Numpy 属性

ndim:维度shape:行数和列数size:元素个数
import numpy as np # 定义数组 array = np.array([[1,2,3],[2,3,4]]) print(array) # ndim 维度的数量 print('维度的数量',array.ndim) # 维度 print('维度',array.shape) # 数组元素的个数 print('数组元素的个数',array.size) # 对象元素的类型 print('对象元素的类型',array.dtype) # 对象每个元素的大小、以字节为单位 print('对象每个元素的大小、以字节为单位',array.itemsize) # 对象内存信息 print(' 对象内存信息',array.flags)

axis=0 与 axis=1 的区分
就是0轴匹配的是index, 涉及上下运算;1轴匹配的是columns, 涉及左右运算。

amin(a,0) 是延着 axis=0 轴的最小值,axis=0是把元素看成[1,2,3],[4,5,6],[7,8,9]三个元素,所以最小值是[1,2,3],
amin(a,1) 是延着 axis=1 轴的最小值,axis=1 轴是把元素看成了 [1,4,7],[2,5,8], [3,6,9] 三个元素,所以最小值为 [1,4,7]。
a = np.array([[1,2,3], [4,5,6],[7,8,9]]) print('a=',a,'\n') print('a[1]:',a[1]) print(np.amin(a)) print(np.amin(a,0)) print(np.amin(a,1)) print(np.amax(a)) print(np.amax(a,0)) print(np.amax(a,1)) a= [[1 2 3] [4 5 6] [7 8 9]] a[1]: [4 5 6] 1 [1 2 3] [1 4 7] 9 [7 8 9] [3 6 9]
创建数组
关键字
array:创建数组
dtype:指定数据类型
zeros:创建数据全为0
ones:创建数据全为1
empty:创建数据接近0
arange:按指定范围创建数据
linspace:创建线段
具体代码:
# 创建数组 import numpy as np a = np.array([1,2,3]) print(a) [1 2 3] # 指定数组类型 指定数据 dtype a = np.array([1,2,3],dtype=np.float32) print(a) a2 = np.array([1,2,3],dtype=np.int32) print(a2) [1. 2. 3.] [1 2 3] # 创建特定数据 # 2行3列 a = np.array([[1,2,3],[3,2,1]]) print(a) print(a.shape) print(a.dtype) [[1 2 3] [3 2 1]] (2, 3) int32 # 创建全零数组 # 数据全为0,3行4列 # 默认为float a = np.zeros((3,4)) print(a) print(a.dtype) [[0. 0. 0. 0.] [0. 0. 0. 0.] [0. 0. 0. 0.]] float64 # 创建全为1的数组, 同时也能指定这些特定数据的 dtype: a = np.ones((3,4),dtype=np.int) print(a) print(a.dtype) [[1 1 1 1] [1 1 1 1] [1 1 1 1]] int32 # 创建全空数组, 其实每个值都是接近于零的数: a = np.empty((3,4)) print(a) print(a.dtype) [[0. 0. 0. 0.] [0. 0. 0. 0.] [0. 0. 0. 0.]] float64 # 用 arange 创建连续数组: # 10-19 的数据,2步长 arange用来创建数组 a = np.arange(10,20,2) print(a) print(a.dtype) [10 12 14 16 18] int32 # 使用 reshape 改变数据的形状 # 3行4列 ,0到11 a = np.arange(12).reshape((3,4)) print(a) print(a.dtype) [[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] int32 # 用 linspace 创建线段型数据: # 开始端为1 ,结束端10,且分割成20个数据,生成线段 a = np.linspace(1,10,20) print(a) print(a.dtype) # 同样也能进行 reshape 工作: a2 = np.linspace(1,10,20).reshape((4,5)) print('------------------------------------------------------------------') print(a2) print(a2.dtype) [ 1. 