Hadoop(一)—— 启动与基本使用
一、安装&启动
安装
下载hadoop2.7.2
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
2.7.2-官方文档
https://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/SingleCluster.html
安装ssh
## 检查是否有ssh
## 若返回结果有openssh-clients、openssh-server说明安装
rpm -qa | grep ssh
## 检查ssh是否可用
ssh localhost
启动
查看hadoop版本
./bin/hadoop version
运行一个例子
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
$ cat output/*
输出结果

运行WordCount样例
创建文件夹wordinput以及在文件夹下创建word.txt文本,文本内容如下:
hello
world
hello
kafka kafka
hello world
big data
bigdata
执行脚本
./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wordinput wordoutput
得到运行结果
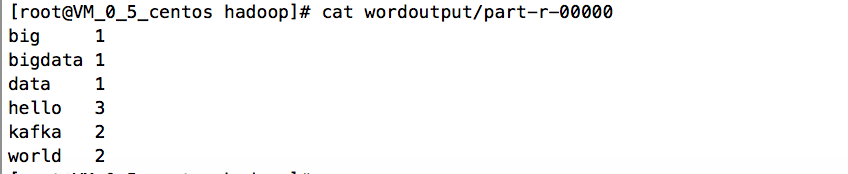
Hadoop 配置文件
hadoop core-default配置文件介绍
https://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/core-default.xml
配置etc/hadoop/core-site.xml
<configuration>
<!-- 指定HDFS中的NameNode地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
配置etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
启动HDFS
执行脚本
./bin/hdfs namenode -format
下面两种方式是等价的
./sbin/start-dfs.sh
或
## 启动namenode进程
./sbin/hadoop-daemon.sh start namenode
