Hadoop(四)—— MapReduce
一、Hadoop版本特性
MRv1
第一代计算框架,由编程模型和运行时环境两部分组成。
编程模型是,将数据进行map操作,然后进行reduce操作,最后将计算结果存储到HDFS中。
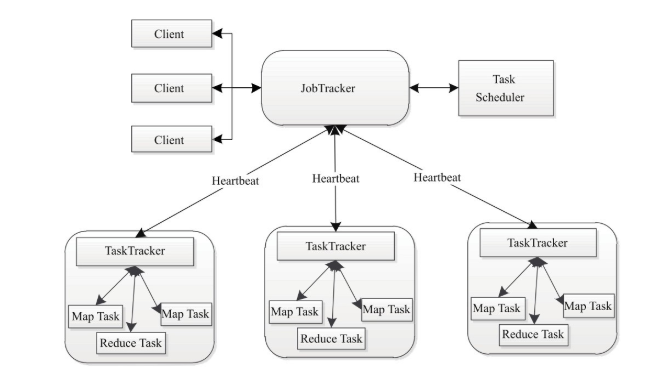
运行时环境是,由JobTracker和TaskTracker组成,JobTracker进行资源管理和作业控制。TaskTracker负责接收JobTracker分配的任务并执行。
YARN/MRv2
针对MRv1的问题,提出YARN资源管理框架,将JobTracker中的资源管理和作业控制分开,资源管理由ResourceManager进程实现,作业控制由ApplicationMaster进程实现。
二、模型概述
The MapReduce framework operates exclusively on <key, value> pairs, that is, the framework views the input to the job as a set of <key, value> pairs and produces a set of <key, value> pairs as the output of the job, conceivably of different types.
The key and value classes have to be serializable by the framework and hence need to implement the Writable interface. Additionally, the key classes have to implement the WritableComparable interface to facilitate sorting by the framework.
Input and Output types of a MapReduce job:
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
map()
对多个key/value进行处理产生对应的新的key/value。
reduce()
对key/value进行处理,生成最终结果。
MapReduce架构
实现一个MapReduce程序
对数据进行处理。找出所有年份中的最高气温。
引入Jar包
<!-- hadoop mapreduce编程所需jars -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
<version>1.2</version>
</dependency>
MapReduce模型
Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable(可靠的), fault-tolerant manner(方式).
MR是一个软件框架,可以简化编写应用,用于在分布式环境下,用一种可用、容错的方式处理大规模数据。
A MapReduce job usually splits the input data-set into independent chunks(块、片) which are processed by the map tasks in a completely parallel manner. The framework sorts the outputs of the maps, which are then input to the reduce tasks. Typically both the input and the output of the job are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
一个MR任务,通常将输入的数据集用map任务以完全并行的方式处理成独立的块。
参考文档
关于作者
后端程序员,五年开发经验,从事互联网金融方向。技术公众号「清泉白石」。如果您在阅读文章时有什么疑问或者发现文章的错误,欢迎在公众号里给我留言。