1.47368421 1.94736842 2.42105263 2.89473684 3.36842105 3.84210526 4.31578947 4.78947368 5.26315789 5.73684211 6.21052632 6.68421053 7.15789474 7.63157895 8.10526316 8.57894737 9.05263158 9.52631579 10. ] float64 ------------------------------------------------------------------ [[ 1. 1.47368421 1.94736842 2.42105263 2.89473684] [ 3.36842105 3.84210526 4.31578947 4.78947368 5.26315789] [ 5.73684211 6.21052632 6.68421053 7.15789474 7.63157895] [ 8.10526316 8.57894737 9.05263158 9.52631579 10. ]] float64
NumPy 从已有的数组创建数组
numpy.asarray(a, dtype = None, order = None)
a 任意形式的输入参数,可以是,列表, 列表的元组, 元组, 元组的元组, 元组的列表,多维数组
dtype 数据类型,可选
order 可选,有"C"和"F"两个选项,分别代表,行优先和列优先,在计算机内存中的存储元素的顺序。
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合 实例 将列表转换为 ndarray: import numpy as np x = [1,2,3] a = np.asarray(x) print(a,type(a),a.dtype) [1 2 3] <class 'numpy.ndarray'> int32
将元组转换为 ndarray:

将元组列表转换为 ndarray:

设置了 dtype 参数:数据类型
NumPy 从数值范围创建数组
numpy.arange
numpy 包中的使用 arange 函数创建数值范围并返回 ndarray 对象,函数格式如下:
numpy.arange(start, stop, step, dtype)
import numpy as np
x = np.arange(0,5,2,float)
print(x)
[0. 2. 4.]
numpy.linspace
numpy.linspace 函数用于创建一个一维数组,数组是一个等差数列构成的,格式如下:
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
numpy.logspace
numpy.logspace 函数用于创建一个于等比数列。格式如下:
np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
切片
# 切片 顾头不顾尾,指的索引 a = np.array(range(10)) print(a) # # 从索引 0 开始到索引 10 停止,不包括10,间隔为 2 print(a[0:10:2]) [0 1 2 3 4 5 6 7 8 9] [0 2 4 6 8]
多维数组同样适用上述索引提取方法:
多维数组是对行的切片
# 多维数组同样适用上述索引提取方法: b = np.array([[1,2,3],[4,5,6],[7,8,9]]) print(b[0]) print(b[1:]) [1 2 3] [[4 5 6] [7 8 9]]
b = np.array([[1,2,3],[4,5,6],[7,8,9],[10,11,12]])
print(b[1:3])查询第二行到第三行的数组
[[4 5 6]
[7 8 9]]
切片还可以包括省略号 …,来使选择元组的长度与数组的维度相同。 如果在行位置使用省略号,它将返回包含行中元素的 ndarray。
a = np.array([[1, 2, 3], [3, 4, 5], [6, 7, 8]]) print(a[..., 1]) # 第2列元素 print() print(a[1, ...]) # 第2行元素 print() print(a[..., 1:]) # 第2列及剩下的所有元素 [2 4 7] [3 4 5] [[2 3] [4 5] [7 8]]
NumPy 高级索引
整数数组索引
# 以下实例获取数组中(0,0),(1,1)和(2,0)位置处的元素。 x = np.array([[1, 2], [3, 4], [5, 6]]) y = x[[0, 1, 2], [0, 1, 0]] print('x:',x) print('y:',y) x: [[1 2] [3 4] [5 6]] y: [1 4 5] [0, 1, 2] [0, 1, 0] 组合:(0,0),(1,1)和(2,0)
NumPy 高级索引
