Scrapy框架课程介绍:
- 框架的简介和基础使用
- 持久化存储
- 代理和cookie
- 日志等级和请求传参
- CrawlSpider
- 基于redis的分布式爬虫
一scrapy框架的简介和基础使用
a) 概念:为了爬取网站数据而编写的一款应用框架,出名,强大。所谓的框架其实就是一个集成了相应的功能且具有很强通用性的项目模板。(高性能的异步下载,解析,持久化……)
b) 安装:
i. linux mac os:pip install scrapy
ii. win:
- pip install wheel
- 下载twisted:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
pip install 下载好的框架.whl
- pip install pywin32
- pip install scrapy
c) 基础使用: 使用流程
i. 创建一个工程:scrapy startproject 工程名称
- 目录结构:
ii. 在工程目录下创建一个爬虫文件:
- cd 工程
- scrapy genspider 爬虫文件的名称 起始url
iii. 对应的文件中编写爬虫程序来完成爬虫的相关操作
iv. 配置文件的编写(settings)
v. 执行
vi. 在工程目录下创建一个爬虫文件
- cd 工程
- scrapy genspider 爬虫文件的名称 起始的url
vii. 对应的文件中编写爬虫程序来完成爬虫的相关操作
viii. 配置文件的编写(settings)
- 19行:对请求载体的身份进行伪装
- 22行:不遵从robots协议
ix. 执行 :scrapy crawl 爬虫文件的名称 --nolog(阻止日志信息的输出)

cp后面的数字代表python的版本,35代表3.5版本;

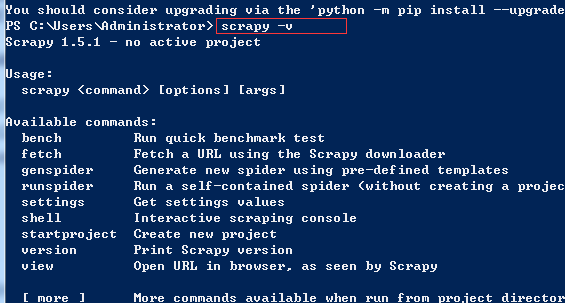
创建项目:
目前还没有IDE 能够创建scrapy的项目,我们必须手动初始化项目
1、找一个目录
输入命令
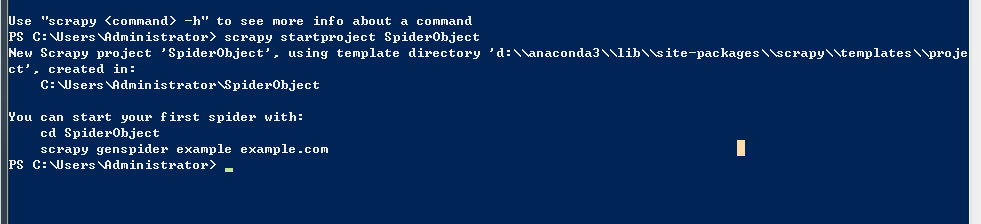
命令行出现这样的结果说明创建成果
You can start your first spider with:
cd SpiderObject
scrapy genspider example example.com
------------------------------------------
基础使用: 使用流程
1、创建一个工程:scrapy startproject 工程名称
在命令行下:
scrapy startproject 项目名称
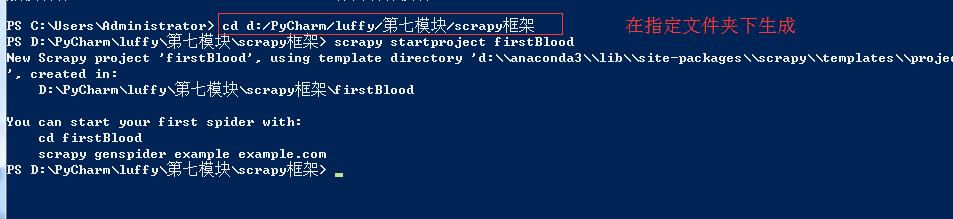
在pycharm中打开:

目录结构:
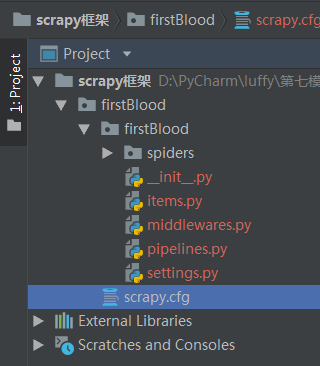
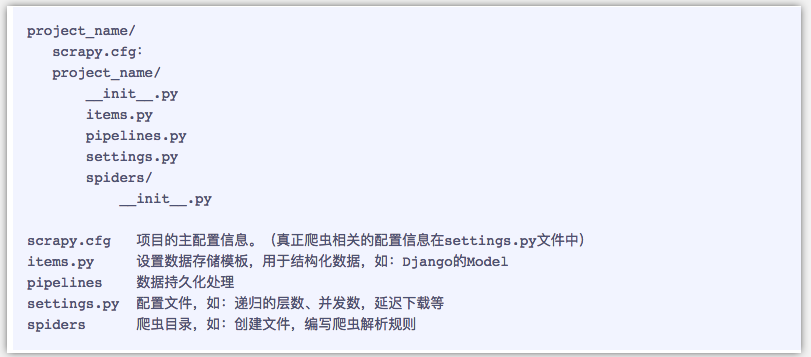
pipelines管道
2.在工程目录下创建一个爬虫文件:
1. 在命令行下 cd 进入工程所在文件夹
2.scrapy genspider 爬虫文件的名称 起始url


class FirstSpider(scrapy.Spider): # 爬虫文件的名称:通过爬虫文件的名称可以指定的定位到某一个具体的爬虫文件 name = 'first' # 允许的域名:只可以爬取指定域名下的页面数据 allowed_domains = ['www.baidu.com'] # 起始url start_urls = ['http://www.baidu.com/'] # 解析方法:对获取的页面数据进行指定内容的解析 # response:根据起始url列表发起请求,请求成功后返回的响应对象 # parse方法返回值:必须为迭代器或者空 def parse(self, response): print(response.text)#获取响应对象中的页面数据 print('执行over')
3.对应的文件中编写爬虫程序来完成爬虫的相关操作
初始阶段settings.py配置
修改内容及其结果如下: 19行:USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' #伪装请求载体身份 22行:ROBOTSTXT_OBEY = False #可以忽略或者不遵守robots协议
进入到项目文件下再执行命令
执行 :scrapy crawl 爬虫文件的名称 --nolog(阻止日志信息的输出)

如果后面加上 --nolog就是阻止日志信息输出
小试牛刀:将糗百首页中段子的内容和标题进行爬取
vi. 在工程目录下创建一个爬虫文件
1. cd 工程 2. scrapy genspider 爬虫文件的名称 起始的url vii. 对应的文件中编写爬虫程序来完成爬虫的相关操作 viii. 配置文件的编写(settings) 1. 19行:对请求载体的身份进行伪装 2. 22行:不遵从robots协议 ix. 执行 :scrapy crawl 爬虫文件的名称 --nolog(阻止日志信息的输出)
class QiubaiSpider(scrapy.Spider): name = 'qiubai' #allowed_domains = ['www.qiushibaike.com/text'] start_urls = ['https://www.qiushibaike.com/text/'] def parse(self, response): # 建议大家使用xpath进行解析(框架集成了xpath解析的接口) div_list = response.xpath("//div[@id='content-left']/div") for div in div_list: author = div.xpath('./div/a[2]/h2/text()') content = div.xpath(".//div[@class='content']/span/text()") print(author)
-------------------------------------

# xpath解析到的指定内容被存储到了Selector对象 # extract()改方法可以将Selector对象数据值拿到 #author = div.xpath('./div/a[2]/h2/text()').extract()[0] author = div.xpath('./div/a[2]/h2/text()').extract_first()

最终形式:
class QiubaiSpider(scrapy.Spider): name = 'qiubai' #allowed_domains = ['www.qiushibaike.com/text'] start_urls = ['https://www.qiushibaike.com/text/'] def parse(self, response): # 建议大家使用xpath进行解析(框架集成了xpath解析的接口) div_list = response.xpath("//div[@id='content-left']/div") for div in div_list: # xpath解析到的指定内容被存储到了Selector对象 # extract()改方法可以将Selector对象数据值拿到 #author = div.xpath('./div/a[2]/h2/text()').extract()[0] # extract()[0]======>extract_first() author = div.xpath('./div/a[2]/h2/text()').extract_first() #content = div.xpath(".//div[@class='content']/span/text()") content = div.xpath(".//div[@class='content']/span/text()").extract_first() print(author) print(content)

