lucene.net全文检索(一)相关概念及示例
相关概念
站内搜索
站内搜索通俗来讲是一个网站或商城的“大门口”,一般在形式上包括两个要件:搜索入口和搜索结果页面,但在其后台架构上是比较复杂的,其核心要件包括:中文分词技术、页面抓取技术、建立索引、对搜索结果排序以及对搜索关键词的统计、分析、关联、推荐等。
比较常见的就是电商网站中首页的搜索框,它可以根据关键词(分词)、分类、商品简介、详情等搜索商品信息,可以根据相关度、价格、销量做排序。


全文检索
Lucene.Net
Lucene.net是Lucene的.net移植版本,用C#编写,它完成了全文检索的功能——预先把数据拆分成原子(字/词),保存到磁盘中;查询时把关键字也拆分成原子(字/词),再根据(字/词)进行匹配,返回结果。
Nuget安装“Lucene.Net”和“Lucene.Net.Analysis.PanGu”(盘古分词,一个第三方的分词器)
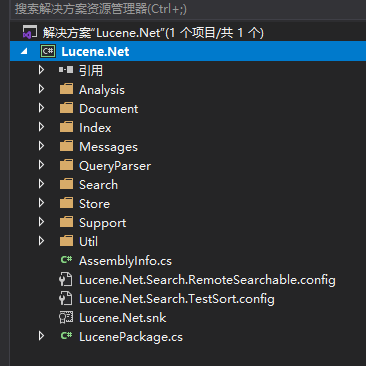
lucene.net七大对象
1、Analysis
分词器,负责把字符串拆分成原子,包含了标准分词,直接空格拆分。项目中用的是盘古中文分词。

2、Document
数据结构,定义存储数据的格式

3、Index:索引的读写类

4、QueryParser:查询解析器,负责解析查询语句

5、Search:负责各种查询类,命令解析后得到就是查询类

6、Store:索引存储类,负责文件夹等等

7、Util:常见工具类库
git地址:https://github.com/apache/lucenenet/releases/tag/Lucene.Net_3_0_3_RC2_final
索引库-写示例
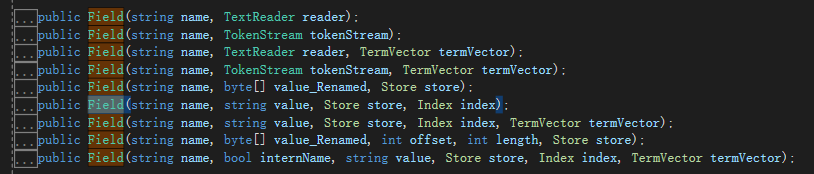
List<Commodity> commodityList = GetList();//获取数据源 FSDirectory directory = FSDirectory.Open(StaticConstant.TestIndexPath);//文件夹 //经过分词以后把内容写入到硬盘 //PanGuAnalyzer 盘古分词;中华人民共和国,从后往前匹配,匹配到和词典一样的词,就保存起来;建议大家去看看盘古分词的官网;词典是可以我们手动去维护; //城会玩---网络流行词--默认没有,盘古分词,可以由我们自己把这些词给添加进去; using (IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), true, IndexWriter.MaxFieldLength.LIMITED))//索引写入器 { foreach (Commodity commdity in commodityList) { for (int k = 0; k < 10; k++) { Document doc = new Document();//一条数据 doc.Add(new Field("id", commdity.Id.ToString(), Field.Store.NO, Field.Index.NOT_ANALYZED));//一个字段 列名 值 是否保存值 是否分词 doc.Add(new Field("title", commdity.Title, Field.Store.YES, Field.Index.ANALYZED)); doc.Add(new Field("url", commdity.Url, Field.Store.NO, Field.Index.NOT_ANALYZED)); doc.Add(new Field("imageurl", commdity.ImageUrl, Field.Store.NO, Field.Index.NOT_ANALYZED)); doc.Add(new Field("content", "this is lucene working,powerful tool " + k, Field.Store.YES, Field.Index.ANALYZED)); doc.Add(new NumericField("price", Field.Store.YES, true).SetDoubleValue((double)(commdity.Price + k))); //doc.Add(new NumericField("time", Field.Store.YES, true).SetLongValue(DateTime.Now.ToFileTimeUtc())); doc.Add(new NumericField("time", Field.Store.YES, true).SetIntValue(int.Parse(DateTime.Now.ToString("yyyyMMdd")) + k)); writer.AddDocument(doc);//写进去 } } writer.Optimize();//优化 就是合并 }



