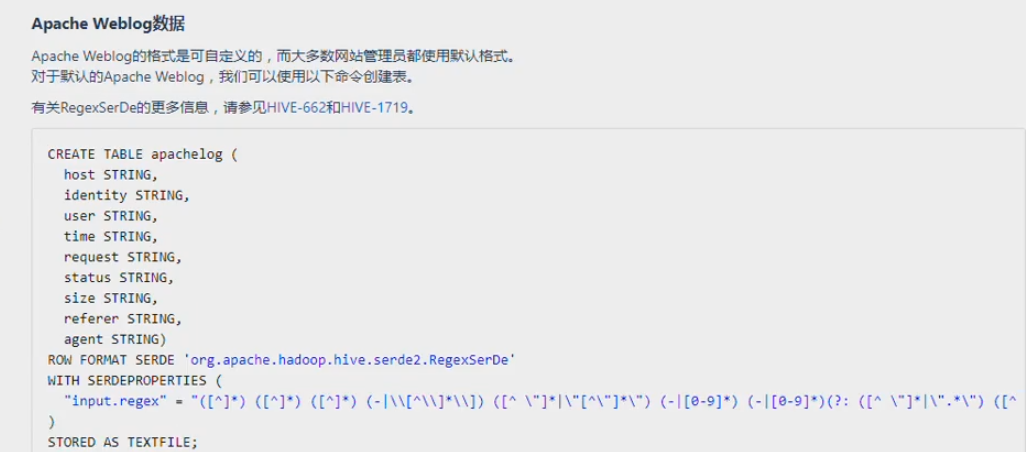
CREATE TABLE apachelog ( remote_addr string, remote_user string, time_local string, request string, status string, body_bytes_sent string, request_body string, http_referer string, http_user_agent string, http_x_forwarded_for string, host string) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( "input.regex" = "(\"[^ ]*\") (\"-|[^ ]*\") (\"[^\]]*\") (\"[^\]]*\") (\"[0-9]*\") (\"[0-9]*\") (-|[^ ]*\) (\"[^ ]*\") (\"[^\]]*\") (\"-|[^ ]*\") (\"[^ ]*\")" ); "27.38.5.159" "-" "31/Aug/2015:00:04:37 +0800" "GET /course/view.php?id=27 HTTP/1.1" "303" "440" - "http://www.ibeifeng.com/user.php?act=mycourse" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36" "-" "learn.ibeifeng.com" (\"[^ ]*\") (\"-|[^ ]*\") (\"[^\]]*\") (\"[^\]]*\") (\"[0-9]*\") (\"[0-9]*\") (-|[^ ]*\) (\"[^ ]*\") (\"[^\]]*\") (\"-|[^ ]*\") (\"[^ ]*\") 解决复杂格式数据导入的问题
hive查询
数据向hive表里的多种导入方式:
load data local inpath '本地Linux文件路径' into table tbname; 2:从hdfs上加载 load data inpath 'hdfs文件路径' into table tbname; overwrite 覆盖数据 3:as select 4: insert 语法格式:insert into table tbname select sql; create table emp_11 like emp; insert into table emp_11 select * from emp where deptno=10; 5:hdfs命令,直接把数据put到表的目录下 hive表------- hdfs目录 bin/hdfs dfs -put /home/hadoop/emp.txt /user/hive/warehouse/hadoop29.db/emp
导出数据:
1: insert overwrite
格式 insert overwrite [local] directory 'path' select sql;
导出到本地:
insert overwrite local directory '/home/hadoop/nice' select * from emp where sal >2000;
默认列分割符 ---'\001' ----- '^A'
insert overwrite local directory '/home/hadoop/nice' row format delimited fields terminated by '\t' select * from emp where sal >2000;
导出到hdfs:
insert overwrite directory '/nice' row format delimited fields terminated by '\t' select * from emp where sal >2000;
2: bin/hive -help 查看帮助
bin/hive --database hadoop29
bin/hive -e 'use hadoop29;select * from emp;' > /home/hadoop/nice/emp.txt
hive常用的hql语句:
过滤 where
select * from emp where sal >2000;
limit select * from emp limit 1;
distinct select distinct deptno from emp; 去重
between...and
select * from emp where sal between 2000 and 3000;
is null 和 is not null
select * from emp where comm is not null;
having 过滤分组后的数据
select deptno,round(avg(sal),2) as avg_sal from emp group by deptno having avg_sal > 2000;
hive函数
