为什么使用 Redis 及其产品定位
一:传统 MySQL+ Memcached 架构遇到的问题
实际 MySQL 是适合进行海量数据存储的,通过 Memcached 将热点数据加载到 cache,加速访问,很多公司都曾经使用过这样的架构,但随着业务数据量的不断增加,和访问量的持续增长,我们遇到了很多问题:
- MySQL 需要不断进行拆库拆表,Memcached 也需不断跟着扩容,扩容和维护工作占据大量开发时间。
- Memcached 与 MySQL 数据库数据一致性问题。
- Memcached 数据命中率低或 down 机,大量访问直接穿透到 DB,MySQL 无法支撑。
- 跨机房 cache 同步问题。
二:众多 NoSQL 百花齐放,如何选择
最近几年,业界不断涌现出很多各种各样的 NoSQL 产品,那么如何才能正确地使用好这些产品,最大化地发挥其长处,是我们需要深入研究和思考的问题,实际归根结底最重要的是了解这些产品的定位,并且了解到每款产品的权衡取舍(tradeoffs),在实际应用中做到扬长避短,总体上这些 NoSQL 主要用于解决以下几种问题
- 少量数据存储,高速读写访问。此类产品通过数据全部内存数据库(in-momery DB) 的方式来保证高速访问,同时提供数据落地的功能,实际这正是 Redis 最主要的适用场景。
- 海量数据存储,分布式系统支持,数据一致性保证,方便的集群节点添加 / 删除。
- 这方面最具代表性的是 dynamo(亚马逊的存储方式) 和 bigtable(谷歌的存储方式) 2 篇论文所阐述的思路。前者是一个完全无中心的设计,节点之间通过 gossip 方式传递集群信息,数据保证最终一致性,后者是一个中心化的方案设计,通过类似一个分布式锁服务来保证强一致性, 数据写入先写内存和 redo log(物理日志,记录的是数据页的物理修改,而不是某一行或某几行修改成怎样怎样,它用来恢复提交后的物理数据页(恢复数据页,且只能恢复到最后一次提交的位置),然后定期 compat (兼容)归并到磁盘上,将随机写优化为顺序写,提高写入性能。
- Schema free(自由模式),auto-sharding(自动分片) 等。比如目前常见的一些文档数据库都是支持 schema-free (自由模式)的,直接存储 json 格式数据,并且支持 auto-sharding 等功能,比如 mongodb。
面对这些不同类型的 NoSQL 产品, 我们需要根据我们的业务场景选择最合适的产品。
三:Redis 适用场景,如何正确的使用
前面已经分析过,Redis 最适合所有数据 in-momory(内存存储) 的场景,虽然 Redis 也提供持久化功能,但实际更多的是一个 disk-backed 的功能,跟传统意义上的持久化有比较大的差别,那么可能大家就会有疑问,似乎 Redis 更像一个加强版的 Memcached,那么何时使用 Memcached, 何时使用 Redis 呢?
四:Redis 与 Memcached 的比较
1:网络 IO 模型
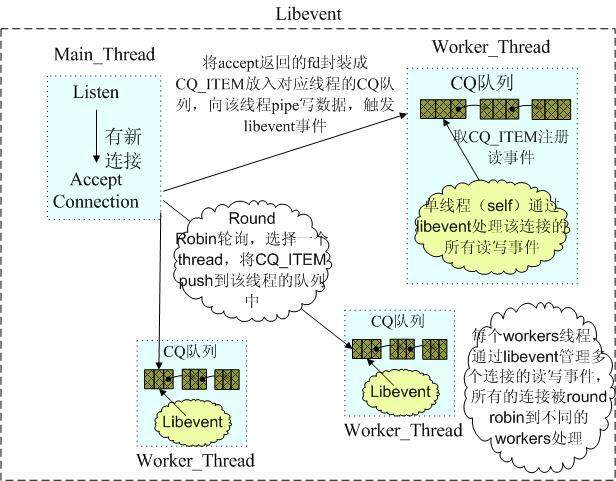
Memcached 是多线程,非阻塞 IO 复用的网络模型,分为监听主线程和 worker 子线程,监听线程监听网络连接,接受请求后,将连接描述字 pipe 传递给 worker 线程,进行读写 IO, 网络层使用 libevent 封装的事件库,多线程模型可以发挥多核作用,但是引入了 cache coherency 和锁的问题,比如,Memcached 最常用的 stats 命令,实际 Memcached 所有操作都要对这个全局变量加锁,进行计数等工作,带来了性能损耗。
(Memcached 网络 IO 模型)
Redis 使用单线程的 IO 复用模型,自己封装了一个简单的 AeEvent 事件处理框架,主要实现了 epoll、kqueue 和 select,对于单纯只有 IO 操作来说,单线程可以将速度优势发挥到最大,但是 Redis 也提供了一些简单的计算功能,比如排序、聚合等,对于这些操作,单线程模型实际会严重影响整体吞吐量,CPU 计算过程中,整个 IO 调度都是被阻塞住的。
