EntityFramework6 相关知识
什么是ORM?
ORM是一种工具,可以自动地把领域对象数据存储到关系型数据库(如MS SQL Server),而不需要大量的编码。
O/RM包含三个重要的部分:
1. 领域对象(Domain class objects):我们定义的类。
2. 关系型数据库对象(Relational database objects):数据库表,视图,存储过程等。
3. 映射信息(Mapping information):领域对象与关系型数据库对象之间转换的信息。
O/RM允许开发者把数据库设计和领域对象设计独立开,让程序更具有可维护性和可扩展性。
它还提供了基本的增删改查的功能,开发者不需要手动再编写这部分代码。
一个典型的数据库与应用程序的O/RM交互如下图所示:

什么是EF?
EF是一种ORM(Object-relational mapping)框架,以ADO.NET为基础发展出来的对象关系映射解决方案,也就是对象模型和关系模型数据库的数据结构之间的相互转换;ORM负责把对象模型映射到基于SQL的关系模型数据库结构中,这样在具体操作实体对象的时候,就不需要再去和复杂的SQL语句打交道了,只需要简单的操作实体对象的属性和方法,即用操作对象的方式进行数据库操作;
| 版本 | 引入功能 |
|---|---|
| EF 3.5 | Database First模式下基本的O/RM支持。 |
| EF 4.0 | POCO的支持, 懒加载, 可测试性提升,定制化代码生成,以及引入Model First开发模式。 |
| EF 4.1 | 在ObjectContext的基础上简化了DBContext API,引入Code First开发模式。 |
| EF 4.3 | 引入Code First Migrations,可以根据定义的Code First模型来创建或修改数据库。 |
| EF 5.0 | 宣布EF为开源项目。引入了枚举支持,表值函数, 空间数据类型,模型多图表,设计界面着色形状,批量导入存储过程,EF Power Tools,以及各种性能提升。 |
| EF 6.0 | 引入了许多Code First & EF设计相关的新功能,如异步操作(asynchronous),弹性连接(connection resiliency),依赖解析(dependency resolution)等。 |
注:Entity Framework Core不在本文讨论范围。
Entity Framework的总体结构如下图所示。

EDM(Entity Data Model):EDM包含三个主要的部分 - 概念模型(Conceptual model)、存储模型(Storage model)和映射(Mapping)。
1. Conceptual model:概念模型包含了模型的类定义,以及类之间的关系。概念模型的设计独立于数据库表设计。
2. Storage model:存储模型是数据库设计模型,包含了数据库表,视图,存储过程,以及它们的之间的关系和键。
3. Mapping:映射包含了概念模型映射到存储模型的相关信息。
LINQ to Entities:一种基于对象模型编写的查询语言,它将返回概念模型中设计的实体。
Entity SQL:另一种和LINQ to Entities相似的查询语言,但是它们还是有一些差异的,开发者还是需要单独花时间去学习它。
Object Service:数据库数据访问的主要入口,主要职责是物化(materialization),把Entity Client Data Provider返回的数据转换成实体对象结构。
Entity Client Data Provider:把LINQ to Entities或Entity SQL转换成数据库SQL。和ADO.Net Data Provider进行通讯,发送或检索数据库数据。
ADO.Net Data Provider:ADO.Net Data Provider使用标准的ADO.Net和数据库进行交互。
EF开发模式
Entity Framework提供了三种开发模式:
1. Code First
2. Database First
3. Model First

在Code First的开发模式中,要避免使用视觉模型设计器(EDMX),一般是先编写POCO类,然后根据这些类去生成数据库。
那些遵循领域驱动开发(DDD)原则的开发者,更倾向于一开始先编写自己的领域类,然后再生成数据库来实现数据持久化。
Code First 有两种配置数据库映射的方式,一种是使用数据属性DataAnnotation,另外一种是使用Fluent API。
DataAnnotation的配置方式需要给实体类和类中的属性加上与数据库映射相关的配置标签。常见配置标签如下:
[Key]------主键,[Required]------非空,[MaxLenth],[MinLength],[StringLength]-----长度限制,[Table]-----表名,[Column]-----列名,[DatabaseGenerated]自增长,
[ForeignKey]----外键,[NotMapped]-----忽略映射
要使用Fluent API 就必须在自定义的继承自DbContext类中重载OnModelCreating方法。这个方法签名如下:
protected override void OnModelCreating(DbModelBuilder modelBuilder)
通过modelBuilder这个对象的Entity<>泛型方法类配置DbContext中的每个类的数据库映射
例如通过Fluent API配置数据库表的名字:
protected override void OnModelCreating(DbModelBuilder modelBuilder) { modelBuilder.Entity<Customer>().ToTable("CustomerInfo"); }
过程演示:
1.右键EFDemo解决方案,“添加-》新建项目-》控制台应用程序”,修改项目名称为CodeFirst
2.右键CodeFirst项目引用,选择“管理NuGet程序包”,搜索entity freamwork,安装entity freamwork包,如下图:

3.创建模型
添加一个Models文件夹,在Models下新建Order和OrderDetial模型
public class Order { /// <summary> /// Id 或者 类名+Id 的属性,默认会当成主键 ,不用添加[Key]特性 /// </summary> [Key] public long OrderId { get; set; } /// <summary> /// 订单号 /// </summary> [StringLength(50)] public string OrderCode { get; set; } /// <summary> /// 订单金额 /// </summary> public decimal OrderAmount { get; set; } /// <summary> /// 导航属性设置成virtual,可以实现延迟加载 /// </summary> public virtual List<OrderDetail> OrderDetail { get; set; } }
public class OrderDetail { [Key] public long OrderDetailId { get; set; } /// <summary> /// 订单明细单价 /// </summary> public decimal Price { get; set; } /// <summary> /// 订单明细数量 /// </summary> public int Count { get; set; } /// <summary> /// 外键,如果属性名称和Order主键名称一样,默认会当成外键,可以不加[ForeignKey]特性 /// 注意,ForeignKey里面的值要和导航属性的名称一致 /// </summary> [ForeignKey("Order")] public long OrderId { get; set; } /// <summary> /// 导航属性 /// </summary> public virtual Order Order { get; set; } }
4.在配置文件中配置连接字符串
在App.config中添加如下配置节点,注意provideName必须填写,否则报错
<connectionStrings> <add name="CodeFirstContext" connectionString="Data Source=SC-201703312219;Initial Catalog=EFDemoDB;Integrated Security=True" providerName="System.Data.SqlClient" /> </connectionStrings>
5.创建上下文类CodeFirstContext
public class CodeFirstContext : DbContext { public CodeFirstContext() : base("name=CodeFirstContext") { } public virtual DbSet<Order> Orders { get; set; } public virtual DbSet<OrderDetail> OrderDetails { get; set; } protected override void OnModelCreating(DbModelBuilder modelBuilder) { //Database.SetInitializer<CodeFirstContext>(null);//不检查 // Database.SetInitializer<CodeFirstContext>(new DropCreateDatabaseIfModelChanges<CodeFirstContext>());//模型修改了 删除数据库 Database.SetInitializer<CodeFirstContext>(new DropCreateDatabaseAlways<CodeFirstContext>());//每次启动都删除数据库 }
6.调用插入数据
static void Main(string[] args) { try { using (CodeFirstContext context = new CodeFirstContext()) { Order order = new Order() { OrderCode="sdfdsgdfgrertef", OrderAmount=74.23M, }; context.Orders.Add(order); context.SaveChanges(); } Console.WriteLine("完成!"); } catch (Exception ex) { Console.WriteLine(ex.Message); } Console.ReadKey(); }
Database First:

通过已有的数据库来生成EDMX(Entity Data Model)的开发模式就是Database First的开发模式。
如果数据库变更了,EDMX(Entity Data Model)也会更新。同时,Database First也支持存储过程,视图等。
过程演示:
1.创建一个空白解决方法EFDemo,在EFDemo下创建一个控制台应用程序EFDBFirst,右键添加新项,选择实体数据模型,创建实体数据模型EFDBFirstModel

2.选择模型类型

3.新建数据库连接,本例以Northwind数据库为例



4.生成的文件结构如下:

5.在代码中访问上下文插入数据到数据库中:



Model First是Code First和Database First的一种折中开发模式,它提供视觉模型设计器(EDMX)来设计数据模型,然后根据数据库模型来生成数据库以及领域类。
过程演示:
1.右键解决方法“EFDemo”,选择“添加项目-》控制台应用程序”,并将名称改为ModelFirst
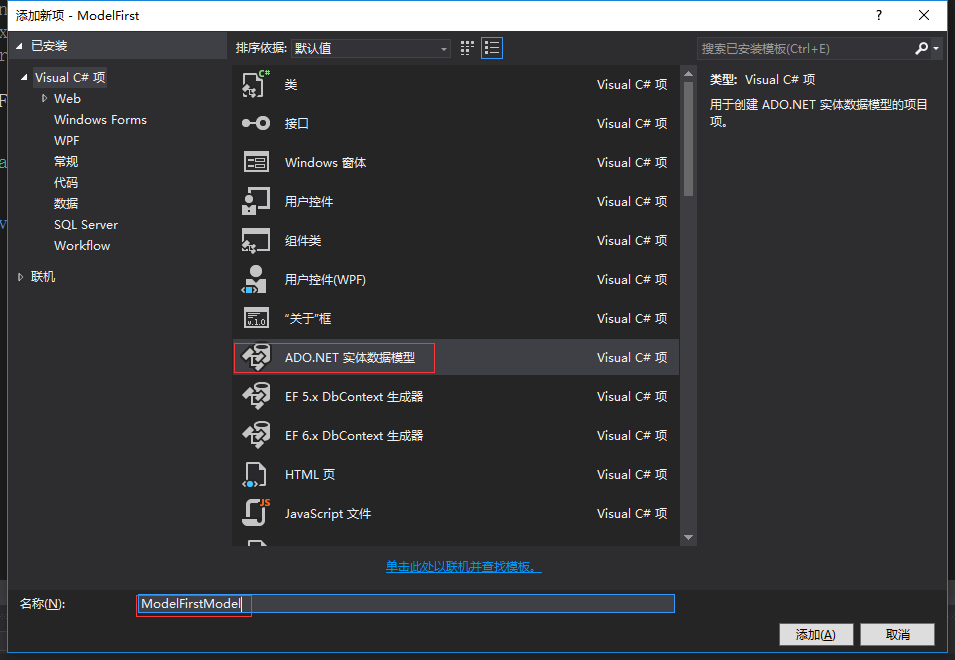
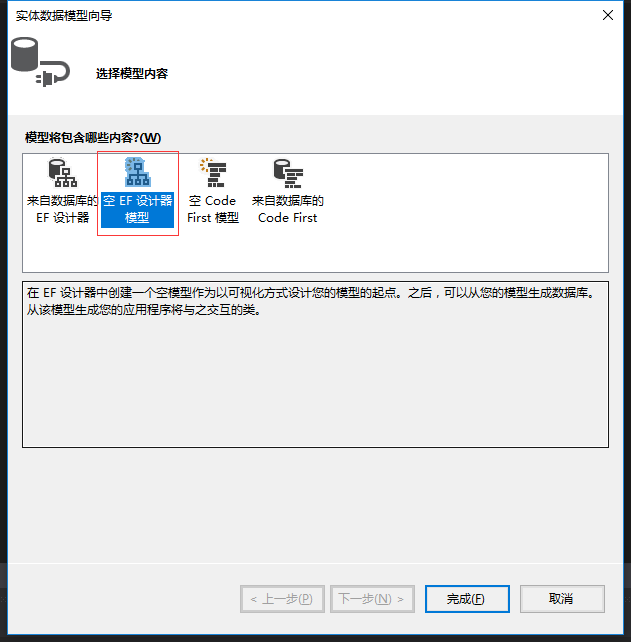
2.右键ModelFirst项目,再选择“添加新建项-》ADO.NET实体数据模型”,并命名为ModelFirstModel.edmx,下一步,选择“空EF设计器模型”,完成。
步骤如下图:
3.添加实体Customer
3.1右键模式设计器空白处,选择“新增-》实体”,添加Customer实体

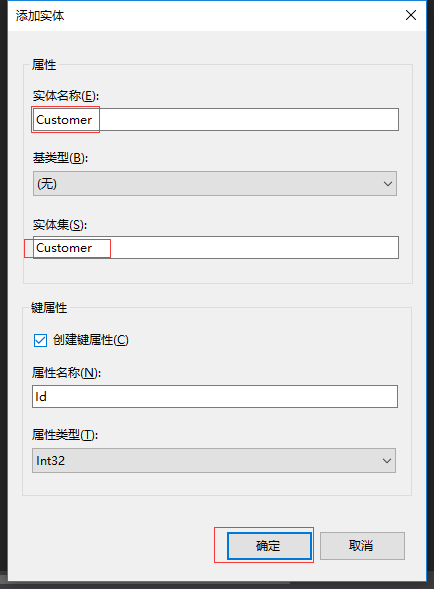
3.2添加标量属性。标量属性可以看成数据库中的普通字段(主键和外键之外的),我们在设计字段属性时,
一定要记得设置其最大范围,否则最终会生成一个比较大的默认范围,严重影响性能

