一、知识结构
分类问题和逻辑回归?
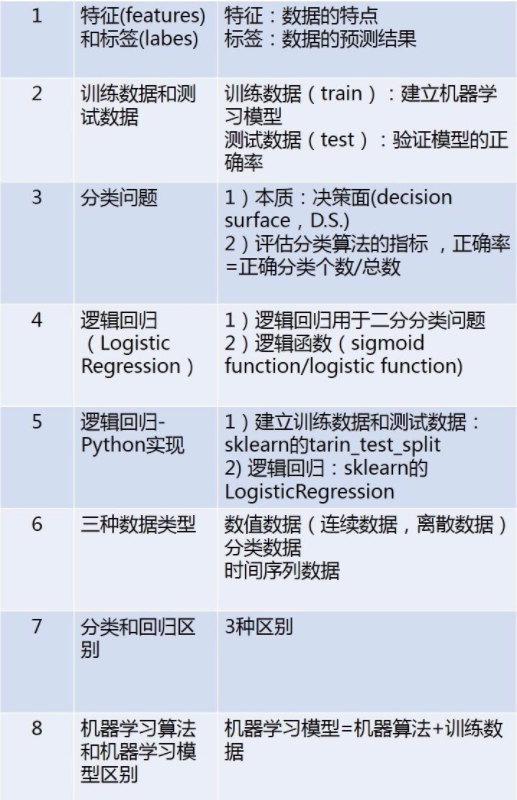
1)输出数据的类型
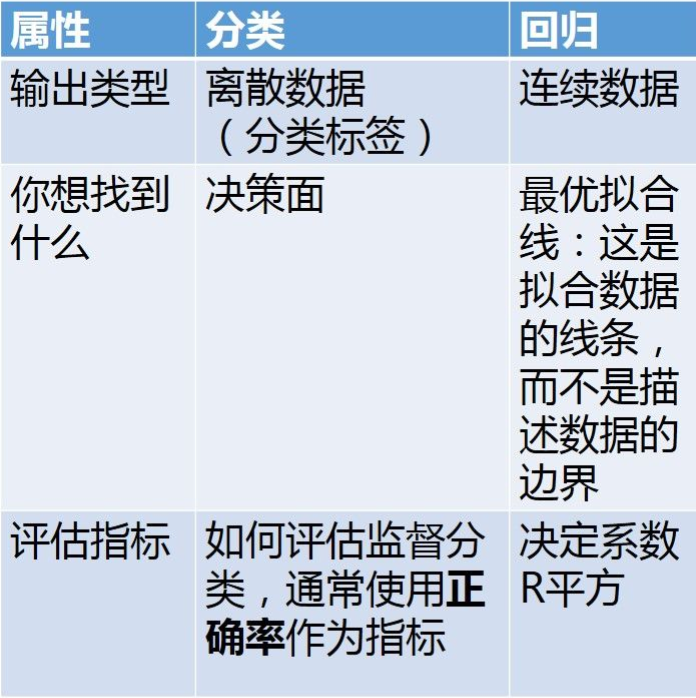
分类输出的数据类型是离散数据,也就是分类的标签。 回归输出的是连续数据类型。 2)第2个区别是我们想要通过机器学习算法得到什么? 分类算法得到是一个决策面,用于对数据集中的数据进行分类。 回归算法得到是一个最优拟合线,这个线条可以最好的接近数据集中的各个点。
3)第3个区别是对模型的评估指标不一样 在监督分类中,我们我们通常会使用正确率作为为指标,也就是预测结果中分类正确数据占总数据的比例 在回归中,我们用决定系数R平方来评估模型的好坏。R平方表示有多少百分比的y波动被回归线描述。
用python实现逻辑回归
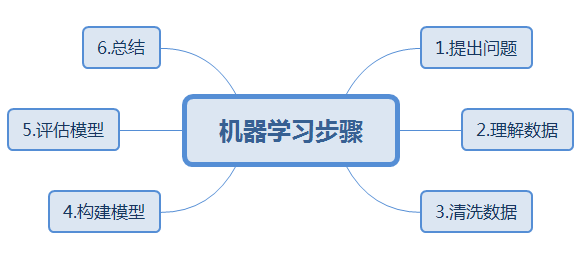
1、机器学习的步骤
2、提出问题
分析学习时间与考试通过的关系(属于分类问题)
3、理解数据
import numpy as np import pandas as pd from matplotlib import pyplot as plt from sklearn.linear_model import LinearRegression from collections import OrderedDict
3.1 获取数据源 本次数据源为自定义数据
data={ '学习时间':[0.50,0.75,1.00,1.25,1.50,1.75,1.75,2.00,2.25,2.50, 2.75,3.00,3.25,3.50,4.00,4.25,4.50,4.75,5.00,5.50], '通过考试':[0,0,0,0,0,0,1,0,1,0,1,0,1,0,1,1,1,1,1,1] }
3.2将字典转化为排序字典
order_data=OrderedDict(data)
df=pd.DataFrame(order_data)
3.3查看数据集信息
df.info()

df.head()
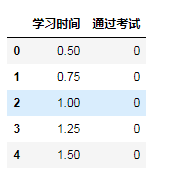
自定义数据集共有两个字段,学习时间和分数,共20条数据
4、清洗数据
数据自定义且格式正确
5、构建模型
5.1绘制散点图
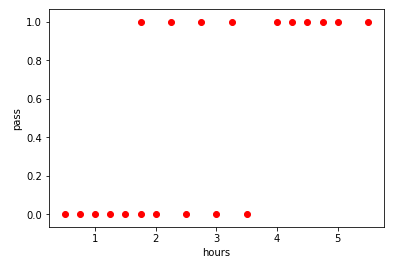
# 提取特征值 exam_x = df.loc[:,'学习时间'] exam_y = df.loc[:,'通过考试'] plt.scatter(exam_x,exam_y,color='r',label='exam_score') # 添加坐标标签 plt.xlabel('hours') plt.ylabel('pass') #显示图像 plt.show()
5.2建立训练数据集和测试数据集
分割数据,将数据随机分成训练数据(80%)和测试数据(20%)
from sklearn.model_selection import train_test_split x_train , x_test , y_train , y_test = train_test_split(exam_x , exam_y, train_size = 0.8) #输出数据大小 print('原始数据特征:',exam_x.shape , ',训练数据特征:', x_train.shape , ',测试数据特征:',x_test.shape ) print('原始数据标签:',exam_y.shape , '训练数据标签:', y_train.shape , '测试数据标签:' ,y_test.shape)

5.3选择机器学习算法:
