1、 网站部署:熟悉Linux基本原理,熟练使用常用的命令,了解Nginux、Uwsgi框架
本地安装:
(1)安装虚拟机
vmware /,vi ɛm 'wɛr/
(2)安装基于linux的系统centos7.5
(3)安装nginx服务器
(4)uwsgi服务器
(5)安装各种工具包+Django+python+mysql数据库

------------------------------------------------------------------------------------
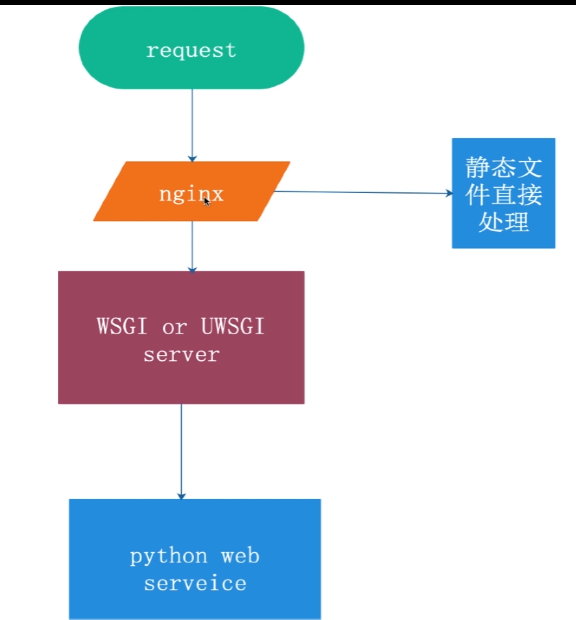
用户发起请求,如果是静态文件的处理可以直接由nginx处理----放在 里面就 可以调用 css
如果访问的动态的,就必须通过WSGI OR uwsgi服务器
2、 熟悉使用git工具并熟悉原理流程,上传下载会用,还有拉取推送怎么弄?
Git 作为一个源码管理系统
版本控制系统
常见版本管理工具:
集中式的版本控制系统,只有一个中央数据仓库,如果中央数据仓库挂了或者不可访问,所有的使用者无法使用SVN,无法进行提交或备份文件。
分布式的版本控制系统 ,在每个使用者电脑上就有一个完整的数据仓库,没有网络依然可以使用Git,当然为了 习惯以团队协作,会将本地数据同步到Git服务器或者Github等代码仓库。
(1)Git的安装和配置
(2)git初始化仓库 git init
git的四个区域:远程仓库、本地仓库、暂存区域、工作目录

git init 初始化仓库
git status 查看状态:
git add -A 直接添加所有改动文件
git add README.md git commit -m "first commit" git remote add origin git@github.com:foremostxiao/aa.git git push -u origin master
克隆:
git clone https://github.com/hemiahwu/vue-basic.git
1.fetch和merge和pull的区别 pull相当于git fetch 和 git merge,即更新远程仓库的代码到本地仓库,然后将内容合并到当前分支。 git fetch:相当于是从远程获取最新版本到本地,不会自动merge git merge : 将内容合并到当前分支 git pull:相当于是从远程获取最新版本并merge到本地 2.tag tag指向一次commit的id,通常用来给开发分支做一个标记 打标签 : git tag -a v1.01 -m "Relase version 1.01" 提交标签到远程仓库 : git push origin --tags 查看标签 : git tag 查看某两次tag之间的commit:git log --pretty=oneline tagA..tagB 查看某次tag之后的commit: git log --pretty=oneline tagA.. 3.Git和SVN的区别 Git是分布式版本控制系统,SVN是集中式版本控制系统 4.Git工作流程 1、在工作目录中修改某些文件 2、对修改后的文件进行快照,然后保存到暂存区域 3、提交更新,将保存在暂存区域的文件快照永久转储到Git目录中 5.常用命令 git show # 显示某次提交的内容 git show $id git add <file> # 将工作文件修改提交到本地暂存区 git rm <file> # 从版本库中删除文件 git reset <file> # 从暂存区恢复到工作文件 git reset HEAD^ # 恢复最近一次提交过的状态,即放弃上次提交后的所有本次修改 git diff <file> # 比较当前文件和暂存区文件差异 git diff git log -p <file> # 查看每次详细修改内容的diff git branch -r # 查看远程分支 git merge <branch> # 将branch分支合并到当前分支 git stash # 暂存 git stash pop #恢复最近一次的暂存 git pull # 抓取远程仓库所有分支更新并合并到本地 git push origin master # 将本地主分支推到远程主分支
github---共有仓库
gitlab----私有仓库
3、Flask---web框架的学习
django大而全 ,flask小而精 python的微框架,也是一个基于MVC设计模式的web框架
官方网站:http://flask.pocoo.org/
Flask依赖的三个库:
jinja2模板引擎
werkzeug WSGI工具集
itsdangerous
from flask import Flask app = Flask(__name__) @app.route('/') def hello_world(): return 'Hello World!' if __name__ == '__main__': app.run()
Vue框架
这里我们就说一下vue,vue是一款有好的、多用途且高性能的JavaScript框架,它能够帮助你创建可维护性和课测试性更强的代码库,vue是渐进式的JavaScript框架,
也就是说如果你已经有一个现成的服务端应用你可以将vue作为该应用的一部分嵌入其中,带来更加丰富的交互体验或者如果你希望将更多的业务逻辑放到前端来实现
那么vue的核心库机器生态系统也可以满足你的各式需求。
与其他框架相同,vue允许你将一个网页分割成可复用的组件,每个组件都包含属于自己的HTML、CSS、JavaScript以用来渲染网页中相应的地方。
什么是Resful API规范
URL定位资源,用HTTP动词(GET,POST,PUT,DELETE)描述操作。
Resource:资源,即数据。
Representational:某种表现形式,比如用JSON,XML,JPEG等;
State Transfer:状态变化。通过HTTP动词实现。
RESTful API就是一套协议来规范多种形式的前端和同一个后台的交互方式。
RESTful API由后台也就是服务端 来提供 前端来调用。前端调用API向后台发起HTTP请求,后台响应请求将处理结果反馈给前端。
也就是说RESTful 是典型的基于HTTP的协议。那么RESTful API有哪些设计原则和规范呢?