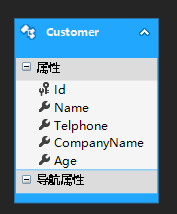
再依次添加标量属性Telphone、CompanyName、Age
4.添加实体之间的联系
4.1在添加一个Product实体,属性类型设为Guid
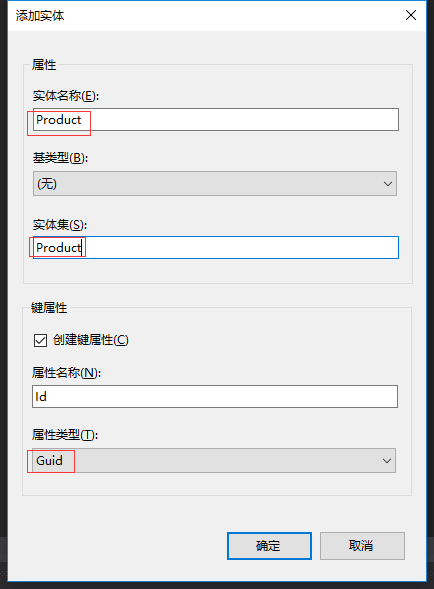
再依次添加标量属性Name、Price、Weight
4.2 再添加实体Order以及标量属性OrderNo、Amount、CreateTime
4.3 添加实体之间的关联,右键设计器面板空白处“新增-》关联”
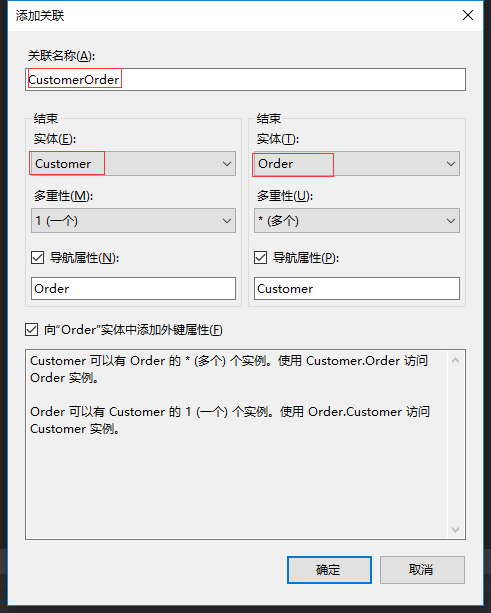
Customer和Order 是一个一对多的关系。我们再添加Customer和Product多对多的关联
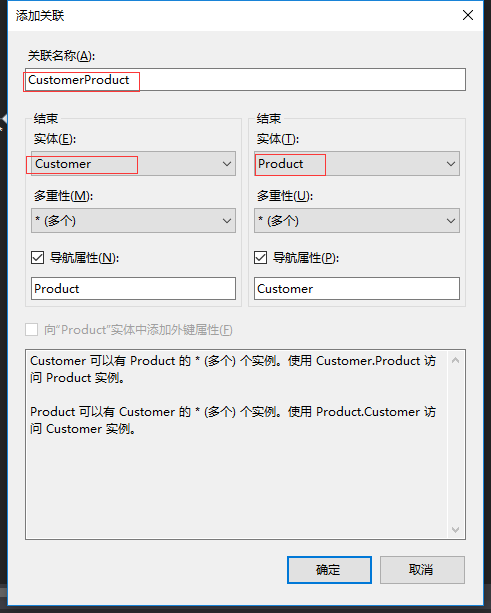
最终结果如下图:
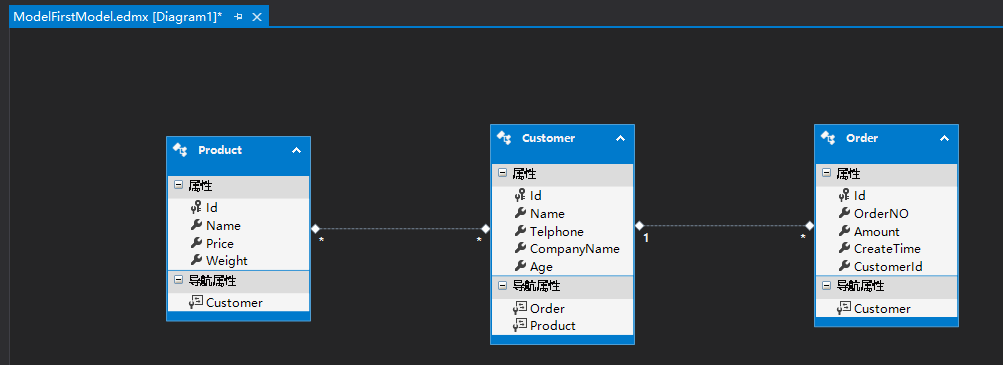
说明:这里只是为了演示,在实际项目中商品是和订单明细关联的
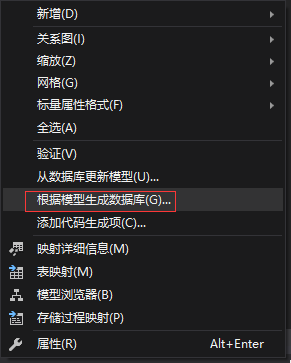
5.根据模型创建数据库
右键模型设计器界面空白处,选择“根据模型生成数据库”
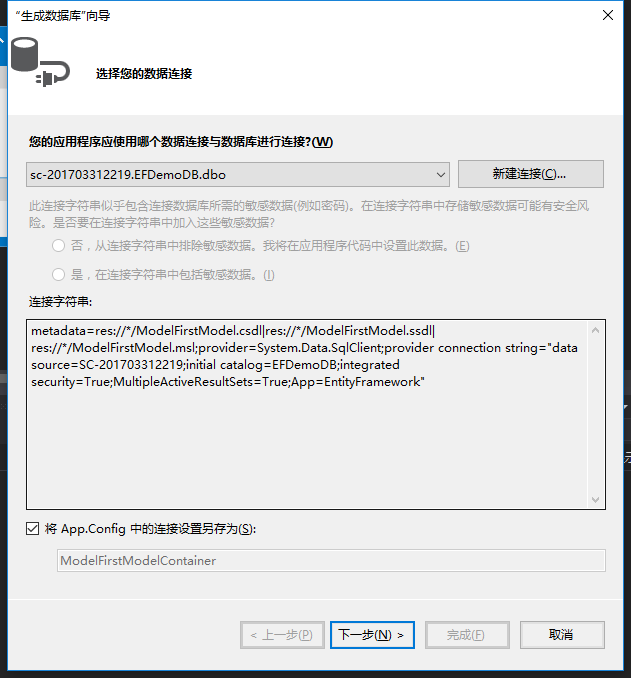
单击“下一步-》完成”,生成DLL脚本,然后执行生成的DLL脚本
执行DLL脚本后,数据库中出现了4张表
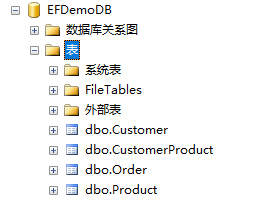
CustomerProduct是怎么回事呢?因为我们之前添加了多对多关联,而多对多关联就是通过一张新表来实现存储的。
总结:
1. Code First是先编写领域类,然后根据类来生成数据库,无视觉模型设计器(EDMX)。
2. Database First是根据数据库生成视觉模型设计器(EDMX)及领域类。
3. Model First是先生成视觉模型设计器(EDMX),然后根据EDMX生成数据库及领域类。
DbContext

DbContext是Entity Framework的一个重要部分,它是领域或实体类与数据库之间的桥梁。
DbContext是一个很重要的类,主要职责是以对象的方式和数据进行交互,它包含以下活动:
EntitySet:DbContext包含实体集合(DbSet<TEntity>),把实体映射到数据库表。
Querying:DbContext把LINQ to Entities查询转换成SQL查询,并发送到数据库。
Change Tracking:DbContext会跟踪从数据库查询出来的实体的状态变更。
Persisting Data:DbContext根据实体的状态提供插入,更新和删除等数据库操作。
Caching:DbContext默认实现一级缓存,在Context类的生命周期期间,它会保存检索出来的实体。
Manage Relationship:
Object Materialization:DbContext把表原始数据转换成实体对象。
EF原理
-
EF会自动把Where()、OrderBy()、 Select()等这些编译 成“表达式树(Expression Tree)",然后会把表达式树翻译成SQL语句去执行;
-
如何查看真正执行的SQL是什么?
DBContext有一个Database属性,其中的Log属性,是Action委托类型,可以指向一个voidA(strings)方法,其中的参数就是执行的SQL语句,每次EF执行SQL语句时候都会执行Log,就可以知道执行了什么SQL;
EF中查询是“延迟执行的”,在foreach之后执行,
//实例化数据库上下文 using (var db = new Model1()) { db.Database.Log = (sql) => { Console.WriteLine("********Log********" + sql); }; //普通查询 var result = (from u in db.user where u.Id > 0 select u); Console.WriteLine("准备开始foreach"); foreach (var users in result) { Console.WriteLine("用户ID:" + users.Id + " 姓名:" + users.username + " 密码:" + users.password + " 邮箱:" + users.email); } Console.ReadKey(); }

Lambda
Where用法
Where用法相对比较简单,多个并列条件可以在一个Where中用&&符号链接,也可以写多个Where,最终的结果结果相同
#region 01-where用法 { //1. where用法 //1.1 查询账号为admin的用户信息 Console.WriteLine("---------------------------- 1. where用法 ----------------------------------------"); Console.WriteLine("---------------------------- 1.1 查询账号为admin的用户信息 ----------------------------------------"); List<Sys_UserInfor> sUserList1 = db.Sys_UserInfor.Where(u => u.userAccount == "admin").ToList(); foreach (var item in sUserList1) { Console.WriteLine("用户名:{0},用户账号:{1},用户年龄:{2},用户性别:{3}", item.userName, item.userAccount, item.userAge, item.userSex); } //1.2 查询账号为中包含admin且性别为男的用户信息 Console.WriteLine("---------------------------- 1.2 查询账号为中包含admin且性别为男的用户信息 ----------------------------------------"); List<Sys_UserInfor> sUserList2 = db.Sys_UserInfor.Where(u => u.userAccount.Contains("admin") && u.userSex == "男").ToList(); foreach (var item in sUserList2) { Console.WriteLine("用户名:{0},用户账号:{1},用户年龄:{2},用户性别:{3}", item.userName, item.userAccount, item.userAge, item.userSex); } } #endregion

Select用法
Select中可以查询所有数据,也可以查询指定字段。
当查询所有数据的时候可以这么写:var sUserList22 = db.Sys_UserInfor.Where(u => u.userAccount.Contains("admin")).Select(u=>u).ToList(); 或者直接可以省略Select部分。
当查询部分数据的时候: 可以用匿名类,也可以用实体。
即使用匿名类的时候,也可以指定列名,不指定的话,默认和数据库的列名一致。
#region 02-select用法 (匿名类和非匿名类写法) { //2. select用法 (匿名类和非匿名类写法) //2.1 查询账号中包含 admin 的用户的 姓名、年龄和性别 三条信息 (匿名类的写法,自动生成匿名类名称) Console.WriteLine("---------------------------- 2. select用法 (匿名类和非匿名类写法) ----------------------------------------"); Console.WriteLine("-------------2.1 查询账号中包含 admin 的用户的 姓名、年龄和性别 三条信息 (匿名类的写法)-------------------------"); var sUserList1 = db.Sys_UserInfor.Where(u => u.userAccount.Contains("admin")).Select(u => new { u.userName, u.userAge, u.userSex }).ToList(); sUserList1.ForEach(u => { Console.WriteLine("用户名:{0},用户年龄:{1},用户性别:{2}", u.userName, u.userAge, u.userSex); }); //2.2 查询账号中包含 admin 的用户的 姓名、年龄和性别 三条信息 (匿名类的写法,指定匿名类名称) Console.WriteLine("---------2.2 查询账号中包含 admin 的用户的 姓名、年龄和性别 三条信息 (匿名类的写法 指定匿名类名称)--------"); var sUserList2 = db.Sys_UserInfor.Where(u => u.userAccount.Contains("admin")).Select(u => new { Name = u.userName, Age = u.userAge, Sex = u.userSex }).ToList(); sUserList2.ForEach(u => { Console.WriteLine("用户名:{0},用户年龄:{1},用户性别:{2}", u.Name, u.Age, u.Sex); }); //2.3 查询账号中包含 admin 的用户的 姓名、年龄和性别 三条信息 (非匿名类的写法) Console.WriteLine("-------------2.3 查询账号中包含 admin 的用户的 姓名、年龄和性别 三条信息 (非匿名类的写法)-------------------------"); List<newUserInfor> sUserList3 = db.Sys_UserInfor.Where(u => u.userAccount.Contains("admin")).Select(u => new newUserInfor { newName = u.userName, newAge = u.userAge, newSex = u.userSex }).ToList(); sUserList3.ForEach(u => { Console.WriteLine("用户名:{0},用户年龄:{1},用户性别:{2}", u.newName, u.newAge, u.newSex); }); } #endregion

OrderBy(OrderByDescending、ThenBy、ThenByDescending)用法
排序的用法在Lambda、Linq和SQL中相差还是很大的,写法的关键字截然不同。
在Lambda中:升序: OrderBy→ThenBy→ThenBy
降序: OrderByDescending→ThenByDescending
先升序后降序再升序: OrderBy→ThenByDescending→ThenBy
#region 03-OrderBy(OrderByDescending、ThenBy、ThenByDescending)用法 { //3. OrderBy(OrderByDescending、ThenBy、ThenByDescending)用法 (单条件升降序、多条件综合排序) //3.1 查询delflag 为1 的所有用户信息,按照时间升序排列 Console.WriteLine("------3. OrderBy(OrderByDescending、ThenBy、ThenByDescending)用法 (单条件升降序、多条件综合排序)-------------"); Console.WriteLine("--------------------- 3.1 查询delflag 为1 的所有用户信息,按照时间升序排列 ------------------------------"); List<Sys_UserInfor> sUserList1 = db.Sys_UserInfor.Where(u => u.delFlag == 1).OrderBy(u => u.addTime).ToList(); foreach (var item in sUserList1) { Console.WriteLine("用户名:{0},用户账号:{1},用户年龄:{2},用户性别:{3},创建时间:{4}", item.userName, item.userAccount, item.userAge, item.userSex, item.addTime); } //3.2 查询delflag 为1 的所有用户信息,先按照时间升序排列,再按照年龄降序 Console.WriteLine("---------------3.2 查询delflag 为1 的所有用户信息,先按照时间升序排列,再按照年龄降序----------------------"); List<Sys_UserInfor> sUserList2 = db.Sys_UserInfor.Where(u => u.delFlag == 1).OrderBy(u => u.addTime).ThenByDescending(u => u.userAge).ToList(); foreach (var item in sUserList2) { Console.WriteLine("用户名:{0},用户账号:{1},用户年龄:{2},用户性别:{3},创建时间:{4}", item.userName, item.userAccount, item.userAge, item.userSex, item.addTime); } } #endregion

join连接查询
这里展示的类似全连接的查询,在多表查询,特别是内连接和外链接方面明显不如 Linq和SQL。
#region 04-join连接查询(作用仅限与此么?) { //4. join连接查询(匿名类和非匿名类) Console.WriteLine("-------------------- 4. join连接查询(匿名类和非匿名类)------------------------"); var sUserList = db.Sys_UserInfor; var sLoginRecordsList = db.LoginRecords; var newList = sUserList.Join(sLoginRecordsList, u => u.id, p => p.userId, (u, p) => new { UserName = u.userName, LoginIp = p.loginIp, LoginCity = p.loginCity, LoginTime = p.loginTime }).ToList(); newList.ForEach(a => Console.WriteLine("姓名:{0},登录IP:{1},登录城市:{2},登录时间:{3}", a.UserName, a.LoginIp, a.LoginCity, a.LoginTime)); //非匿名类的情况与上述select中的用法相似 } #endregion