## 启动datanode进程
./sbin/hadoop-daemon.sh start datanode
namenode是什么?datanode是什么?为什么必须要格式化namenode才能启动成功?
访问 http://127.0.0.1:50070/dfshealth.html#tab-overview
看到DFS的面板。
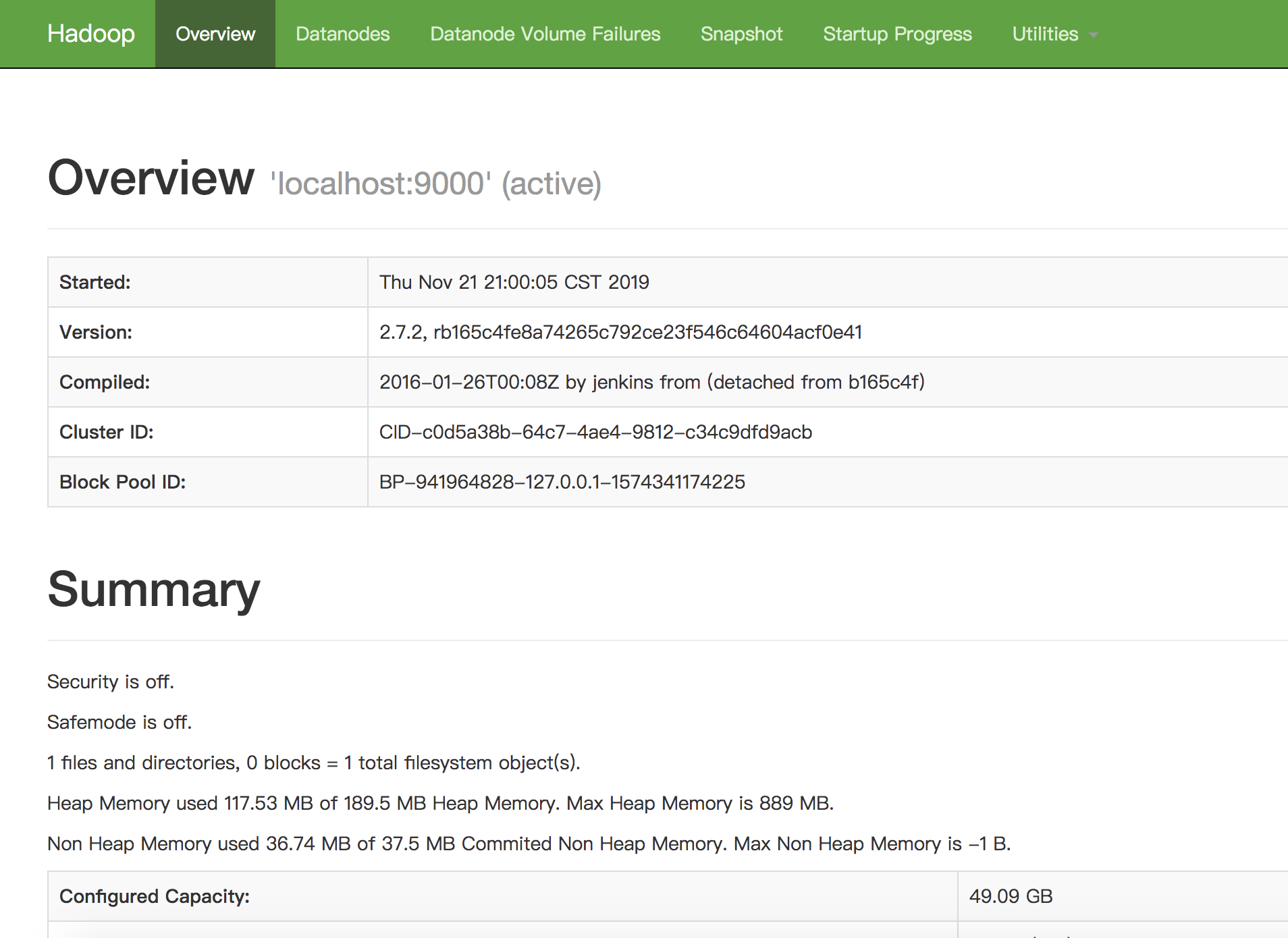
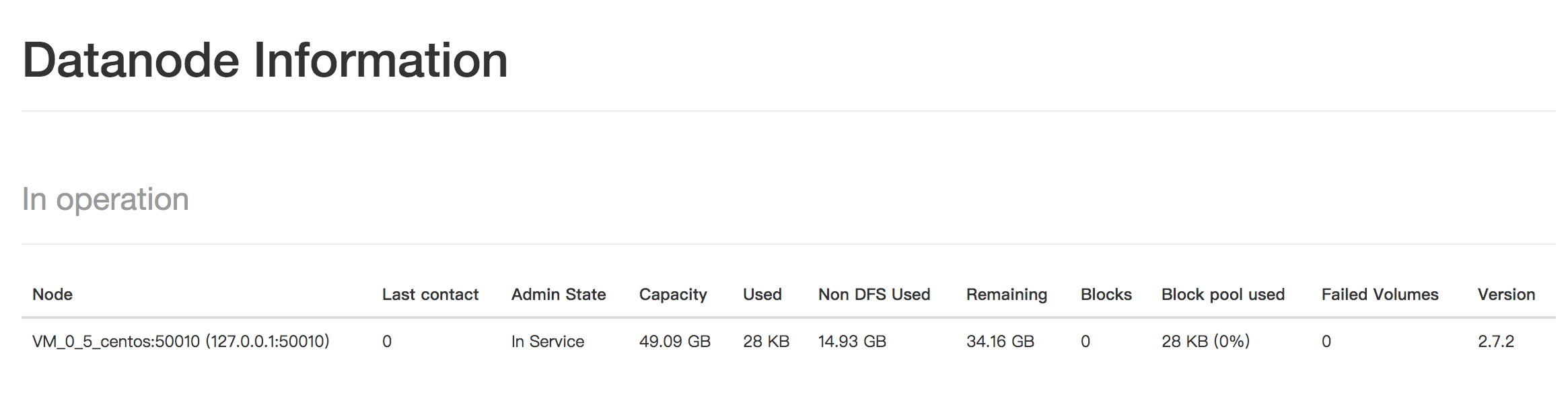
启动Yarn
配置etc/hadoop/mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置etc/hadoop/yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
启动 ResourceManager daemon and NodeManager daemon:
sbin/start-yarn.sh
打开资源管理的web页面,http://localhost:8088/
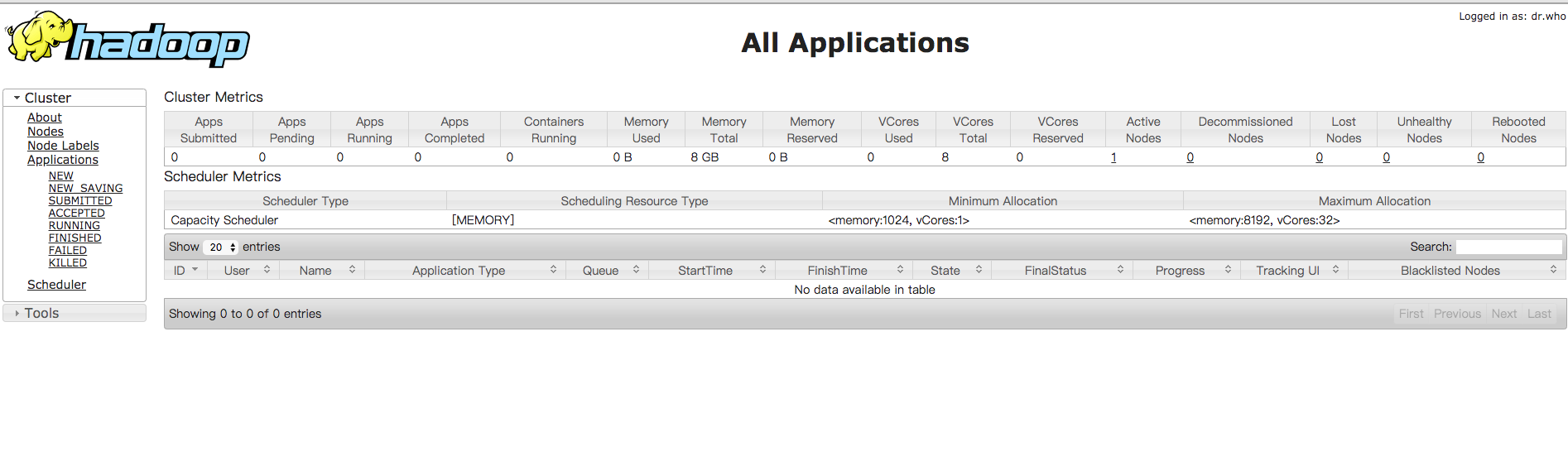
问题解决
每次启动HDFS,都必须格式化,才能启动NameNode
原因是,配置HDFS时,只配置了DataNode目录,没有配置NameNode相关信息。默认的tmp文件每次重新开机都会被清空,导致集群找不到NameNode信息,所以需要每次都重新格式化。
解决方法:
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/Hadoop_tmp</value>
<description>A base for other temporary directories.</description>
</property>
参考文档
Hadoop官网-Hadoop: Setting up a Single Node Cluster
Hadoop官网2.7.3
《Hadoop权威指南》
尚硅谷大数据之Hadoop
运行第一个MapReduce程序
MapReduce过程详解(基于hadoop2.x架构)
关于作者
后端程序员,五年开发经验,从事互联网金融方向。技术公众号「清泉白石」。如果您在阅读文章时有什么疑问或者发现文章的错误,欢迎在公众号里给我留言。


