linux shell相关 & 定时清除日志脚本
日志清除脚本clear_log.sh
Linux定时清理日志脚本(find ... exec rm -rf)
#!/bin/bash # source /home/.bash_profile # 日志目录数组,根据需要增删 log_dirs=(/home/.../logdir1 /home/.../logdir2 ) # 定义日志文件最大容量KB max_size=1024*1024 # 循环定义的日志目录下的logs,超过1G则删除 for dir in ${log_dirs[@]} do echo 日志目录:$dir > /dev/null cd $dir # 超过定义大小,覆写nohup日志文件 out='nohup*' out_size=`ls -s $out|awk '{print $2}'` out_file=`ls -s $out|awk '{print $2}'` if [ $out_size -ge $max_size ] then :>$out_file fi # 超过规定大小,清空logs文件夹 file=logs if [ -e $file ] then # echo '日志目录logs存在' # if [ -f $file ] # then # echo "是文件" # elif [ -d $file ] # then # echo "是目录" size=`du -s $file|awk '{print $1}'` if [ $size -ge $max_size ] then rm -rf $file echo 执行删除 > /dev/null fi # fi else echo "logs目录不存在" # exec ls -s $file # exit 0 fi echo "结束" done
Linux下,脚本实现:查找tomcat的进程号,并杀死该进程;通过查找绝对路径 ,启动tomcat并查看日志
添加到服务器定时任务执行 crontab
Linux set命令
最常用的两个参数就是 -e 与 -x ,一般写在 shell 代码逻辑之前,这两个组合在一起用,可以在 debug 的时候替你节省许多时间 。
set -x 会在执行每一行 shell 脚本时,把执行的内容输出来。它可以让你看到当前执行的情况,里面涉及的变量也会被替换成实际的值。
set -e 会在执行出错时结束程序,就像其他语言中的“抛出异常”一样。
- -x 执行指令后,会先显示该指令及所下的参数。
vim set_test.sh #!/bin/bash set -x echo $* set +x 执行: sh set_test.sh 123 abc 运行结果 + echo 123 abc 123 abc + set +x
Shell 教程
变量
定义变量时,变量名不加美元符号
变量名和等号之间不能有空格
-
命名只能使用英文字母,数字和下划线,首个字符不能以数字开头。
-
中间不能有空格,可以使用下划线(_)。
-
不能使用标点符号。
使用一个定义过的变量,只要在变量名前面加美元符号即可
变量名外面的花括号是可选的,加不加都行,加花括号是为了帮助解释器识别变量的边界
使用 readonly 命令可以将变量定义为只读变量,只读变量的值不能被改变
使用 unset 命令可以删除变量。unset 命令不能删除只读变量。语法:
unset variable_name
Shell 字符串
字符串可以用单引号,也可以用双引号,也可以不用引号。
单引号字符串的限制:
单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的;
单引号字串中不能出现单独一个的单引号(对单引号使用转义符后也不行),但可成对出现,作为字符串拼接使用。
双引号的优点:
双引号里可以有变量
双引号里可以出现转义字符
Shell 数组
定义数组
在 Shell 中,用括号来表示数组,数组元素用"空格"符号分割开。定义数组的一般形式为:
数组名=(值1 值2 ... 值n)
读取数组
读取数组元素值的一般格式是:
${数组名[下标]}
${#数组名[*/@]}
使用 @ 符号可以获取数组中的所有元素
shell 注释
以#开头的行
多行注释
:>>EOF :>>' :>>!
注释内容
EOF ' !
shell基本运算符
算数运算符
+
-
* 乘号(*)前边必须加反斜杠()才能实现乘法运算
/
%
=
条件表达式要放在方括号之间,并且要有空格,例如: [$a==$b] 是错误的,必须写成 [ $a == $b ]
==
!=
关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字
-eq
-ne
-gt
-lt
-ge
le
布尔运算符
! 非
-o 或
-a 与
&&
||
字符串运算符
= 检查字符串是否相等
!=
-z 字符串长度是否为0,是返回true。[ -z $str ]
-n 字符串长度是否不为0
$ 检测字符串是否为空,不为空返回 true。
文件测试运算符
-d 检测文件是否是目录,如果是,则返回 true。
-f 检测文件是否是普通文件(既不是目录,也不是设备文件),如果是,则返回 true。
-p 检测文件是否是有名管道,如果是,则返回 true。
-e 检测文件(包括目录)是否存在,如果是,则返回 true
-s 检测文件是否为空(文件大小是否大于0),不为空返回 true。
-rwx 检测文件是否可读、可写、可执行
原生bash不支持简单的数学运算,但是可以通过其他命令来实现,例如 awk 和 expr,expr 最常用。
expr 是一款表达式计算工具,使用它能完成表达式的求值操作。
-
表达式和运算符之间要有空格,例如 2+2 是不对的,必须写成 2 + 2,这与我们熟悉的大多数编程语言不一样。
-
完整的表达式要被 ` ` 包含
shell流程控制
sh 的流程控制不可为空(如果 else 分支没有语句执行,就不要写这个 else。)
if else
if condition
then
command1
command2
...