#以下实例获取了 4X3 数组中的四个角的元素。 # 行索引是 [0,0] 和 [3,3],而列索引是 [0,2] 和 [0,2]。 x = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 10, 11]]) print('我们的数组是:') print(x) print('\n') rows = np.array([[0, 0], [3, 3]]) print(rows,'\n') cols = np.array([[0, 2], [0, 2]]) print(cols,'\n') y = x[[0, 0, 3, 3],[0, 2,0, 2]] y2 = x[rows, cols] print('这个数组的四个角元素是:') print(y) print(y2)
我们的数组是:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
[[0 0]
[3 3]]
[[0 2]
[0 2]]
这个数组的四个角元素是:
[ 0 2 9 11]
[[ 0 2]
[ 9 11]]
----------------------------------------------
[0, 0, 3, 3]
[0, 2,0, 2]
行和列:(0,0),(0,2),(3,0),(3,2)
Numpy 数组操作
Numpy 中包含了一些函数用于处理数组,大概可分为以下几类:
修改数组形状
翻转数组
修改数组维度
连接数组
分割数组
数组元素的添加与删除
索引
import numpy as np A = np.arange(3,15) print(A) print(A[3]) [ 3 4 5 6 7 8 9 10 11 12 13 14] 6 # 让我们将矩阵转换为二维的,此时进行同样的操作: A = np.arange(3,15).reshape((3,4)) print(A[2]) [11 12 13 14] # 二维索引 print(A[1][1]) 8 # 在Python的 list 中,我们可以利用:对一定范围内的元素进行切片操作, # 在Numpy中我们依然可以给出相应的方法: print(A[1, 1:3]) [8 9] # 用for循环进行打印 # 逐行进行打印 for row in A: print(row) [3 4 5 6] [ 7 8 9 10] [11 12 13 14] # 逐列打印,就需要稍稍变化一下 for column in A.T: print(column) [ 3 7 11] [ 4 8 12] [ 5 9 13] [ 6 10 14] # flatten是一个展开性质的函数,将多维的矩阵进行展开成1行的数列 # 而flat是一个迭代器,本身是一个object属性。 import numpy as np A = np.arange(3,15).reshape((3,4)) print(A.flatten()) [ 3 4 5 6 7 8 9 10 11 12 13 14] for item in A.flat: print(item) 3 4 5 6 7 8 9 10 11 12 13 14
Numpy array合并
# Numpy array合并 np.vstack() np.hstack() np.newaxis() np.concatenate() # vertical stack本身属于一种上下合并,即对括号中的两个整体进行对应操作 import numpy as np A = np.array([1,2,3]) B = np.array([4,5,6]) print(np.vstack((A,B))) [[1 2 3] [4 5 6]] C = np.vstack((A,B)) # 数组的维度,几行几列 # A仅仅是一个拥有3项元素的数组(数列),而合并后得到的C是一个2行3列的矩阵。 print(A.shape,C.shape) (3,) (2, 3) # 左右合并 D = np.hstack((A,B)) # horizontal stack print(D) print(A.shape,D.shape) [1 2 3 4 5 6] (3,) (6,) # 转置操作 # 具有3个元素的array转换为了1行3列以及3行1列的矩阵了。 print(A[np.newaxis,:])# 横着的 print('--------------') print(A[:,np.newaxis])# 竖着的 [[1 2 3]] -------------- [[1] [2] [3]] import numpy as np A = np.array([1,1,1])[:,np.newaxis]# 竖着的 B = np.array([2,2,2])[:,np.newaxis]# 竖着的 C = np.vstack((A,B)) # vertical stack # 上下合并 D = np.hstack((A,B)) # horizontal stack 左右合并 print(D) [[1 2] [1 2] [1 2]] # 合并操作需要针对多个矩阵或序列时,借助concatenate函数可能会让你使用起来比前述的函数更加方便: # axis参数很好的控制了矩阵的纵向或是横向打印,相比较vstack和hstack函数显得更加方便。 # 多个array 的纵向或者横向合并 A = np.array([1,1,1])[:,np.newaxis]# 竖着的 B = np.array([2,2,2])[:,np.newaxis]# 竖着的 C = np.concatenate((A,B,B,A),axis=0) # axis=0 上下合并 print(C) print('维度',C.shape) [[1] [1] [1] [2] [2] [2] [2] [2] [2] [1] [1] [1]] 维度 (12, 1) D = np.concatenate((A,B,B,A),axis=1) # 左右合并 print(D) print('维度',D.shape) [[1 2 2 1] [1 2 2 1] [1 2 2 1]] 维度 (3, 4)
Numpy array分割
Numpy array 分割 import numpy as np A = np.arange(12).reshape((3, 4)) print(A) [[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] # 纵向分割 # 参数介绍 split(数组,分割多少片段,分割方向) print(np.split(A, 2, axis=1))# 垂直方向 [array([[0, 1],[4, 5],[8, 9]]), array([[ 2, 3],[ 6, 7],[10, 11]])] # 横向分割 print(np.split(A, 3, axis=0))# 水平方向 [array([[0, 1, 2, 3]]), array([[4, 5, 6, 7]]), array([[ 8, 9, 10, 11]])] # 错误的分割 #print(np.split(A, 3, axis=1)) # 不等量的分割 # 在机器学习时经常会需要将数据做不等量的分割,因此解决办法为np.array_split() print(np.array_split(A, 3, axis=1)) [array([[0, 1], [4, 5], [8, 9]]), array([[ 2], [ 6], [10]]), array([[ 3], [ 7], [11]])] # 在Numpy里还有np.vsplit()与横np.hsplit()方式可用。 print(np.vsplit(A, 3)) #等于 print(np.split(A, 3, axis=0)) print(np.hsplit(A, 2)) #等于 print(np.split(A, 2, axis=1)) [array([[0, 1, 2, 3]]), array([[4, 5, 6, 7]]), array([[ 8, 9, 10, 11]])] [array([[0, 1], [4, 5], [8, 9]]), array([[ 2, 3], [ 6, 7], [10, 11]])]
Numpy copy & deep copy
Numpy copy & deep copy 1、copy 有关联性 # = 的赋值方式会带有关联性 import numpy as np a = np.arange(4) print(a) b = a c = a d = b # 改变a的第一个值,b、c、d的第一个值也会同时改变。 a[0] = 11 print('a',a) # 确认b、c、d是否与a相同。 print('b',b) print('c',c) print('d',d) [0 1 2 3] a [11 1 2 3] b [11 1 2 3] c [11 1 2 3] d [11 1 2 3] # 同样更改d的值,a、b、c也会改变。 d[1:3] = [22, 33] # array([11, 22, 33, 3]) print('d',b) print('a',a) print('c',c) print('d',d) d [11 22 33 3] a [11 22 33 3] c [11 22 33 3] d [11 22 33 3] 2、deep copy没有关联性 # copy() 的赋值方式没有关联性 b = a.copy() # deep copy print('b',b) a[3] = 44 print('a',a) print('b',b) b [11 22 33 3] a [11 22 33 44] b [11 22 33 3]
例题
统计全班的成绩
假设一个团队里有 5 名学员,成绩如下表所示。你可以用 NumPy 统计下这些人在语文、
英语、数学中的平均成绩、最小成绩、最大成绩、方差、标准差。然后把这些人的总成绩
排序,得出名次进行成绩输出。
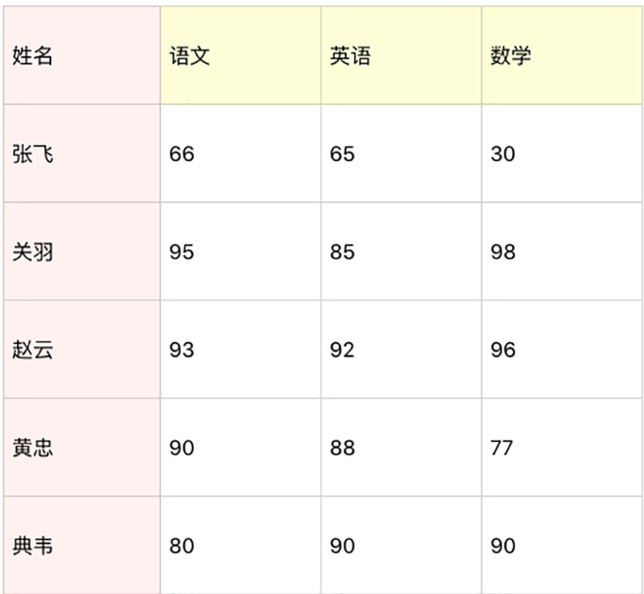