GroupBy分组(匿名类写法)
这里建议使用var类型接收,原类型太难记忆了,记住一点Lambda和Linq可以把分组依据和分组后对应的数据一次性全部拿出来,但是SQL中分组只能查询分组的依据和使用聚合函数处理其它字段,不能直接查询非分组依据以外的字段。
#region 05-GroupBy分组(匿名类写法) { //5. GroupBy分组(需要重点看一下) //5.1 根据用户的性别进行分类,然后将不同性别的用户信息输出来 Console.WriteLine("-------------------- 5. GroupBy分组------------------------"); Console.WriteLine("-------------------- 5.1 根据用户的性别进行分类,然后将不同性别的用户信息输出来------------------------"); var sUserListGroup = db.Sys_UserInfor.GroupBy(u => u.userSex).ToList(); foreach (var group in sUserListGroup) { Console.WriteLine("性别为:{0}", group.Key); //分组依据的字段内容 foreach (var item in group) { Console.WriteLine("用户名:{0},用户账号:{1},用户年龄:{2},用户性别:{3}", item.userName, item.userAccount, item.userAge, item.userSex); } } //5.2 根据用户性别进行分类,然后将不同性别的年龄大于等于21岁的用户信息输出来 Console.WriteLine("-------------5.2 根据用户性别进行分类,然后将不同性别的年龄大于等于21岁的用户信息输出来-------------------"); var sUserListGroup2 = db.Sys_UserInfor.Where(u => u.userAge >= 21).GroupBy(u => u.userSex).ToList(); foreach (var group in sUserListGroup2) { Console.WriteLine("性别为:{0}", group.Key); //分组依据的字段内容 foreach (var item in group) { Console.WriteLine("用户名:{0},用户账号:{1},用户年龄:{2},用户性别:{3}", item.userName, item.userAccount, item.userAge, item.userSex); } } } #endregion

Skip和Take用法
这里结合Skip和Take写分页,太方便了,分页公式:
data.Skip((pageIndex - 1) * pageSize).Take(pageSize).ToList(); 补充MySQL数据中特有的分页,也很方便,分页公式:SELECT * FROM 表名 LIMIT (pageIndex-1)*pageSize,pageSize .
#region 06-Skip和Take用法 { //6. Skip和Take 分页用法 //skip表示跳过多少条,Take表示取多少条 //6.1 根据时间降序排列,取第2和第3条数据(即先排序,然后跨过1条,取2条数据) Console.WriteLine("--------------------6. Skip和Take 分页用法------------------------"); Console.WriteLine("---------6.1 根据时间降序排列,取第2和第3条数据(即先排序,然后跨过1条,取2条数据)---------"); var sUserList = db.Sys_UserInfor.OrderByDescending(u => u.addTime).Skip(1).Take(2).ToList(); sUserList.ForEach(u => { Console.WriteLine("用户名:{0},用户年龄:{1},用户性别:{2},创建时间:{3}", u.userName, u.userAge, u.userSex, u.addTime); }); // 6.2 分页公式 // 每页两条数据,根据时间降序,取第三页的所有数据 Console.WriteLine("---------6.2 每页两条数据,根据时间降序,取第三页的所有数据---------"); var sUserList2 = GetDataByIndex(db.Sys_UserInfor.OrderByDescending(u => u.addTime).ToList(), 3, 2); sUserList2.ForEach(u => { Console.WriteLine("用户名:{0},用户年龄:{1},用户性别:{2},创建时间:{3}", u.userName, u.userAge, u.userSex, u.addTime); }); } #endregion #region 分页公式 static List<Sys_UserInfor> GetDataByIndex(List<Sys_UserInfor> data, int pageIndex, int pageSize) { return data.Skip((pageIndex - 1) * pageSize).Take(pageSize).ToList(); } #endregion

#region 06-GroupJoin外连接查询(相当于left Join) { Console.WriteLine("-------------------- 06-GroupJoin多表关联分组------------------------"); Console.WriteLine("--------------------根据性别分组,输出相同性别的用户和登录城市 ------------------------"); var list = db.Sys_UserInfor.GroupJoin(db.LoginRecord2, a => a.id, b => b.userId, (a,b) => new { a.userName, b }).ToList(); foreach (var item in list) { var userName = item.userName; foreach (var cItem in item.n.ToList()) { Console.WriteLine("用户名为{0}的用户的登录城市是:{1},登录时间是:{2}", userName, cItem.loginCity,cItem.loginTime); } } } #endregion

linq中where的用法与SQL中where的用法基本一致。
#region 01-where用法 { //1. where用法 //1.1 查询账号为admin的用户信息 Console.WriteLine("---------------------------- 1. where用法 ----------------------------------------"); Console.WriteLine("---------------------------- 1.1 查询账号为admin的用户信息 ----------------------------------------"); List<Sys_UserInfor> sUserList1 = (from u in db.Sys_UserInfor where u.userAccount == "admin" select u).ToList(); foreach (var item in sUserList1) { Console.WriteLine("用户名:{0},用户账号:{1},用户年龄:{2},用户性别:{3}", item.userName, item.userAccount, item.userAge, item.userSex); } //1.2 查询账号为中包含admin且性别为男的用户信息 Console.WriteLine("---------------------------- 1.2 查询账号为中包含admin且性别为男的用户信息 ----------------------------------------"); List<Sys_UserInfor> sUserList2 = (from u in db.Sys_UserInfor where u.userAccount.Contains("admin") && u.userSex == "男" select u).ToList(); foreach (var item in sUserList2) { Console.WriteLine("用户名:{0},用户账号:{1},用户年龄:{2},用户性别:{3}", item.userName, item.userAccount, item.userAge, item.userSex); } } #endregion

Select用法
与前一个章节lambda中介绍的一样,select可以全部查询或查询部分字段
查询部分的时候可以使用匿名类或者实体类,使用匿名的时候也可以指定列名。
#region 02-select用法 (匿名类和非匿名类写法) { //2. select用法 (匿名类和非匿名类写法) //2.1 查询账号中包含 admin 的用户的 姓名、年龄和性别 三条信息 (匿名类的写法,自动生成匿名类名称) Console.WriteLine("---------------------------- 2. select用法 (匿名类和非匿名类写法) ----------------------------------------"); Console.WriteLine("-------------2.1 查询账号中包含 admin 的用户的 姓名、年龄和性别 三条信息 (匿名类的写法)-------------------------"); var sUserList1 = (from u in db.Sys_UserInfor where u.userAccount.Contains("admin") select new { u.userName, u.userAge, u.userSex }).ToList(); sUserList1.ForEach(u => { Console.WriteLine("用户名:{0},用户年龄:{1},用户性别:{2}", u.userName, u.userAge, u.userSex); }); //2.2 查询账号中包含 admin 的用户的 姓名、年龄和性别 三条信息 (匿名类的写法,指定匿名类名称) Console.WriteLine("---------2.2 查询账号中包含 admin 的用户的 姓名、年龄和性别 三条信息 (匿名类的写法 指定匿名类名称)--------"); var sUserList2 = (from u in db.Sys_UserInfor where u.userAccount.Contains("admin") select new { Name = u.userName, Age = u.userAge, Sex = u.userSex }).ToList(); sUserList2.ForEach(u => { Console.WriteLine("用户名:{0},用户年龄:{1},用户性别:{2}", u.Name, u.Age, u.Sex); }); //2.3 查询账号中包含 admin 的用户的 姓名、年龄和性别 三条信息 (非匿名类的写法) Console.WriteLine("-------------2.3 查询账号中包含 admin 的用户的 姓名、年龄和性别 三条信息 (非匿名类的写法)-------------------------"); List<newUserInfor> sUserList3 = (from u in db.Sys_UserInfor where u.userAccount.Contains("admin") select new newUserInfor { newName = u.userName, newAge = u.userAge, newSex = u.userSex }).ToList(); sUserList3.ForEach(u => { Console.WriteLine("用户名:{0},用户年龄:{1},用户性别:{2}", u.newName, u.newAge, u.newSex); }); } #endregion

orderby用法
关键字是:orderby (默认是升序) 和orderby descending
需要按照多个条件进行升序或降序,格式为: orderby x1,x2 descending,x3 (表示先按照x1升序排,x1相同的话,再按照x2降序排,x2相同的话,在按照x3升序排列)
#region 03-orderby用法 { //区分:在Lambda中有 orderby(OrderByDescending、ThenBy、ThenByDescending),但在Linq中 只有orderby (默认是升序) 和orderby descending //需要按照多个条件进行升序或降序,格式为: orderby x1,x2 descending,x3 (表示先按照x1升序排,x1相同的话,再按照x2降序排,x2相同的话,在按照x3升序排列) //3. OrderBy用法 (单条件升降序、多条件综合排序) //3.1 查询delflag 为1 的所有用户信息,按照时间升序排列 Console.WriteLine("------3. orderby用法 (单条件升降序、多条件综合排序)-------------"); Console.WriteLine("--------------------- 3.1 查询delflag 为1 的所有用户信息,按照时间升序排列 ------------------------------"); List<Sys_UserInfor> sUserList1 = (from u in db.Sys_UserInfor where u.delFlag == 1 orderby u.addTime select u).ToList(); foreach (var item in sUserList1) { Console.WriteLine("用户名:{0},用户账号:{1},用户年龄:{2},用户性别:{3},创建时间:{4}", item.userName, item.userAccount, item.userAge, item.userSex, item.addTime); } //3.2 查询delflag 为1 的所有用户信息,先按照时间升序排列,再按照年龄降序 Console.WriteLine("---------------3.2 查询delflag 为1 的所有用户信息,先按照时间升序排列,再按照年龄降序----------------------"); List<Sys_UserInfor> sUserList2 = (from u in db.Sys_UserInfor where u.delFlag == 1 orderby u.addTime, u.userAge descending select u).ToList(); foreach (var item in sUserList2) { Console.WriteLine("用户名:{0},用户账号:{1},用户年龄:{2},用户性别:{3},创建时间:{4}", item.userName, item.userAccount, item.userAge, item.userSex, item.addTime); } } #endregion

多表关联查询
用到的用户表和用户登录记录表如下:


这里类比SQL语句里的查询,查询包括内连接和外连接,其中,
1.内连接分为:隐式内连接和显示内连接.特点:二者只是写法不同,查询出来的结果都是多表交叉共有的。
(1).隐式内连接: 多个from并联拼接
(2).显示内连接: join-in-on拼接,注意没有into哦!加上into就成外连接了。
PS:这里的内连接相当于sql中的等值连接inner join。
2.外连接分为:左外连接和右外连接.
(1).左外连接:查询出JOIN左边表的全部数据,JOIN右边的表不匹配的数据用NULL来填充。
(2).右外连接:查询出JOIN右边表的全部数据,JOIN左边的表不匹配的数据用NULL来填充。
PS:linq中没有sql中的left/right join, 只有join,左外连接和右外连接通过颠倒数据的顺序来实现。
注:外连接join后必须有into,然后可以加上XX.DefaultIfEmpty(),表示对于引用类型将返回null,而对于值类型则返回0。对于结构体类型,则会根据其成员类型将它们相应地初始化为null(引用类型)或0(值类型)
\3. 分析几个场景,一对一,一对多,而且还要统计个数的案例
(1).用户表-用户详情表(一对一):用内连接
(2).用户表-用户登录记录表(一对零,一对多):用左外连接,用户表为左,如果统计个数需要用Distinct()去重.
//4.查询账号中含有admin的所有用户的用户昵称、账号、和登录信息 //4.1 隐式内连接(匿名类且不指定名称) Console.WriteLine("---------------04-多表关联查询--------------------"); Console.WriteLine("---------------4.1 隐式内连接(匿名类且不指定名称)--------------------"); var uList1 = (from a in db.Sys_UserInfor from b in db.LoginRecords where a.id == b.userId select new { a.userName, a.userAccount, b.loginCity, b.loginIp, b.loginTime }).ToList(); foreach (var item in uList1) { Console.WriteLine("姓名:{0},账号:{1},登录城市:{2},登录IP:{3},登录时间:{4}", item.userName, item.userAccount, item.loginCity, item.loginIp, item.loginTime); } //4.2 显式内链接(匿名类 且部分列指定名称) Console.WriteLine("---------------4.2 显式内链接(匿名类 且部分列指定名称) --------------------"); var uList2 = (from a in db.Sys_UserInfor join b in db.LoginRecords on a.id equals b.userId select new { UserName = a.userName, UserAccount = a.userAccount, b.loginCity, b.loginIp, b.loginTime }).ToList(); foreach (var item in uList2) { Console.WriteLine("姓名:{0},账号:{1},登录城市:{2},登录IP:{3},登录时间:{4}", item.UserName, item.UserAccount, item.loginCity, item.loginIp, item.loginTime); } //4.3 查询所有用户的登录信息(左外连接的方式) //join时必须将join后的表into到一个新的变量XX中,然后要用XX.DefaultIfEmpty()表示外连接。 //DefaultIfEmpty使用了泛型中的default关键字。default关键字对于引用类型将返回null,而对于值类型则返回0。对于结构体类型,则会根据其成员类型将它们相应地初始化为null(引用类型)或0(值类型) Console.WriteLine("-----------------------4.3 查询所有用户的登录信息(左外连接的方式)----------------------------"); var uList3 = (from a in db.Sys_UserInfor join b in db.LoginRecords on a.id equals b.userId into fk from c in fk.DefaultIfEmpty() select new { UserName = a.userName, UserAccount = a.userAccount, c.loginCity, c.loginIp, c.loginTime }).ToList(); foreach (var item in uList3) { Console.WriteLine("姓名:{0},账号:{1},登录城市:{2},登录IP:{3},登录时间:{4}", item.UserName, item.UserAccount, item.loginCity, item.loginIp, item.loginTime); } // 4.4 查询所有用户的登录信息(右外连接的方式) Console.WriteLine("-----------------------4.4 查询所有用户的登录信息(右外连接的方式)----------------------------"); var uList4 = (from a in db.LoginRecords join b in db.Sys_UserInfor on a.userId equals b.id into fk from c in fk.DefaultIfEmpty() select new { UserName = c.userName, UserAccount = c.userAccount, a.loginCity, a.loginIp, a.loginTime }).ToList(); foreach (var item in uList4) { Console.WriteLine("姓名:{0},账号:{1},登录城市:{2},登录IP:{3},登录时间:{4}", item.UserName, item.UserAccount, item.loginCity, item.loginIp, item.loginTime); } //4.5 查询每个用户的登录次数(用且应该用左外连接 ) //注:这里需要加一个Distinct()去重,否则同一个账号会查出来多条数据重复了 Console.WriteLine("-----------------------4.5 查询每个用户的登录次数(用且应该用左外连接 )----------------------------"); var uList5 = (from a in db.Sys_UserInfor join b in db.LoginRecords on a.id equals b.userId into fk select new { UserName = a.userName, UserAccount = a.userAccount, loginCount = fk.Count() }).Distinct().ToList(); foreach (var item in uList5) { Console.WriteLine($"姓名:{item.UserName},账号:{item.UserAccount},登录次数:{item.loginCount}"); }
运行 结果:

group by into 分组
#region 05-group By分组(匿名类写法) { //5. GroupBy分组(需要重点看一下) //5.1 根据用户的性别进行分类,然后将不同性别的用户信息输出来 Console.WriteLine("-------------------- 5. GroupBy分组------------------------"); Console.WriteLine("-------------------- 5.1 根据用户的性别进行分类,然后将不同性别的用户信息输出来------------------------"); var sUserListGroup = (from u in db.Sys_UserInfor group u by u.userSex into fk select fk).ToList(); foreach (var group in sUserListGroup) { Console.WriteLine("性别为:{0}", group.Key); //分组依据的字段内容 foreach (var item in group) { Console.WriteLine("用户名:{0},用户账号:{1},用户年龄:{2},用户性别:{3}", item.userName, item.userAccount, item.userAge, item.userSex); } } //5.2 根据用户性别进行分类,然后将不同性别的年龄大于等于21岁的用户信息输出来 Console.WriteLine("-------------5.2 根据用户性别进行分类,然后将不同性别的年龄大于等于21岁的用户信息输出来-------------------"); var sUserListGroup2 = (from u in db.Sys_UserInfor where u.userAge >= 21 group u by u.userSex into fk select fk).ToList(); foreach (var group in sUserListGroup2) { Console.WriteLine("性别为:{0}", group.Key); //分组依据的字段内容 foreach (var item in group) { Console.WriteLine("用户名:{0},用户账号:{1},用户年龄:{2},用户性别:{3}", item.userName, item.userAccount, item.userAge, item.userSex); } } } #endregion

skip和take用法
#region 06-Skip和Take用法 { //6. Skip和Take 分页用法 //skip表示跳过多少条,Take表示取多少条 //6.1 根据时间降序排列,取第2和第3条数据(即先排序,然后跨过1条,取2条数据) Console.WriteLine("--------------------6. Skip和Take 分页用法------------------------"); Console.WriteLine("---------6.1 根据时间降序排列,取用户信息中的第2和第3条数据(即先排序,然后跨过1条,取2条数据)---------"); var sUserList = (from u in db.Sys_UserInfor orderby u.addTime descending select u).Skip(1).Take(2).ToList(); sUserList.ForEach(u => { Console.WriteLine("用户名:{0},用户年龄:{1},用户性别:{2},创建时间:{3}", u.userName, u.userAge, u.userSex, u.addTime); }); } #endregion

实体生命周期
在实体的生命期中,每个实体都有一个基于上下文(DbContext)的操作的实体状态。实体状态是一个System.Data.Entity.EntityState类型的枚举,它包含以下的值:
1、detached:实体不在上下文的追踪范围内。如刚new的实例处于detached,可以通过Attach()添加到上下文,此时的状态是unchanged。
2、unchanged:未改变,如刚从数据库读出来的实例
3、added:添加状态 一般执行 db.Set<T>.Add(t)/ AddRange(ts)时标记为added。因为新对象在数据库中没有相应的记录,所有不能转成deleted和modified状态。
4、deleted:删除状态 一般执行 db.Set<T>.Remove(t)/ RemoveRange(ts)时标记为deleted。数据库中必须先有了相应的记录,所有deleted不能转为added状态。
5、modified:修改状态 改变了实体的属性处于这个状态,可以转为deleted,不能转为added状态。
当EF从数据库中提取一条记录生成一个实体对象之后,应用程序可以针对它的操作太多了,EF是怎么知道哪个对象处于哪个状态的?
下图说明了实体状态如何影响数据库操作。

