Selenium用法
初步使用Selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
_input = browser.find_element_by_id('kw')
_input.send_keys('Python')
_input.send_keys(Keys.ENTER)
wait = WebDriverWait(browser, 10)
wait.until(EC.presence_of_element_located((By.ID, 'content_left')))
print(browser.current_url)
print(browser.get_cookies())
print(browser.page_source)
finally:
browser.close()
访问单个节点
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element_by_id('q')
input_second = browser.find_element_by_css_selector('#q')
input_third = browser.find_element_by_xpath('//*[@id="q"]')
print(input_first, input_second, input_third)
browser.close()
访问单个节点的所有方法
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
访问单个节点的通用方法
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element(By.ID, 'q')
print(input_first)
browser.close()
多个节点
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
lis = browser.find_elements_by_css_selector('.service-bd li')
print(lis)
browser.close()
所有方法
find_elements_by_id
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
节点交互
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
_input = browser.find_element_by_id('q')
_input.send_keys('iPhone')
time.sleep(1)
_input.clear()
_input.send_keys('iPad')
button = browser.find_element_by_class_name('btn-search')
button.click()
动作链
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
target = browser.find_element_by_css_selector('#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
切换frame
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
try:
logo = browser.find_element_by_class_name('logo')
except NoSuchElementException:
print('NO LOGO')
browser.switch_to.parent_frame()
logo = browser.find_element_by_class_name('logo')
print(logo)
print(logo.text)
隐式等待