GET SELECT :从服务器获取资源。
POST CREATE :在服务器新建资源。
PUT UPDATE :在服务器更新资源。
DELETE DELETE :从服务器删除资源。
--------------------------
1. 轻量,直接基于http,不再需要任何别的诸如消息协议。get/post/put/delete为CRUD操作 2. 面向资源,一目了然,具有自解释性。 3. 数据描述简单,一般以xml,json做数据交换。 4. 无状态,在调用一个接口(访问、操作资源)的时候,可以不用考虑上下文,不用考虑当前状态,极大的降低了复杂度。 5. 简单、低耦合
什么是Django REST framework框架
在前后端分离的应用模式中,我们通常将后端开发的每个视图都称为一个接口,或者API,前端通过访问接口来对数据进行增删改查。
在开发REST API接口时,我们在视图中需要做的最核心的事是:
将数据库数据序列化为前端所需要的格式,并返回;
将前端发送的数据反序列化为模型类对象,并保存到数据库中。
6. Django REST framework 简介
在序列化与反序列化时,虽然操作的数据不尽相同,但是执行的过程却是相似的,也就是说这部分代码是可以复用简化编写的。
开发REST API的视图中,虽然每个视图具体操作的数据不同,但增、删、改、查的实现流程基本套路化,所以这部分代码也是可以复用简化编写的:
增:校验请求数据 -> 执行反序列化过程 -> 保存数据库 -> 将保存的对象序列化并返回
删:判断要删除的数据是否存在 -> 执行数据库删除
改:判断要修改的数据是否存在 -> 校验请求的数据 -> 执行反序列化过程 -> 保存数据库 -> 将保存的对象序列化并返回
查:查询数据库 -> 将数据序列化并返回
Django REST framework可以帮助我们简化上述两部分的代码编写,大大提高REST API的开发速度。
7.认识 Django REST framework 框架
Django REST framework 框架是一个用于构建Web API 的强大而又灵活的工具。
通常简称为DRF框架 或 REST framework。
DRF框架是建立在Django框架基础之上,由Tom Christie大牛二次开发的开源项目。
特点
提供了定义序列化器Serializer的方法,可以快速根据 Django ORM 或者其它库自动序列化/反序列化;
提供了丰富的类视图、Mixin扩展类,简化视图的编写;
丰富的定制层级:函数视图、类视图、视图集合到自动生成 API,满足各种需要;
多种身份认证和权限认证方式的支持;
内置了限流系统;
直观的 API web 界面;
可扩展性,插件丰富
redis数据库的基本使用
是一个高性能的key-value数据库
主要是再弄分布式爬虫中使用
三.redis分布式部署
1.scrapy框架是否可以自己实现分布式?
- 不可以。原因有二。
其一:因为多台机器上部署的scrapy会各自拥有各自的调度器,这样就使得多台机器无法分配start_urls列表中的url。(多台机器无法共享同一个调度器)
其二:多台机器爬取到的数据无法通过同一个管道对数据进行统一的数据持久出存储。(多台机器无法共享同一个管道)
2.redis实现分布式基本流程:
- 使用基于scrapy-redis组件中的爬虫文件。
# 使用scrapy-redis组件的去重队列 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 使用scrapy-redis组件自己的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 是否允许暂停 SCHEDULER_PERSIST = True
- 使用scrapy-redis组件中封装好的管道,将每台机器爬取到的数据存储通过该管道存储到redis数据库中,从而实现了多台机器的管道共享。 ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipeline': 400, } - 执行:scrapy runspider xxx.py,然后向调度器队列中传入起始url:lpush nnspider:start_urls "http://www.xxx.com/"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号