Flink(一) —— 启动与基本使用
一、介绍
Apache Flink is an open source platform for distributed stream and batch data processing.
Flink’s core is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams.
Flink builds batch processing on top of the streaming engine, overlaying native iteration support, managed memory, and program optimization.
批处理与实时处理的优缺点
批处理,吞吐量大,但延时高。
实时处理,延时低,但吞吐量小。
以聊天做比喻,实时处理,来一条回一条,批处理,别人说十句,你最后一起回。
Flink的目标
- 低延迟
- 高吞吐
- 容错率高,计算正确率高
流数据处理的应用场景
- 电商、市场营销
- 数据报表
- 金融、银行
- 实时监测异常行为
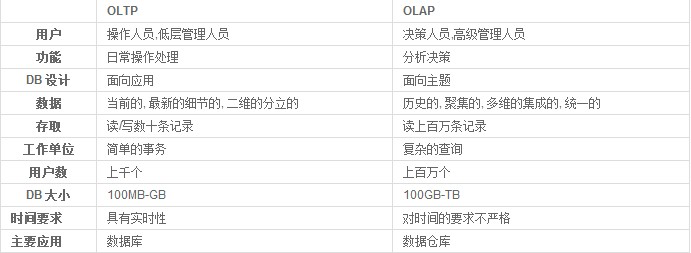
OLTP和OLAP
OLTP(on-line transaction processing)联机事务处理,面向的是事务,处理几条数据。
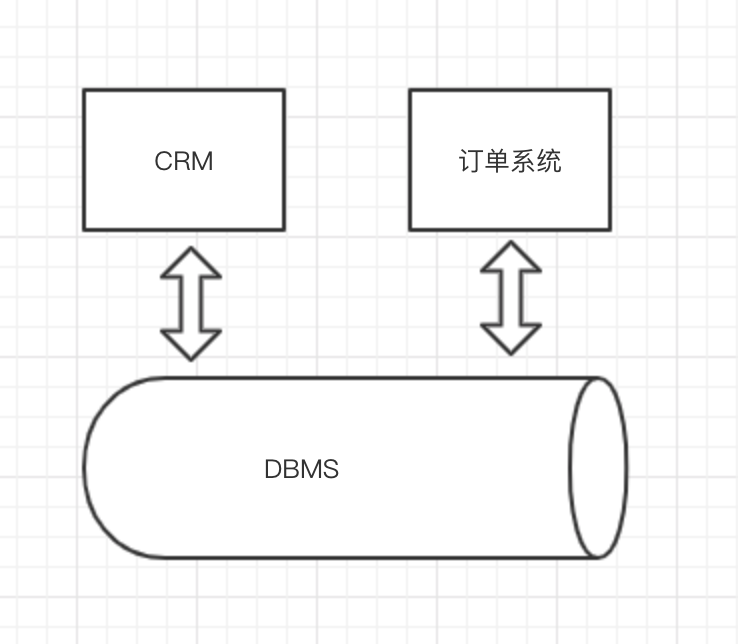