索引库——读示例
FSDirectory dir = FSDirectory.Open(StaticConstant.TestIndexPath); IndexSearcher searcher = new IndexSearcher(dir);//查找器 { FuzzyQuery query = new FuzzyQuery(new Term("title", "高中政治")); //TermQuery query = new TermQuery(new Term("title", "周年"));//包含 TopDocs docs = searcher.Search(query, null, 10000);//找到的数据 foreach (ScoreDoc sd in docs.ScoreDocs) { Document doc = searcher.Doc(sd.Doc); Console.WriteLine("***************************************"); Console.WriteLine(string.Format("id={0}", doc.Get("id"))); Console.WriteLine(string.Format("title={0}", doc.Get("title"))); Console.WriteLine(string.Format("time={0}", doc.Get("time"))); Console.WriteLine(string.Format("price={0}", doc.Get("price"))); Console.WriteLine(string.Format("content={0}", doc.Get("content"))); } Console.WriteLine("1一共命中了{0}个", docs.TotalHits); } QueryParser parser = new QueryParser(Version.LUCENE_30, "title", new PanGuAnalyzer());//解析器 { // string keyword = "高中政治人教新课标选修生活中的法律常识"; string keyword = "高中政治 人 教 新课 标 选修 生活 中的 法律常识"; { Query query = parser.Parse(keyword); TopDocs docs = searcher.Search(query, null, 10000);//找到的数据 int i = 0; foreach (ScoreDoc sd in docs.ScoreDocs) { if (i++ < 1000) { Document doc = searcher.Doc(sd.Doc); Console.WriteLine("***************************************"); Console.WriteLine(string.Format("id={0}", doc.Get("id"))); Console.WriteLine(string.Format("title={0}", doc.Get("title"))); Console.WriteLine(string.Format("time={0}", doc.Get("time"))); Console.WriteLine(string.Format("price={0}", doc.Get("price"))); } } Console.WriteLine($"一共命中{docs.TotalHits}"); } { Query query = parser.Parse(keyword); NumericRangeFilter<int> timeFilter = NumericRangeFilter.NewIntRange("time", 20090101, 20201231, true, true);//过滤 SortField sortPrice = new SortField("price", SortField.DOUBLE, false);//false::降序 SortField sortTime = new SortField("time", SortField.INT, true);//true:升序 Sort sort = new Sort(sortTime, sortPrice);//排序 哪个前哪个后 TopDocs docs = searcher.Search(query, timeFilter, 10000, sort);//找到的数据 //可以做什么?就可以分页查询! int i = 0; foreach (ScoreDoc sd in docs.ScoreDocs) { if (i++ < 1000) { Document doc = searcher.Doc(sd.Doc); Console.WriteLine("***************************************"); Console.WriteLine(string.Format("id={0}", doc.Get("id"))); Console.WriteLine(string.Format("title={0}", doc.Get("title"))); Console.WriteLine(string.Format("time={0}", doc.Get("time"))); Console.WriteLine(string.Format("price={0}", doc.Get("price"))); } } Console.WriteLine("3一共命中了{0}个", docs.TotalHits); } }




多线程写入索引库示例
try { logger.Debug(string.Format("{0} BuildIndex开始",DateTime.Now)); List<Task> taskList = new List<Task>(); TaskFactory taskFactory = new TaskFactory(); CTS = new CancellationTokenSource(); //30个表 30个线程 不用折腾,一线程一表 平均分配 //30个表 18个线程 1到12号2个表 13到18是一个表? 错的!前12个线程活儿多,后面的活少 //自己去想想,怎么样可以做,随便配置线程数量,但是可以均匀分配任务? for (int i = 1; i < 31; i++) { IndexBuilderPerThread thread = new IndexBuilderPerThread(i, i.ToString("000"), CTS); PathSuffixList.Add(i.ToString("000")); taskList.Add(taskFactory.StartNew(thread.Process));//开启一个线程 里面创建索引 } taskList.Add(taskFactory.ContinueWhenAll(taskList.ToArray(), MergeIndex)); Task.WaitAll(taskList.ToArray()); logger.Debug(string.Format("BuildIndex{0}", CTS.IsCancellationRequested ? "失败" : "成功")); } catch (Exception ex) { logger.Error("BuildIndex出现异常", ex); } finally { logger.Debug(string.Format("{0} BuildIndex结束", DateTime.Now)); }
private static void MergeIndex(Task[] tasks) { try { if (CTS.IsCancellationRequested) return; ILuceneBulid builder = new LuceneBulid(); builder.MergeIndex(PathSuffixList.ToArray()); } catch (Exception ex) { CTS.Cancel(); logger.Error("MergeIndex出现异常", ex); } }
///<summary>
/// 将索引合并到上级目录 /// </summary> /// <param name="sourceDir">子文件夹名</param> public void MergeIndex(string[] childDirs) { Console.WriteLine("MergeIndex Start"); IndexWriter writer = null; try { if (childDirs == null || childDirs.Length == 0) return; Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_30); string rootPath = StaticConstant.IndexPath; DirectoryInfo dirInfo = Directory.CreateDirectory(rootPath); LuceneIO.Directory directory = LuceneIO.FSDirectory.Open(dirInfo); writer = new IndexWriter(directory, analyzer, true, IndexWriter.MaxFieldLength.LIMITED);//删除原有的 LuceneIO.Directory[] dirNo = childDirs.Select(dir => LuceneIO.FSDirectory.Open(Directory.CreateDirectory(string.Format("{0}\\{1}", rootPath, dir)))).ToArray(); writer.MergeFactor = 100;//控制多个segment合并的频率,默认10 writer.UseCompoundFile = true;//创建符合文件 减少索引文件数量 writer.AddIndexesNoOptimize(dirNo); } finally { if (writer != null) { writer.Optimize(); writer.Close(); } Console.WriteLine("MergeIndex End"); } }


付费内容,请联系本人QQ:1002453261
本文来自博客园,作者:明志德道,转载请注明原文链接:https://www.cnblogs.com/for-easy-fast/p/14318803.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号