1. 新的实体具有Added的状态,DbContext后续会在数据库中执行插入操作。
2. 通过LINQ检索出来的实体具有Unchanged的状态,但如果调用了AsNoTracking()方法,其状态为Detached。
3. 修改了检索出来的实体的属性值,实体会修改状态为Modified,DbContext后续会在数据库中执行更新操作。
4. 需要删除的实体会具有Deleted的状态,DbContext后续会在数据库中执行删除操作。
5. 对于DbContext中已有的实体,可以通过dbContext.Entry(entity).State = EntityState.Detached的方式把状态设置为Detached。
下面拿一个User实体的插入、修改、删除、查询等操作来理解实体的状态
User userNew = new User() { Account = "Admin", State = 0, CompanyId = 4, CompanyName = "万达集团", CreateTime = DateTime.Now, CreatorId = 1, Email = "57265177@qq.com", LastLoginTime = null, LastModifierId = 0, LastModifyTime = DateTime.Now, Mobile = "18664876671", Name = "yoyo", Password = "12356789", UserType = 1 }; using (JDDbContext context = new JDDbContext()) { Console.WriteLine(context.Entry<User>(userNew).State);//实体跟context没关系 Detached userNew.Name = "小鱼"; context.SaveChanges();//Detached啥事儿不发生 context.Users.Add(userNew); Console.WriteLine(context.Entry<User>(userNew).State);//Added context.SaveChanges();//插入数据(自增主键在插入成功后,会自动赋值过去) Console.WriteLine(context.Entry<User>(userNew).State);//Unchanged(跟踪,但是没变化) userNew.Name = "加菲猫";//修改----内存clone Console.WriteLine(context.Entry<User>(userNew).State);//Modified context.SaveChanges();//更新数据库,因为状态是Modified Console.WriteLine(context.Entry<User>(userNew).State);//Unchanged(跟踪,但是没变化) context.Users.Remove(userNew); Console.WriteLine(context.Entry<User>(userNew).State);//Deleted context.SaveChanges();//删除数据,因为状态是Deleted Console.WriteLine(context.Entry<User>(userNew).State);//Detached已经从内存移除了 }
当EF从数据库中提取一条记录生成一个实体对象之后,应用程序可以针对它的操作太多了,EF是怎么知道哪个对象处于哪个状态的?
EF的解决方案是:为当前所有需要跟踪的实体对象,创建一个相应的DbEntityEntry对象,此对象包容着实体对象每个属性的三个值:Current Value、Original Value和Database Value,只要比较这三个值,很容易地就知道哪个属性值被修改了(设置:context.Configuration.AutoDetectChangesEnabled = false则不会去追踪,默认是打开的),从而生成相应的Sql命令。对象的状态会随着操作而改变,我们也可以自己指定状态:
//为user生成一个DbEntityEntry对象 DbEntityEntry userEntry = context.Entry(user); userEntry.State = EntityState.Added;//添加标记 userEntry.State = EntityState.Deleted;//删除标记 userEntry.State = EntityState.Modified;//修改标记 userEntry.State = EntityState.Unchanged;//无变化标记 userEntry.State = EntityState.Detached;//不追踪标记
SaveChanges是以context为标准的,如果监听到任何数据的变化,然后会一次性的保存到数据库去,而且会开启事务! 关注下EntityState相互转换 可以直接Attach增加监听 EF本身是依赖监听变化,然后更新的; 平时业务都一次查询,然后用户修改,然后提交, 把实体传到EF,然后context.Entry<User>(user).State = EntityState.Modified; Find可以使用缓存,优先从内存查找(限于context) 但是linq时不能用缓存,每次都是要查询的 AsNoTracking() 如果数据不会更新,加一个可以提升性能 按需更新--只更新修改过的字段 context.Entry<User>(user5).Property("Name").IsModified = true;//指定某字段被改过 context.Entry<User>(user).State = EntityState.Modified;//全字段更新
状态追踪方法 以及状态追踪的删除、附加
context.Entry<User>(user).State;// 追踪单个实体的状态
context.ChangeTracker.Entries();//追踪EF上下文中所有实体的状态
context.Users.Local;//获取单个实体状态发生增加、修改的实体集合(不含删除)
context.Users.Where(u => u.Id > 10).AsNoTracking();//删除状态追踪
context.Users.Attach(user);//附加状态追踪
一. 背景
说起EF的增删改操作,相信很多人都会说,有两种方式:① 通过方法操作 和 ② 通过状态控制。
相信你在使用EF进行删除或修改操作的时候,可能会遇到以下错误:“ The object cannot be deleted because it was not found in the ObjectStateManager”,通过百度查询,说是没有进行上下文的附加,需要attach一下,那么都哪些情况需要附加,哪些是不需要附加的呢?
在本章节,将结合EF的两种方式,从EF本地缓存的角度来详细介绍EF的增删改情况。
二. EF核心结论
经过无数次摸爬滚打,详细的代码测试,整理出下面关于EF增删改操作的结论。
-
总纲
SaveChangs的时候一次性保存本地属性状态的全部变化.(换言之:只有本地缓存属性的状态发生变化了,SaveChanges才会实际生效)
补充:这里的属性状态的变化是存在于服务器端,一定不要理解为存在于本地,这也是为什么EF上下文不能用单例创建了。
EF的本地缓存属性的三种形式:
①.通过Attach附加.
②.通过EF的即时查询,查询出来的数据,自动就本地缓存了.
③.通过状态控制. eg:Added、Modified、Deleted. (db.Entry(sl).State = EntityState.Added;)
-
EF的增删改操作的操作有两种形式
(一). 通过方法来操控
a. 增加1个实体. Add() 不需要Attach()附加.(当然附加了也不受影响)
b. 增加1个集合. AddRange() 不需要Attach()附加.(当然附加了也不受影响)
c. 删除. Remove(). 分两种情况:
特别注意:如果数据为空,会报错.所以在实际开发过程中,要采用相应的业务逻辑进行处理.
①:自己创建了一个实体(非查询出来的),必须先Attach,然后Remove.
②:访问数据库,即时查询出来的数据(已经放到EF本地缓存里了),可以省略Attach,直接Remove(当然附加了也不受影响)
d. 修改(如果数据主键不存在,执行增加操作). AddOrUpdate(),可以省略Attach,直接AddOrUpdate.
需要引用程序集:using System.Data.Entity.Migrations;
①: 如果是执行增加操作,不需要进行Attach附加,但附加了Attach不受影响
②:如果是执行修改操作,不能进行Attach的附加,附加了Attach将导致修改失效,saveChange为0(无论是自己创建的或即时查询出来的,都不能进行Attach的附加)
e. 修改. 不需要调用任何方法.
该种方式如果实体为空,SaveChanges时将报错.
①:自己创建对象→先Attach(根据主键来区分对象)→然后修改属性值→最后saveChange
②: EF即时查询对象(自动本地缓存)→然后修改属性值→最后saveChange
(二). 通过修改本地属性的状态来操控.
(该种方式本身已经改变了本地缓存属性了,所以根本不需要Attach附加)
a. 增加. db.Entry(sl).State = EntityState.Added;
b. 删除. db.Entry(sl).State = EntityState.Deleted;
特别注意:如果数据为空,会报错.所以在实际开发过程中,要采用相应的业务逻辑进行处理.
①.适用于自己创建对象(根据主键来确定对象),然后删除的情况.
②.适用于即时查询出来的对象,然后进行删除的情况.
c. 修改. db.Entry(sl).State = EntityState.Modified;
特别注意:如果数据为空,会报错.所以在实际开发过程中,要采用相应的业务逻辑进行处理.
①.适用于自己创建对象(根据主键来确定对象),然后修改的情况.
②.适用于即时查询出来的对象,然后修改的情况.
-
private static void ADD() { using (DbContext db = new CodeFirstModel()) { Console.WriteLine("---------------------------1. Add()方法-------------------------------------"); //监控数据库SQL情况 // db.Database.Log += c => Console.WriteLine(c); TestInfor tInfor = new TestInfor() { id = Guid.NewGuid().ToString("N"), txt1 = "t1", txt2 = "t2" }; // db.Set<TestInfor>().Attach(tInfor); //特别注意Add方法前不需要进行Attach状态的附加,当然附加了也不会出错. db.Set<TestInfor>().Add(tInfor); int n = db.SaveChanges(); Console.WriteLine("数据作用条数:" + n); } using (DbContext db = new CodeFirstModel()) { Console.WriteLine("---------------------------2. AddRange()方法-------------------------------------"); //监控数据库SQL情况 //db.Database.Log += c => Console.WriteLine(c); List<TestInfor> tList = new List<TestInfor>() { new TestInfor() { id = Guid.NewGuid().ToString("N"), txt1 = "t11", txt2 = "t22" }, new TestInfor() { id = Guid.NewGuid().ToString("N"), txt1 = "t11", txt2 = "t22" }, new TestInfor() { id = Guid.NewGuid().ToString("N"), txt1 = "t11", txt2 = "t22" } }; //特别注意AddRange方法前不需要进行Attach状态的附加,当然附加也不错. foreach (var item in tList) { db.Set<TestInfor>().Attach(item); } db.Set<TestInfor>().AddRange(tList); int n = db.SaveChanges(); Console.WriteLine("数据作用条数:" + n); } }
2. 删除方法(先Attach-后Remove)
private static void Delete1() { using (DbContext db = new CodeFirstModel()) { Console.WriteLine("---------------------------1. Remove()方法 (调用Attach状态附加)-------------------------------------"); //监控数据库SQL情况 //db.Database.Log += c => Console.WriteLine(c); TestInfor tInfor = new TestInfor() { id = "11", //实际测试的时候要有这条id的数据才能去测试哦 }; /* * 特别注意1:Remove方法删除必须调用Attach进行状态的附加,如果不附加将报下面的错误。 * The object cannot be deleted because it was not found in the ObjectStateManager. * 特别注意2:直接使用状态的方式进行删除,db.Entry(tInfor).State = EntityState.Deleted; 是不需要进行attach附加的 * 该种方式在后面进行测试讲解 * 特别注意3:无论是Remove凡是还是直接状态的方式,如果传入的删除的数据为空,会报错抛异常 */ db.Set<TestInfor>().Attach(tInfor); //如果注释掉该句话,则报错 db.Set<TestInfor>().Remove(tInfor); int n = db.SaveChanges(); Console.WriteLine("数据作用条数:" + n); } }
3. 删除方法(先查询→后Remove删除)
private static void Delete2() { using (DbContext db = new CodeFirstModel()) { Console.WriteLine("---------------------------3. Remove()方法 (调用Attach状态附加)-------------------------------------"); int n; //监控数据库SQL情况 //db.Database.Log += c => Console.WriteLine(c); TestInfor tInfor = db.Set<TestInfor>().Where(u => u.id == "3").FirstOrDefault(); /* * 特别注意1:对于先查询(即时查询,查出来放到了EF的本地缓存里),后删除,这种情况可以省略Attach状态的附加。 * 因为查出来的数据已经放在EF的本地缓存里了,相当于已经附加了,无须再次附加(当然附加也不报错) */ if (tInfor == null) { n = 0; } else { //db.Set<TestInfor>().Attach(tInfor); //对于先查询(即时查询,查出来放到了EF的本地缓存里),后删除,这种情况省略该句话,仍然有效 db.Set<TestInfor>().Remove(tInfor); n = db.SaveChanges(); } Console.WriteLine("数据作用条数:" + n); } }
4. 修改(AddOrUpdate)
private static void Update1() { using (DbContext db = new CodeFirstModel()) { Console.WriteLine("---------------------------1. AddOrUpdate()方法-------------------------------------"); Console.WriteLine("-------------------------测试增加和自己创建数据的修改情况-----------------------------"); //监控数据库SQL情况 // db.Database.Log += c => Console.WriteLine(c); TestInfor tInfor = new TestInfor() { id = "123", txt1 = "马茹", txt2 = "马茹2" }; /* 特别注意AddOrUpdate方法前不需要进行Attach状态的附加 * 如果是执行增加操作,不需要附加Attach,附加了Attach不受影响 * 如果是执行修改操作,不能附加Attach,附加了Attach将导致修改失效,saveChange为0 */ //db.Set<TestInfor>().Attach(tInfor); db.Set<TestInfor>().AddOrUpdate(tInfor); int n = db.SaveChanges(); Console.WriteLine("数据作用条数:" + n); } using (DbContext db = new CodeFirstModel()) { Console.WriteLine("-------------------------测试即时查询出来的数据的修改情况-----------------------------"); //监控数据库SQL情况 // db.Database.Log += c => Console.WriteLine(c); TestInfor tInfor =db.Set<TestInfor>().Where(u=>u.id=="123").FirstOrDefault(); tInfor.txt1="ypf11"; /* 即时查询出来的数据,调用AddorUpdate方法执行修改操作 * 如果是执行修改操作,不需要进行Attach的附加,附加了Attach将导致修改失效,saveChange为0 */ db.Set<TestInfor>().Attach(tInfor); db.Set<TestInfor>().AddOrUpdate(tInfor); int n = db.SaveChanges(); Console.WriteLine("数据作用条数:" + n); } }
5. 修改(自己创建对象,然后attach附加→修改属性值→SaveChanges)
private static void Update2() { using (DbContext db = new CodeFirstModel()) { Console.WriteLine("---------------------------1. attach附加→修改属性值→SaveChanges-------------------------------------"); //监控数据库SQL情况 // db.Database.Log += c => Console.WriteLine(c); TestInfor tInfor = new TestInfor() { id = "123" }; /* 特别注意1:该方式为自己创建对象(对象中必须要有主键值),然后通过attach附加,然后修改属性值,最后保存SaveChange。可以实现修改操作. 特别注意2:该种方式如果实体为空,SaveChanges时将报错. */ db.Set<TestInfor>().Attach(tInfor); tInfor.txt1 = "ypf1"; int n = db.SaveChanges(); Console.WriteLine("数据作用条数:" + n); } }
6. 修改(即时查询→修改属性值→SaveChanges)
private static void Update3() { using (DbContext db = new CodeFirstModel()) { Console.WriteLine("---------------------------1. 即时查询→修改属性值→SaveChangess-------------------------------------"); //监控数据库SQL情况 // db.Database.Log += c => Console.WriteLine(c); TestInfor tInfor = db.Set<TestInfor>().Where(u => u.id == "123").FirstOrDefault(); /* 特别注意1:EF即时查询出来一个对象(自动保存到本地缓存了),然后修改属性值,最后保存SaveChange。可以实现修改操作. 特别注意2:该种方式如果实体为空,SaveChanges时将报错. */ tInfor.txt1 = "ypf333"; int n = db.SaveChanges(); Console.WriteLine("数据作用条数:" + n); } }
7. 增加方法(EntityState.Added)
private static void ADD2() { using (DbContext db = new CodeFirstModel()) { Console.WriteLine("---------------------------1. EntityState.Added-------------------------------------"); //监控数据库SQL情况 // db.Database.Log += c => Console.WriteLine(c); TestInfor tInfor = new TestInfor() { id = Guid.NewGuid().ToString("N"), txt1 = "t1", txt2 = "t2" }; db.Entry(tInfor).State = EntityState.Added; int n = db.SaveChanges(); Console.WriteLine("数据作用条数:" + n); } }
8. 删除方法(EntityState.Deleted-自己创建的对象)
private static void Delete3() { using (DbContext db = new CodeFirstModel()) { Console.WriteLine("---------------------------EntityState.Deleted-自己创建的对象-------------------------------------"); //监控数据库SQL情况 // db.Database.Log += c => Console.WriteLine(c); TestInfor tInfor = new TestInfor() { id = "122", }; db.Entry(tInfor).State = EntityState.Deleted; int n = db.SaveChanges(); Console.WriteLine("数据作用条数:" + n); } }
9. 删除方法(EntityState.Deleted-即时查询的对象)
private static void Delete4() { using (DbContext db = new CodeFirstModel()) { Console.WriteLine("---------------------------EntityState.Deleted-即时查询的对象-------------------------------------"); //监控数据库SQL情况 // db.Database.Log += c => Console.WriteLine(c); TestInfor tInfor = db.Set<TestInfor>().Where(u => u.id == "123").FirstOrDefault(); db.Entry(tInfor).State = EntityState.Deleted; int n = db.SaveChanges(); Console.WriteLine("数据作用条数:" + n); } }
10. 修改(自己创建对象,然后Modified→SaveChanges)
private static void Update4() { using (DbContext db = new CodeFirstModel()) { Console.WriteLine("---------------------------1. 自己创建对象,然后Modified→SaveChanges-------------------------------------"); //监控数据库SQL情况 // db.Database.Log += c => Console.WriteLine(c); TestInfor tInfor = new TestInfor() { id = "1", txt1 = "ypf1", txt2="ypf1" }; db.Entry(tInfor).State = EntityState.Modified; int n = db.SaveChanges(); Console.WriteLine("数据作用条数:" + n); } }
11. 修改(即时查询→修改属性值→然后Modified→SaveChanges)
private static void Update5() { using (DbContext db = new CodeFirstModel()) { Console.WriteLine("---------------------------1. 即时查询→修改属性值→SaveChanges-------------------------------------"); //监控数据库SQL情况 // db.Database.Log += c => Console.WriteLine(c); TestInfor tInfor = db.Set<TestInfor>().Where(u => u.id == "2").FirstOrDefault(); tInfor.txt1 = "ypf2"; tInfor.txt2 = "ypf2"; db.Entry(tInfor).State = EntityState.Modified; int n = db.SaveChanges(); Console.WriteLine("数据作用条数:" + n); } }
调用sql语句
EF调用SQL语句,主要是依赖于DbContext→DataBase类下SqlQuery和ExecuteSqlCommand两个方法,来处理查询的SQL语句、增删改或其它的SQL语句。


封装思想
结合泛型方法和参数化查询,将这两个方法进行简单封装一下,方便后面代码的调用。
#region 01-封装增删改或其他的方法 /// <summary> /// 封装增删改或其他的方法 /// </summary> /// <param name="db">数据库连接上下文</param> /// <param name="sql">数据库sql语句</param> /// <param name="paras">参数化参数</param> /// <returns></returns> public static int ExecuteSqlCommand(DbContext db, string sql, params SqlParameter[] paras) { return db.Database.ExecuteSqlCommand(sql, paras); } #endregion #region 02-执行查询操作(结果为集合) public static List<T> SqlQueryList<T>(DbContext db, string sql, params SqlParameter[] paras) { return db.Database.SqlQuery<T>(sql, paras).ToList(); } #endregion #region 03-执行查询操作(结果为单一实体) public static T SqlQuery<T>(DbContext db, string sql, params SqlParameter[] paras) { return db.Database.SqlQuery<T>(sql, paras).FirstOrDefault(); } #endregion
补充参数化查询:
目的:防止SQL注入。 那么什么是SQL注入呢?
SQL 注入漏洞存在的原因,就是拼接 SQL 参数。也就是将用于输入的查询参数,直接拼接在 SQL 语句中,导致了SQL 注入漏洞。
举例:String sql = "select * from user where id=" + id; 该局sql语句的目的是通过id来查询用户信息,id的值传入进入。
SQL注入的写法:id值传为: 2 or 1=1 ,由于 1=1 始终为true,加上or的配合,可以将所有的user信息查出来。
以上还是比较温柔的:下面来个狠的,比如: 2; truncate table user 这种破坏就有点可怕了。
参数化查询的写法:
String sql = "select * from user where id=@id" ;
SqlParameter[] paras ={
new SqlParameter("@id","2"),
};
这种写法,就有效的阻止SQL注入的风险。
代码实践
下面结合代码,展示EF调用SQL语句进行查询、增加、修改、删除、删除表所有数据的相关操作。
using (DbContext db = new CodeFirstModel()) { //1. 查询TestInfor表中的所有数据 Console.WriteLine("-----------------------------1. 查询TestInfor表中的所有数据----------------------------------"); string sql1 = @"select * from TestInfor"; List<TestInfor> tList = EFSqlTest.SqlQueryList<TestInfor>(db, sql1); tList.ForEach(t => { Console.WriteLine("id值为{0},txt1值为{1},txt2值为{2}", t.id, t.txt1, t.txt2); }); //2. 查询TestInfor表中ID值为2的数据txt1和txt2 Console.WriteLine("-----------------------------2. 查询TestInfor表中ID值为2的数据----------------------------------"); string sql2 = @"select * from TestInfor where id=@id "; SqlParameter[] paras ={ new SqlParameter("@id","2"), }; TestInfor T2 = EFSqlTest.SqlQuery<TestInfor>(db, sql2, paras); if (T2!=null) { Console.WriteLine("id值为{0},txt1值为{1},txt2值为{2}", T2.id, T2.txt1, T2.txt2); } else { Console.WriteLine("没有查出符合条件的数据"); } //3. 增加一条数据 Console.WriteLine("-----------------------------3. 增加一条数据----------------------------------"); string sql3 = @"insert into TestInfor values(@id,@txt1,@txt2)"; SqlParameter[] paras3 ={ new SqlParameter("@id",Guid.NewGuid().ToString("N")), new SqlParameter("@txt1","txt1+"+Guid.NewGuid().ToString("N").Substring(1,2)), new SqlParameter("@txt2","txt2+"+Guid.NewGuid().ToString("N").Substring(1,2)) }; int result3 = EFSqlTest.ExecuteSqlCommand(db, sql3, paras3); if (result3 > 0) { Console.WriteLine("增加成功"); } //4. 删除一条数据 Console.WriteLine("-----------------------------4. 删除一条数据----------------------------------"); string sql4 = @"delete from TestInfor where id=@id"; SqlParameter[] paras4 ={ new SqlParameter("@id","1"), }; int result4 = EFSqlTest.ExecuteSqlCommand(db, sql4, paras4); if (result4 > 0) { Console.WriteLine("删除成功"); } else { Console.WriteLine("没有查到相应的数据进行删除"); } //5. 修改一条数据 Console.WriteLine("-----------------------------5. 修改一条数据----------------------------------"); string sql5 = @"update TestInfor set txt1=@txt1 where id=@id"; SqlParameter[] paras5 ={ new SqlParameter("@id","2"), new SqlParameter("@txt1","limaru") }; int result5 = EFSqlTest.ExecuteSqlCommand(db, sql5, paras5); if (result5 > 0) { Console.WriteLine("修改成功"); } else { Console.WriteLine("没有查到相应的数据进行修改"); } //6. 删除表中的所有数据 Console.WriteLine("-----------------------------6. 删除表中的所有数据----------------------------------"); string sql6 = @"truncate table LoginRecords"; //执行成功的话 result6仍然为0 int result6 = EFSqlTest.ExecuteSqlCommand(db, sql6); }
调用存储过程
EF调用存储过程通用的写法,分两类:
① 对于查询相关的存储过程,调用 SqlQuery 方法
② 对于增删改或其他的存储过程,调用 ExecuteSqlCommand 方法
-
不含任何参数(查询类的存储过程)
直接调用SqlQuery方法进行操作。
if (exists (select * from sys.objects where name = 'GetAll')) drop proc GetAll go create proc GetAll as select * from TestOne; -- 调用 exec GetAll;
private static void NewMethod(DbContext db) { Console.WriteLine("---------------------------------1. 测试查询所有数据(不含输入参数)----------------------------------------"); List<TestOne> tList = db.Database.SqlQuery<TestOne>("GetAll").ToList(); foreach (var item in tList) { Console.WriteLine("id为:{0},t1为:{1},t2为:{2}", item.id, item.t1, item.t2); } }
-
含多个输入参数(查询类的存储过程)
调用SqlQuery方法进行操作,传入参数的使用要使用SqlParameter参数化的方式进行传入,特别注意:调用时,存储过程的名字后面的参数 必须按照SqlParameter中的先后顺序来写。
if (exists (select * from sys.objects where name = 'GetALLBy')) drop proc GetALLBy go create proc GetALLBy( @id varchar(32), @t1 varchar(32) ) as select * from TestOne where id=@id and t1=@t1; exec GetALLBy @id='1',@t1='2';
private static void NewMethod2(DbContext db) { Console.WriteLine("---------------------------------2. 测试根据指定条件查询数据(含输入参数)----------------------------------------"); SqlParameter[] para ={ new SqlParameter("@id","1"), new SqlParameter("@t1","txt1") }; //调用的时,存储过程的名字后面的参数 必须按照SqlParameter中的先后顺序来写 List<TestOne> tList = db.Database.SqlQuery<TestOne>("GetALLBy @id,@t1", para).ToList(); foreach (var item in tList) { Console.WriteLine("id为:{0},t1为:{1},t2为:{2}", item.id, item.t1, item.t2); } }
-
增删改的存储过程(含1个输入参数)
if (exists (select * from sys.objects where name = 'DoSome')) drop proc DoSome go create proc DoSome( @id varchar(32) ) as begin transaction begin try truncate table [dbo].[TestOne]; insert into TestOne values(@id,'1','2'); delete from TestOne where id='2' commit transaction end try begin catch rollback transaction end catch exec DoSome 1
private static void NewMethod3(DbContext db) { Console.WriteLine("---------------------------------3. 测试根据指定条件查询数据(含输入参数)----------------------------------------"); SqlParameter[] para ={ new SqlParameter("@id",Guid.NewGuid().ToString("N")), }; int n = db.Database.ExecuteSqlCommand("DoSome @id", para); if (n > 0) { Console.WriteLine("操作成功"); } else { Console.WriteLine("没有更多数据进行处理"); } }
-
带输出参数的存储过程的调用
GO if (exists (select * from sys.objects where name = 'GetT1Value')) drop proc GetT1Value go create proc GetT1Value( @t1 varchar(32), @count int output ) as select @count=count(*) from TestOne where t1=@t1; select * from TestOne where t1=@t1; go declare @myCount int; exec GetT1Value '111',@myCount output; select @myCount as myCount;
private static void NewMethod4(DbContext db) { Console.WriteLine("---------------------------------4. 测试查询含有输入和输出操作----------------------------------------"); //把输出参数单独拿出来声明 SqlParameter para1 = new SqlParameter("@t2", SqlDbType.Int); para1.Direction = ParameterDirection.Output; //把输出参数放到数组里 SqlParameter[] para2 ={ new SqlParameter("@t1","111"), para1 }; var tList1 = db.Database.SqlQuery<TestOne>("exec GetT1Value @t1,@t2 out", para2).ToList(); //通过输出参数在数组中的位置来获取返回值。 var count = para2[1].Value; Console.WriteLine($"数量count为:{count}"); foreach (var item in tList1) { Console.WriteLine("id为:{0},t1为:{1},t2为:{2}", item.id, item.t1, item.t2); } }
DBFirst模式快捷调用存储过程
前面介绍的调用存储过程的方法是通用模式,无论EF的哪种模式都可以使用,这里将介绍DBFirst模式的快捷调用,原理即创建的时候将存储过程映射进来了,所以可以直接调用。如下图:

1. 不含任何参数(查询类存储过程)
-- 1.无参存储过程(查询) if (exists (select * from sys.objects where name = 'GetAll')) drop proc GetAll go create proc GetAll as select * from DBTestOne; -- 调用 exec GetAll;
private static void DBNewMethod(EFDB3Entities db) { Console.WriteLine("---------------------------------1. 测试查询所有数据(不含输入参数)----------------------------------------"); var tList = db.GetAll().ToList(); foreach (var item in tList) { Console.WriteLine("id为:{0},t1为:{1},t2为:{2}", item.id, item.t1, item.t2); } }
2. 含多个输入参数(查询类存储过程)
--2. 有参数的存储过程(查询) if (exists (select * from sys.objects where name = 'GetALLBy')) drop proc GetALLBy go create proc GetALLBy( @id varchar(32), @t1 varchar(32) ) as select * from DBTestOne where id=@id and t1=@t1; exec GetALLBy @id='1',@t1='2';
private static void DBNewMethod2(EFDB3Entities db) { Console.WriteLine("---------------------------------2. 测试根据指定条件查询数据(含输入参数)----------------------------------------"); var tList = db.GetALLBy("11", "1").ToList(); foreach (var item in tList) { Console.WriteLine("id为:{0},t1为:{1},t2为:{2}", item.id, item.t1, item.t2); } }
3. 增删改存储过程(含1个输入参数)
--3. 增删改的一组过程 if (exists (select * from sys.objects where name = 'DoSome')) drop proc DoSome go create proc DoSome( @id varchar(32) ) as begin transaction begin try truncate table [dbo].[DBTestOne]; insert into DBTestOne values(@id,'1','2'); delete from DBTestOne where id='2' commit transaction end try begin catch rollback transaction end catch go exec DoSome 1
private static void DBNewMethod3(EFDB3Entities db) { Console.WriteLine("---------------------------------3. 测试根据指定条件查询数据(含输入参数)----------------------------------------"); int n = db.DoSome("33"); if (n > 0) { Console.WriteLine("操作成功"); } else { Console.WriteLine("没有更多数据进行处理"); } }
4. 带有输出参数
if (exists (select * from sys.objects where name = 'GetT1Value')) drop proc GetT1Value go create proc GetT1Value( @t1 varchar(32), @count int output ) as select @count=count(*) from DBTestOne where t1=@t1; select * from DBTestOne where t1=@t1; go declare @myCount int; exec GetT1Value '111',@myCount output; select @myCount as myCount;
private static void DBNewMethod4(EFDB3Entities db) { Console.WriteLine("---------------------------------4. 测试查询含有输入和输出操作----------------------------------------"); //声明一下输出参数 ObjectParameter para1 = new ObjectParameter("XXX", SqlDbType.Int); var tList1 = db.GetT1Value("1", para1).ToList(); //通过.Value获取输出参数的值。 var count = para1.Value; Console.WriteLine($"数量count为:{count}"); foreach (var item in tList1) { Console.WriteLine("id为:{0},t1为:{1},t2为:{2}", item.id, item.t1, item.t2); } }
PS:需要先声明ObjectParameter对象来存放输出参数,执行完后,通过.Value即可以获取输出参数,输出参数都是一个值,还没遇到集合的(PS:欢迎补充)。
EF高级属性
一. 本地缓存
从这个章节开始,介绍一下EF的一些高级特性,这里介绍的首先介绍的EF的本地缓存,在前面的“EF增删改”章节中介绍过该特性(SaveChanges一次性会作用于本地缓存中所有的状态的变化),在这里介绍一下本地缓存的另外一个用途。
① Find方法通过主键查询数据,主键相同的查询,只有第一次访问数据库,其它均从缓存中读取。
② 延迟加载的数据,在第一次使用的使用时访问数据库,后面无论再使用多少次,均是从内存中读取了。
Console.WriteLine("--------------------------- 1.本地缓存属性 ------------------------------------"); db.Database.Log += c => Console.WriteLine(c); //以下4个根据主键id查询,查询了一次,都存到本地缓存里了,所以user2不查询数据库,但user3的id不同,所以查询数据库 var user1 = db.Set<TestInfor>().Find("2"); var user2 = db.Set<TestInfor>().Find("2"); var user3 = db.Set<TestInfor>().Find("3");
二. 立即加载
这里的立即加载指单表,不含主外键的情况。
所谓的立即加载就是代码执行的时候直接去数据库查询,与是否立即使用无关,查出来后放到本地缓存里,以后再次使用的时候,从本地缓存中读取。
常见的立即加载的的标记:toList() 、FirstOrDefault() 。
Console.WriteLine("--------------------------- 2.即时加载 ------------------------------------"); ////以下3个属于立即查询,所以每次都要查询数据库,不缓存 var user5 = db.Set<TestInfor>().Where(u => u.id == "2").FirstOrDefault(); var user6 = db.Set<TestInfor>().Where(u => u.id == "2").FirstOrDefault(); var user7 = db.Set<TestInfor>().Where(u => u.id == "2").FirstOrDefault();
这里的延迟加载指单表,不含主外键的情况。
1. 定义:只有我们需要数据的时候,才去数据库查询
比如:我们需要根据条件判断,通过Where来拼接条件(IQueryable),在拼接的过程中,并没有访问数据库,只有在最终使用的时候,才访问数据库。
特别注意:调用的时候要foreach循环来调用,只有第一次使用的时候去访问数据库,其它的都是从本地缓存中读取。
2. 禁用延迟加载的方法:
a:如果结果是集合,在拼接的结尾加 toList() ,其它类型调用其它方法
b:如果结果是单个实体,在拼接的结尾加 FirstOrDefault()
3. 好处:保证了数据的实时性,什么时候用,什么时候查询
4. 弊端:每用一次,就需要查询一次数据,服务器压力大
5. 延迟加载的实际开发场景:
分页要要经历where多个条件查询、skip、take、toList,如果每调用一个方法都连接一个数据库,那么在拼接过程中就访问了3次数据库,而且可能数据量非常多,所以这个时候使用延迟加载,只有在所有sql语句拼接完的最后一步才连接数据库。
总结:只要查询结果实现了IQueryable接口类的,那么查询结果都是延迟加载的。
Console.WriteLine("--------------------------- 3.延迟加载 ------------------------------------"); IQueryable<TestInfor> user4 = db.Set<TestInfor>().Where(u => u.id != "123"); IQueryable<TestInfor> user6 = db.Set<TestInfor>().Where(u => u.id != "123"); foreach (var item in user4) { Console.WriteLine("我要从数据库中读取数据了:" + item.txt1); } foreach (var item in user4) { Console.WriteLine("我要从数据库中读取数据了2:" + item.txt1); } foreach (var item in user6) { Console.WriteLine("我要从数据库中读取数据了3:" + item.txt1); }
延迟加载上述案例分析:
* IQueryable类型的 user4和user6, 都是延迟加载的,下面foreach第一次使用该对象的时候去数据库查询。
* 这里会有这么几个问题:
* ①:foreach第一次遍历的时候去数据库中查询user4,然后放到本地缓存里,后面无论循环多少次,都是从本地缓存中读取user4。
* ②:前两个foreach操控的对象都是user4,所以第二个foreach无论哪次循环,都是从本地缓存中读取
* ③:第三个foreach操控的对象是user6,同样是在foreach第一次循环的时候去数据库查询,所以在代码执行到第一个或第二个foreach的时候,
* 手动去数据库改数据,当执行到第三个foreach,查询出来的数据就是修改后的了。
Lazy Loading
1. 又名:延迟加载、懒加载
2. 需要满足的条件:
①:poco类是public且不能为sealed
②:导航属性需要标记为Virtual
满足以上两个条件,EF6默认就为延迟加载的模式。(默认:db.Configuration.LazyLoadingEnabled = true; )
3. 含义:每次调用子实体(外键所在的实体)的时候,才去查询数据库. 主表数据加载的时候,不去查询外键所在的从表。
4. 关闭延迟加载的办法: db.Configuration.LazyLoadingEnabled = false;
特别注意:关闭延迟加载后,查询主表数据时候,主表的中从表实体为null.
下面准备两张表:Student和StudentAddress两张表,一对一 or 零 的关系,实体结构如下,通过CodeFirst来反向生成数据库。
/// <summary> /// 学生表(一个学生只能有一个地址或没有地址) /// </summary> public class Student { public Student() { } public string studentId { get; set; } public string studentName { get; set; } public virtual StudentAddress StudentAddress { get; set; } }
/// <summary> /// 学生地址表(一个地址只能对应一个学生) /// </summary> public class StudentAddress { public StudentAddress() { } [ForeignKey("stu")] //特别注意这个地方,stu对应下面的 Student stu; //另外特别注意:studentAddressId,符合默认的Id生成规则,自动映射成主键,否则需要加【key】特性 public string studentAddressId { get; set; } public string addressName { get; set; } public virtual Student stu { get; set; } }
1. 延迟加载代码测试
using (dbContext1 db = new dbContext1()) { Console.WriteLine("--------------------------- 01-延迟加载 -----------------------------"); db.Database.Log = Console.WriteLine; //EF默认就是延迟加载,默认下面的语句就是true,所以下面语句注释没有任何影响 //db.Configuration.LazyLoadingEnabled = true; var list = db.Student.ToList(); //此处加载的数据,根据监测得出结论,没有对从表进行任何查询操作 foreach (var stu in list) { Console.WriteLine("学生编号:{0},学生姓名:{1}", stu.studentId, stu.studentName); //下面调用导航属性(一对一的关系) 每次调用时,都要去查询数据库(查询从表) var stuAddress = stu.StudentAddress; Console.WriteLine("地址编号:{0},地址名称:{1}", stuAddress.studentAddressId, stu.studentName); } }
2. 关闭延迟加载
using (dbContext1 db = new dbContext1()) { try { Console.WriteLine("--------------------------- 02-关闭延迟加载 -----------------------------"); db.Database.Log = Console.WriteLine; //下面的语句为关闭延迟加载 db.Configuration.LazyLoadingEnabled = false; var list = db.Student.ToList(); //关闭延迟加载后,此处从表实体StudentAddress为null,后面不会再次查询了 foreach (var stu in list) { Console.WriteLine("学生编号:{0},学生姓名:{1}", stu.studentId, stu.studentName); //StudentAddress为null,不会再次查询数据库,所以此处报错 var stuAddress = stu.StudentAddress; Console.WriteLine("地址编号:{0},地址名称:{1}", stuAddress.studentAddressId, stu.studentName); } } catch (Exception ex) { Console.WriteLine(ex.Message); } }
Eager Loading
1. 又名:立即加载、贪婪加载、预加载
2. 使用步骤:
①:先关闭延迟加载:db.Configuration.LazyLoadingEnabled = false;
②:查询主表的同时通过Include把从表数据也查询出来:
3. 含义:由于查询主表的时候通过Include已经一次性将数据查询了出来,所以在调用从表数据的时候,均从缓存中读取,无须查询数据库
代码测试
using (dbContext1 db = new dbContext1()) { Console.WriteLine("--------------------------- 03-立即加载 -----------------------------"); db.Database.Log = Console.WriteLine; //1.关闭延迟加载 db.Configuration.LazyLoadingEnabled = false; //2. 获取主表数据的同时,通过Include将从表中的数据也全部加载出来 var list = db.Student.Include("StudentAddress").ToList(); foreach (var stu in list) { Console.WriteLine("学生编号:{0},学生姓名:{1}", stu.studentId, stu.studentName); //这里获取从表中的数据,均是从缓存中获取,无需查询数据库 var stuAddress = stu.StudentAddress; Console.WriteLine("地址编号:{0},地址名称:{1}", stuAddress.studentAddressId, stu.studentName); } }
Explicit Loading
1. 又名:显示加载
2. 背景:关闭延迟加载后,单纯查询主表的数据,后面又想再次查询从表,这个时候就需要用到显示加载了.
3. 前提:
①:关闭了延迟加载:db.Configuration.LazyLoadingEnabled = false;
②:单纯查询了主表,没有使用Include函数关联查询从表.
4. 使用步骤:
①:单个实体用:Reference
②:集合用:Collection
③:最后需要Load一下
5. 含义:关闭了延迟加载,单纯查询了主表数据,这个时候需要重新查询从表数据,就要用到显式加载了
代码测试
using (dbContext1 db = new dbContext1()) { Console.WriteLine("--------------------------- 04-显式加载 -----------------------------"); db.Database.Log = Console.WriteLine; //1.关闭延迟加载 db.Configuration.LazyLoadingEnabled = false; //2.此处加载的数据,不含从表中的数据 var list = db.Student.ToList(); foreach (var stu in list) { Console.WriteLine("学生编号:{0},学生姓名:{1}", stu.studentId, stu.studentName); //3.下面的这句话,可以开启重新查询一次数据库 //3.1 单个属性的情况用Refercence db.Entry<Student>(stu).Reference(c => c.StudentAddress).Load(); //3.2 集合的情况用Collection //db.Entry<Student>(stu).Collection(c => c.StudentAddress).Load(); //下面调用导航属性(一对一的关系) 每次调用时,都要去查询数据库 var stuAddress = stu.StudentAddress; Console.WriteLine("地址编号:{0},地址名称:{1}", stuAddress.studentAddressId, stu.studentName); } }
EF的三种事务
什么是事务
我们通俗的理解事务就是一系列操作要么全部成功、要么全部失败(不可能存在部分成功,部分失败的情况)。
举一个事务在我们日常生活中的经典例子:两张银行卡(甲、乙),甲向乙转钱,整个过程需要执行两个操作,甲账户钱减少,乙账户钱增加,这是转账成功的情况;转账失败时候,二者均不执行,甲乙账户钱都不变。
1. SQLServer中的事务
SQLServer中的事务具体封装方式有多种,但无论是哪种,都需要依赖于这三句代码:begin transaction 、commit transaction、rollback transaction。
具体怎么使用,详见数据库事务章节:去复习
2. EF中的事务
EF中的事务主要分为三类,分别是SaveChanges、DbContextTransaction、TransactionScope。
需要掌握的是这三种事务各自的使用方式和适用场景。
SaveChanges
SaveChanges是EF中最常见的事务了,在前面章节,多次提到,SaveChanges一次性将本地缓存中所有的状态变化一次性提交到数据库,这就是一个事务,要么统一成功,要么统一回滚。
应用场景:该种事务模式在实际开发中非常常用,在处理模块业务同时需要对一张表(或多张表)进行一系列增删改操作,但这些操作都是要么都成功,要么都失败,这种情况下可以在流程的最后 调用SaveChanges,一次性保存本地属性状态的全部变化。
该模式作用于一个DBContext,即一个数据库的EF的上下文,不能控制多个数据库。
比如:注册场景,可能需要向用户表、日志表、账户表等多张表中插入数据,其中一张表插入失败,所有的都需要回滚,这种情况,就可以在该业务的最后,统一调用SaveChanges一次性的事务提交。
事务成功
private static void TestSaveChanges() { using (DbContext db = new CodeFirstModel()) { //增加 TestInfor t1 = new TestInfor() { id = Guid.NewGuid().ToString("N"), txt1 = "txt1", txt2 = "txt2" }; db.Set<TestInfor>().Add(t1); //删除 TestInfor t2 = db.Set<TestInfor>().Where(u => u.id == "1").FirstOrDefault(); if (t2 != null) { db.Set<TestInfor>().Remove(t2); } //修改 TestInfor t3 = db.Set<TestInfor>().Where(u => u.id == "3").FirstOrDefault(); t3.txt2 = "我是李马茹23"; //SaveChanges事务提交 int n = db.SaveChanges(); Console.WriteLine("数据作用条数:" + n); } }
事务回滚
private static void TestSaveChangesFailure() { using (DbContext db = new CodeFirstModel()) { //增加 TestInfor t1 = new TestInfor() { id = Guid.NewGuid().ToString("N"), txt1 = "txt1", txt2 = "txt2" }; db.Set<TestInfor>().Add(t1); //删除 TestInfor t2 = db.Set<TestInfor>().Where(u => u.id == "1").FirstOrDefault(); if (t2 != null) { db.Set<TestInfor>().Remove(t2); } //修改 TestInfor t3 = db.Set<TestInfor>().Where(u => u.id == "3").FirstOrDefault(); t3.txt2 = "我是李马茹23"; //增加(制造错误) TestInfor t4 = new TestInfor() { id = Guid.NewGuid().ToString("N") + "123", txt1 = "txt1", txt2 = "txt2" }; db.Set<TestInfor>().Add(t4); //SaveChanges事务提交 int n = db.SaveChanges(); Console.WriteLine("数据作用条数:" + n); } }
DbContextTransaction事务
该事务为EF6新增的事务,通常用于手动接管事务,某些操作是一个事务,某些操作是另外一个事务。
使用场景:EF调用SQL语句的时候使用该事务、 多个SaveChanges的情况(解决自增ID另一个业务中使用的场景)。
核心代码:BeginTransaction、Commit、Rollback、Dispose. 如果放到using块中,就不需要手动Dispose了。
该种事务与数据库中的transaction事务原理一致,在EF中,由于每次调用 db.Database.ExecuteSqlCommand(sql1, pars1)的时候,即刻执行了该SQL语句,所以要把他放到一个大的事务中,整体提交、回滚.(EF6新增的)
事务成功
private static void TestDbContextTransaction() { using (DbContext db = new CodeFirstModel()) { DbContextTransaction trans = null; try { //开启事务 trans = db.Database.BeginTransaction(); //增加 string sql1 = @"insert into TestInfor values(@id,@txt1,@txt2)"; SqlParameter[] pars1 ={ new SqlParameter("@id",Guid.NewGuid().ToString("N")), new SqlParameter("@txt1","txt11"), new SqlParameter("@txt2","txt22") }; db.Database.ExecuteSqlCommand(sql1, pars1); //删除 string sql2 = @"delete from TestInfor where id=@id"; SqlParameter[] pars2 ={ new SqlParameter("@id","22") }; db.Database.ExecuteSqlCommand(sql2, pars2); //修改 string sql3 = @"update TestInfor set txt1=@txt1 where id=@id"; SqlParameter[] pars3 ={ new SqlParameter("@id","3"), new SqlParameter("@txt1","二狗子") }; db.Database.ExecuteSqlCommand(sql3, pars3); //提交事务 trans.Commit(); Console.WriteLine("事务成功了"); } catch (Exception ex) { Console.WriteLine(ex.Message); trans.Rollback(); } finally { trans.Dispose(); //也可以把该事务写到using块中,让其自己托管,就不需要手动释放了 } } }
事务回滚
private static void TestDbContextTransactionFailure() { using (DbContext db = new CodeFirstModel()) { DbContextTransaction trans = null; try { //开启事务 trans = db.Database.BeginTransaction(); //增加 string sql1 = @"insert into TestInfor values(@id,@txt1,@txt2)"; SqlParameter[] pars1 ={ new SqlParameter("@id",Guid.NewGuid().ToString("N")), new SqlParameter("@txt1","txt11"), new SqlParameter("@txt2","txt22") }; db.Database.ExecuteSqlCommand(sql1, pars1); //删除 string sql2 = @"delete from TestInfor where id=@id"; SqlParameter[] pars2 ={ new SqlParameter("@id","22") }; db.Database.ExecuteSqlCommand(sql2, pars2); //修改 string sql3 = @"update TestInfor set txt1=@txt1 where id=@id"; SqlParameter[] pars3 ={ new SqlParameter("@id","3"), new SqlParameter("@txt1","二狗子222") }; db.Database.ExecuteSqlCommand(sql3, pars3); //增加(制造错误) string sql4 = @"insert into TestInfor values(@id,@txt1,@txt2)"; SqlParameter[] pars4 ={ new SqlParameter("@id",Guid.NewGuid().ToString("N")+"123"), new SqlParameter("@txt1","txt11"), new SqlParameter("@txt2","txt22") }; db.Database.ExecuteSqlCommand(sql4, pars4); //提交事务 trans.Commit(); Console.WriteLine("事务成功了"); } catch (Exception ex) { Console.WriteLine(ex.Message); trans.Rollback(); } finally { trans.Dispose(); } } }
自DbContextTransaction事务测试多个SaveChanges的情况统一回滚
private static void DbContextTransSaveChanges() { using (DbContext db = new CodeFirstModel()) { //自动脱管,不需要手动释放 using (DbContextTransaction trans = db.Database.BeginTransaction()) { try { TestInfor t1 = new TestInfor() { id = Guid.NewGuid().ToString("N"), txt1 = "111111111", txt2 = "222222222222" }; db.Entry(t1).State = EntityState.Added; db.SaveChanges(); //人为制造失败情况 TestInfor t2 = new TestInfor() { id = Guid.NewGuid().ToString("N") + "123", txt1 = "111111111", txt2 = "222222222222" }; db.Entry(t2).State = EntityState.Added; db.SaveChanges(); trans.Commit(); } catch (Exception) { trans.Rollback(); } } } }
TransactionScope事务
1. 该事务用来处理多个SaveChanges的事务(特殊情况的业务)或者多个DBContext(每个DBContext是一个实例,代表不同的数据库连接).
2. 核心代码:(一个Complete函数走天下,异常的话,自动回滚 ,也可以结合try-catch Transaction.Current.Rollback();实现回滚)
需要引入程序集:using System.Transactions;
3. 适用场景:
①该种事务适用于多数据库连接的情况
特别注意:如果使用该事务来处理多个数据库(多个DBContex)时,必须手动开启msdtc服务,这样才可以将多个DB的SaveChange给放到一个事务中,如果失败, 则多个数据库的数据统一回滚.
开启msdtc服务的步骤: cmd命令→net start msdtc
②主键id自增的情况,同一个业务线中,需要拿到新增加的数据的主键id,进行操作。
③多线程带锁的情况,同一条业务线前半部分必须先SaveChanges,才能保证数据准确性(测试简单版本,实际的业务场景待补充!!!)
4. 主键自增被使用的情况的解决方案
private static void Test3() { using (DbContext db = new CodeFirstModel()) { using (TransactionScope trans = new TransactionScope()) { try { TestInfor2 t1 = new TestInfor2() { txt11 = Guid.NewGuid().ToString("N"), txt22 = Guid.NewGuid().ToString("N") }; db.Set<TestInfor2>().Add(t1); //如果这里不写SaveChanges的话,t1.id永远为0 db.SaveChanges(); TestInfor2 t2 = new TestInfor2() { txt11 = (t1.id + 1).ToString(), txt22 = Guid.NewGuid().ToString("N") }; db.Entry(t2).State = EntityState.Added; db.SaveChanges(); //事务统一提交(若失败则统一回滚) trans.Complete(); Console.WriteLine("自增提交成功"); } catch (Exception) { Transaction.Current.Rollback(); } } } }
5. 多个DBContext、多个数据库的情况。
private static void TransactionScopeTwoDB() { using (TransactionScope trans = new TransactionScope()) { try { DbContext db1 = new CodeFirstModel(); DbContext db2 = new CodeFirstModel2(); //数据库1 TestInfor t1 = new TestInfor() { id = Guid.NewGuid().ToString("N"), txt1 = "111111111", txt2 = "222222222222" }; db1.Entry(t1).State = EntityState.Added; db1.SaveChanges(); //数据库2 TestOne t2 = new TestOne() { id = Guid.NewGuid().ToString("N"), //可以在此处手动制造个错误,来测试多数据库的回滚问题 t1 = "222", t2 = "2222" }; db2.Entry(t2).State = EntityState.Added; db2.SaveChanges(); trans.Complete(); Console.WriteLine("多个数据库添加成功"); } catch (Exception) { Transaction.Current.Rollback(); } } }
EF性能问题
开发中常见的性能问题
我们在日常开发过程中,由于一些不好的习惯,经常会导致所写的代码性能低下,却毫无发觉,下面就总结一下常见的一些性能问题。
1. 真假分页
① 假分页: db.xxx.toList().Skip(2).take(4) 。
② 真分页:db.xxx.Skip(2).take(3).toList() 。
2. 合理的使用EF的数据加载方式
EF的加载方式有:立即加载、延迟加载、显示加载。
详见:
①: 第五节: EF高级属性(一) 之 本地缓存、立即加载、延迟加载(不含导航属性)
②: 第六节: EF高级属性(二) 之延迟加载、立即加载、显示加载(含导航属性)。
3. NoTracking的使用
EF查询出来的实体,默认是跟踪状态的,如果查询出来的实体不需要修改或者删除,查询的时候可以删除状态跟踪,变为Detached状态,来提高性能。
关于EF状态的跟踪,详见后面章节,敬请期待!!
using (DbContext context = new MyDbContext()) { var people = context.Student.Where(p => p.Id > 2).AsNoTracking().ToList(); }
4. 合理的使用SQL事务
将与事务无关的一些SQL语句放到事务外,如果一个事务中的SQL语句过长,很容易出现死锁问题,压力测试时,出现资源被锁的错误。
关于EF数据操作的性能问题
EF自诞生以来,大批量的操作增加、删除、修改操作数据效率一直很低,1000条数据以内,效率尚且可以接受(10s内),但随着数据量逐渐增大,很容易在执行的过程中就宕机了,相当尴尬。在本章节,我们一起来测试一下,EF在不进行任何优化的情况下,几种写法的效率问题。
我们这里的测试是以增加数据为例,先把测试的三种写法的结论贴上。