OLAP(on-line analytical processing)面向的是一堆数据的数据分析。
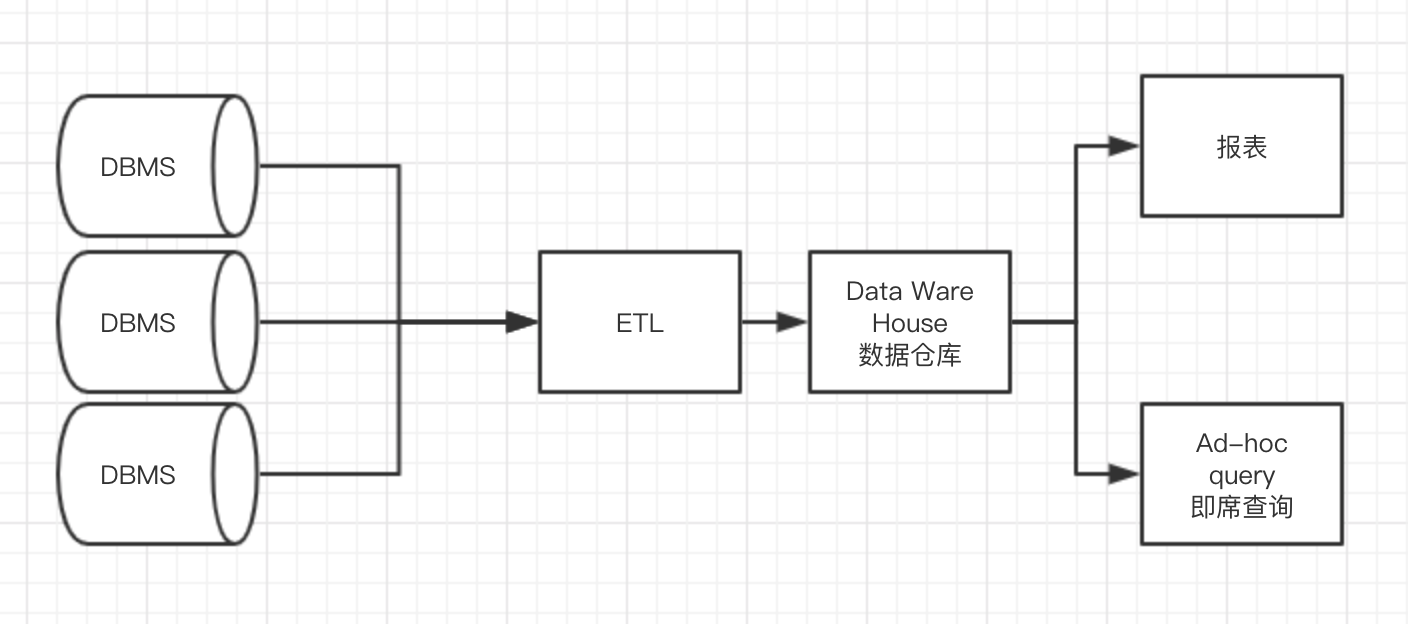
Ad-hoc
即席查询,用户根据自己的需求、灵活地选择查询条件,可以理解为需求不太明确的查询,由用户自定义的查询。
流处理的演变
从起初单纯的流处理,转变为后来的流处理和批处理结合的lambda架构。
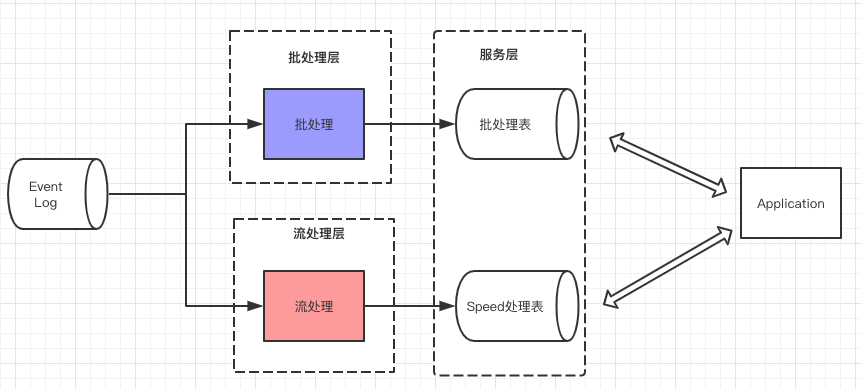
特点就是流处理的数据可能不准确,但延迟低,批处理的数据准确性高,但延迟高,将将两者结合起来。
这就好比是两个人做同一件事,一个人是慢性子做事非常仔细,另一个人是急性子,做事快。急性子的人提前把事情做好,例如得出100,200,300的结果。慢性子也去做同样的事,得出100,250,300,等慢性子把事情做好,最终的结果就会由100,200,300,变为100,250,300。
第一性思考:本质就是优劣势互补。
第三代流式处理,Flink,在lambda架构上又做了改进。
Flink整合了Storm与SparkStreaming的优点。SparkStreaming的逻辑是,将批拆分成更小的批处理,在保证低延时的情况下,还能保证高吞吐。
特点
-
事件驱动
-
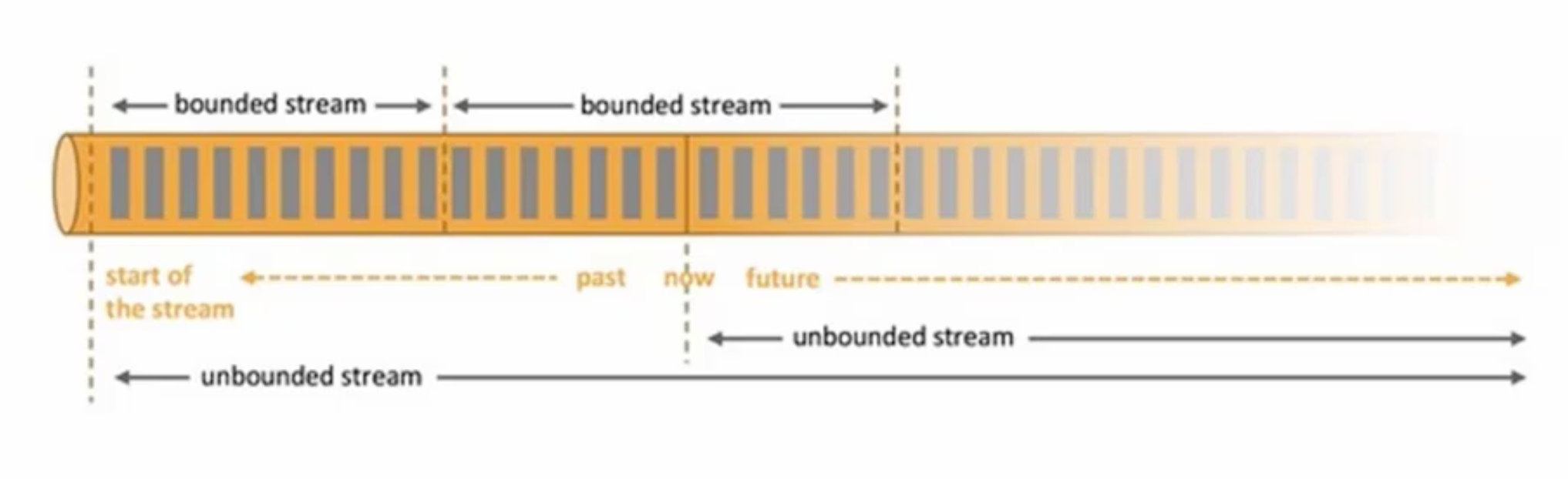