2:内存管理方面
Memcached 使用预分配的内存池的方式,使用 slab 和大小不同的 chunk 来管理内存,Item 根据大小选择合适的 chunk 存储,内存池的方式可以省去申请 / 释放内存的开销,并且能减小内存碎片产生,但这种方式也会带来一定程度上的空间浪费,并且在内存仍然有很大空间时,新的数据也可能会被剔除,原因可以参考 Timyang 的文章:http://timyang.net/data/Memcached-lru-evictions/
Redis 使用现场申请内存的方式来存储数据,并且很少使用 free-list 等方式来优化内存分配,会在一定程度上存在内存碎片,Redis 跟据存储命令参数,会把带过期时间的数据单独存放在一起,并把它们称为临时数据,非临时数据是永远不会被剔除的,即便物理内存不够,导致 swap 也不会剔除任何非临时数据(但会尝试剔除部分临时数据),这点上 Redis 更适合作为存储而不是 cache。
3:数据一致性问题
Memcached 提供了 cas 命令,可以保证多个并发访问操作同一份数据的一致性问题。 Redis 没有提供 cas 命令,并不能保证这点,不过 Redis 提供了事务的功能,可以保证一串 命令的原子性,中间不会被任何操作打断。
4:存储方式及其它方面
Memcached 基本只支持简单的 key-value 存储,不支持枚举,不支持持久化和复制等功能
Redis 除 key/value 之外,还支持 list,set,sorted set,hash 等众多数据结构,提供了 KEYS
进行枚举操作,但不能在线上使用,如果需要枚举线上数据,Redis 提供了工具可以直接扫描其 dump 文件,枚举出所有数据,Redis 还同时提供了持久化和复制等功能。
5:于不同语言的客户端支持
在不同语言的客户端方面,Memcached 和 Redis 都有丰富的第三方客户端可供选择,不过因为 Memcached 发展的时间更久一些,目前看在客户端支持方面,Memcached 的很多客户端更加成熟稳定,而 Redis 由于其协议本身就比 Memcached 复杂,加上作者不断增加新的功能等,对应第三方客户端跟进速度可能会赶不上,有时可能需要自己在第三方客户端基础上做些修改才能更好的使用。
根据以上比较不难看出,当我们不希望数据被踢出,或者需要除 key/value 之外的更多数据类型时,或者需要落地功能时,使用 Redis 比使用 Memcached 更合适。
四:关于 Redis 的一些周边功能
Redis 除了作为存储之外还提供了一些其它方面的功能,比如聚合计算、pubsub、scripting 等,对于此类功能需要了解其实现原理,清楚地了解到它的局限性后,才能正确的使用,比如 pubsub 功能,这个实际是没有任何持久化支持的,消费方连接闪断或重连之间过来的消息是会全部丢失的,又比如聚合计算和 scripting 等功能受 Redis 单线程模型所限,是不可能达到很高的吞吐量的,需要谨慎使用。
总的来说 Redis 作者是一位非常勤奋的开发者,可以经常看到作者在尝试着各种不同的新鲜想法和思路,针对这些方面的功能就要求我们需要深入了解后再使用。
五:总结
- Redis 使用最佳方式是全部数据 in-memory。
- Redis 更多场景是作为 Memcached 的替代者来使用。
- 当需要除 key/value 之外的更多数据类型支持时,使用 Redis 更合适。
- 当存储的数据不能被剔除时,使用 Redis 更合适。

付费内容,请联系本人QQ:1002453261
本文来自博客园,作者:明志德道,转载请注明原文链接:https://www.cnblogs.com/for-easy-fast/articles/12489133.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号