导入算法 逻辑回归(logisic regression) 随机森林(Random Forests Model) 支持向量机(Support Vector Machines) Gradient Boosting Classifier K-nearest neighbors Gaussian Naive Bayes 数据降维:PCA,Isomap 数据分类:SVC,K-Means 线性回归:LinearRegression 创建模型 model=LinearRegression() 训练模型 model.fit(train_X , train_y )
逻辑回归(logisic regression)
5.4训练模型
# - - - - -- - - -训练模型(使用训练数据) - - - - -- - - - x_train=x_train.values.reshape(-1,1) x_test=x_test.values.reshape(-1,1) from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(x_train , y_train)
6、模型评估
model.score(x_test , y_test) #评估模型:准确率
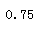
正确率为0.75,正确率较好
6.1绘图
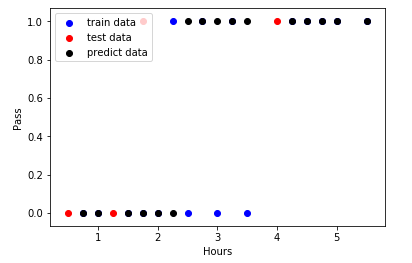
# 绘图 import matplotlib.pyplot as plt # 训练数据散点图 plt.scatter(x_train, y_train, color='blue', label="train data") # 测试数据散点图 plt.scatter(x_test,y_test,color='r',label='test data') # 训练数据的预测值 y_train_pred = model.predict(x_train) plt.scatter(x_train,y_train_pred,color='black',label='predict data') # 绘制最佳拟合 #plt.plot(x_train, y_train_pred, color='black', label="best line") # 添加图标标签 plt.legend(loc=2) plt.xlabel("Hours") plt.ylabel("Pass") plt.show()
理解逻辑函数:
通过回归方程(截距、回归系数与特征值x)求得y值
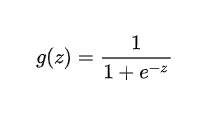
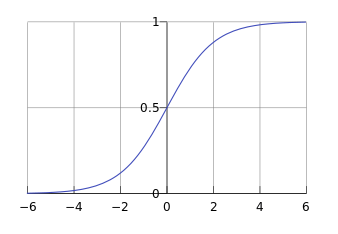
当g(z)值大于0.5
#理解逻辑回归函数 #斜率slope #截距intercept #第1步:得到回归方程的z值 #回归方程:z=𝑎+𝑏x a=model.intercept_ #截距 b=model.coef_ #回归系数 x=3 z=a+b*x #第2步:将z值带入逻辑回归函数中,得到概率值 y_pred=1/(1+np.exp(-z)) print('预测的概率值:',y_pred)
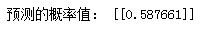
predict_proba:获取概率值
第1个值是标签为0的概率值,第2个值是标签为1的概率值
model.predict_proba([[3]])
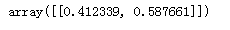
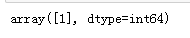
#predict:返回y值
model.predict([[3]])
7.总结
1、研究问题:学习时间和成绩的关系?
2、数据来源:自定义数据源共20条数据
3、特征值和标签分别为:学习时间和通过考试
(特征是做出某个判断的证据,标签是结论)
(机器学习主要的工作就是提取出有用的特征,构造从特征到标签的映射)
6、评估模型:正确率为0.75,正确率较好
结论:学习时间越长考试通过率的概率越大。
悟已往之不谏,知来者之可追。