基于流的世界观,所有东西都是流,批就是有界的流,实时数据就是无界的流。而Spark呢,则是所有东西都是批,SparkStreaming处理的则是更小的批。
-
分层的API
架构
Apache Flink is a framework and distributed processing engine for stateful computations (状态计算) over unbounded and bounded data streams.
Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
lambda架构
将离线计算和实时计算结合在一起,发挥离线计算准确率高、实时计算响应速度快的优势。缺点是,同一套逻辑要分别在两个模式下实现,存在代码冗余的问题。
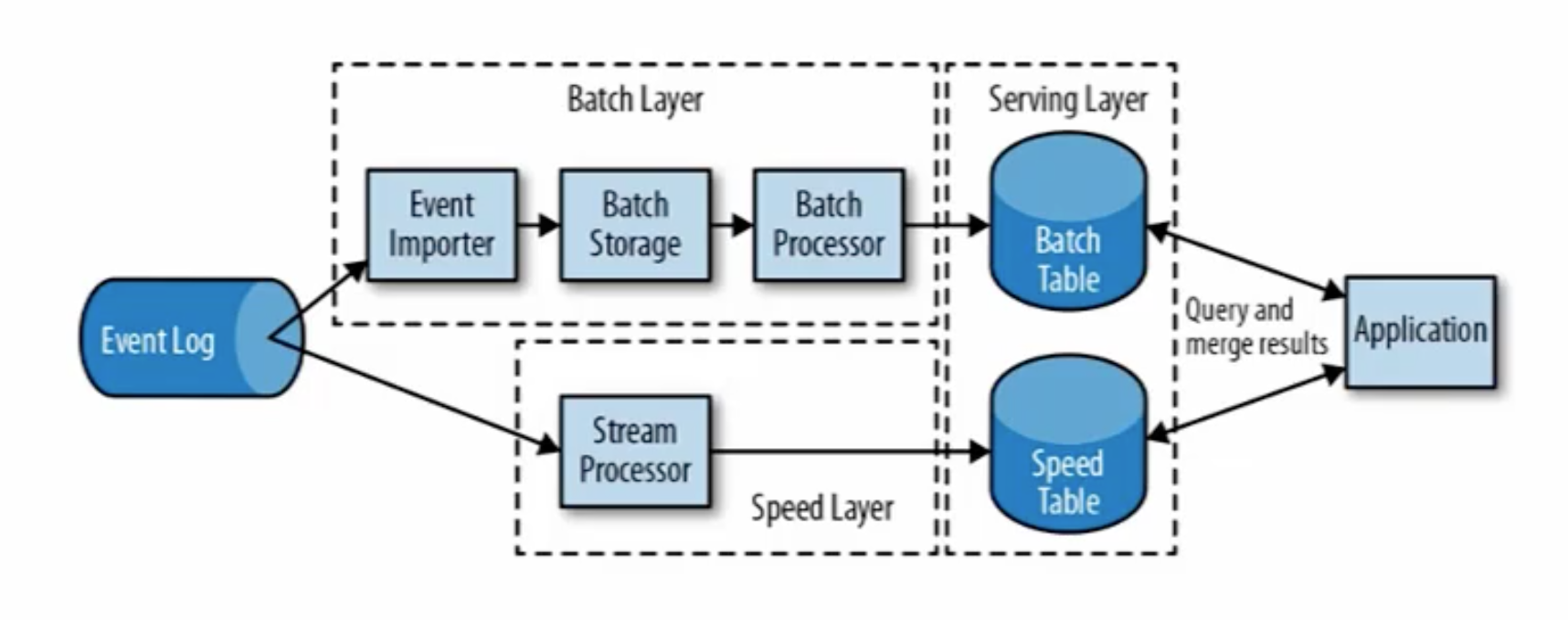
Flink特点
(1)批流一体化
Flink中的思想是,一切都是流。离线计算是有界限的流,实时计算是无界限的流。
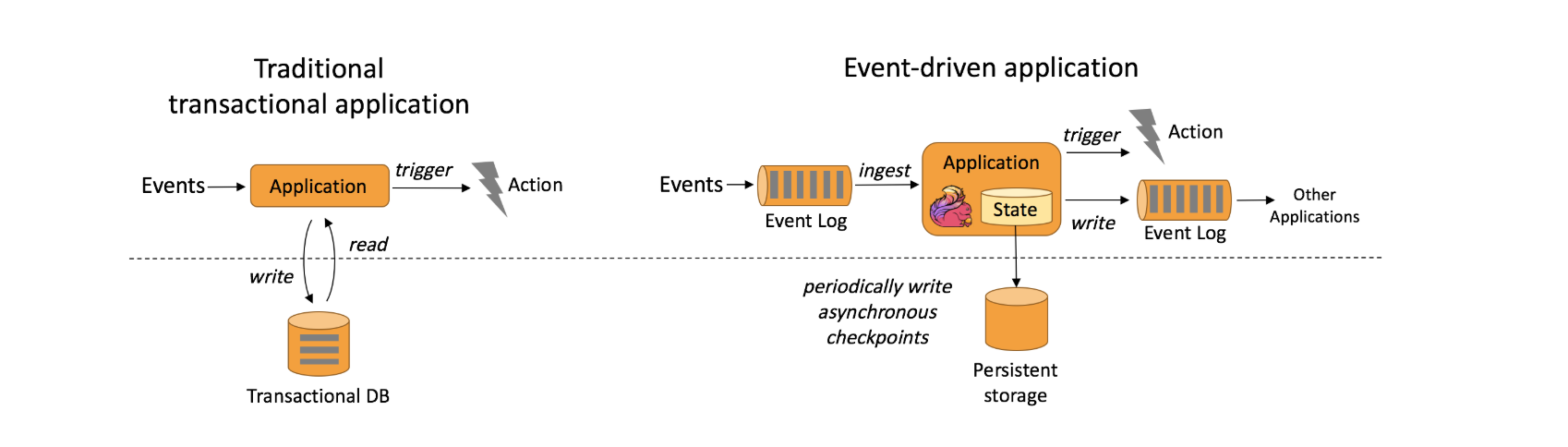
(2)事件驱动型应用
二、本地安装
https://ci.apache.org/projects/flink/flink-docs-release-1.11/try-flink/local_installation.html
三、基本使用