commandN
fi
写成一行(适用于终端命令提示符):if [ $(ps -ef | grep -c "ssh") -gt 1 ]; then echo "true"; fi末尾的 fi 就是 if 倒过来拼写。
if else-if else
if else-if else 语法格式:
if condition1
then
command1
elif condition2
then
command2
else
commandN
fi
for 循环
与其他编程语言类似,Shell支持for循环。
for循环一般格式为:
for var in item1 item2 ... itemN
do
command1
command2
...
commandN
done
写成一行:
for var in item1 item2 ... itemN; do command1; command2… done;
while 语句
while 循环用于不断执行一系列命令,也用于从输入文件中读取数据。其语法格式为:
while condition
do
command
done
until 循环
case ... esac
case ... esac 为多选择语句,与其他语言中的 switch ... case 语句类似,是一种多分枝选择结构,每个 case 分支用右圆括号开始,用两个分号 ;; 表示 break,即执行结束,跳出整个 case ... esac 语句,esac(就是 case 反过来)作为结束标记。
可以用 case 语句匹配一个值与一个模式,如果匹配成功,执行相匹配的命令。
case ... esac 语法格式如下:
case 值 in
模式1)
command1
command2
...
commandN
;;
模式2)
command1
command2
...
commandN
;;
esac
case 工作方式如上所示,取值后面必须为单词 in,每一模式必须以右括号结束。取值可以为变量或常数,匹配发现取值符合某一模式后,其间所有命令开始执行直至 ;;。
取值将检测匹配的每一个模式。一旦模式匹配,则执行完匹配模式相应命令后不再继续其他模式。如果无一匹配模式,使用星号 * 捕获该值,再执行后面的命令。
跳出循环
shell中各种括号()、(())、[]、[[]]、{}的作用和区别
在 bash shell 中,$( ) 与 ` ` (反引号) 都是用来做命令替换用(command substitution)的,各自的优缺点和区别
${var...}
# 是去掉左边(在键盘上 # 在 $ 之左边)
% 是去掉右边(在键盘上 % 在 $ 之右边)
单一符号是最小匹配﹔两个符号是最大匹配。
${#var} 可计算出变量值的长度
$(( )) 用来作整数运算
在 $(( )) 中的变量名称,可于其前面加 $ 符号来替换,也可以不用
事实上,单纯用 (( )) 也可重定义变量值:
a=5; ((a++)) 可将 $a 重定义为 6
a=5; ((a–)) 则为 a=4
a=5; b=7; ((a < b)) 会得到 0 (true) 的返回值。
常见的用于 (( )) 的测试符号有如下这些:
<:小于
>:大于
<=:小于或等于
>=:大于或等于
==:等于
!=:不等于
awk 入门教程 Linux awk 命令
awk -F 指定分隔符
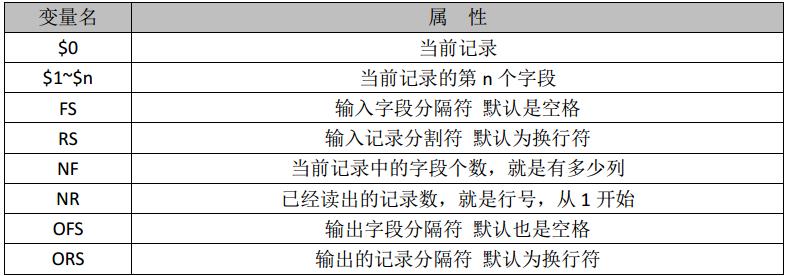
awk '{print $n}' 将数据分割后的第n个字段(print)输出

 浙公网安备 33010602011771号
浙公网安备 33010602011771号