# int8, int16, int32, int64 四种数据类型可以使用字符串 'i1', 'i2','i4','i8' 代替
persontype=np.dtype([('name','S20'),('chinese','i'),('english','i'),('math','i')]) peoples = np.array([("zhangfei",66,85,30),("guanyu",95,85,98), ("zhaoyun",93,92,96),("huangzhong",90,88,77),("dainwei",80,90,90)], dtype=persontype) print(peoples) name = peoples['name'] chinese = peoples['chinese'] english = peoples['english'] math = peoples['math'] print(chinese[0],type(chinese[0])) # 语文、英语、数学中的平均成绩、最小成绩、最大成绩、方差、标准差。然后把这些人的总成绩 # 排序,得出名次进行成绩输出。 print(f""" 语文: 平均成绩:{np.mean(chinese)} 最小成绩:{np.amin(chinese)} 最大成绩:{np.amax(chinese)} 方差:{np.var(chinese)} 标准差:{np.std(chinese)} """) print(f""" 英语: 平均成绩:{np.mean(english)} 最小成绩:{np.amin(english)} 最大成绩:{np.amax(english)} 方差:{np.var(english)} 标准差:{np.std(english)} """) print(f""" 数学: 平均成绩:{np.mean(math)} 最小成绩:{np.amin(math)} 最大成绩:{np.amax(math)} 方差:{np.var(math)} 标准差:{np.std(math)} """) s1 = chinese[0]+english[0]+math[0] s2 = chinese[1]+english[1]+math[1] s3 = chinese[2]+english[2]+math[2] s4 = chinese[3]+english[3]+math[3] s5 = chinese[4]+english[4]+math[4] print(s1,type(s1)) atype=([('name','S20'),('sum','i')]) a=np.array([(peoples['name'][0],s1) ,(peoples['name'][1],s2) ,(peoples['name'][2],s3) ,(peoples['name'][3],s4) ,(peoples['name'][4],s5)] ,dtype=atype) print(np.sort(a['sum'])) ---------------------------------------------------------- [(b'zhangfei', 66, 85, 30) (b'guanyu', 95, 85, 98) (b'zhaoyun', 93, 92, 96) (b'huangzhong', 90, 88, 77) (b'dainwei', 80, 90, 90)] 66 <class 'numpy.int32'> 语文: 平均成绩:84.8 最小成绩:66 最大成绩:95 方差:114.96000000000001 标准差:10.721940122944169 英语: 平均成绩:88.0 最小成绩:85 最大成绩:92 方差:7.6 标准差:2.756809750418044 数学: 平均成绩:78.2 最小成绩:30 最大成绩:98 方差:634.56 标准差:25.19047439013406 181 <class 'numpy.int32'> [181 255 260 278 281]
解决字符串的问题
import numpy as np
new_type = np.dtype([('name', np.str_, 16), ('chinese', np.int32), ('english', np.int32),
('math', np.int32)])
peoples = np.array([("姓名",66,85,30),("张三",95,85,98),
("得到",93,92,96),("王子",90,88,77),("随风倒",80,90,90)],
dtype=new_type)
print(peoples)
------------------------------------------------------------------
[('姓名', 66, 85, 30) ('张三', 95, 85, 98) ('得到', 93, 92, 96)
('王子', 90, 88, 77) ('随风倒', 80, 90, 90)]
悟已往之不谏,知来者之可追。