WordCount
(1)引入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.7.2</version>
</dependency>
(2)准备数据
hello kafka
hello bigdata
hello flink
hello hbase
hbase
kafka
(3)Flink批处理实现
package flink
import org.apache.flink.api.scala._
object wordcount {
def main(args: Array[String]): Unit = {
//创建一个执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
val inputPath = "word.txt";
val inputDataSet = env.readTextFile(inputPath)
//切分数据,得到word
val wordCountDataSet = inputDataSet.flatMap(_.split(" "))
.map((_,1))
.groupBy(0)
.sum(1)
wordCountDataSet.print()
}
}
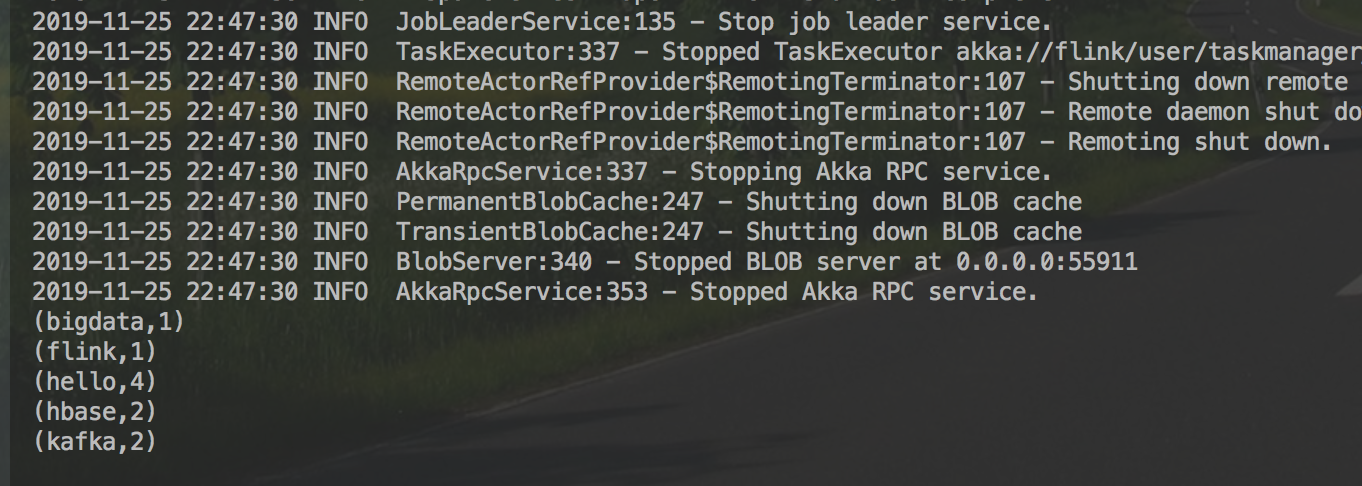
运行结果
(4)Flink流处理实现
/**