count() sum() max() min() avg() select count(*) from emp; select count(comm) from emp; 不统计null值 查看所有内置函数 show functions; 查看函数信息 desc function sum; 查看函数详细信息 desc function extended sum; desc function extended substr; datediff 获取当前时间戳: select unix_timestamp(); select unix_timestamp('2019-12-12 12:12:12'); 时间戳转时间 select from_unixtime(1576123932,'yyyy-MM-dd HH:MM:SS'); 连表: join .... on 内连接: select e.empno,e.ename,d.deptno,d.dname from emp e join dept d on e.deptno=d.deptno; select e.empno,e.ename,d.deptno,d.dname from emp e left join dept d on e.deptno=d.deptno; select e.empno,e.ename,d.deptno,d.dname from emp e right join dept d on e.deptno=d.deptno; select e.empno,e.ename,d.deptno,d.dname from emp e full join dept d on e.deptno=d.deptno; 窗口函数:group by 聚合 查询所有部门的员工信息,并且按照薪资进行降序排序 select empno,ename,sal,deptno from emp order by sal desc; 查询所有部门的员工信息,按照部门进行薪资降序排序,并且在最后一列显示每个部门的最高薪资 select empno,ename,sal,deptno,max(sal) over(partition by deptno order by sal desc) as max_sal from emp; 可以指定根据那个字段分区根据那个字段排序 empno ename sal deptno max_sal 7839 KING 5000.0 10 5000.0 7782 CLARK 2450.0 10 5000.0 7934 MILLER 1300.0 10 5000.0 7788 SCOTT 3000.0 20 3000.0 7902 FORD 3000.0 20 3000.0 7566 JONES 2975.0 20 3000.0 7876 ADAMS 1100.0 20 3000.0 7369 SMITH 800.0 20 3000.0 7698 BLAKE 2850.0 30 2850.0 7499 ALLEN 1600.0 30 2850.0 7844 TURNER 1500.0 30 2850.0 7654 MARTIN 1250.0 30 2850.0 7521 WARD 1250.0 30 2850.0 7900 JAMES 950.0 30 2850.0 查询所有部门的员工信息,按照部门进行薪资降序排序,并且在最后一列显示每个部门唯一编号 select empno,ename,sal,deptno,row_number() over(partition by deptno order by sal desc) as rn from emp; empno ename sal deptno rn 7839 KING 5000.0 10 1 7782 CLARK 2450.0 10 2 7934 MILLER 1300.0 10 3 7788 SCOTT 3000.0 20 1 7902 FORD 3000.0 20 2 7566 JONES 2975.0 20 3 7876 ADAMS 1100.0 20 4 7369 SMITH 800.0 20 5 7698 BLAKE 2850.0 30 1 7499 ALLEN 1600.0 30 2 7844 TURNER 1500.0 30 3 7654 MARTIN 1250.0 30 4 7521 WARD 1250.0 30 5 7900 JAMES 950.0 30 6 select empno,ename,sal,deptno,rank() over(partition by deptno order by sal desc) as rn from emp; empno ename sal deptno rn 7839 KING 5000.0 10 1 7782 CLARK 2450.0 10 2 7934 MILLER 1300.0 10 3 7788 SCOTT 3000.0 20 1 7902 FORD 3000.0 20 1 7566 JONES 2975.0 20 3 7876 ADAMS 1100.0 20 4 7369 SMITH 800.0 20 5 7698 BLAKE 2850.0 30 1 7499 ALLEN 1600.0 30 2 7844 TURNER 1500.0 30 3 7654 MARTIN 1250.0 30 4 7521 WARD 1250.0 30 4 7900 JAMES 950.0 30 6 select empno,ename,sal,deptno,dense_rank() over(partition by deptno order by sal desc) as rn from emp; empno ename sal deptno rn 7839 KING 5000.0 10 1 7782 CLARK 2450.0 10 2 7934 MILLER 1300.0 10 3 7788 SCOTT 3000.0 20 1 7902 FORD 3000.0 20 1 7566 JONES 2975.0 20 2 7876 ADAMS 1100.0 20 3 7369 SMITH 800.0 20 4 7698 BLAKE 2850.0 30 1 7499 ALLEN 1600.0 30 2 7844 TURNER 1500.0 30 3 7654 MARTIN 1250.0 30 4 7521 WARD 1250.0 30 4 7900 JAMES 950.0 30 5 select empno,ename,sal,deptno from (select empno,ename,sal,deptno,row_number() over(partition by deptno order by sal desc) as rn from emp) temp where rn <=2; 大数据 历史数据
1111
悟已往之不谏,知来者之可追。