1. 每添加1条数据,savechange一下(小白常犯的错误,坚决抵制这种做法!!)
private static void NewMethod1(DbContext db) { Console.WriteLine("-------------1. 每添加1条数据,savechange一下(小白常犯的错误,坚决抵制这种做法!!)-------------------"); Stopwatch watch = Stopwatch.StartNew(); for (int i = 0; i < 1000; i++) { TestOne t = new TestOne(); t.id = Guid.NewGuid().ToString("N"); t.t1 = "t1+" + i; t.t1 = "t2+" + i; db.Set<TestOne>().Add(t); db.SaveChanges(); } watch.Stop(); Console.WriteLine("1000条数据耗时:{0}", watch.ElapsedMilliseconds); }
2. 先将所有数据添加到内存里,最后再savechange
private static void NewMethod2(DbContext db, int count) { Console.WriteLine("-------------2. 先将所有数据添加到内存里,最后再savechange-------------------"); Stopwatch watch = Stopwatch.StartNew(); for (int i = 0; i < count; i++) { TestOne t = new TestOne(); t.id = Guid.NewGuid().ToString("N"); t.t1 = "t1+" + i; t.t1 = "t2+" + i; db.Set<TestOne>().Add(t); } db.SaveChanges(); watch.Stop(); Console.WriteLine("{0}条数据耗时:{1}", count, watch.ElapsedMilliseconds); }
3. 使用addRange方法,先将数据加到list集合中,然后一次性通过addRange加到内存里
private static void NewMethod3(DbContext db, int count) { Console.WriteLine("-------------3. 使用addRange方法,先将数据加到list集合中,然后一次性通过addRange加到内存里-------------------"); Stopwatch watch = Stopwatch.StartNew(); List<TestOne> tList = new List<TestOne>(); for (int i = 0; i < count; i++) { TestOne t = new TestOne(); t.id = Guid.NewGuid().ToString("N"); t.t1 = "t1+" + i; t.t1 = "t2+" + i; tList.Add(t); } db.Set<TestOne>().AddRange(tList); db.SaveChanges(); watch.Stop(); Console.WriteLine("{0}条数据耗时:{1}", count, watch.ElapsedMilliseconds); }
总结:EF自有的方法,三个阶段如上,数据超过1000条,性能直线下降
性能解决方案(SqlBulkCopy类插入)
使用步骤:
①. 引入命名空间:using System.Data.SqlClient;
②. 使用DataTable构造与目标数据库表结构相同的字段,并给其赋值。
③. 使用SqlBulkCopy类,将内存表中的数据一次性插入到目标表中。(看下面的封装可知,可以自行设置插入块的大小)
补充:调用下面的封装这种形式必须内存表中的字段名和数据库表中的字段名一一对应。
使用方式及其性能测试
1. 涉及到的数据库结构:

2. 数据库连接字符串
<add name="CodeFirstModel2" connectionString="data source=localhost;initial catalog=EFDB2;persist security info=True;user id=sa;password=123456;MultipleActiveResultSets=True;App=EntityFramework" providerName="System.Data.SqlClient" />
3. 代码实践
有两种插入方式,一种是按部就班的每个字段 内存表和数据表进行映射,这个情况无须名称一致,只要映射正确即可。另外一种方式是,直接调用下面的封装方法即可,这种要求内存表中字段和数据库表中的字段名称必须完全一致,一一对应,这样就省去了方法一 中一一匹配映射的繁琐步骤了。
public class SqlBulkCopyTest { public static void TestSqlBulkCopy() { //一. 构造DataTable结构并且给其赋值 //1.定义与目标表的结构一致的内存表 排除自增id列 DataTable dtSource = new DataTable(); //列名称如果和目标表设置为一样,则后面可以不用进行字段映射 dtSource.Columns.Add("id"); dtSource.Columns.Add("t21"); dtSource.Columns.Add("t22"); //2. 向dt中增加4W条测试数据 DataRow dr; for (int i = 0; i <40000; i++) { // 创建与dt结构相同的DataRow对象 dr = dtSource.NewRow(); dr["id"] = Guid.NewGuid().ToString("N"); dr["t21"] = "Name" + i; dr["t22"] = "Address" + i; // 将dr追加到dt中 dtSource.Rows.Add(dr); } //二.将内存表dt中的4W条数据一次性插入到t_Data表中的相应列中 System.Diagnostics.Stopwatch st = new System.Diagnostics.Stopwatch(); st.Start(); string connStr = ConfigurationManager.ConnectionStrings["CodeFirstModel2"].ToString(); #region 01-按部就班一一对应 //{ // using (SqlBulkCopy copy = new SqlBulkCopy(connStr)) // { // //1 指定数据插入目标表名称 // copy.DestinationTableName = "TestTwo"; // //2 告诉SqlBulkCopy对象 内存表中的 字段和目标表中的字段 对应起来(这里有多个重载,也可以用索引对应) // //前面是内存表,后面是目标表即数据库中的字段 // copy.ColumnMappings.Add("id", "id"); // copy.ColumnMappings.Add("t21", "t21"); // copy.ColumnMappings.Add("t22", "t22"); // //3 将内存表dt中的数据一次性批量插入到目标表中 // copy.WriteToServer(dtSource); // } //} #endregion #region 02-调用封装 { AddByBluckCopy(connStr, dtSource, "TestTwo"); } #endregion st.Stop(); Console.WriteLine("数据插入成功,总耗时为:" + st.ElapsedMilliseconds + "毫秒"); } /// <summary> /// 海量数据插入方法 /// (调用该方法需要注意,DataTable中的字段名称必须和数据库中的字段名称一一对应) /// </summary> /// <param name="connectstring">数据连接字符串</param> /// <param name="table">内存表数据</param> /// <param name="tableName">目标数据的名称</param> public static void AddByBluckCopy(string connectstring,DataTable table, string tableName) { if (table != null && table.Rows.Count > 0) { using (SqlBulkCopy bulk = new SqlBulkCopy(connectstring)) { bulk.BatchSize = 1000; bulk.BulkCopyTimeout = 100; bulk.DestinationTableName = tableName; bulk.WriteToServer(table); } } } }
4. 性能测试的结论

根据上述的数据测试可以看出来,SqlBulkCopy在处理大数据量插入上速度非常快,甚至比付费的插件Z.EntityFramework.Extensions都要快,所以值得参考和推荐。
性能解决方案(Z.EntityFrameWork.Plus.EF6 插件删除和更新)
前面提到了 SqlBulkCopy 类(与EF没有半毛钱关系),它可以实现增加操作,不得不说,它在处理大数据量的增加的时候,确实很出色!!!。
那么删除和更新怎么办呢?
答案是:可以借助 Z.EntityFrameWork.Plus.EF6 才解决。
进入主题
Z.EntityFrameWork.Plus.EF6 和 Z.EntityFramework.Extensions 是同一公司的产物,该插件支持的功能很多,比如 删除、更新、缓存机制、过滤器等等,但唯独没有新增操作(都懂得,什么功能都有的话,他的兄弟 Z.EntityFramework.Extensions 怎么办?)。
本章节仅介绍删除和更新两个最常用的功能。
该插件的几点说明:
①:仅支持EF5、EF6、EF Core,注意不同的版本对应该插件的后缀不同,该章节使用的是EF 6.2,所以对应 Z.EntityFrameWork.Plus.EF6
②:官方号称:Improve EF Performance by 2000%
③:可以通过Nuget进行安装
④:文档地址 : http://entityframework-plus.net/batch-delete
GitHub地址: https://github.com/zzzprojects/EntityFramework-Plus
数据库准备

删除相关
1. Delete() 同步删除方法
2. DeleteAsync() 异步删除方法 <根据实际业务场景选择使用>
3. BatchSize:批次大小
Delete和DeleteAsync两个删除方法都可以设置该参数的值:x => x.BatchSize,该参数表示一次执行的条数,默认值为4000,比如你要删除4w条数据,默认值的话,就要删除10次,
适当的提高该值,会增加删除效率,但并不代表无限增大。
特别注意:下面测试使用的Delete方法是默认块级大小4000的情况下进行测试,后面把BatchSize直接改为8w,删除8w条数据在1.6s左右
4:BatchDelayInterval:批次执行的时间间隔
比如BatchSize=4000,BatchDelayInterval=1000,删除4w条数据,表示的意思是删除4000的时候等待1s,然后再删除。
PS:该参数不是很常用,适用于你既需要删除很多数据,而且在批处理之间的暂停间隔继续执行CRUD操作
5:Executing:执行删除命令之前,去执行一段命令文本
PS:根据实际场景选择使用。
下面进行性能测试:(1w条、 4w条、 8w条数据的删除操作)
(1). EF原生删除代/// <summary>
/// EF普通方法测试性能 /// </summary> /// <param name="db"></param> public static void DeleteCommon1(DbContext db) { Console.WriteLine("---------------------调用普通方法1删除--------------------------------"); var list=db.Set<TestTwo>.Where(u=>u.id!="1").ToList();
Stopwatch watch = Stopwatch.StartNew();
foreach (var item in list) { db.Entry(item).State = EntityState.Deleted; } int count = db.SaveChanges(); watch.Stop(); Console.WriteLine($"{count}条数据耗时:{watch.ElapsedMilliseconds}"); }
(2). EF调用SQL语句的代码
/// <summary> /// EF调用SQL语句测试删除 /// </summary> /// <param name="db"></param> public static async void DeleteCommon2(DbContext db) { Stopwatch watch = Stopwatch.StartNew(); string sql = "delete from TestTwo where id !='1' "; int count = 0; //加上await,表示在这一步上异步方法执行完 var response = await db.Database.ExecuteSqlCommandAsync(sql); count = response; Console.WriteLine("异步方法已经开始执行,请耐心等待"); watch.Stop(); Console.WriteLine($"{count}条数据耗时:{watch.ElapsedMilliseconds}"); }
(3). 利用该插件扩展的代码
public static void DeletePlus(DbContext db) { Console.WriteLine("---------------------调用扩展方法删除--------------------------------"); Stopwatch watch = Stopwatch.StartNew(); int count = db.Set<TestTwo>().Where(u => u.id != "1").Delete(); //设置块级大小(默认4000) //int count = db.Set<TestTwo>().Where(u => u.id != "1").Delete(u => u.BatchSize = 80000); watch.Stop(); Console.WriteLine($"{count}条数据耗时:{watch.ElapsedMilliseconds}"); }
最终的测试结论(下面的时间是取三次结果的平均值):
1w条数据 4w条数据 8w条数据
EF原生删除 76s 累哭了 累哭了
EF调SQL语句 1.152s 1.232s 1.558s
Z.Plus(默认块) 1.307s 1.982s 2.675s
最终结论: Z.EntityFrameWork.Plus.EF6的删除比EF原生要快的多! 但EF直接调用SQL语句貌似更快哈。
更新相关
有了上面删除的基础,这里的更新操作就容易的多,更新的性能提升与删除类似,这里不再单独测试了,下面简单粗暴,直接介绍用法。
1. Update() 同步更新方法
2. UpdateAsync() 异步更新方法
3. Executing:上述两个方法的一个参数,表示执行更新命令之前,去执行一段命令文本(根据实际情况选择使用)
直接上代码:
public static void UpdatePlus(DbContext db) { Console.WriteLine("---------------------调用扩展方法更新--------------------------------"); Stopwatch watch = Stopwatch.StartNew(); int count = db.Set<TestTwo>().Where(u => u.id != "1").Update(x => new TestTwo() { t21 = "0", t22 = "1" }); watch.Stop(); Console.WriteLine($"{count}条数据耗时:{watch.ElapsedMilliseconds}"); }
综述:该插件的使用非常简单,在使用上,可以说没有任何难度可言,很多情况下,并不是你不会解决,而是你缺少一双善于发现的眼镜。
免费的大数据解决方案: SqlBulkCopy + Z.EntityFrameWork.Plus + EF调用SQL语句/存储过程 或许是一个不错的选择。
以上内容主要来自:https://www.cnblogs.com/yaopengfei http://www.cnblogs.com/wukeng/p/6429461.html

付费内容,请联系本人QQ:1002453261
本文来自博客园,作者:明志德道,转载请注明原文链接:https://www.cnblogs.com/for-easy-fast/articles/12523112.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号