* 流式 WordCount程序
*/
object StreamWordCount {
def main(args: Array[String]): Unit = {
// 创建流处理的执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 创建一个文本socket
val dataStream = env.socketTextStream("localhost",7777)
val wordCountDataStream = dataStream.flatMap(_.split(" "))
.map((_,1))
.keyBy(0)
.sum(1)
wordCountDataStream.print()
// 启动executor
env.execute("stream word count")
}
}
在终端使用nc -lk 7777打开一个socket连接,运行程序,得到结果
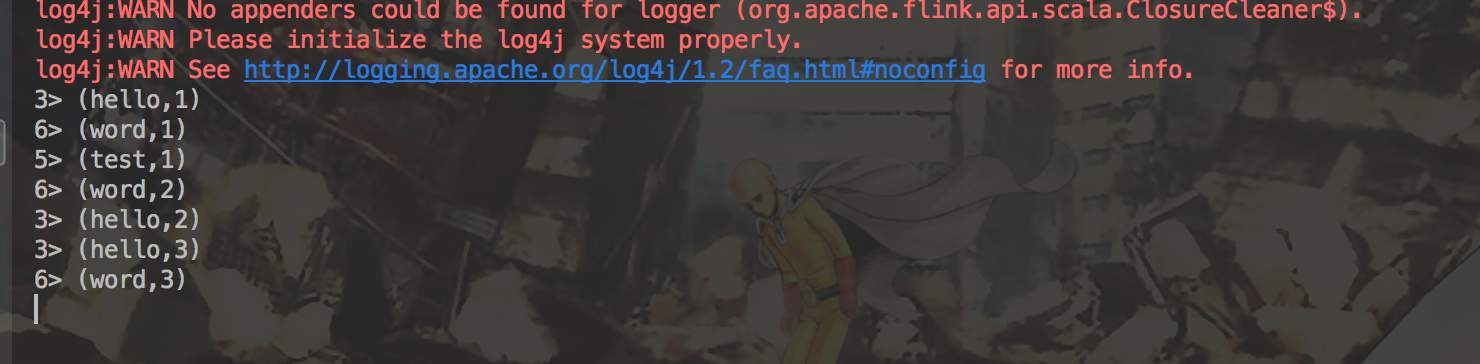
参考文档
Flink官方文档
Flink 实时数仓的应用
Apache Flink 零基础入门(一&二):基础概念解析
企业级数据仓库
大数据工程师 Flink技术与实战
关于作者
后端程序员,五年开发经验,从事互联网金融方向。技术公众号「清泉白石」。如果您在阅读文章时有什么疑问或者发现文章的错误,欢迎在公众号里给我留言。


