Flink(四) —— 数据流编程模型
分层抽象

The lowest level abstraction simply offers stateful streaming. It is embedded into the DataStream API via the Process Function. It allows users freely process events from one or more streams, and use consistent fault tolerant state. In addition, users can register event time and processing time callbacks, allowing programs to realize sophisticated computations.
最低层次的抽象仅提供有状态流。它通过Process函数嵌入到DataStream API中。它允许用户自由地处理来自一个或多个流的事件,并使用一致的容错状态。此外,用户可以注册事件时间和处理时间回调,允许程序实现复杂的计算。
In practice, most applications would not need the above described low level abstraction, but would instead program against the Core APIs like the DataStream API (bounded/unbounded streams) and the DataSet API (bounded data sets). These fluent APIs offer the common building blocks for data processing, like various forms of user-specified transformations, joins, aggregations, windows, state, etc. Data types processed in these APIs are represented as classes in the respective programming languages.
在实践中,大多数应用程序不需要上面描述的低级抽象,而是对核心API进行编程,比如DataStream API(有界或无界数据流)和DataSet API(有界数据集)。这些API提供了用于数据处理的通用构建块,比如由用户定义的多种形式的转换、连接、聚合、窗口、状态等。在这些api中处理的数据类型以类(class)的形式由各自的编程语言所表示。
The low level Process Function integrates with the DataStream API, making it possible to go the lower level abstraction for certain operations only. The DataSet API offers additional primitives on bounded data sets, like loops/iterations.
低级流程函数与DataStream API集成,使得只对某些操作进行低级抽象成为可能。DataSet API为有界数据集提供了额外的原语,比如循环或迭代。
The Table API is a declarative DSL centered around tables, which may be dynamically changing tables (when representing streams). The Table API follows the (extended) relational model: Tables have a schema attached (similar to tables in relational databases) and the API offers comparable operations, such as select, project, join, group-by, aggregate, etc. Table API programs declaratively define what logical operation should be done rather than specifying exactly how the code for the operation looks. Though the Table API is extensible by various types of user-defined functions, it is less expressive than the Core APIs, but more concise to use (less code to write). In addition, Table API programs also go through an optimizer that applies optimization rules before execution.
Table API是一个以表为中心的声明性DSL,其中表可以动态地改变(当表示流数据时)。表API遵循(扩展)关系模型:表有一个附加模式(类似于关系数据库表)和API提供了类似的操作,如select, project, join, group-by, aggregate 等。Table API 程序以声明的方式定义逻辑操作应该做什么而不是指定操作的代码看起来如何。虽然Table API可以通过各种用户定义函数进行扩展,但它的表达性不如核心API,但使用起来更简洁(编写的代码更少)。此外,Table API程序还可以在执行之前通过应用优化规则的优化器。
One can seamlessly convert between tables and DataStream/DataSet, allowing programs to mix Table API and with the DataStream and DataSet APIs.
可以无缝地在Table API和DataStream/DataSet API之间进行切换,允许程序将Table API和DataStream和DataSet API进行混合使用。
The highest level abstraction offered by Flink is SQL. This abstraction is similar to the Table API both in semantics and expressiveness, but represents programs as SQL query expressions. The SQL abstraction closely interacts with the Table API, and SQL queries can be executed over tables defined in the Table API.
Flink提供的最高级别抽象是SQL。这种抽象在语义和表示方面都类似于Table API,但将程序表示为SQL查询表达式。SQL抽象与表API密切交互,SQL查询可以在表API中定义的表上执行。
编程与数据流
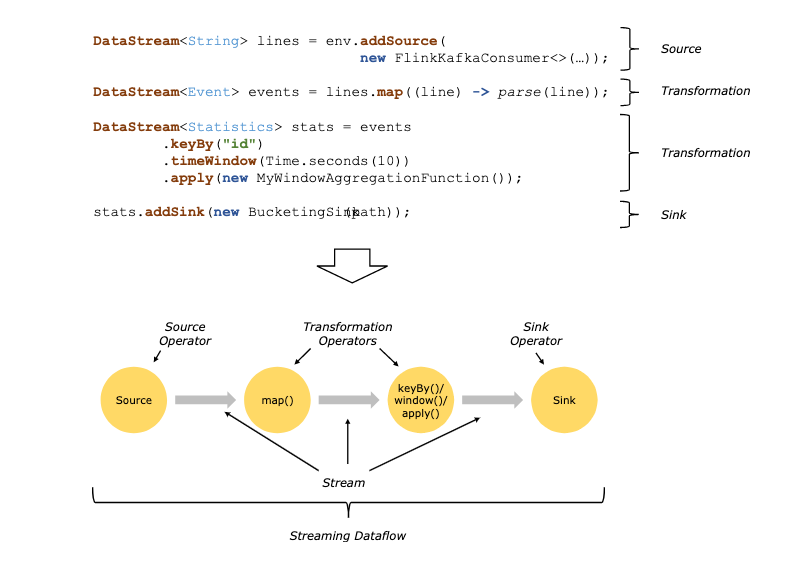
The basic building blocks of Flink programs are streams and transformations. (Note that the DataSets used in Flink’s DataSet API are also streams internally – more about that later.) Conceptually a stream is a (potentially never-ending) flow of data records, and a transformation is an operation that takes one or more streams as input, and produces one or more output streams as a result.
When executed, Flink programs are mapped to streaming dataflows, consisting of streams and transformation operators. Each dataflow starts with one or more sources and ends in one or more sinks. The dataflows resemble arbitrary directed acyclic graphs (DAGs). Although special forms of cycles are permitted via iteration constructs, for the most part we will gloss over this for simplicity.
参考文档
关于作者
后端程序员,五年开发经验,从事互联网金融方向。技术公众号「清泉白石」。如果您在阅读文章时有什么疑问或者发现文章的错误,欢迎在公众号里给我留言。