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait(10)
browser.get('https://dynamic2. scrape.cuiqingcai.com/')
_input = browser.find_element_by_class_name('logo-image')
print(_input)
显式等待
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://www.taobao.com/')
wait = WebDriverWait(browser, 10)
_input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search')))
print(_input, button)
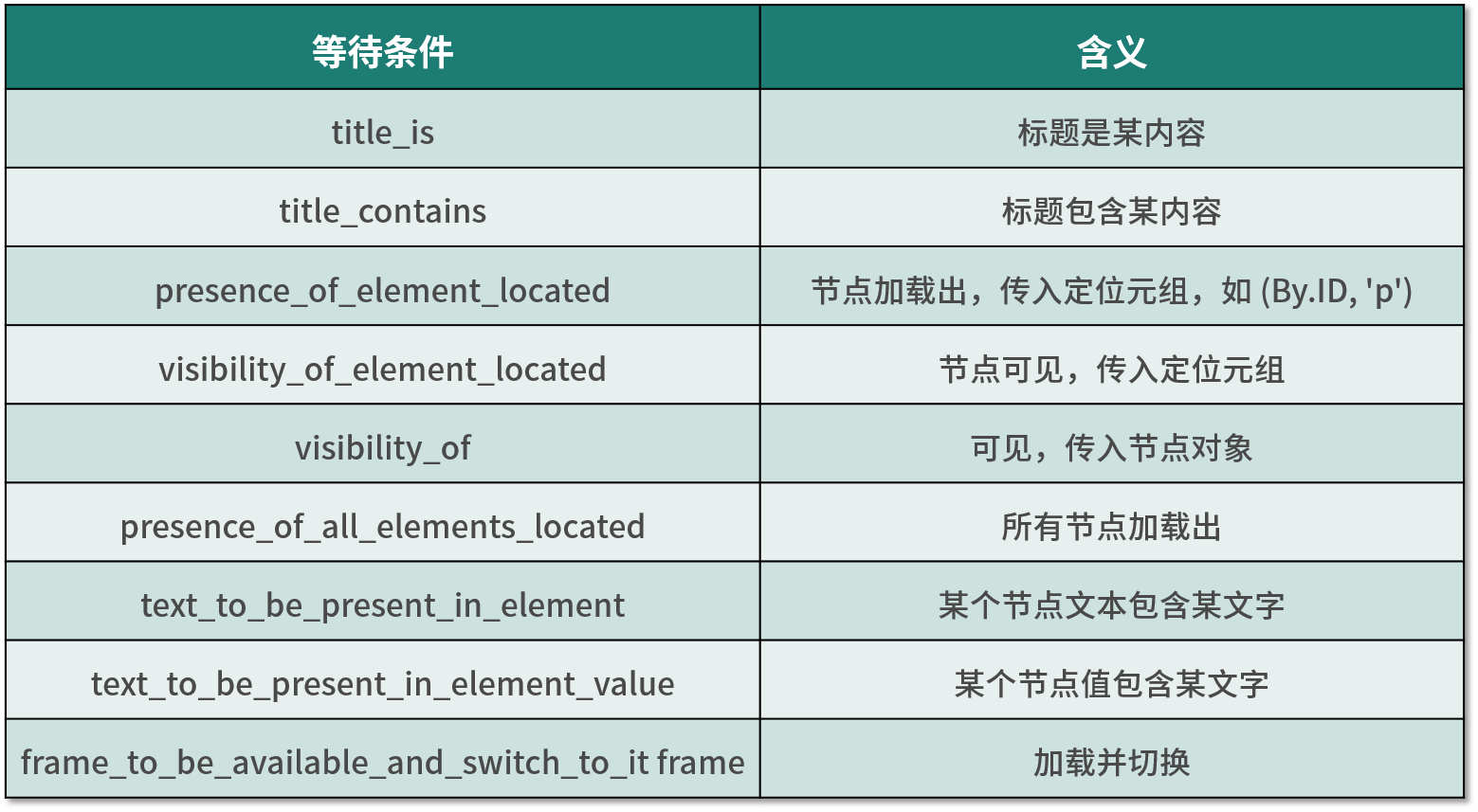
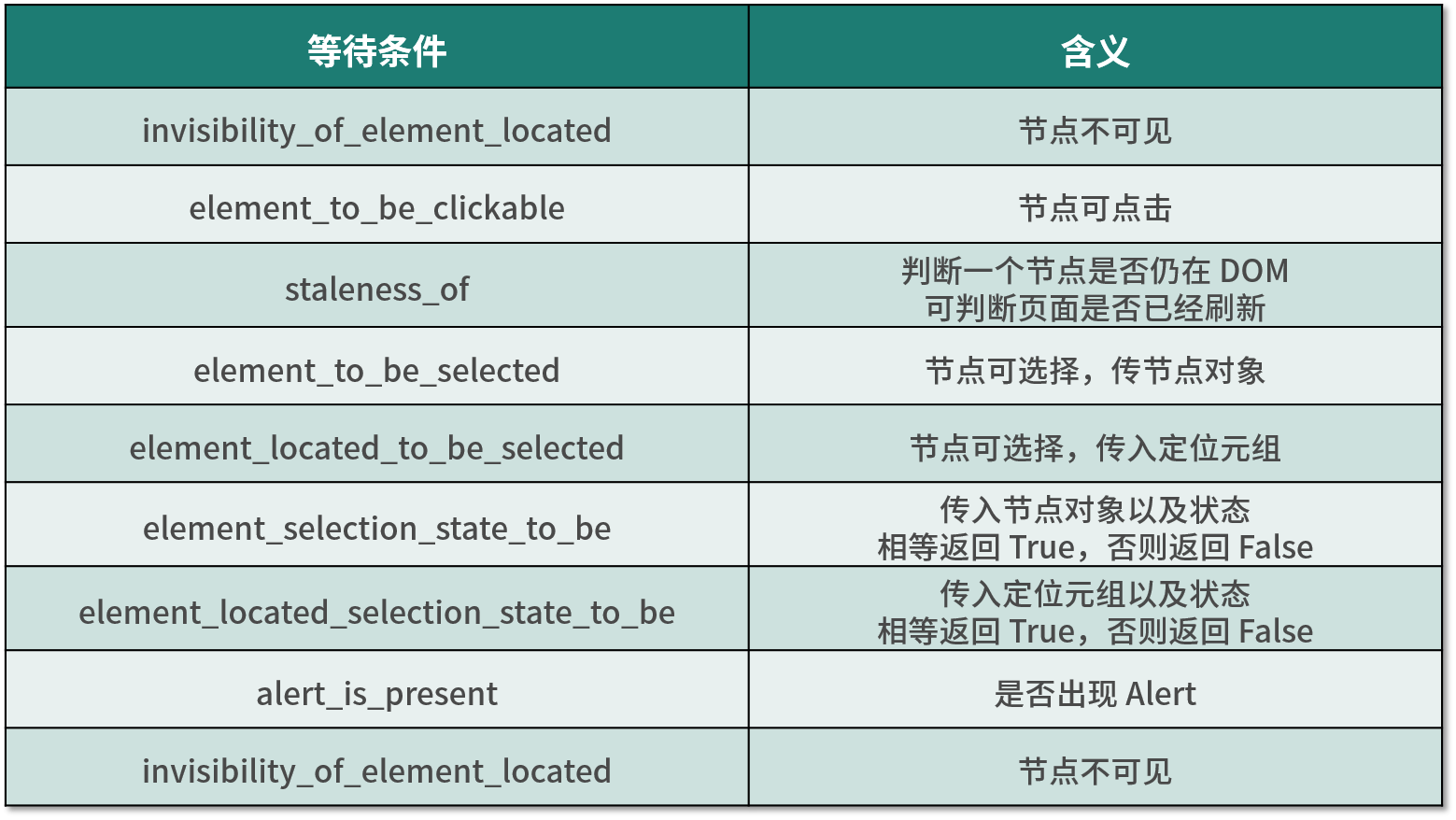
等待条件
选项卡管理
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles)
browser.switch_to.window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to.window(browser.window_handles[0])
browser.get('https://python.org')
反屏蔽
现在很多网站都加上了对 Selenium 的检测,来防止一些爬虫的恶意爬取。即如果检测到有人在使用 Selenium 打开浏览器,那就直接屏蔽。
其大多数情况下,检测基本原理是检测当前浏览器窗口下的 window.navigator 对象是否包含 webdriver 这个属性。因为在正常使用浏览器的情况下,这个属性是 undefined,然而一旦我们使用了 Selenium,Selenium 会给 window.navigator 设置 webdriver 属性。很多网站就通过 JavaScript 判断如果 webdriver 属性存在,那就直接屏蔽。
在 Selenium 中,我们可以使用 CDP(即 Chrome Devtools-Protocol,Chrome 开发工具协议)来解决这个问题,通过 CDP 我们可以实现在每个页面刚加载的时候执行 JavaScript 代码,执行的 CDP 方法叫作 Page.addScriptToEvaluateOnNewDocument,然后传入上文的 JavaScript 代码即可,这样我们就可以在每次页面加载之前将 webdriver 属性置空了。另外我们还可以加入几个选项来隐藏 WebDriver 提示条和自动化扩展信息,代码实现如下:
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
browser = webdriver.Chrome(options=option)
browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'
})
browser.get('https://antispider1.scrape.cuiqingcai.com/')
无头模式
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_argument('--headless')
browser = webdriver.Chrome(options=option)
browser.set_window_size(1366, 768)
browser.get('https://www.baidu.com')
browser.get_screenshot_as_file('preview.png')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号